five years now ❏ Recently working in Analytics Engineering team to improve data modeling ❏ Participating in today's event as a staff member of the venue Hobbies ❏ Watching comedy, Futsal
@Tokyo. ❏ How to predict the wind direction of tomorrow @Tokyo. This is the second time since Tokyo.R #71 that I have given a presentation in front of Hadley wickham.
dplyr notation into a modern data pipeline tool called dbt, which I have recently started using in my work. I think there are many people who have never seen dbt before, so I hope you can understand what it can do!
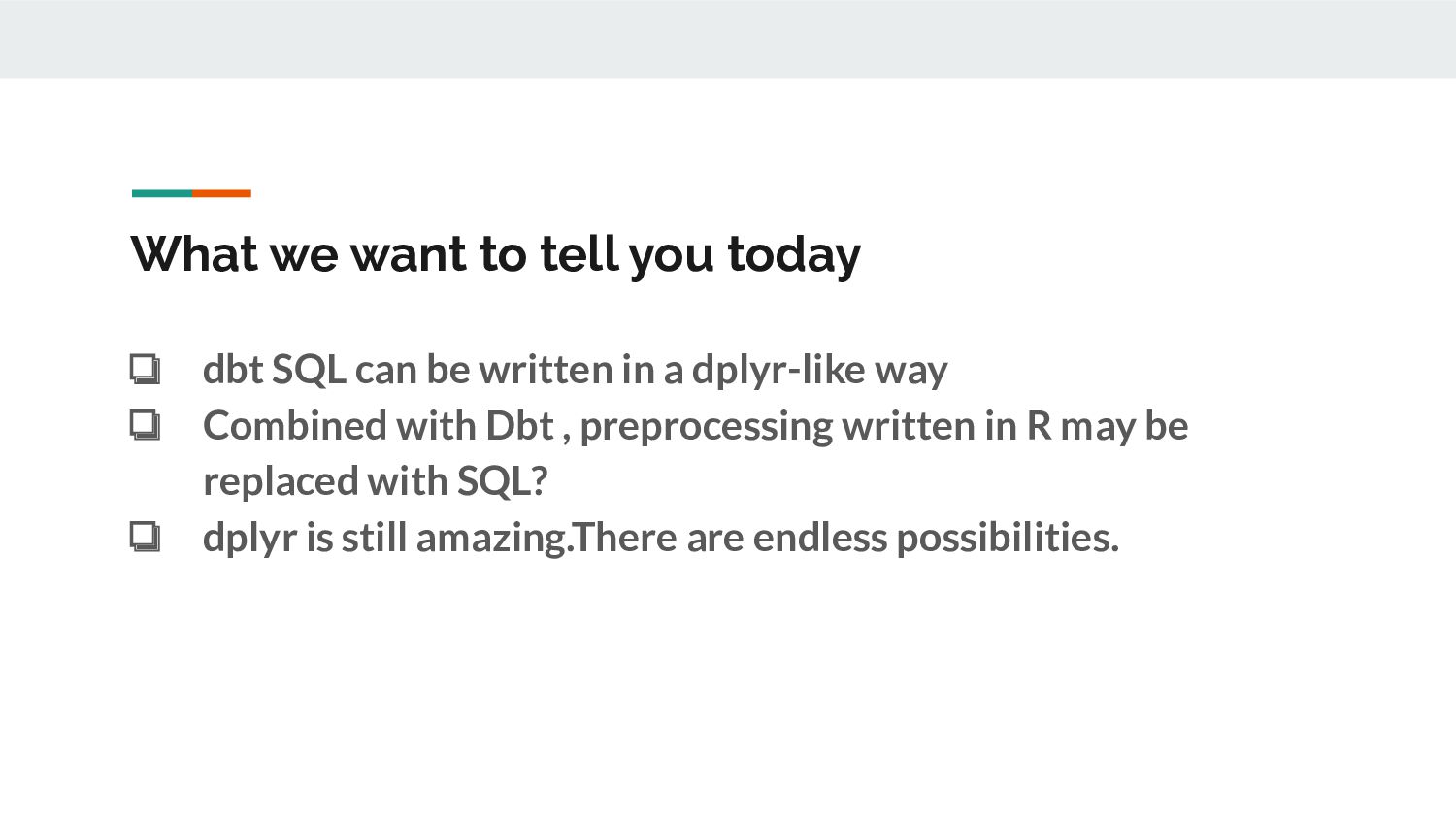
can be written in a dplyr-like way ❏ Combined with Dbt , preprocessing written in R may be replaced with SQL? ❏ dplyr is still amazing.There are endless possibilities.
