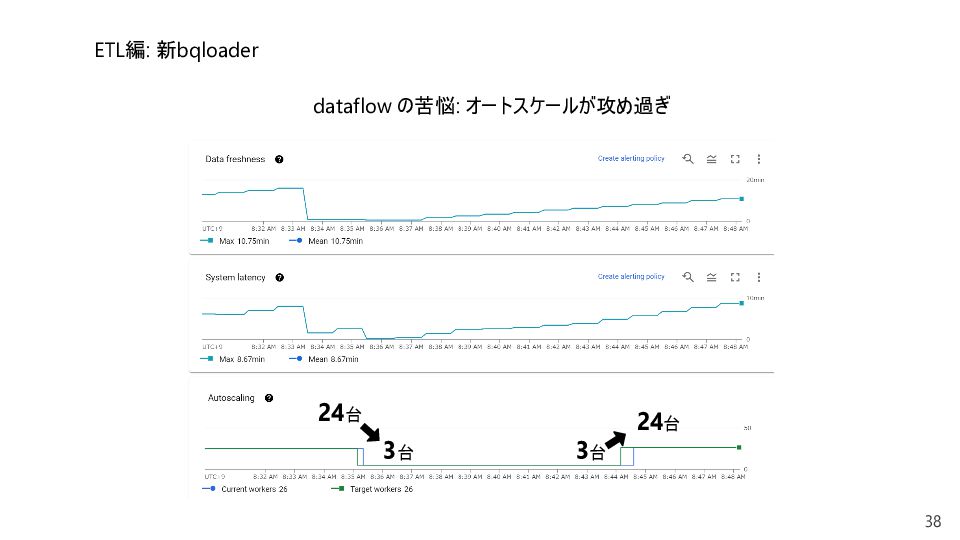
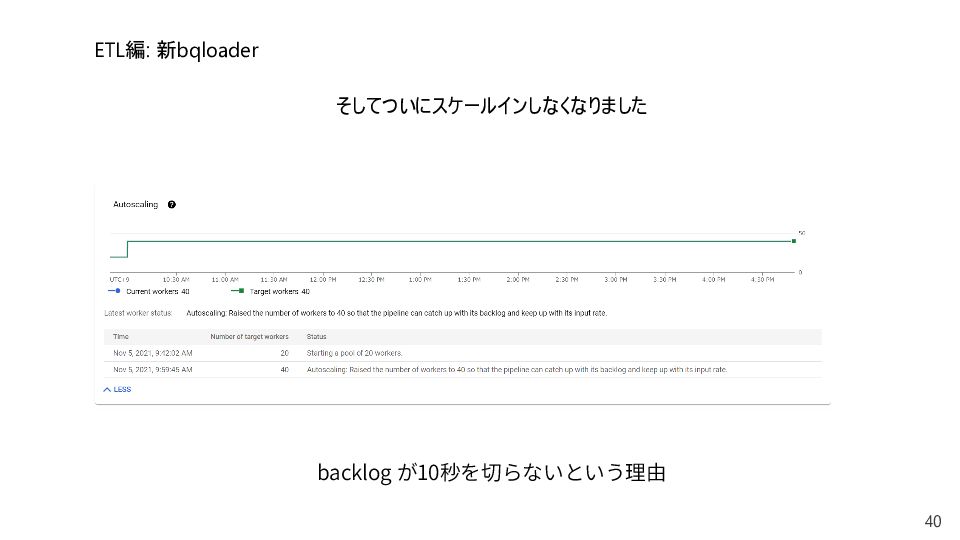
streaming pipeline remains backlogged with workers utilizing, on average, more than 20% of their CPUs, for a couple minutes, Dataflow scales up. Dataflow targets clearing the backlog in approximately 150 seconds after scaling up, given the current throughput per worker. Scaling