Share
AcademiX が開催した 第16回 論文輪読会 資料
日時:2023/07/1 発表者:Yuta Kodaさん 論文タイトル:NeRF:Representing Scenes as Neural
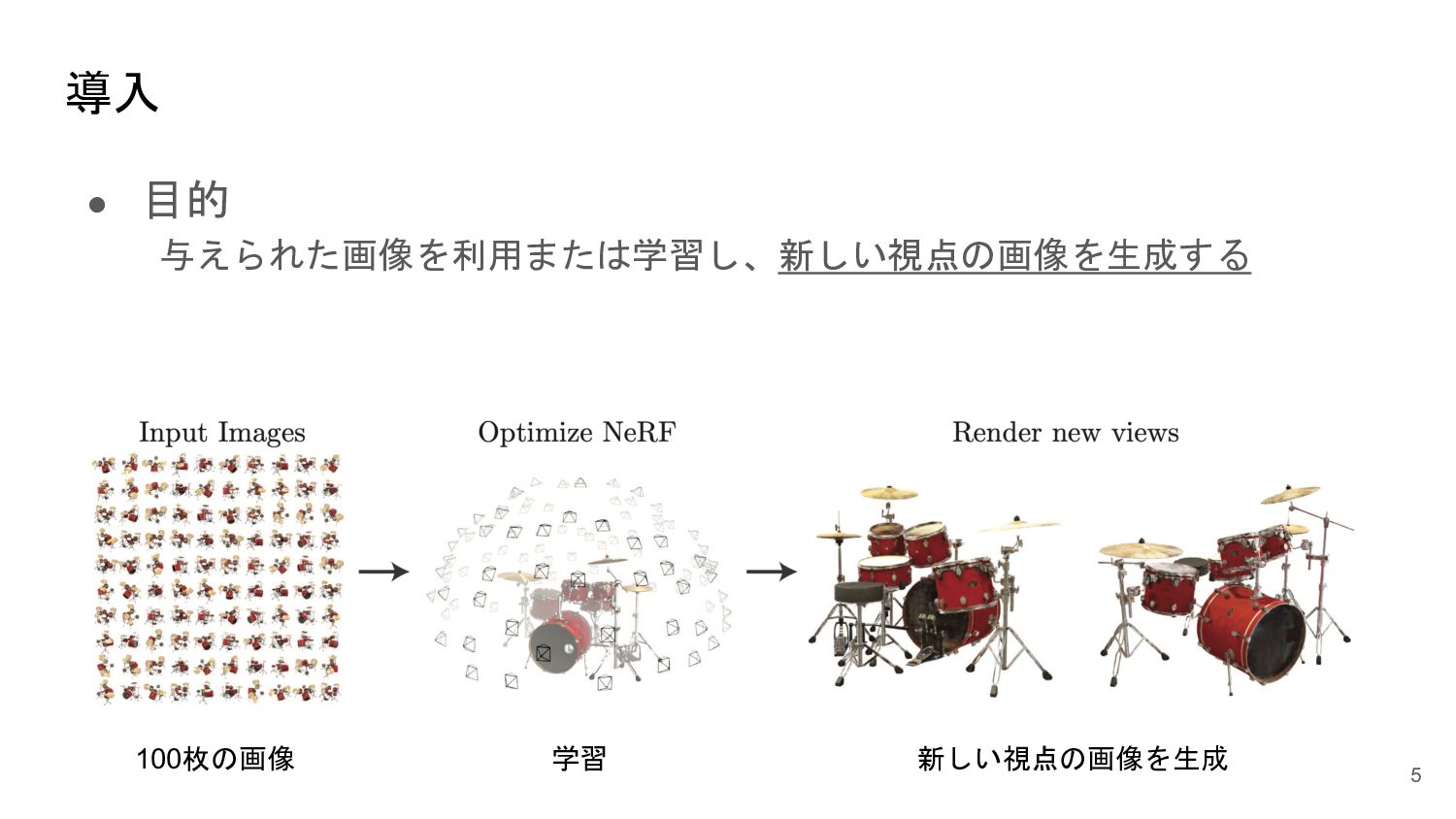
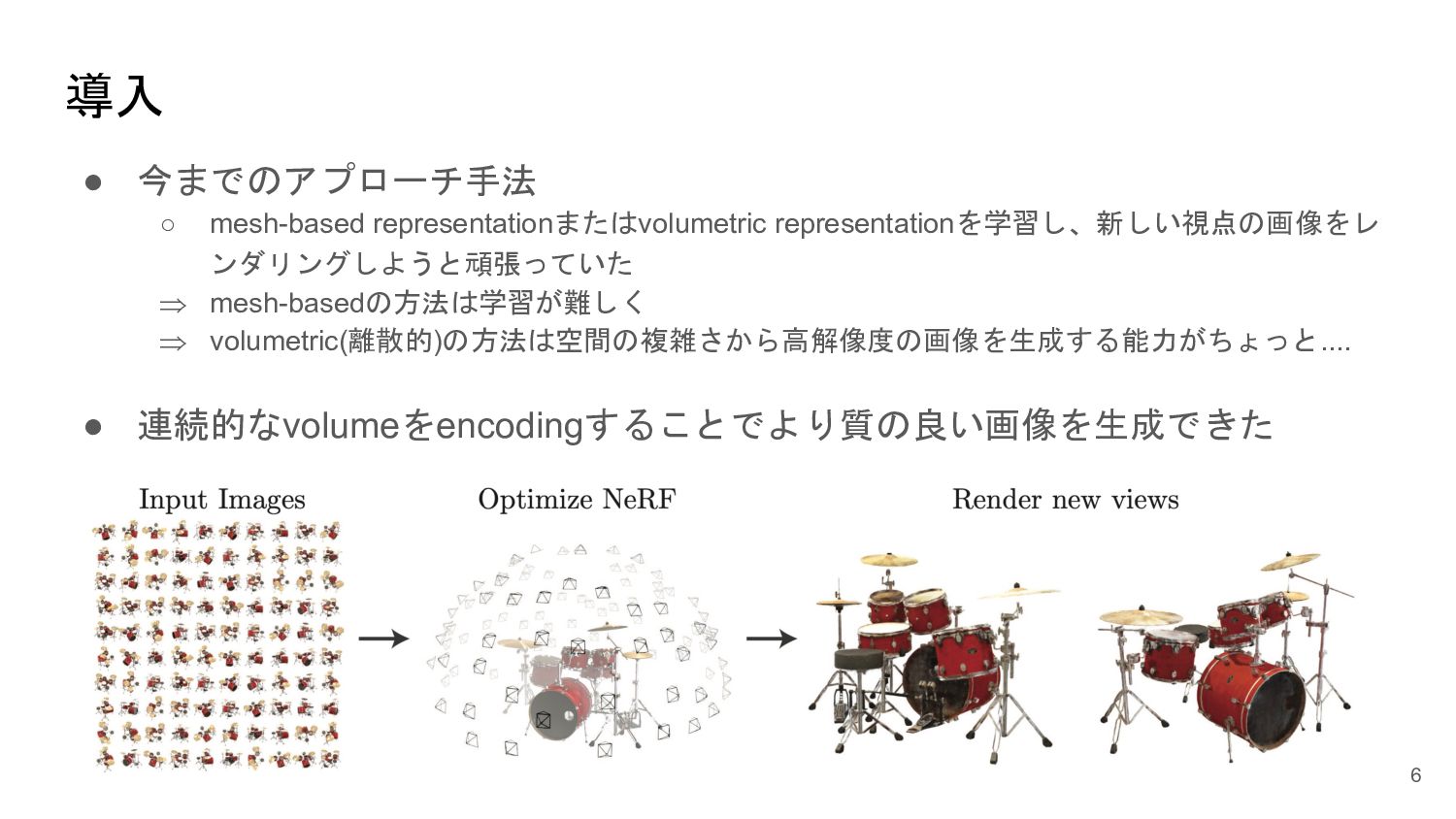
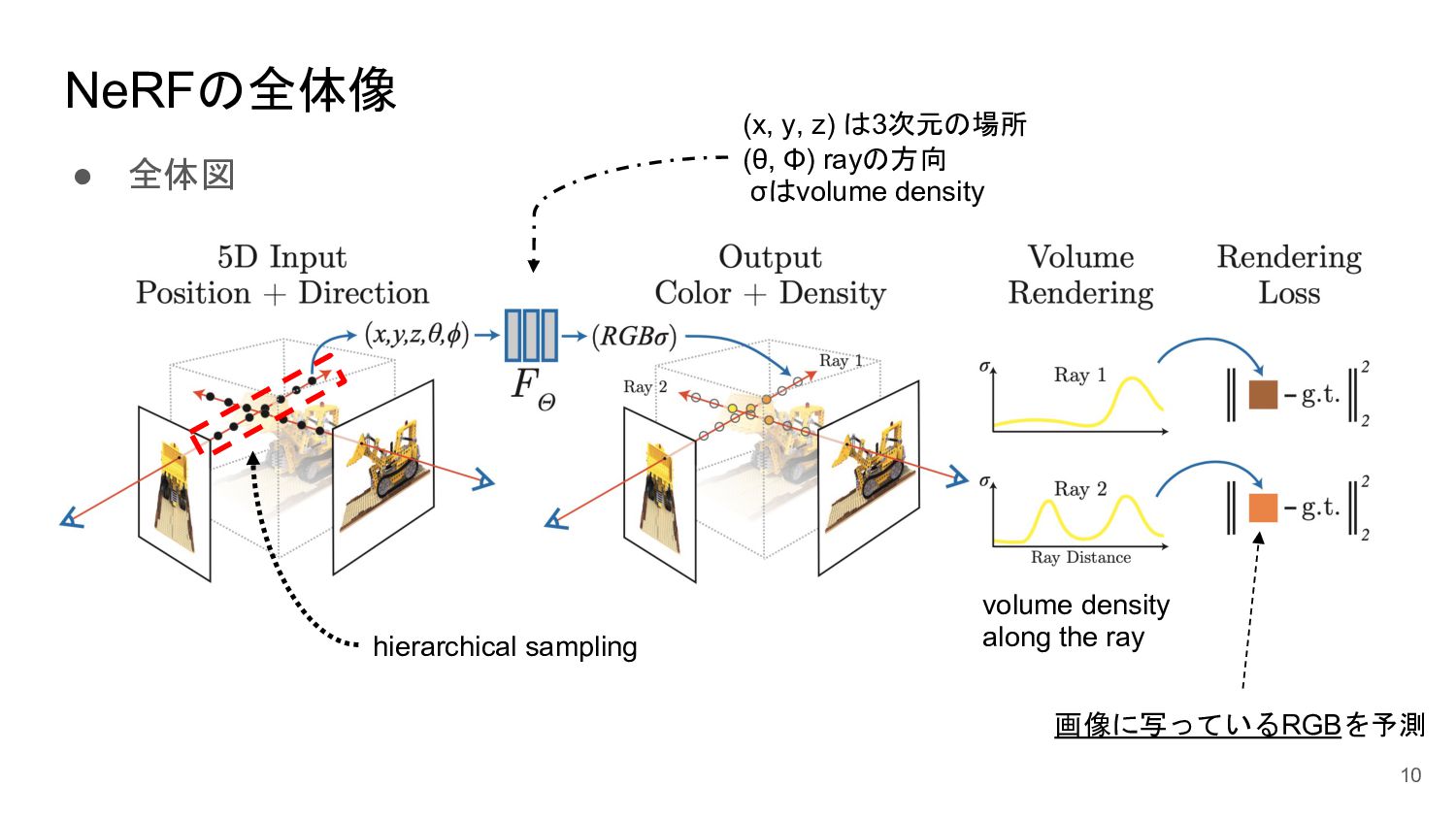