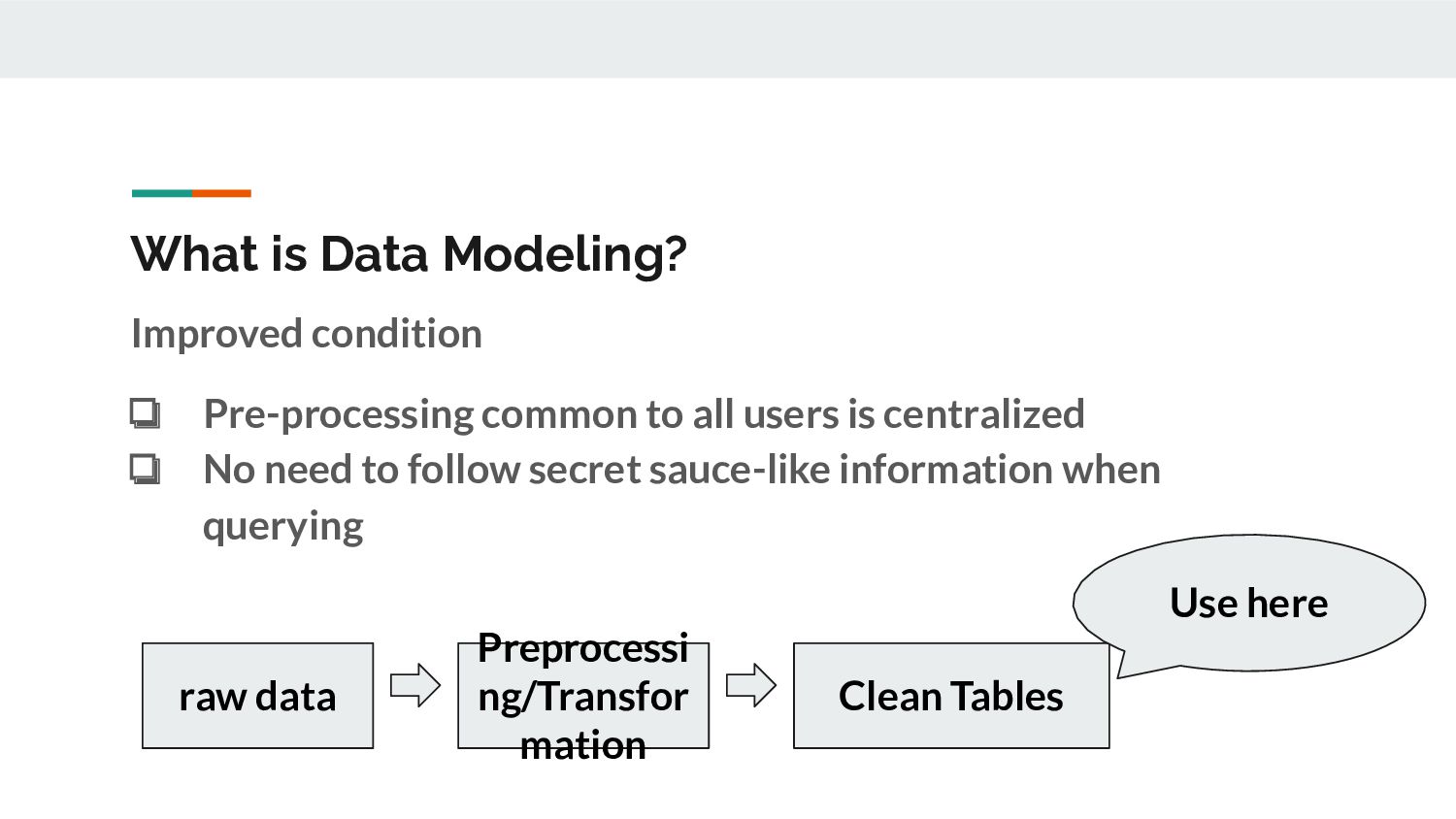
designing and building logical structures to organize data and make it easier to analyze ❏ Improve the speed and reduce the effort of analysis and querying. Centralize management of intermediate processes Example of a not-so-good situation ❏ All users are individually performing pre-processing->totalization->visualization, etc. on information similar to raw data.
template language used in Python ❏ Easy to implement data modeling and full documentation and visualization of the process ❏ There is a function called "macro", which allows for processing that would be difficult to perform using SQL alone.