down: If a streaming pipeline backlog is lower than 10 seconds and workers are utilizing on average less than 75% of the CPUs for a period of a couple minutes, Dataflow scales down. After scaling down, workers utilize on average, 75% of their CPUs. In streaming jobs that do not use Streaming Engine, sometimes the 75% CPU utilization cannot be achieved due to disk distribution (each worker must have the same number of persistent disks), and a lower CPU utilization is used. For example, a job set to use a maximum of 100 workers (with 1 disk per worker) can be scaled down to 50 workers (with 2 disks per worker). For this job, a 75% CPU utilization is not achievable because the next scale down from 100 workers is 50 workers, which is less than the required 75 workers. Consequently, Dataflow does not scale down this job, resulting in a lower than 75% CPU utilization. No scaling: If there is no backlog but CPU usage is 75% or greater, the pipeline does not scale down. If there is backlog but CPU usage is less than 20% the pipeline does not scale up. https://cloud.google.com/dataflow/docs/guides/deploying-a-pipeline 自分でスケーリング条件を管理したい: 切実
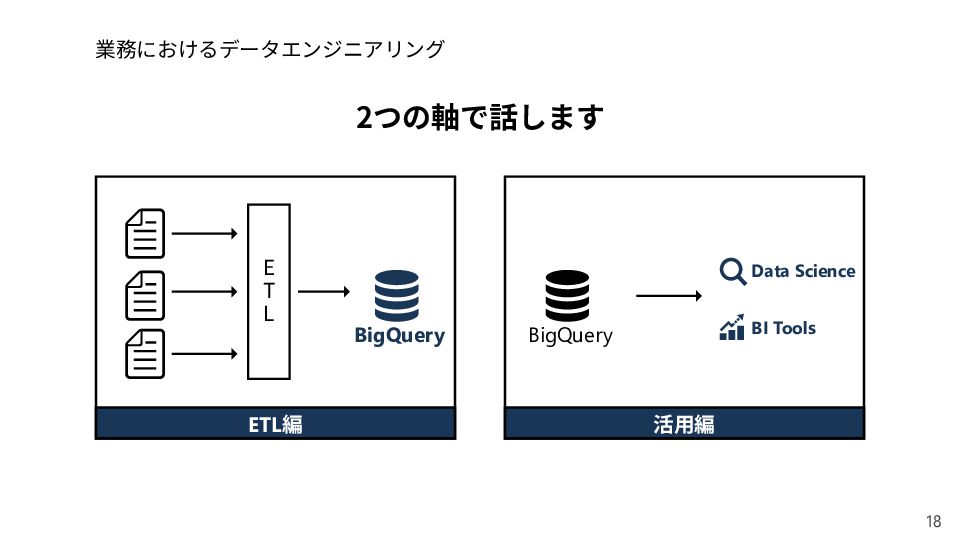
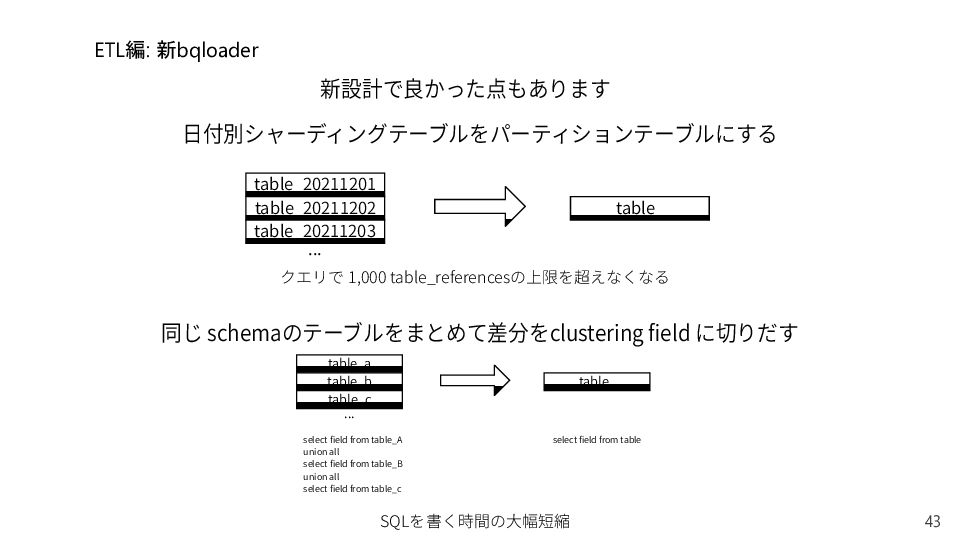
table ETL編: 新bqloader 新設計で良かった点もあります 日付別シャーディングテーブルをパーティションテーブルにする 同じ schemaのテーブルをまとめて差分をclustering field に切りだす select field from table_A union all select field from table_B union all select field from table_c