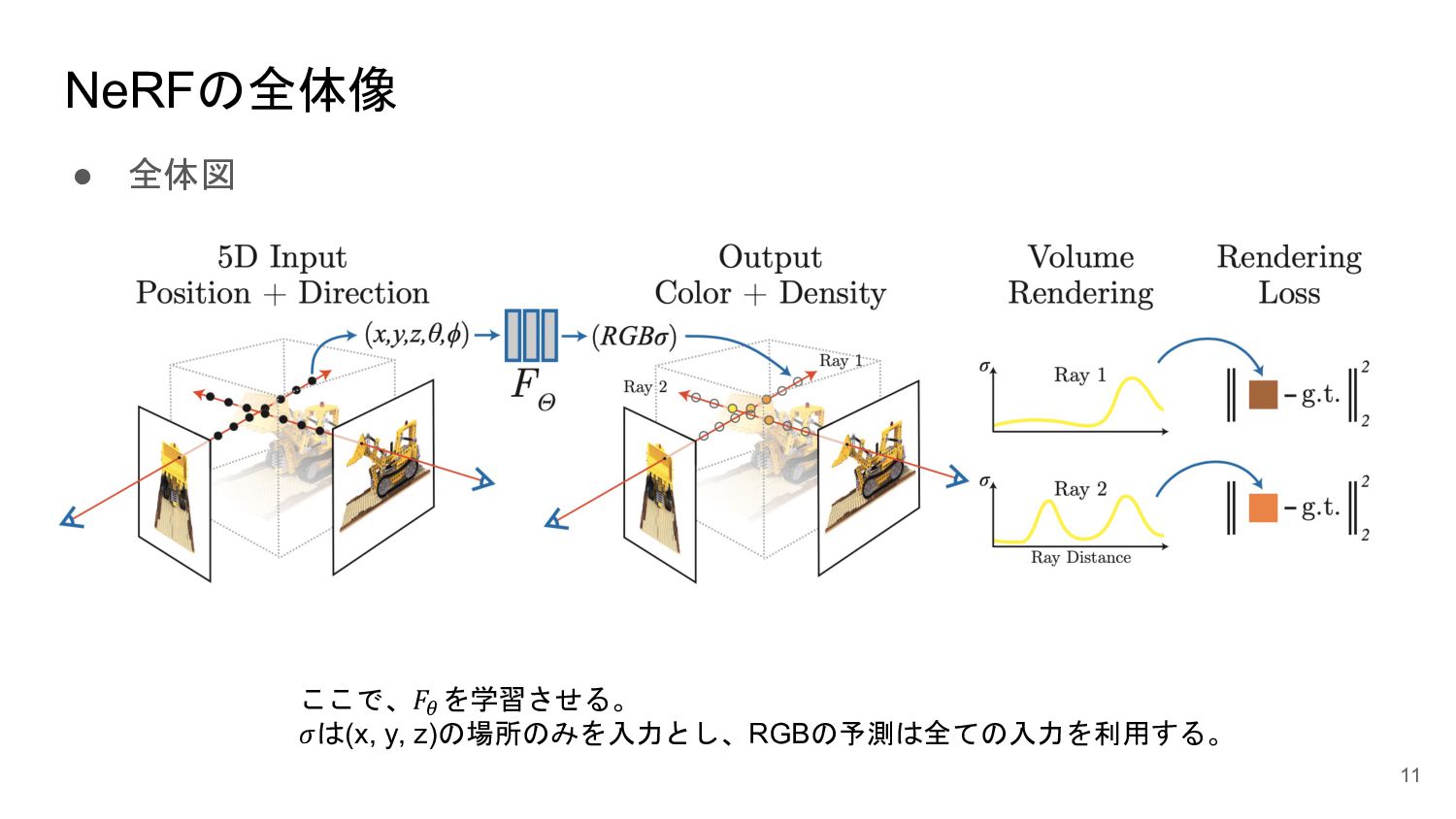
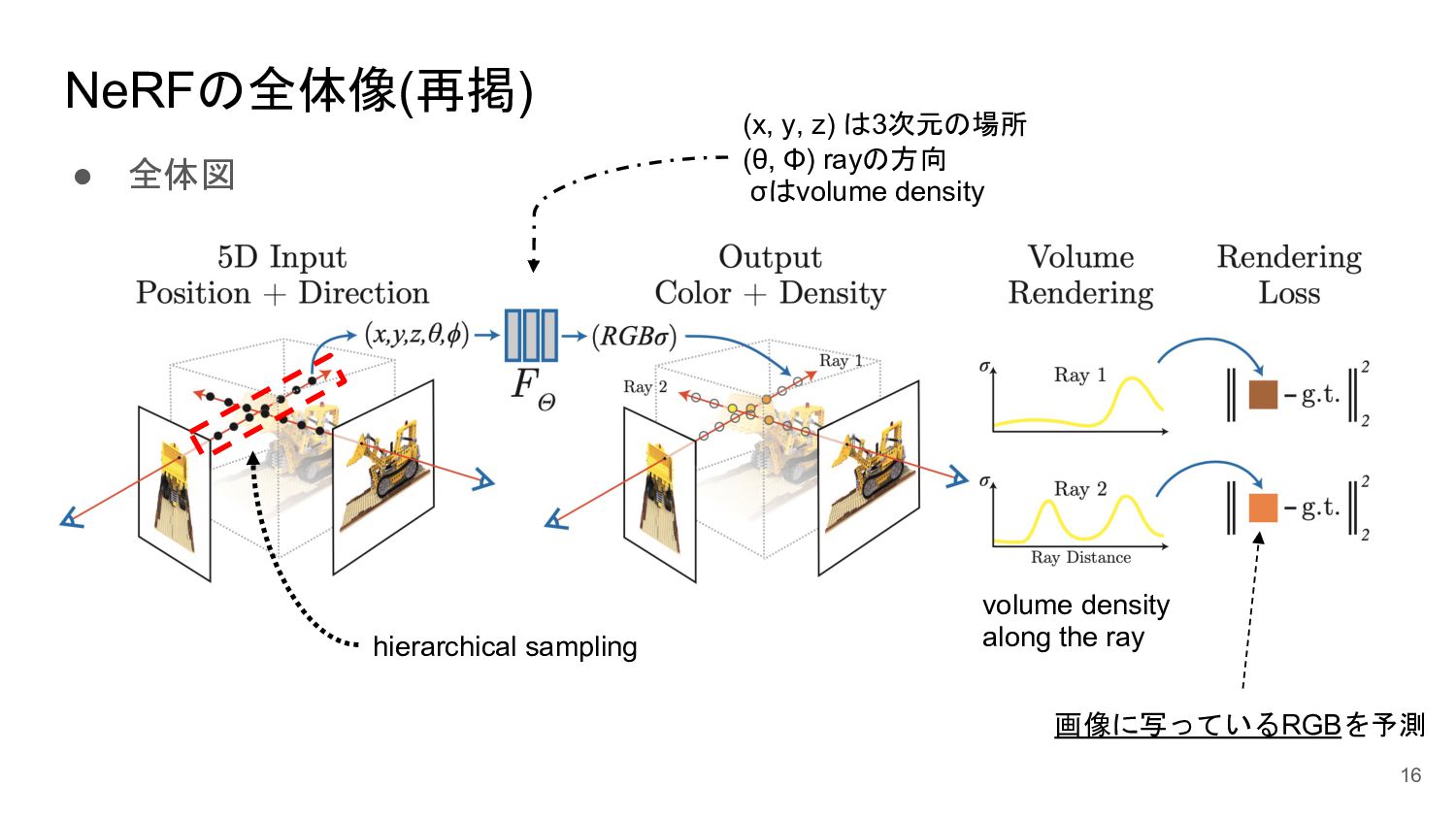
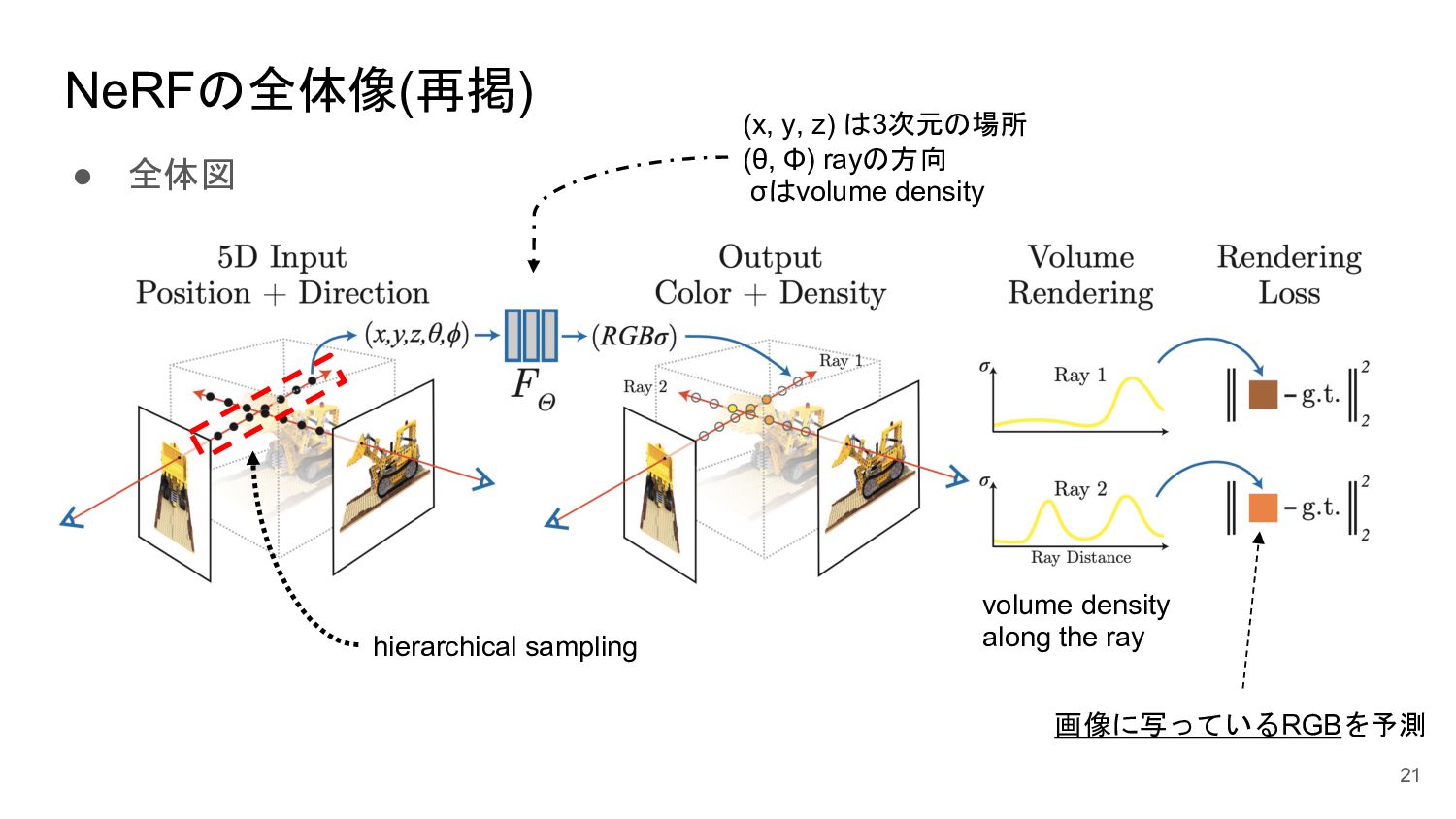
