AcademiX が開催した 第7回 論文輪読会 資料
日時:2023/04/08
発表者:藤野倫太郎さん
論文タイトル:InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
<概要>
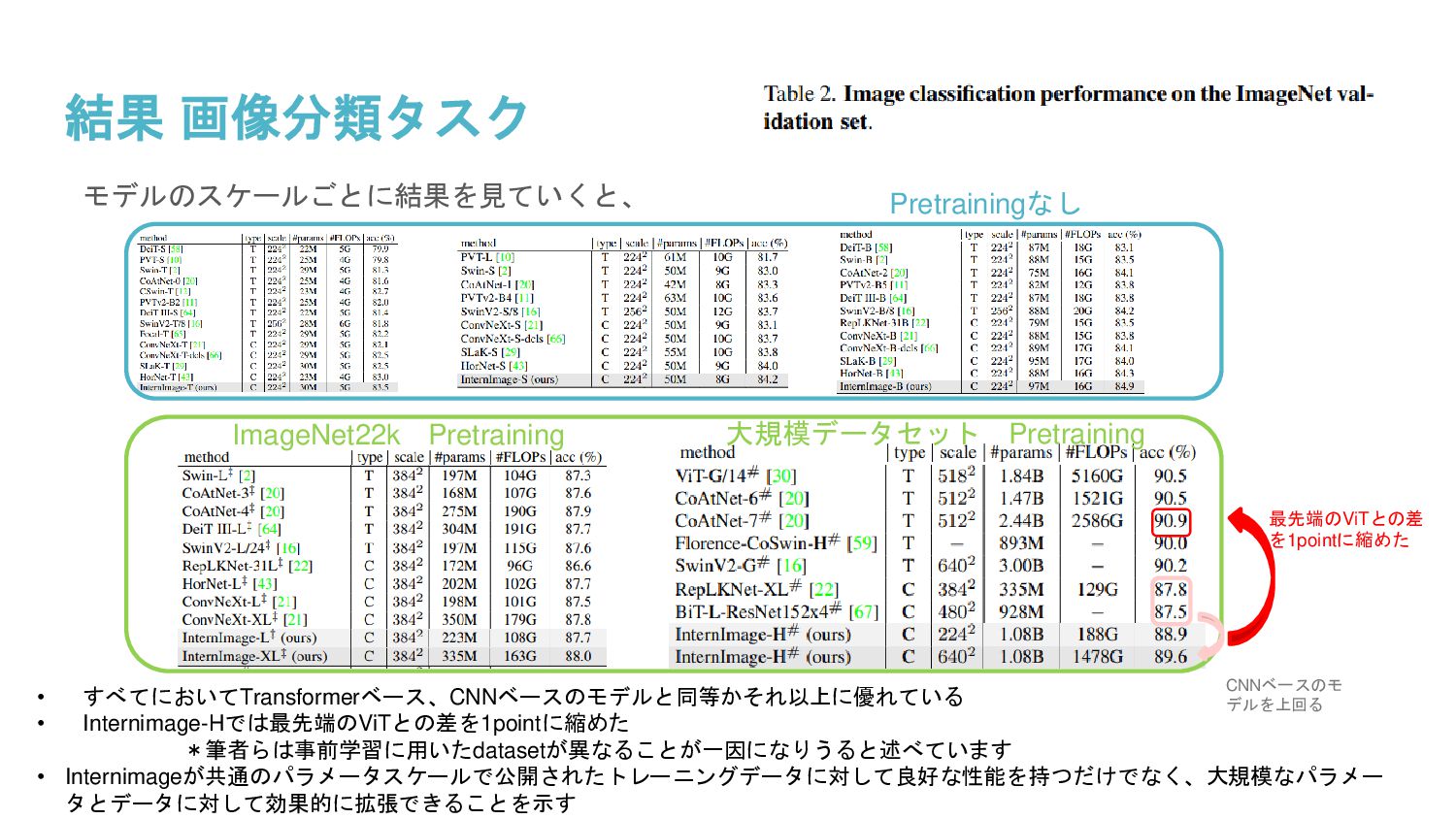
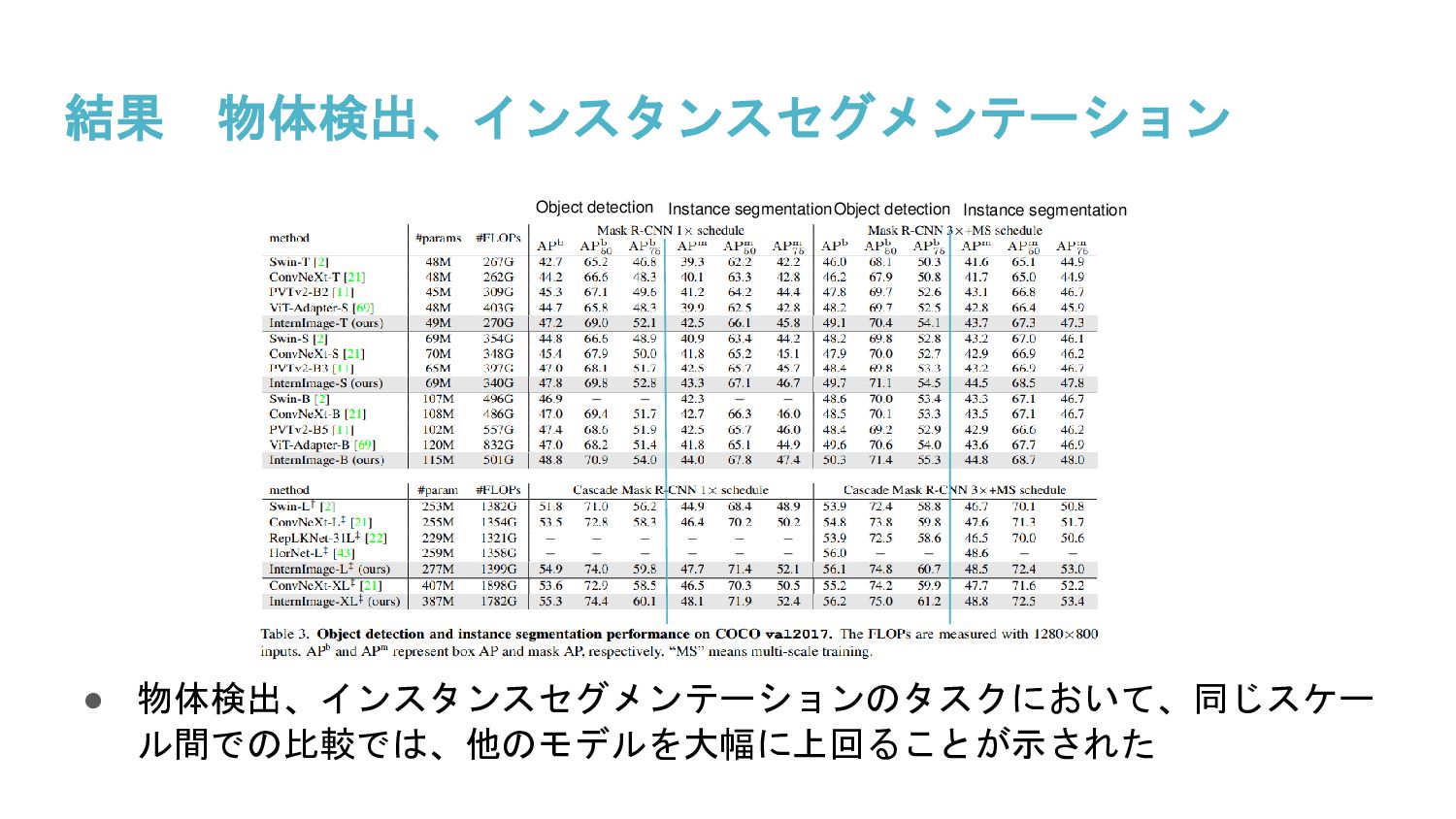
