View Synthesis」 Author : Ben Mildenhall and Pratul P. Srinivasan and Matthew Tancik and Jonathan T. Barron and Ravi Ramamoorthi and Ren Ng year : 2020 Journal :ECCV Paper: 「Depth-supervised NeRF: Fewer Views and Faster Training for Free」 Author : Deng, Kangle and Liu, Andrew and Zhu, Jun-Yan and Ramanan, Deva year : 2022 Journal :CVPR 2 Project Page : https://www.cs.cmu.edu/~dsnerf/
of input views by learning degenerate 3D geometries. Adding depth supervision can assist NeRF to disambiguate geometry and render better novel views. • Faster Training On a single RTX A5000, a training loop of DS-NeRF takes ∼ 362.4 ms/iter while NeRF needs ∼ 359.8 ms/iter. Thus in the 5-view case, DS-NeRF achieves NeRF’s peak test PSNR around 13 hours faster. • Loss function This allows us to integrate depth supervision to many NeRF-based methods and observe significant benefits. 29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
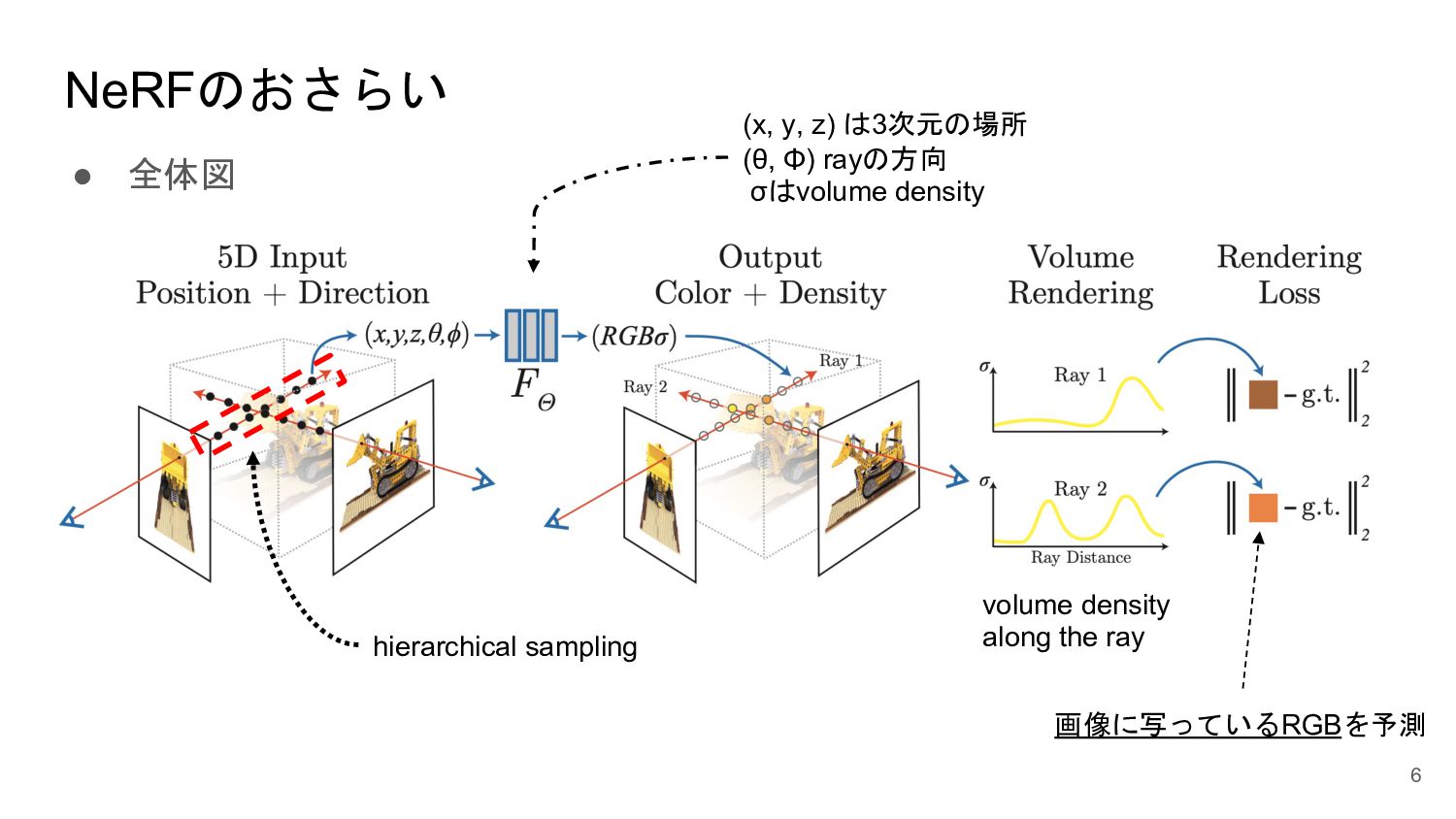{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
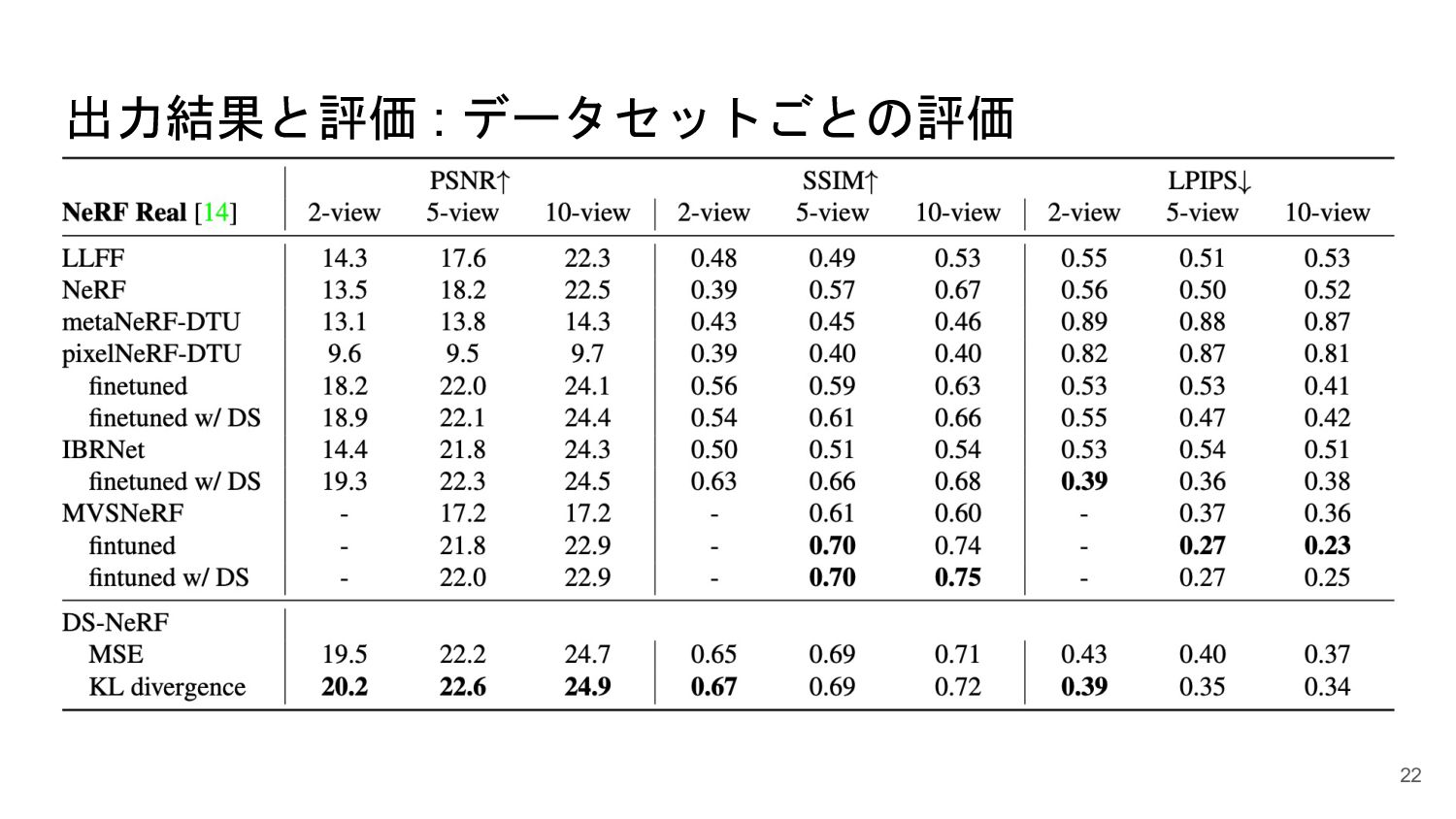{kind=link}
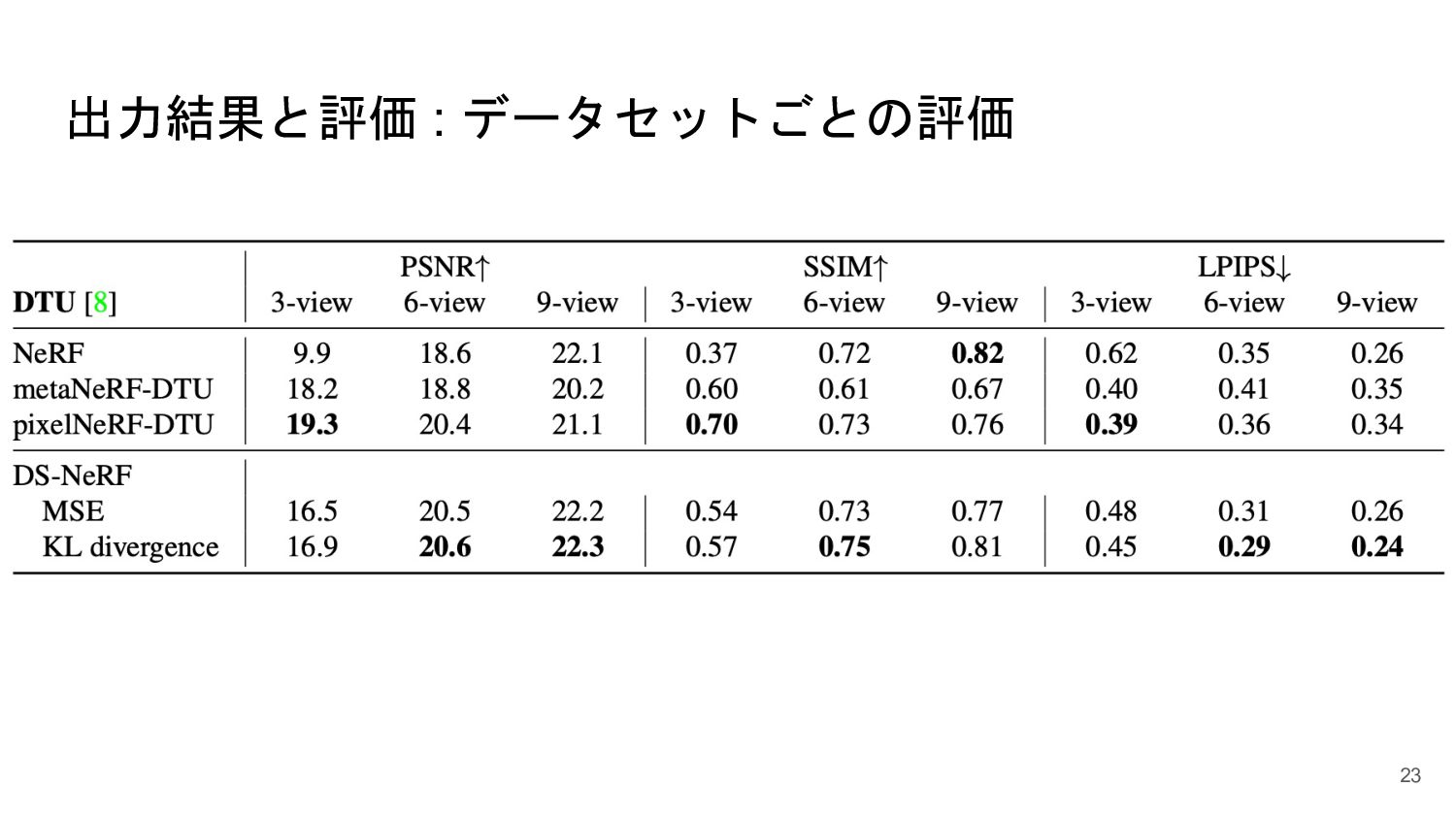{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
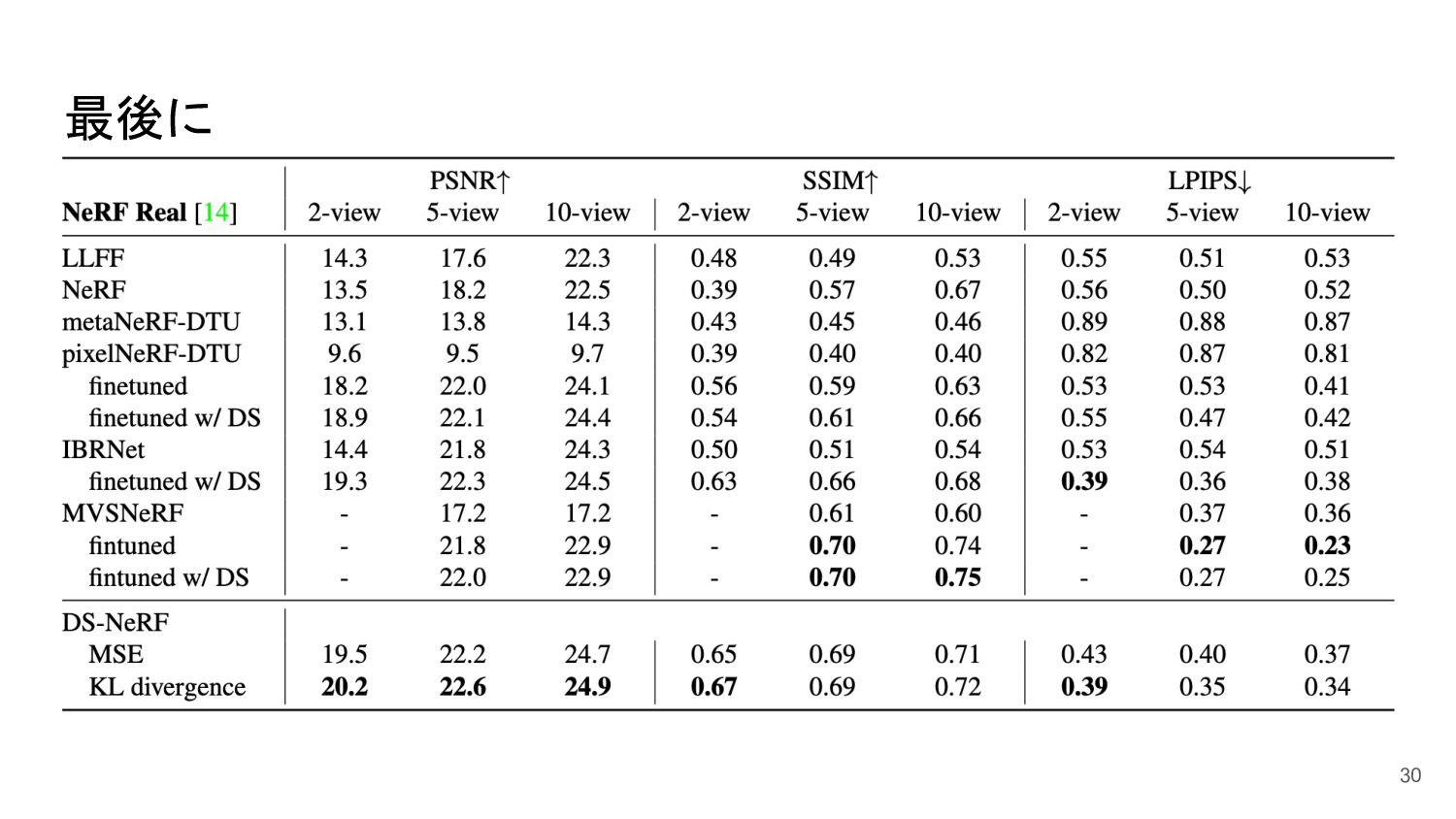{kind=link}
{kind=link}