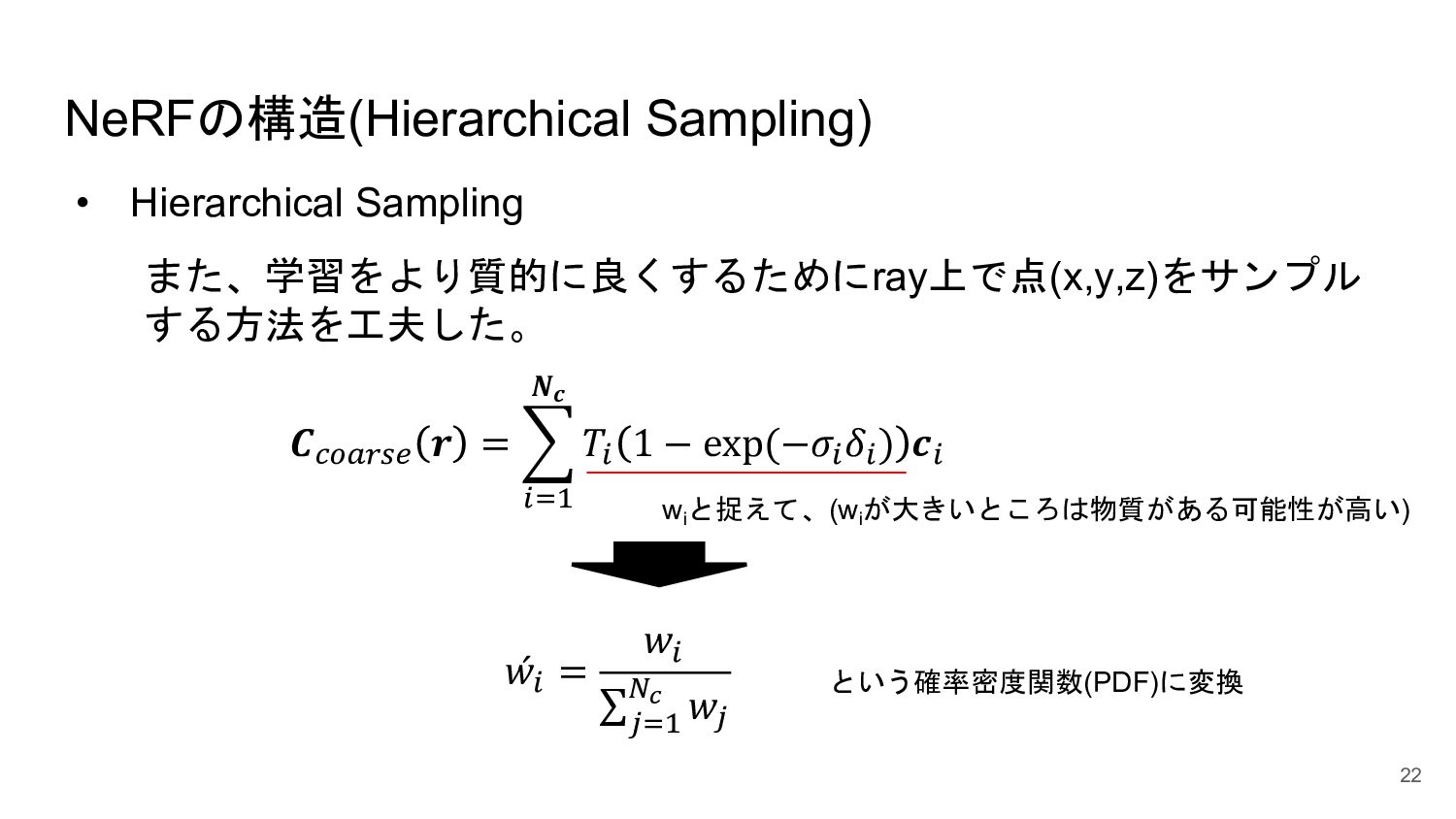
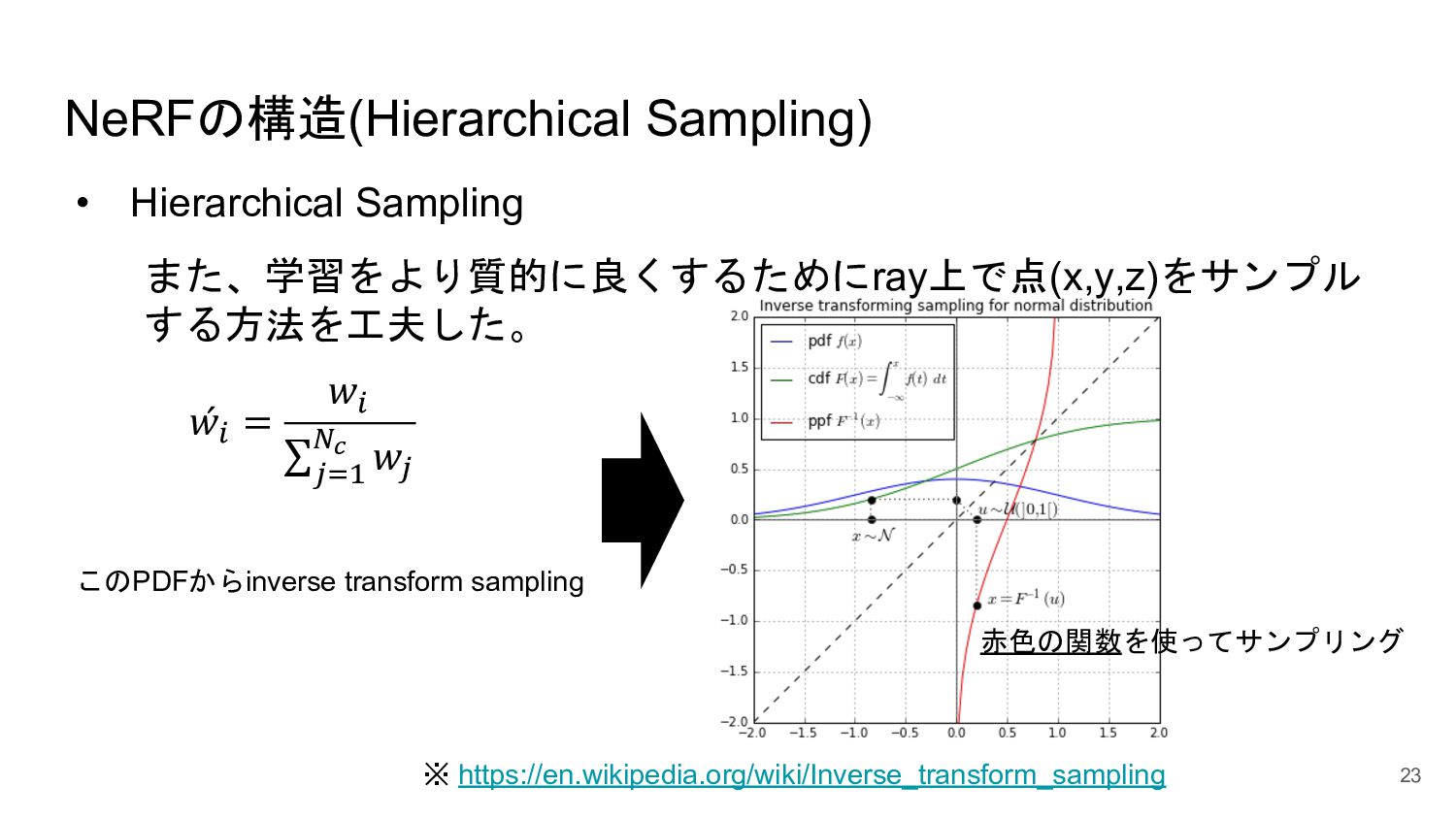