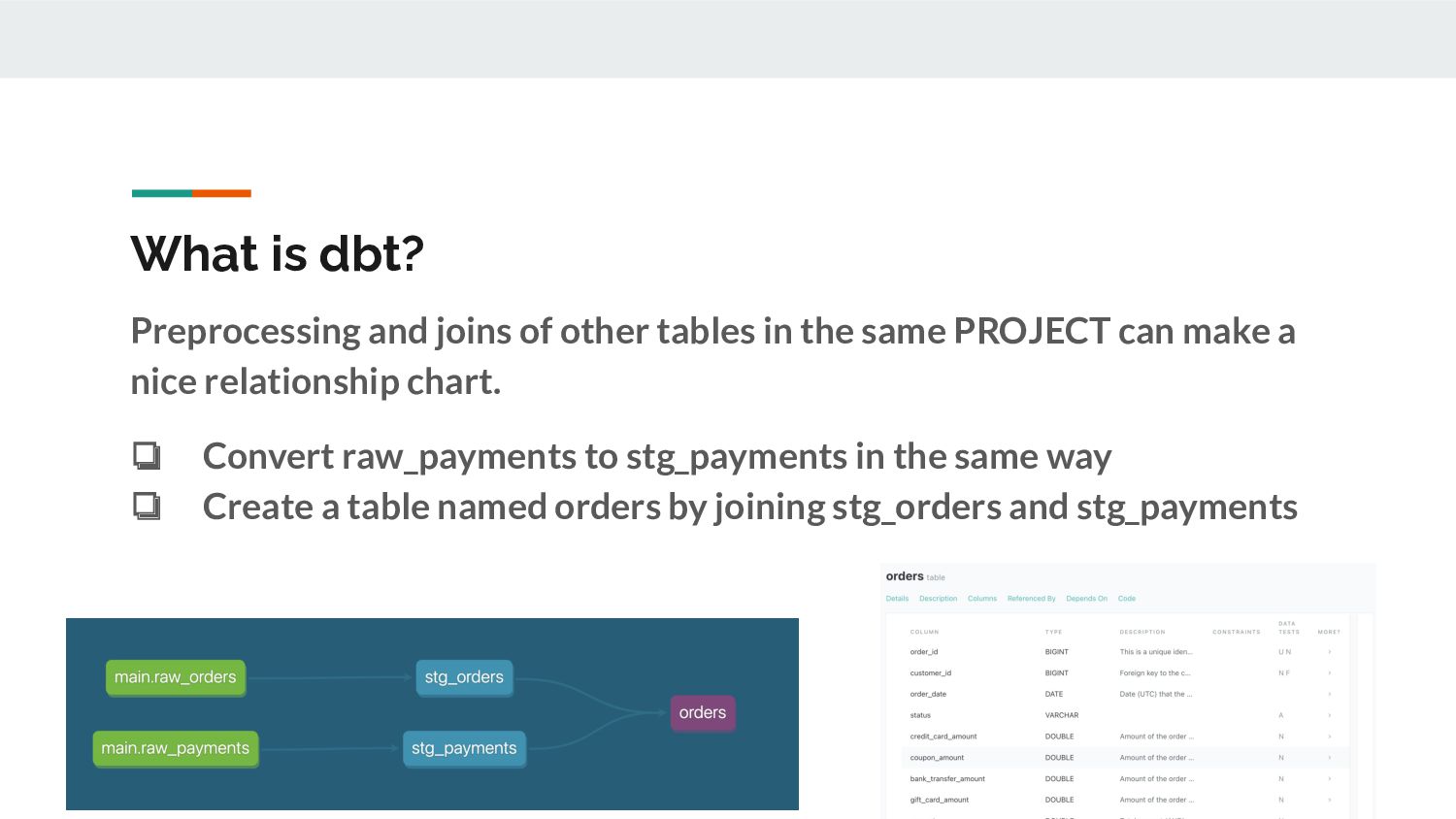
{{ source('main', 'raw_orders') }} select id as order_id, user_id as customer_id, order_date, status from "tutorial"."main"."raw_orders" What is dbt? ❏ When you create the query shown on the left as stg_orders.sql and run dbt, the appropriate DB and table are referenced from the configuration. ❏ From the query, you can visualize the dependency of the process "stg_orders was created by referencing raw_orders".