select field from table SQLを書く時間の大幅短縮 クエリで 1,000 table_referencesの上限を超えなくなる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
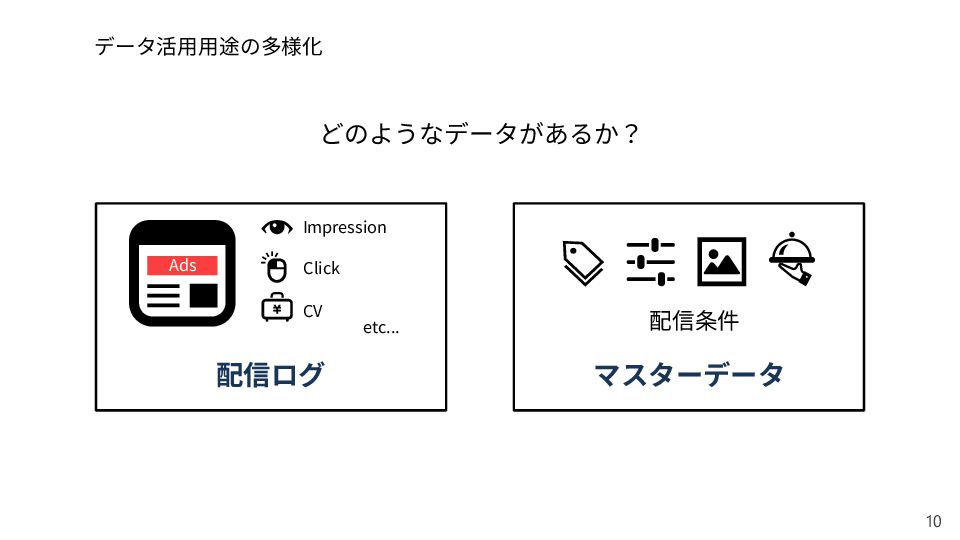{kind=link}
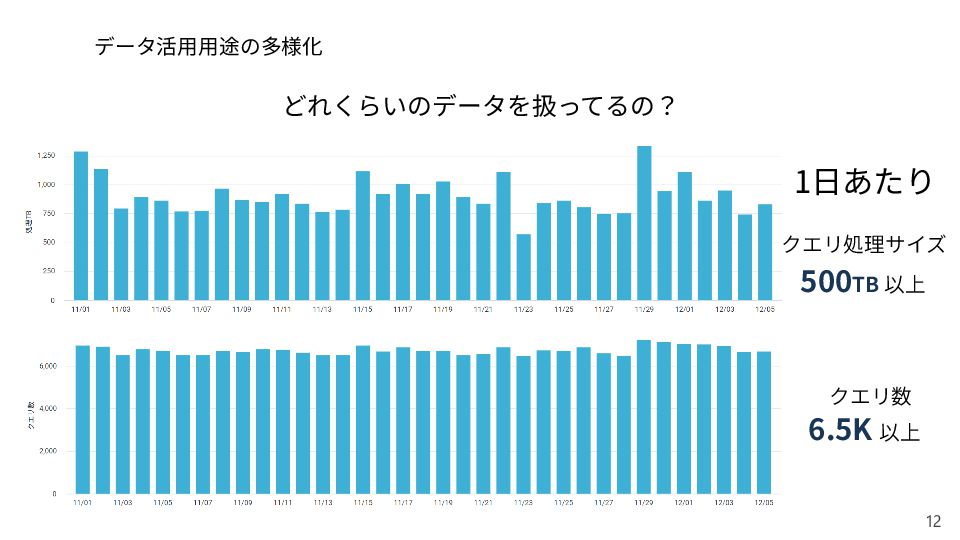
{kind=link}
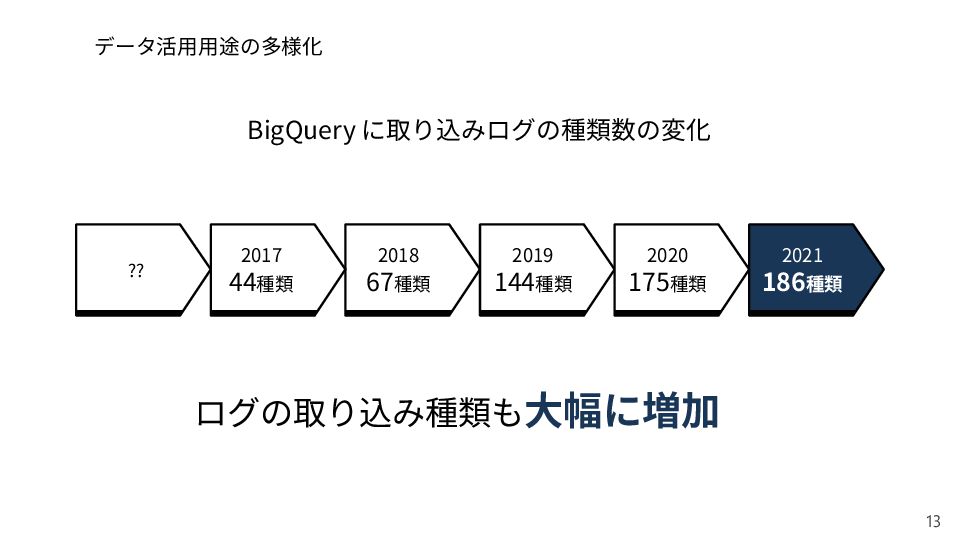
{kind=link}
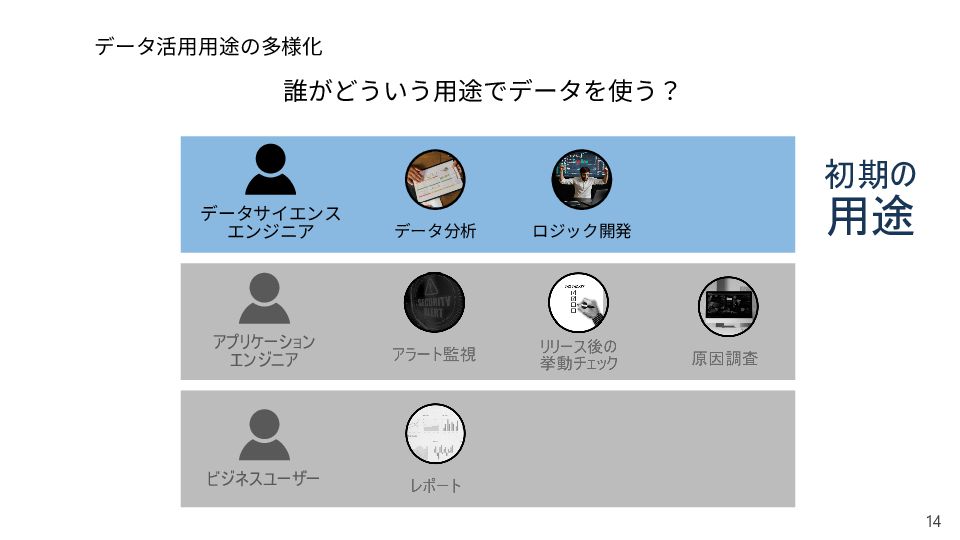
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