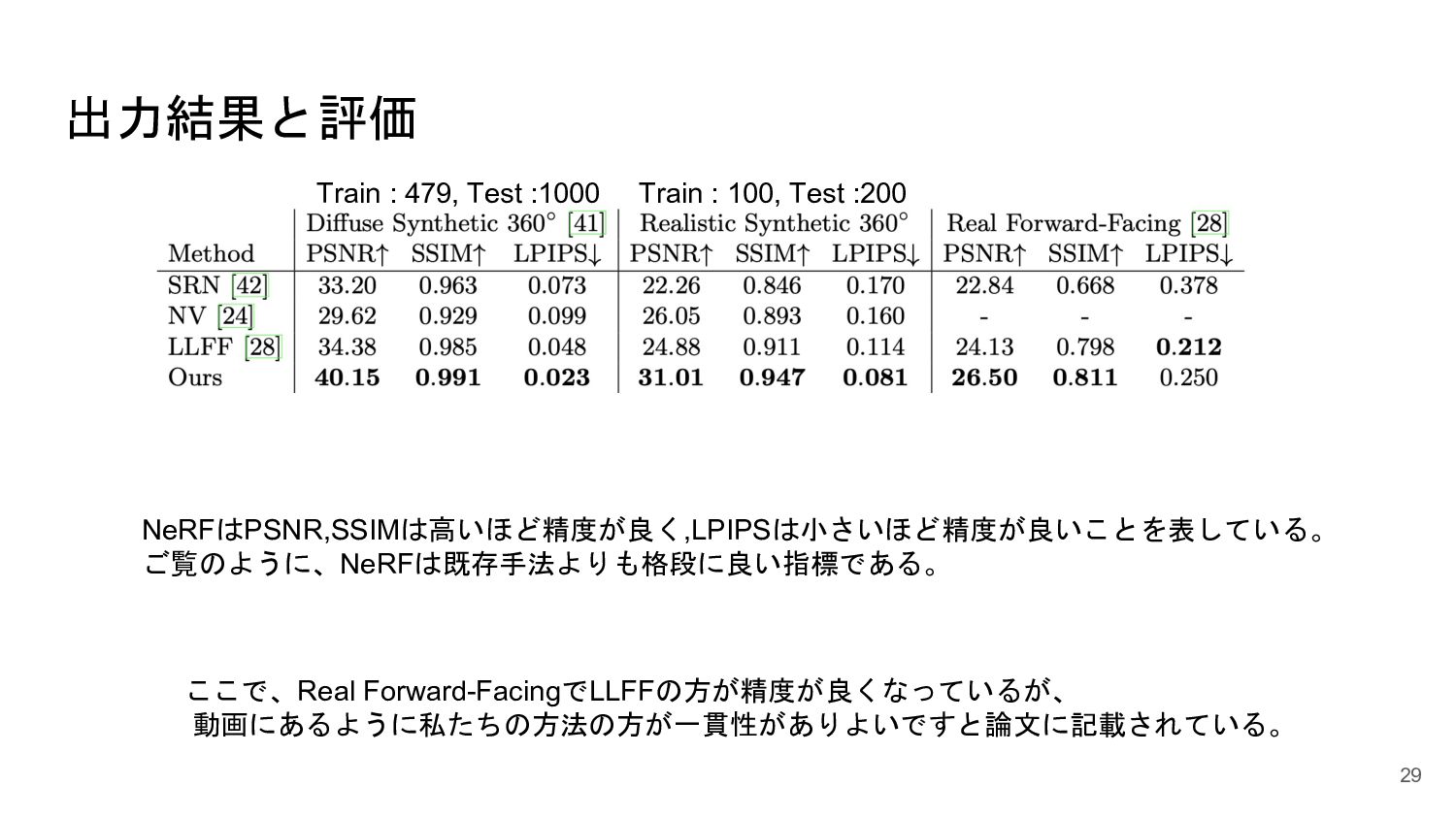
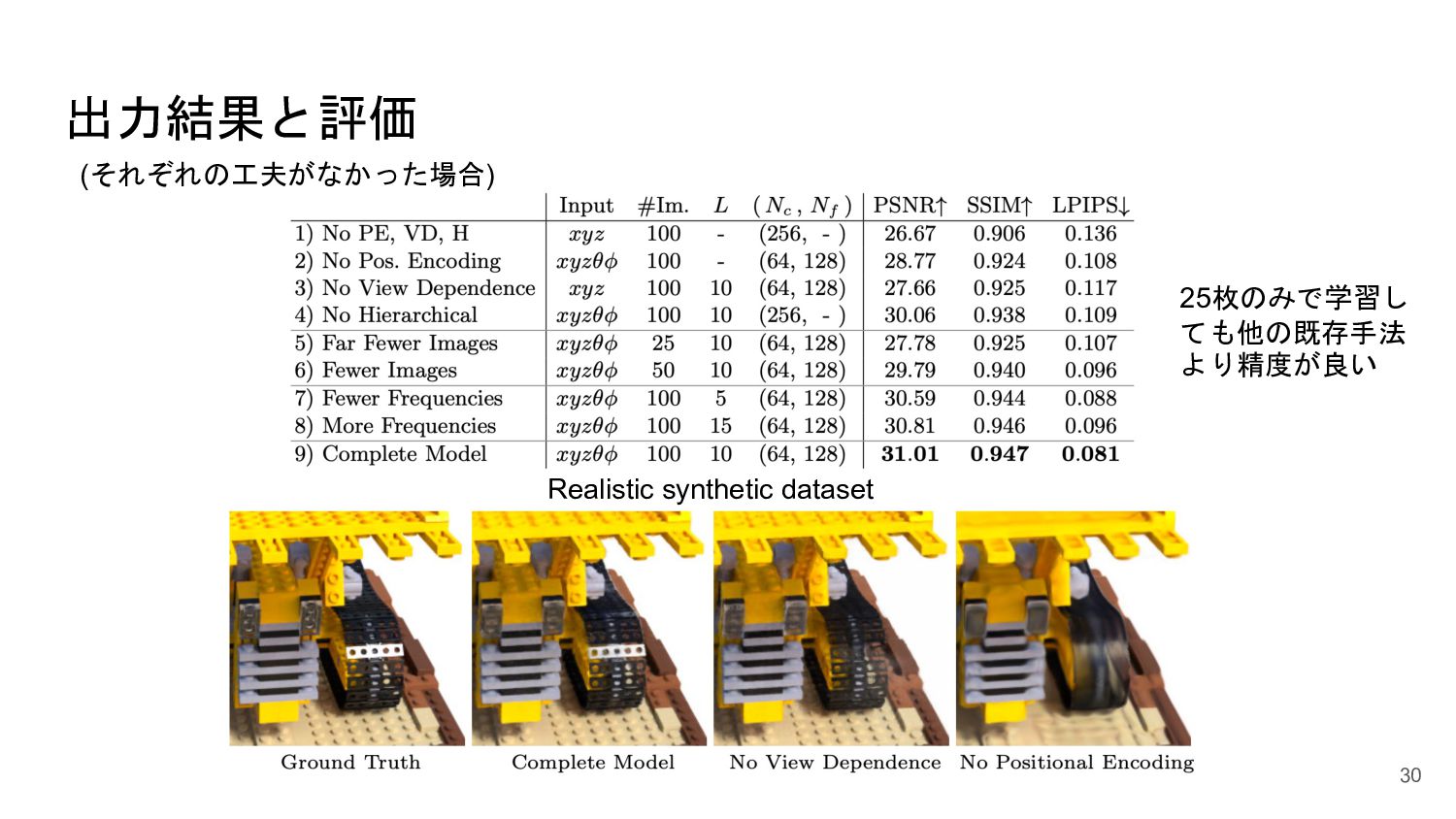
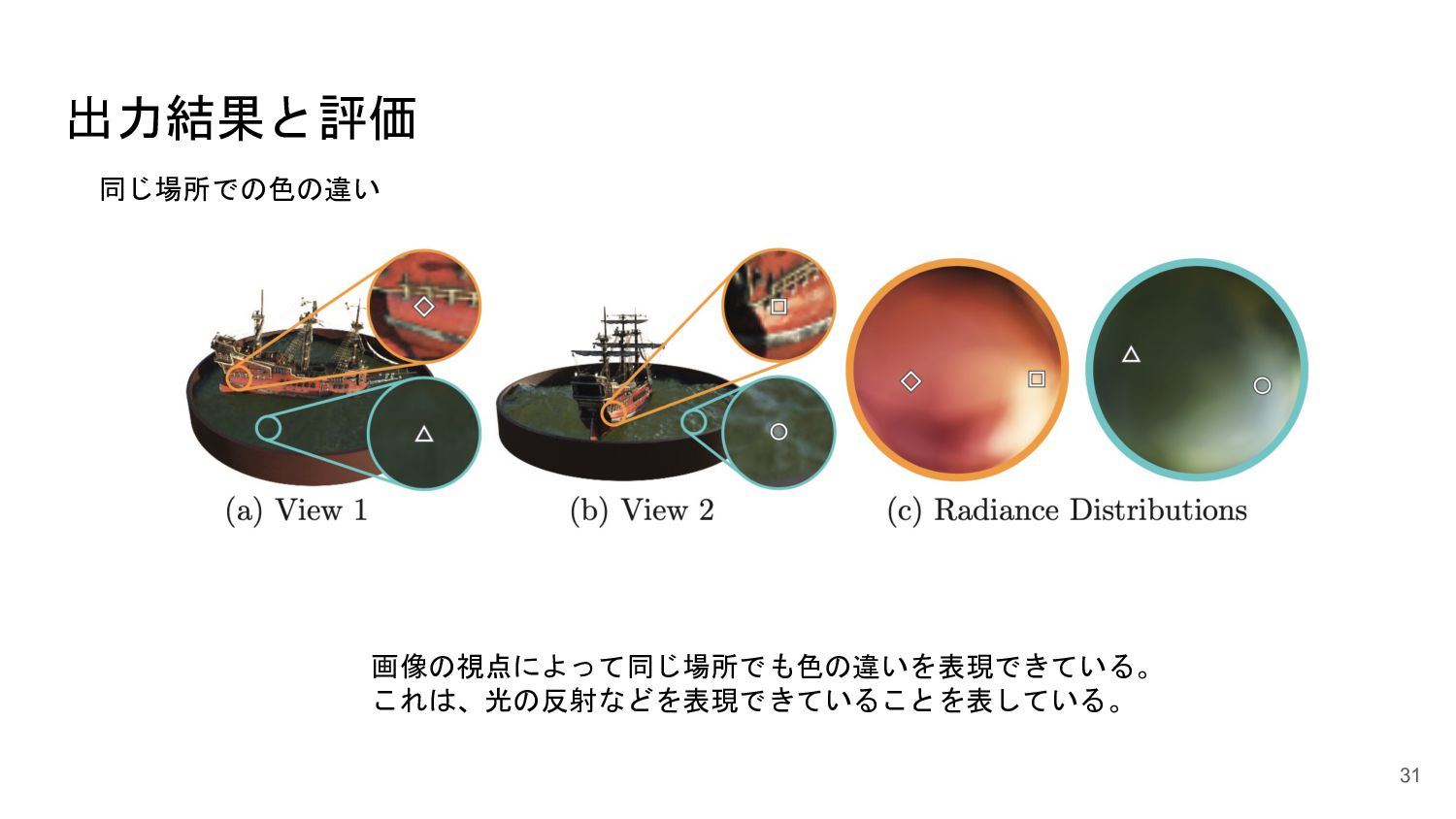
<概要> 5次元の入力(x,y,z, θ, φ)からそれぞれの点のvolume density と色を出力するNNを学習させることで、新しい視点の画像の生成やNNの重みパラメータによる3D mapの表現が可能になった。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Appendix • レンダリング画像の作成 • NDC space あるモデルを[-1, 1]の立方体の範囲に収める方法 near, far](https://files.speakerdeck.com/presentations/910fe53b45df4e509b2405be117d3dd4/slide_33.jpg){kind=link}