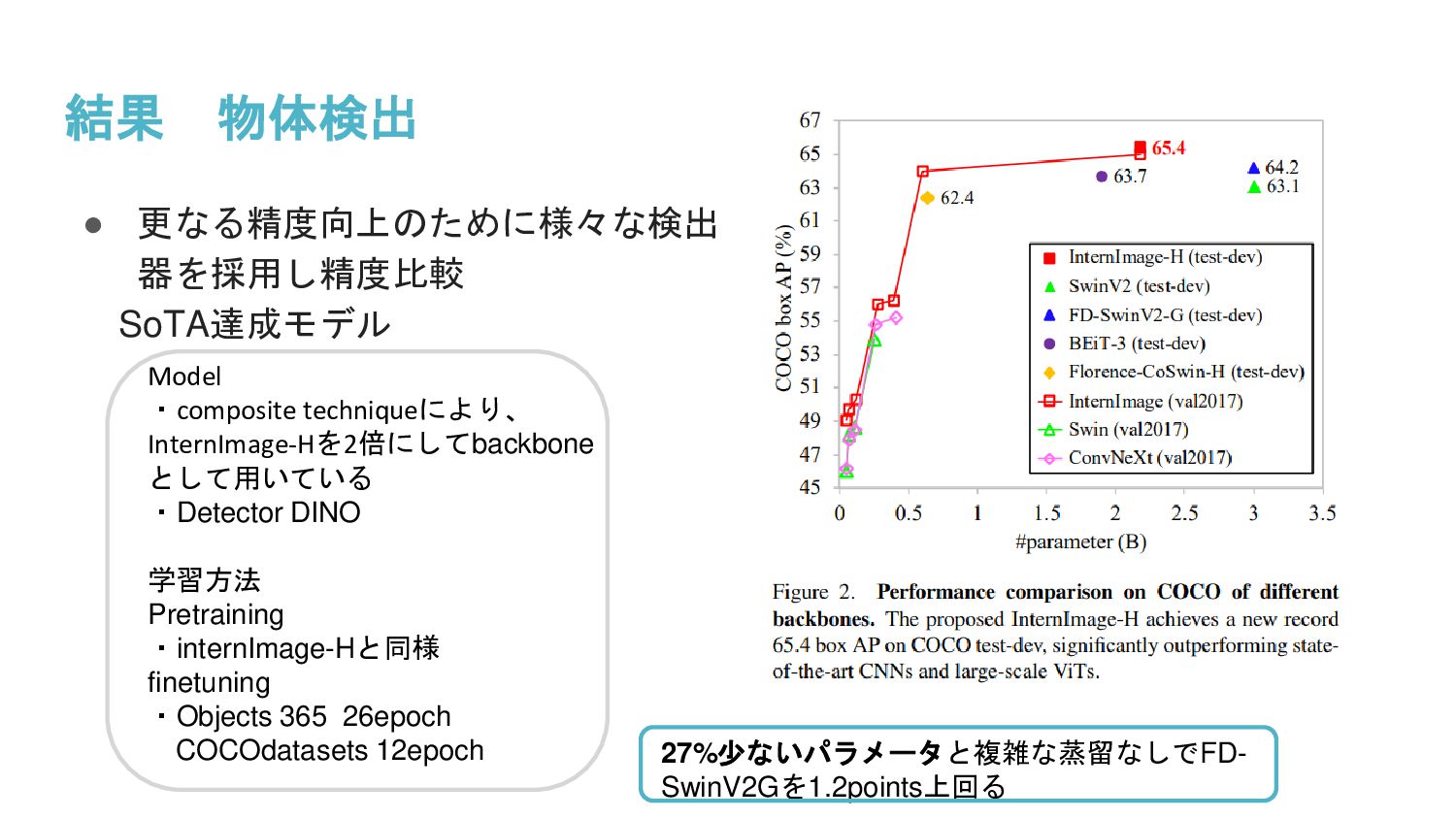
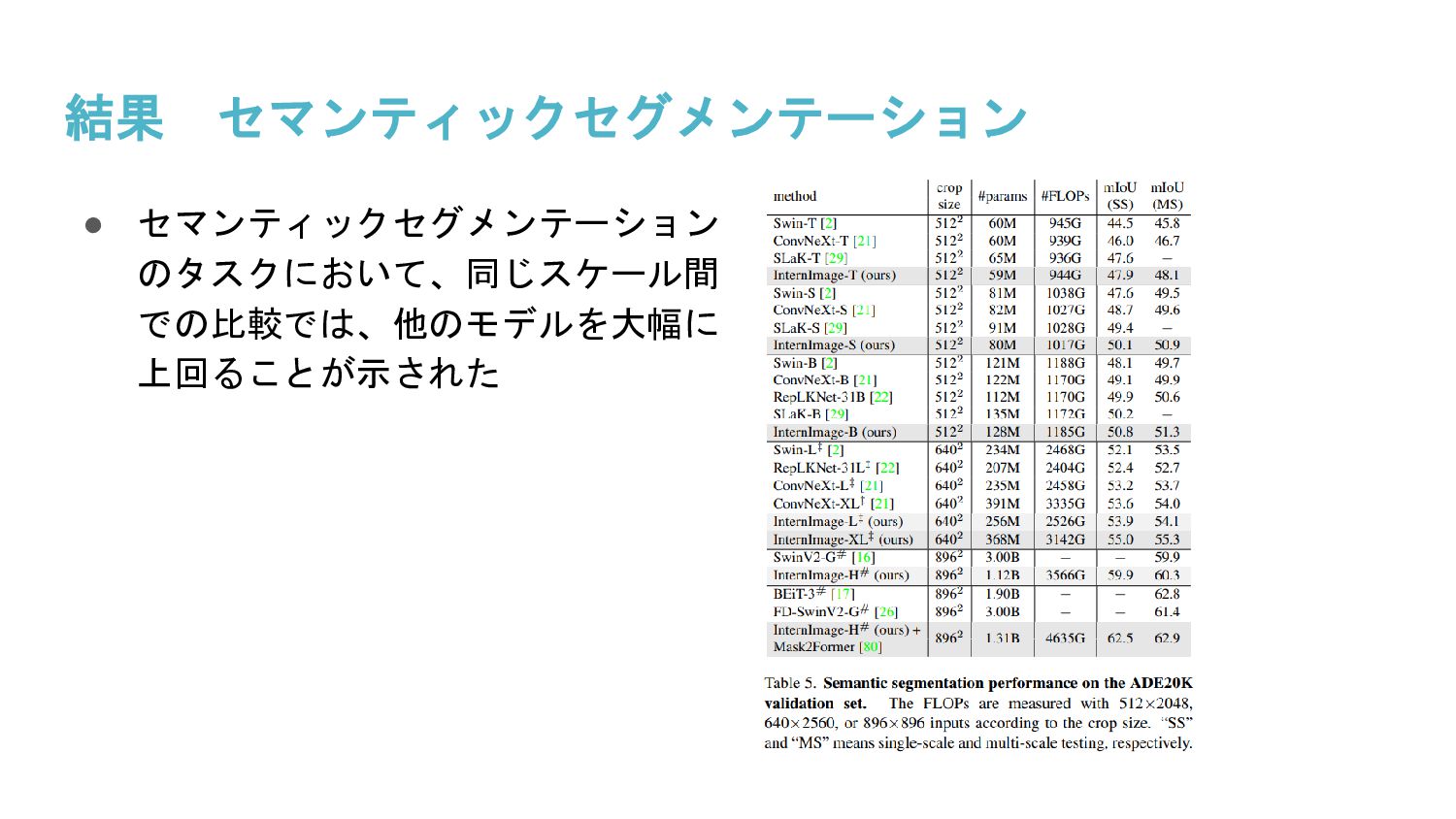