the same PROJECT can make a nice relationship chart. ❏ Convert raw_payments to stg_payments in the same way ❏ Create a table named orders by joining stg_orders and stg_payments
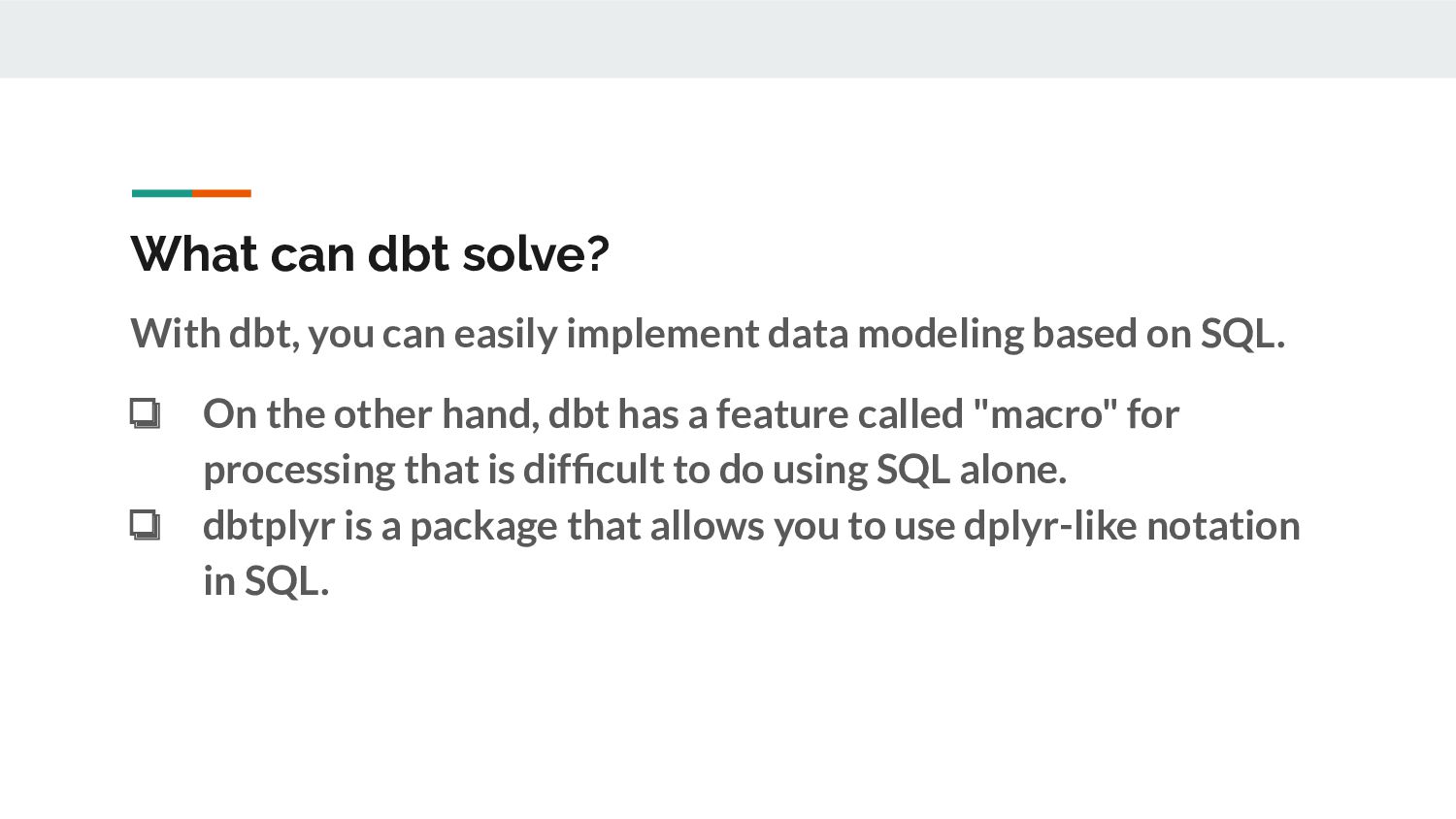
data modeling based on SQL. ❏ On the other hand, dbt has a feature called "macro" for processing that is difficult to do using SQL alone. ❏ dbtplyr is a package that allows you to use dplyr-like notation in SQL.