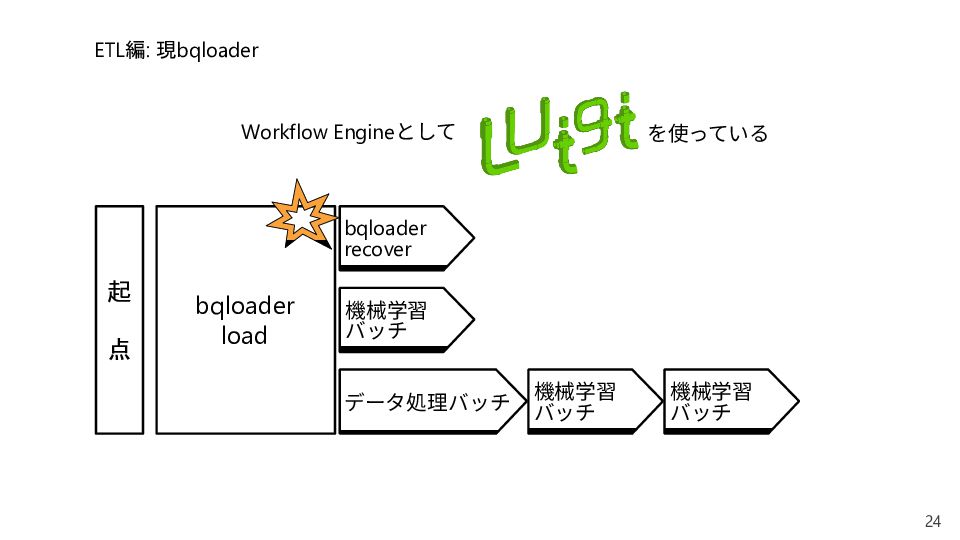{kind=link}
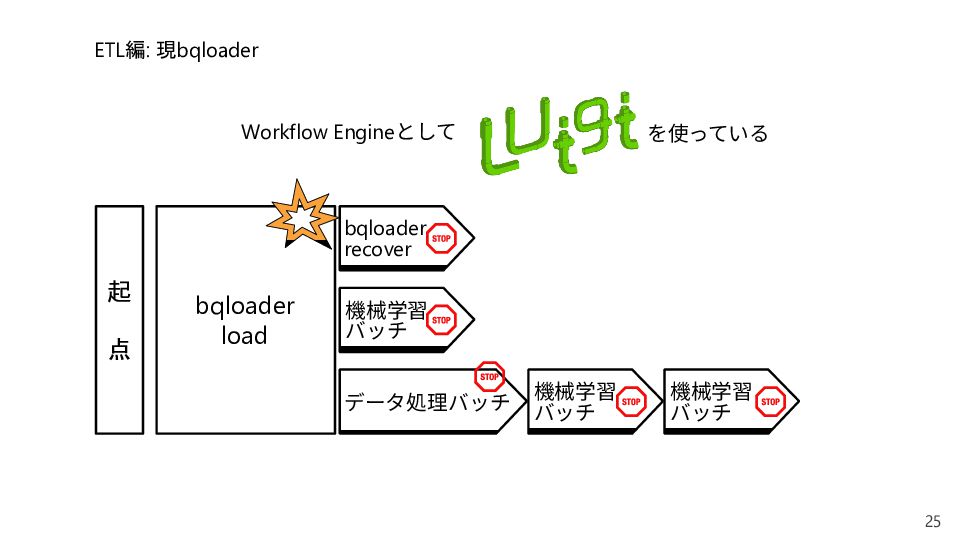{kind=link}
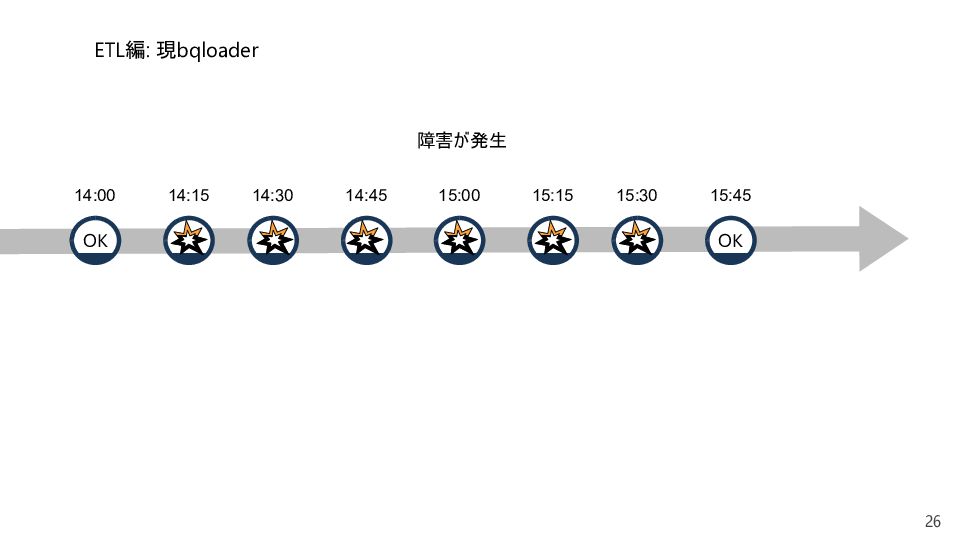{kind=link}
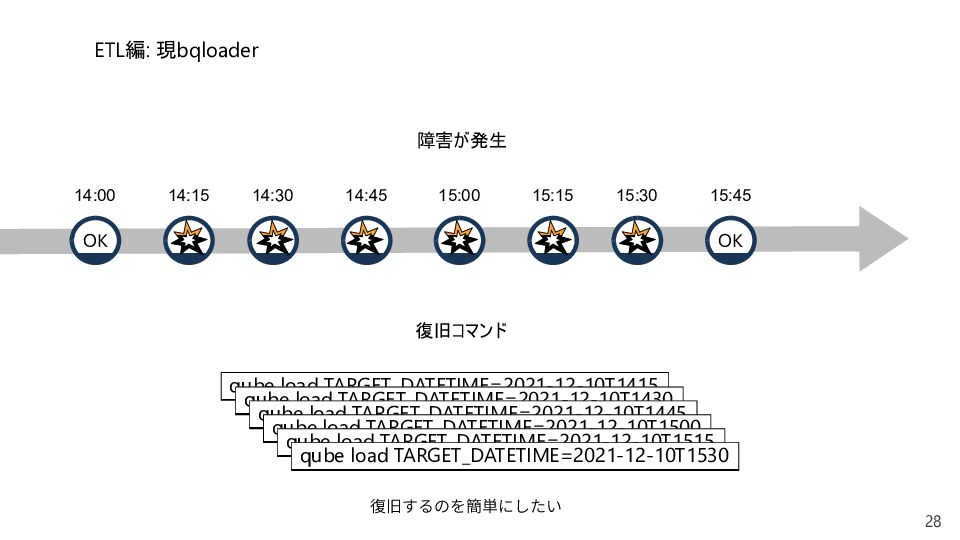
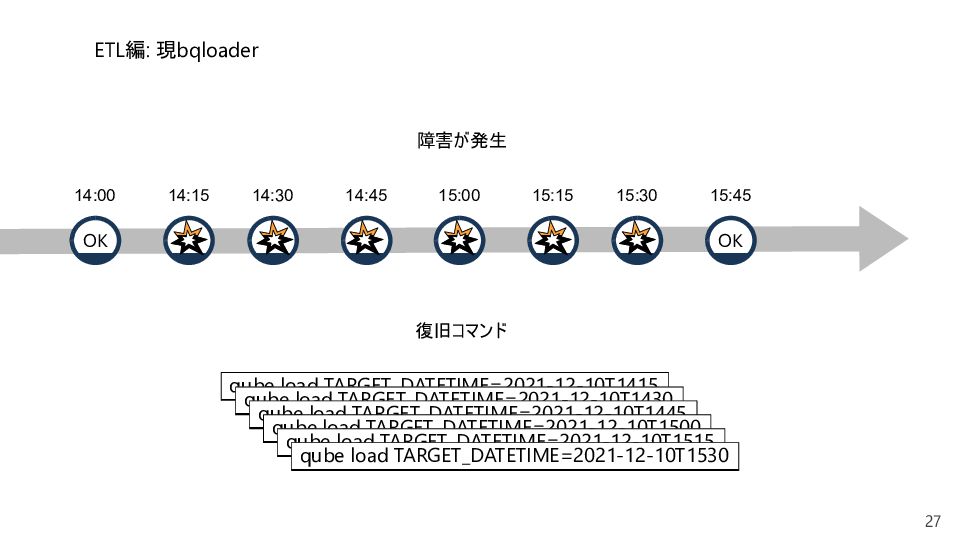{kind=link}
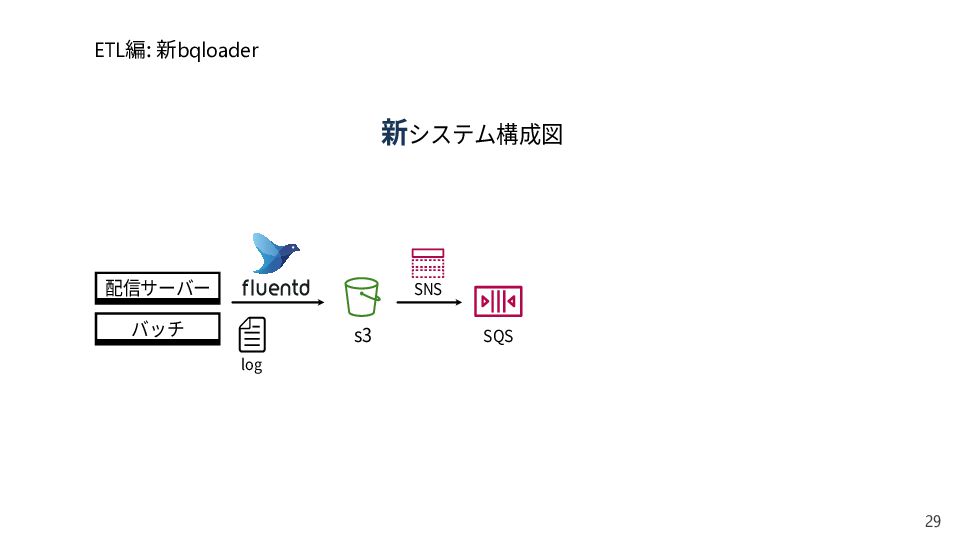
{kind=link}
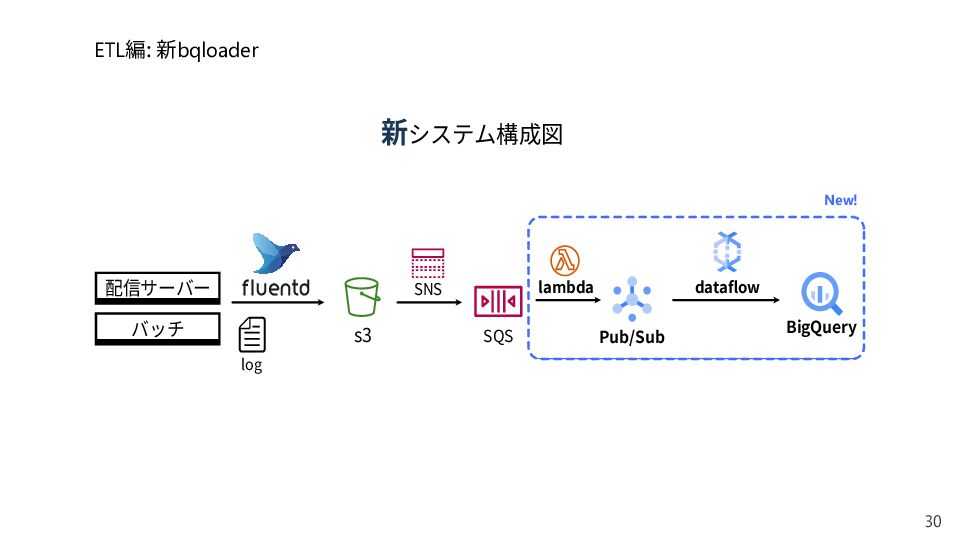