InternImageと呼ばれるDeformable Convolution v3を核とした新しい大規模CNNベースの基盤モデルを提案し、画像分類、物体検出、セグメンテーションのタスクで大規模データで学習されたViTと同等、または同等以上の精度を得ることを示した。大規模モデルの選択肢としてCNNが大きな可能性を持つと述べられている。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
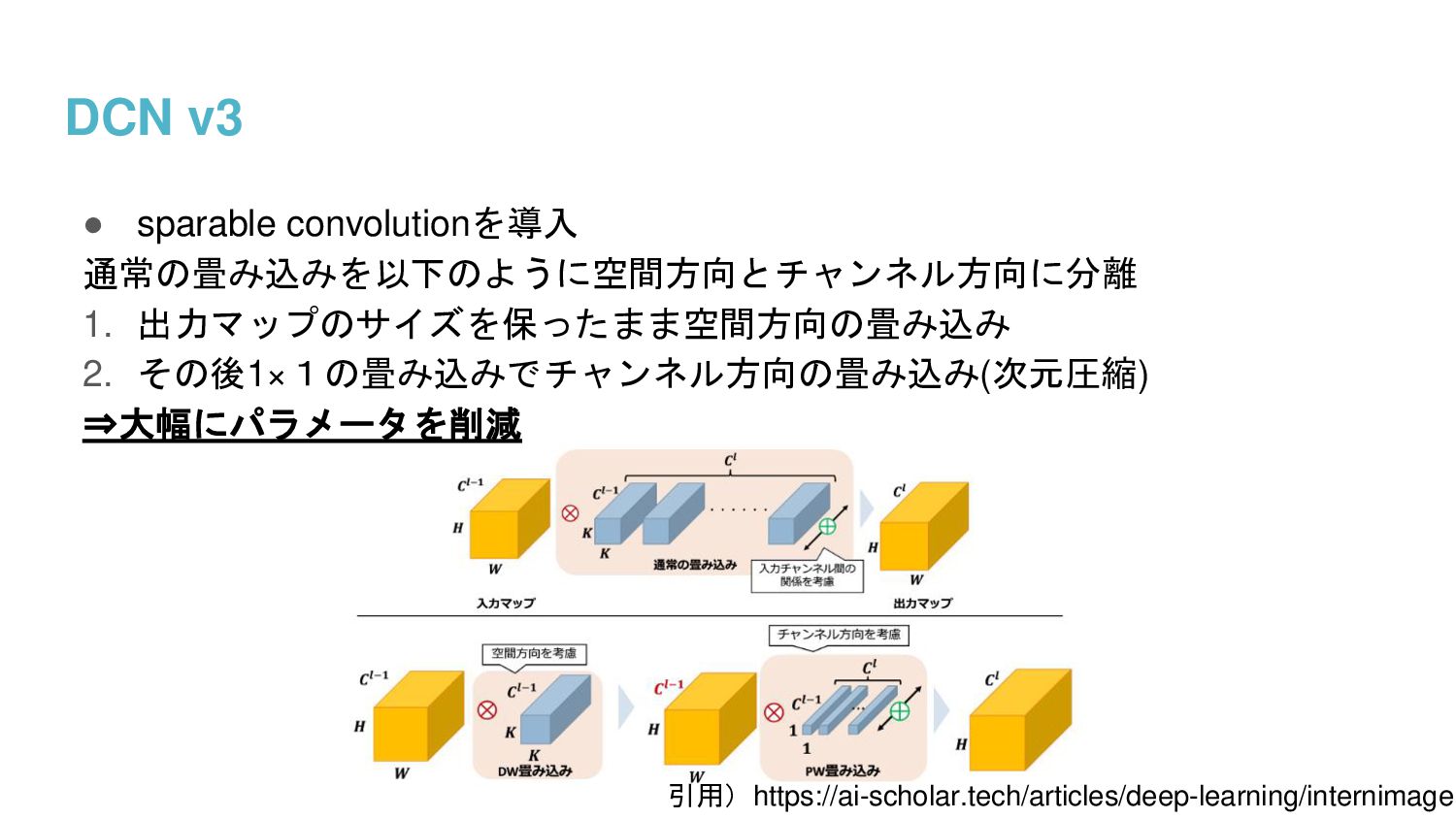{kind=link}
{kind=link}