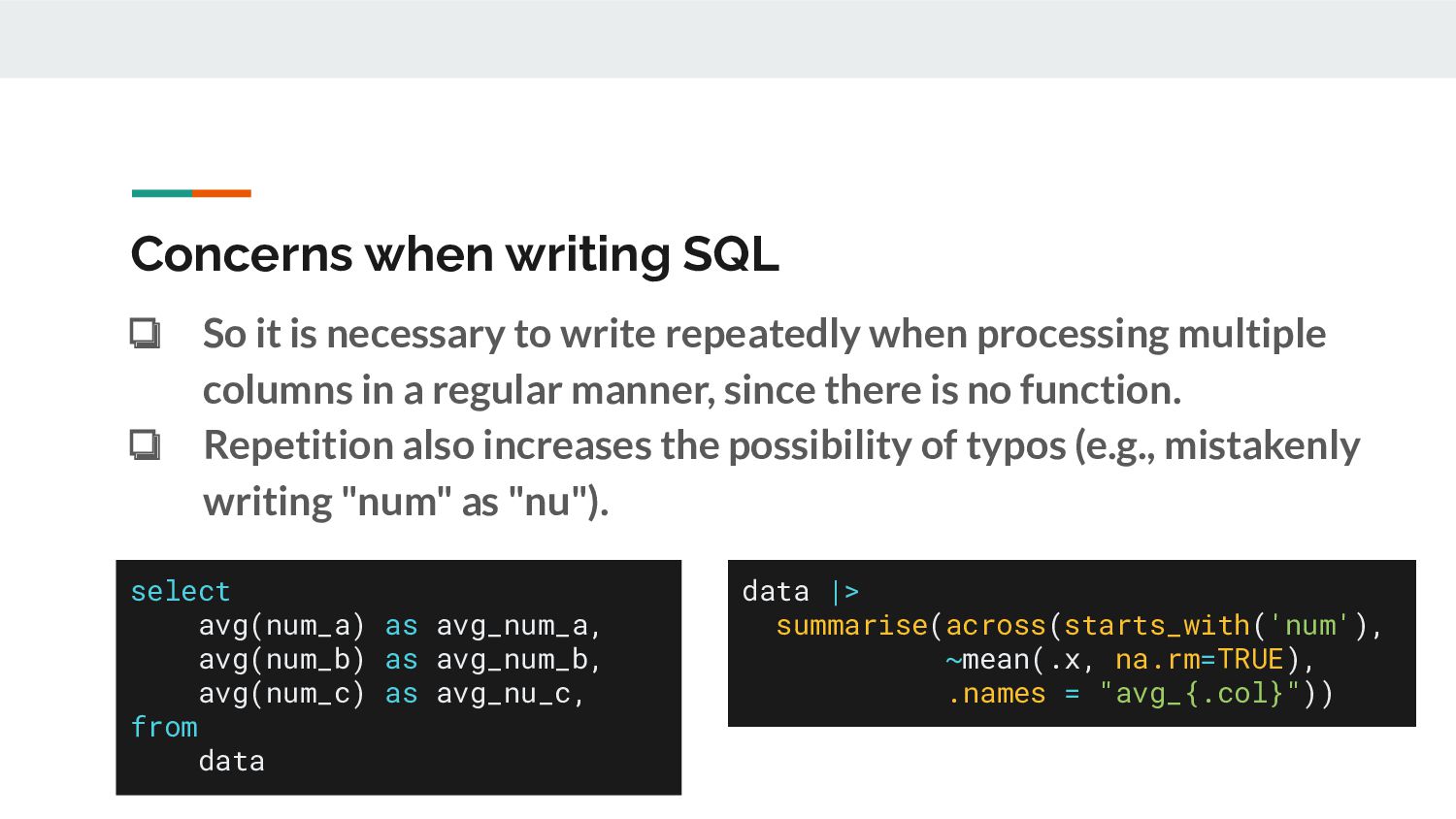
from data data |> summarise(across(starts_with('num'), ~mean(.x, na.rm=TRUE), .names = "avg_{.col}")) Concerns when writing SQL ❏ So it is necessary to write repeatedly when processing multiple columns in a regular manner, since there is no function. ❏ Repetition also increases the possibility of typos (e.g., mistakenly writing "num" as "nu").