{kind=link}
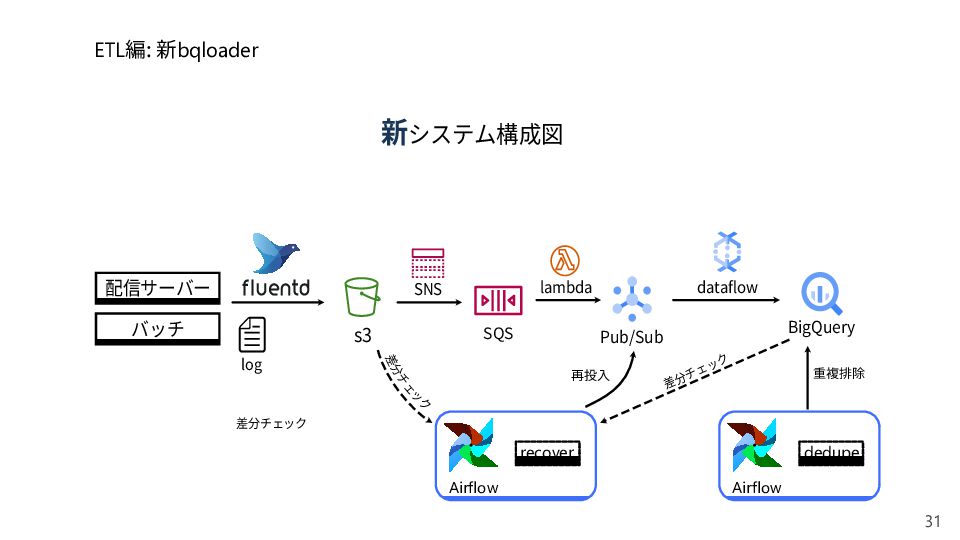
{kind=link}
{kind=link}
{kind=link}
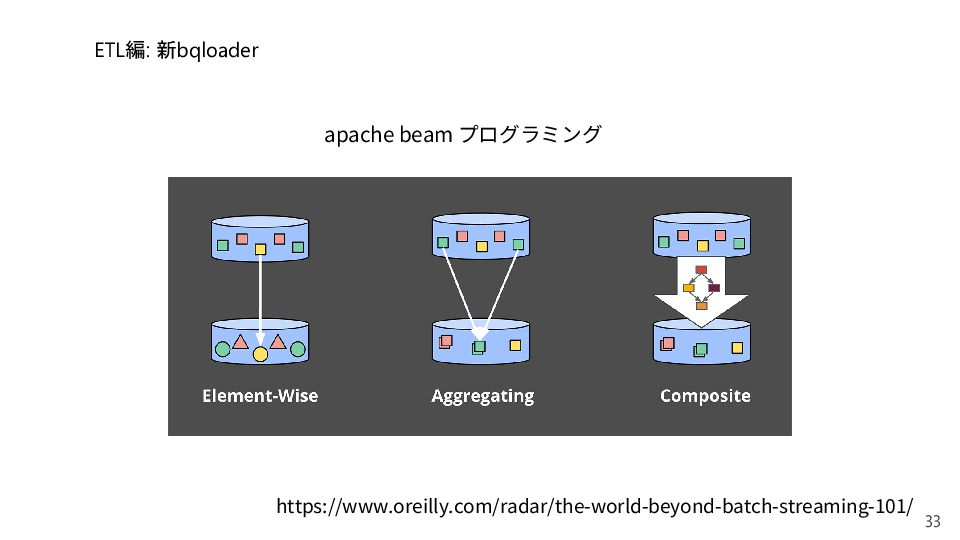{kind=link}
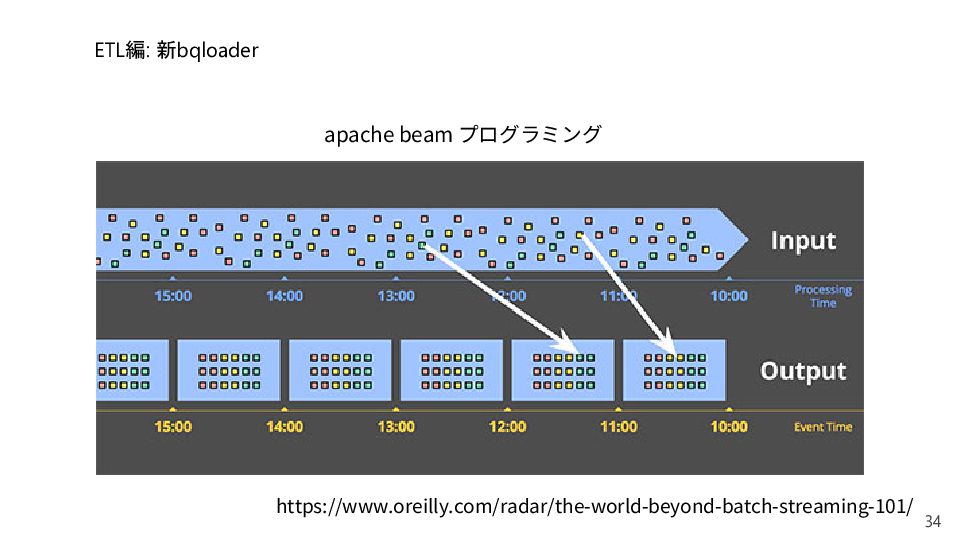{kind=link}
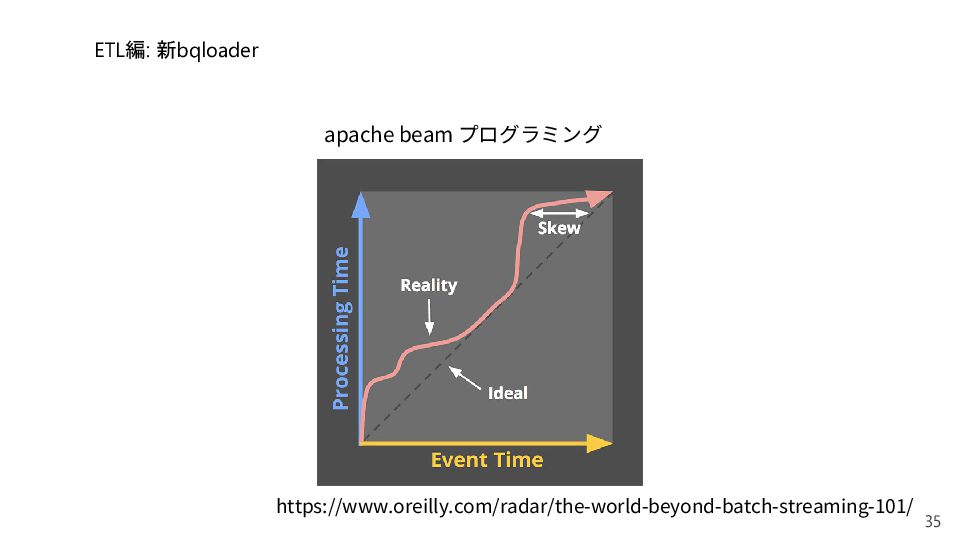{kind=link}
{kind=link}
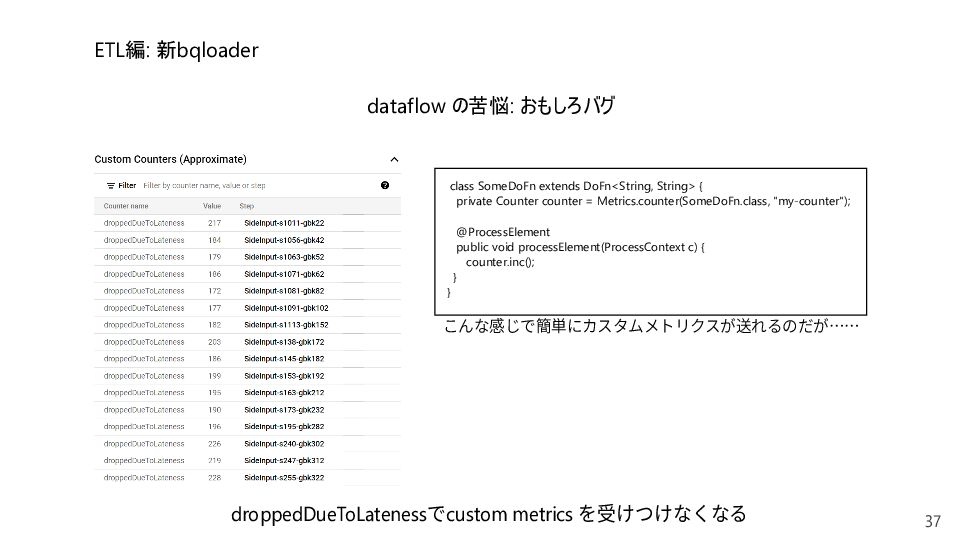{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}