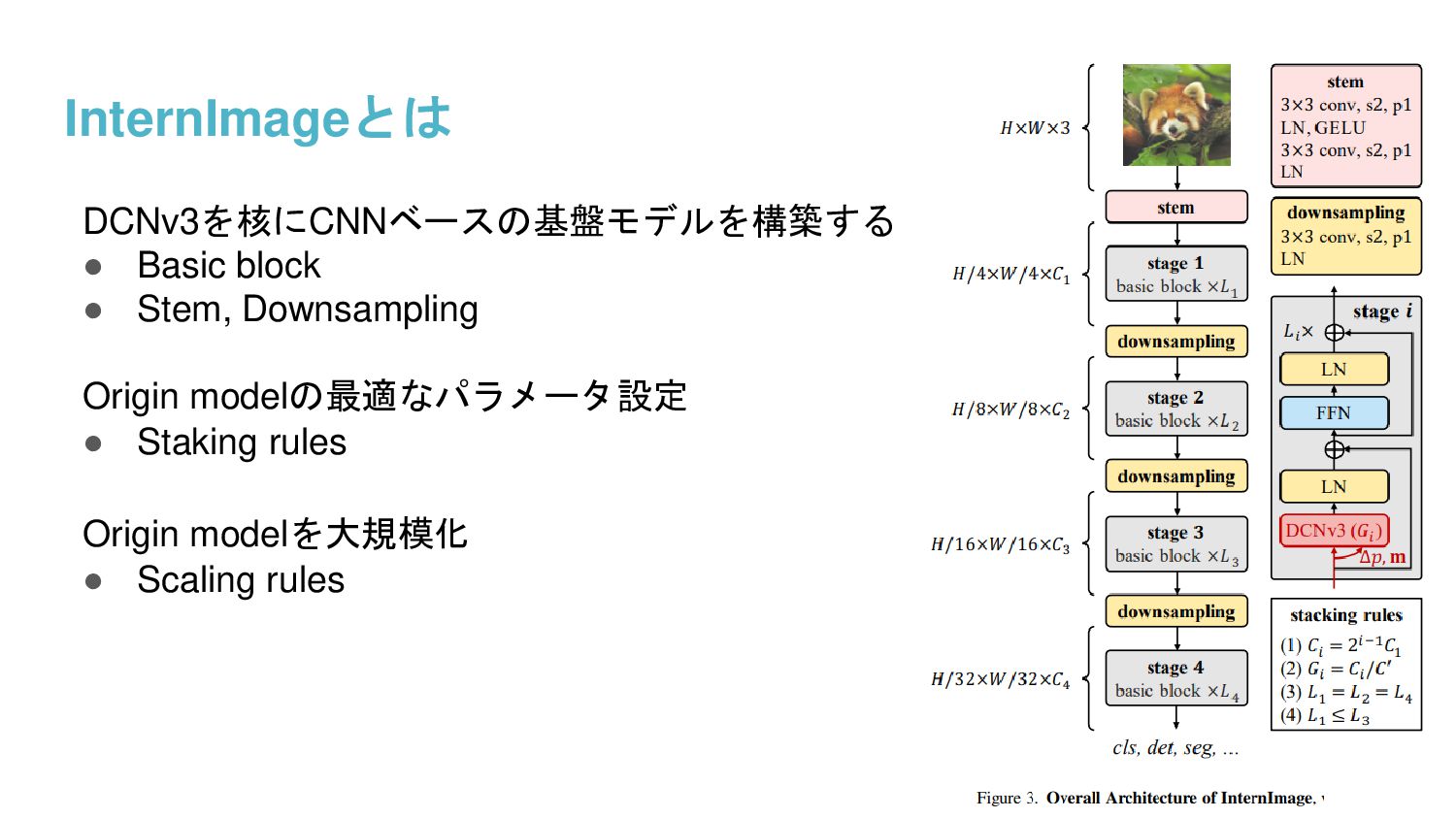{kind=link}
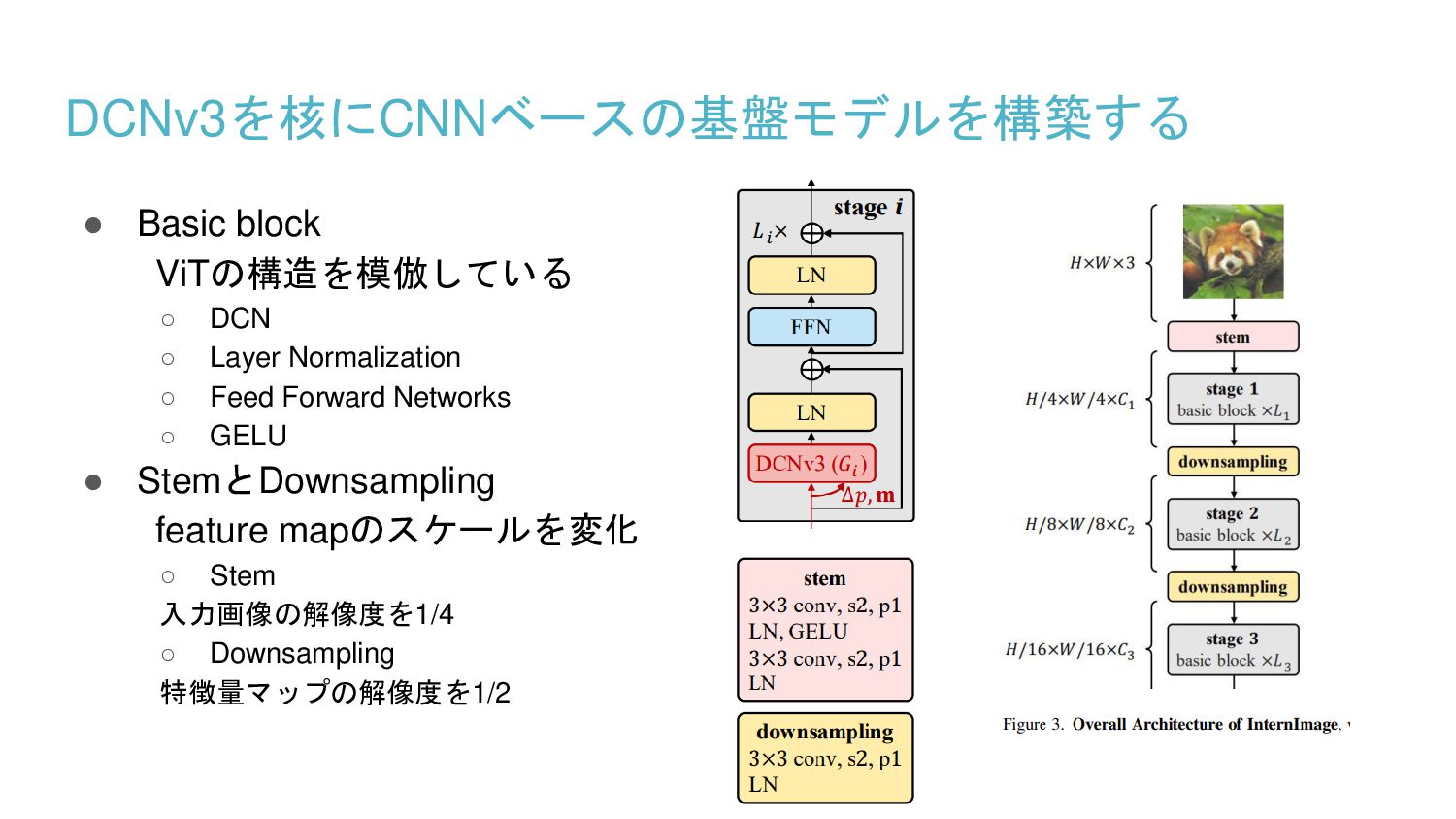{kind=link}
{kind=link}