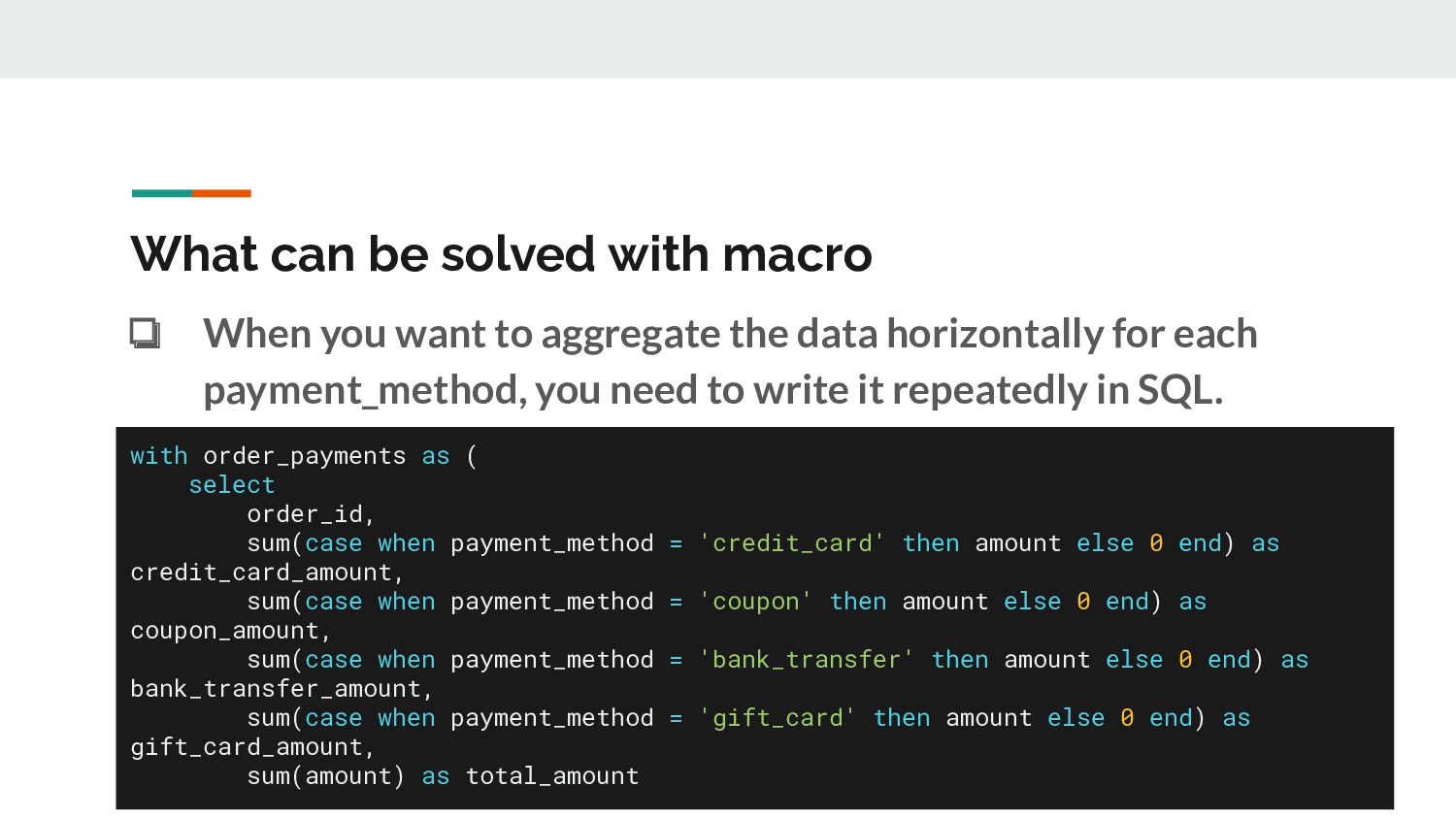
'credit_card' then amount else 0 end) as credit_card_amount, sum(case when payment_method = 'coupon' then amount else 0 end) as coupon_amount, sum(case when payment_method = 'bank_transfer' then amount else 0 end) as bank_transfer_amount, sum(case when payment_method = 'gift_card' then amount else 0 end) as gift_card_amount, sum(amount) as total_amount What can be solved with macro ❏ When you want to aggregate the data horizontally for each payment_method, you need to write it repeatedly in SQL.
order_payments as ( select order_id, {% for payment_method in payment_methods -%} sum(case when payment_method = '{{ payment_method }}' then amount else 0 end) as {{ payment_method }}_amount, {% endfor -%} sum(amount) as total_amount What can be solved with macro ❏ dbt's macro can be used to generalize for loop and processing
%} {% macro calculate_method_amounts(payment_methods, amount_column='amount', payment_method_column='payment_method') %} {% for payment_method in payment_methods -%} sum(case when {{ payment_method_column }} = '{{ payment_method }}' then {{ amount_column }} else 0 end) as {{ payment_method }}_amount, {% endfor -%} {% endmacro %} What can be solved with macro ❏ macro as a function and can be used in other queries (e.g. macro/util.sql)
to implement dplyr-like notation in dbt macro. ❏ A package developed by Emily Riederer , whose X profile also conveys her love of R "Three R's in my last name, but it's not enough #rstats for me!"
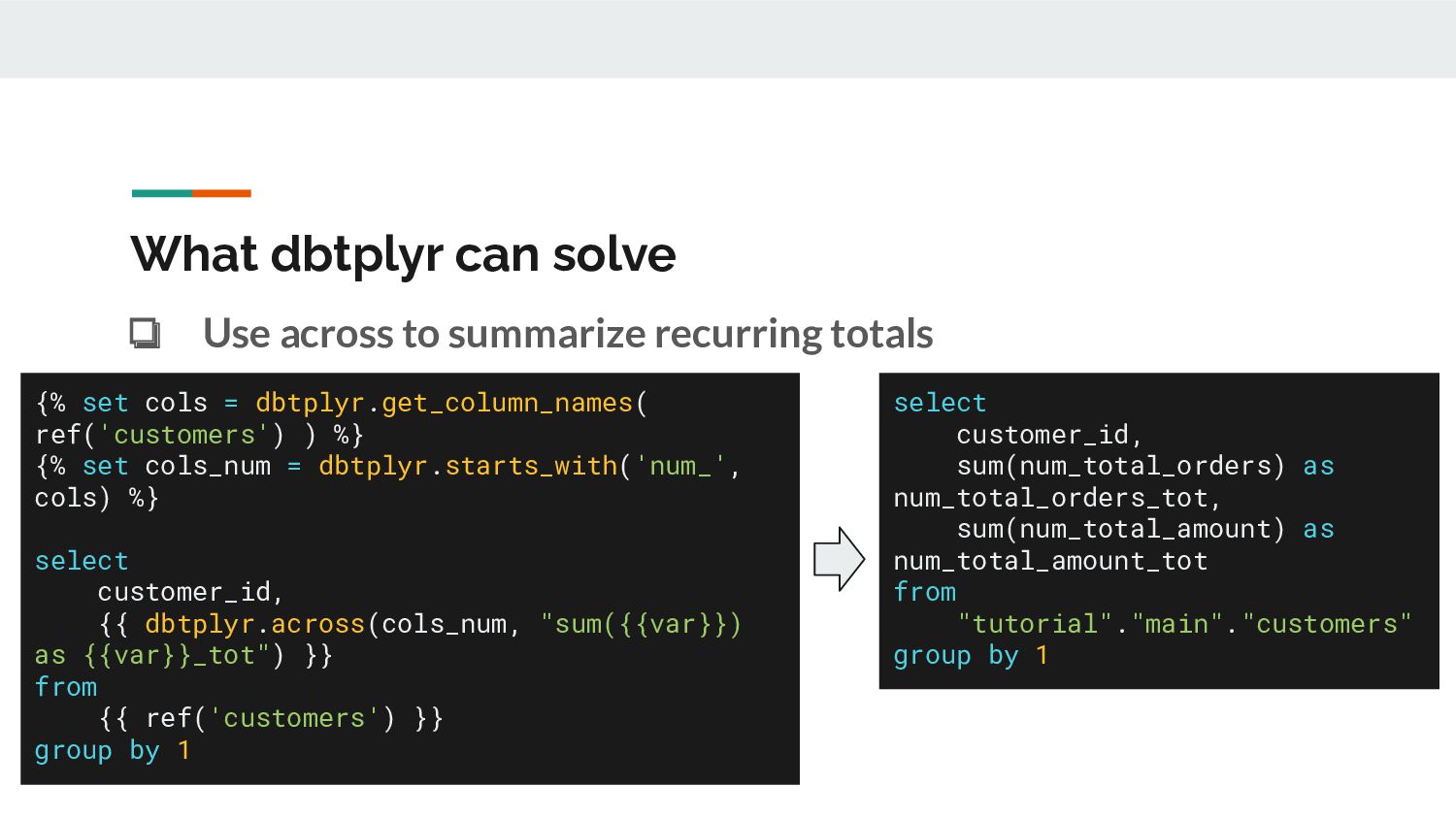
cols_num = dbtplyr.starts_with('num_', cols) %} select customer_id, {{ dbtplyr.across(cols_num, "sum({{var}}) as {{var}}_tot") }} from {{ ref('customers') }} group by 1 select customer_id, sum(num_total_orders) as num_total_orders_tot, sum(num_total_amount) as num_total_amount_tot from "tutorial"."main"."customers" group by 1 What dbtplyr can solve ❏ Use across to summarize recurring totals