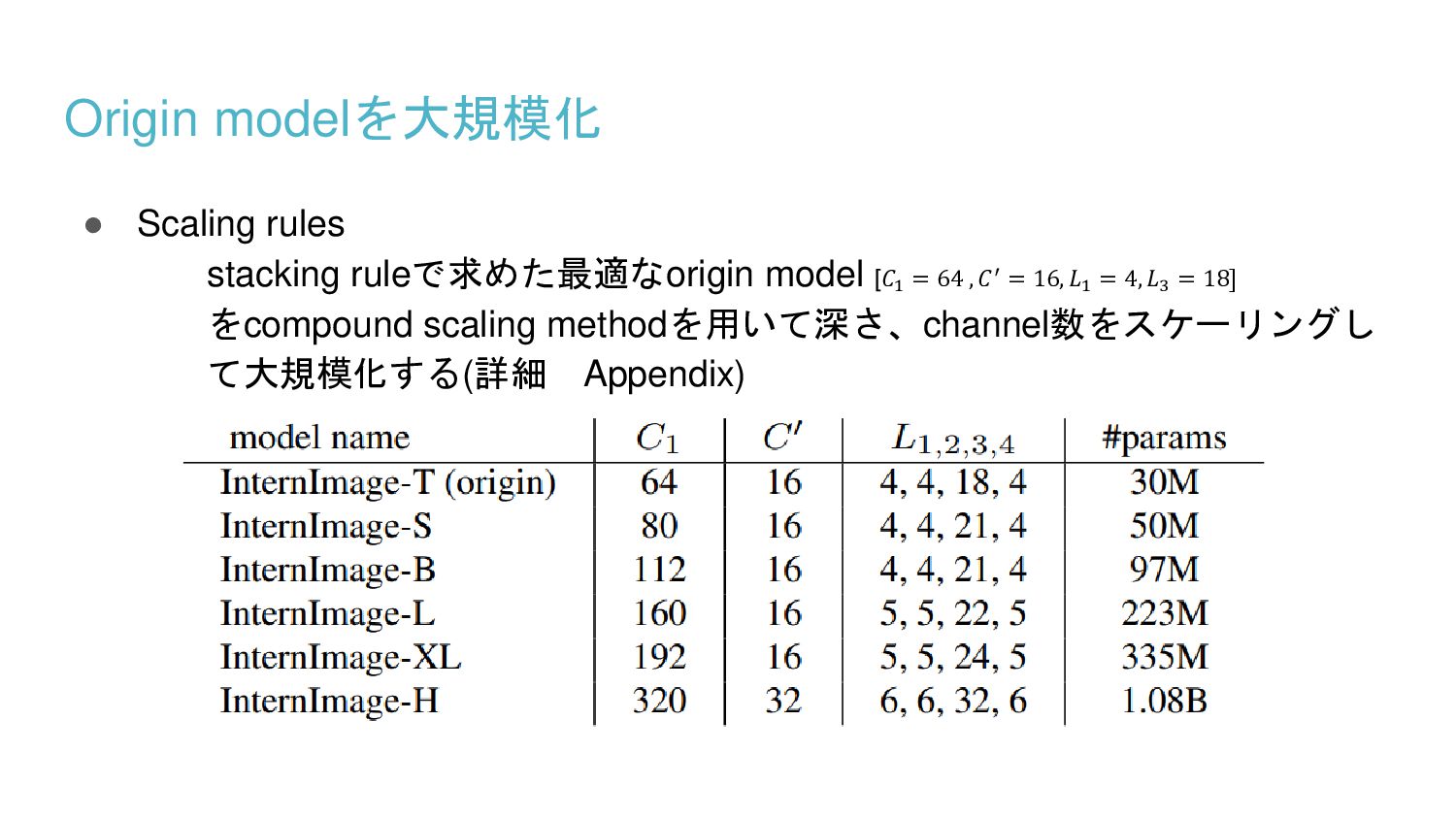{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}