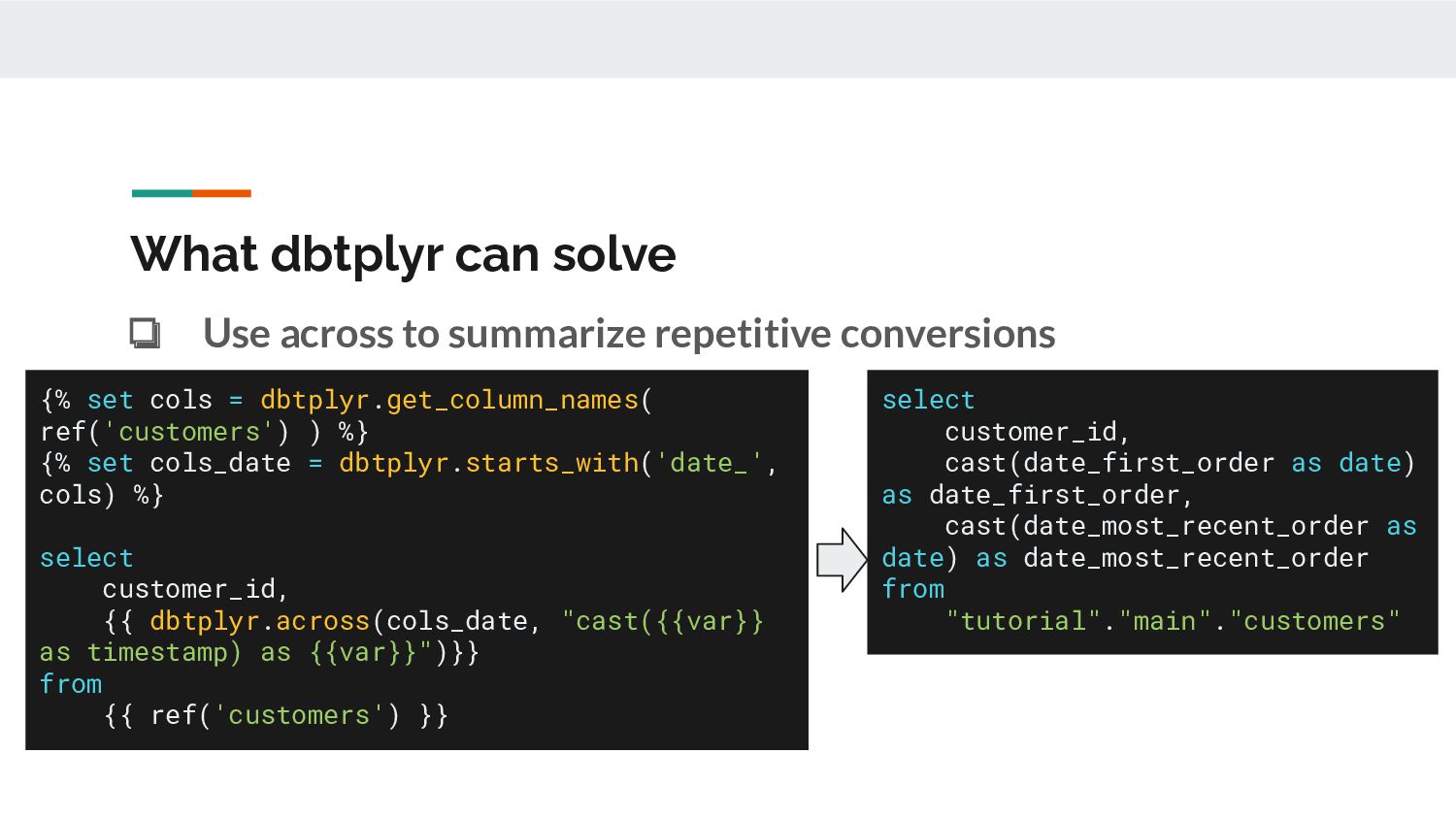
cols_date = dbtplyr.starts_with('date_', cols) %} select customer_id, {{ dbtplyr.across(cols_date, "cast({{var}} as timestamp) as {{var}}")}} from {{ ref('customers') }} select customer_id, cast(date_first_order as date) as date_first_order, cast(date_most_recent_order as date) as date_most_recent_order from "tutorial"."main"."customers" What dbtplyr can solve ❏ Use across to summarize repetitive conversions
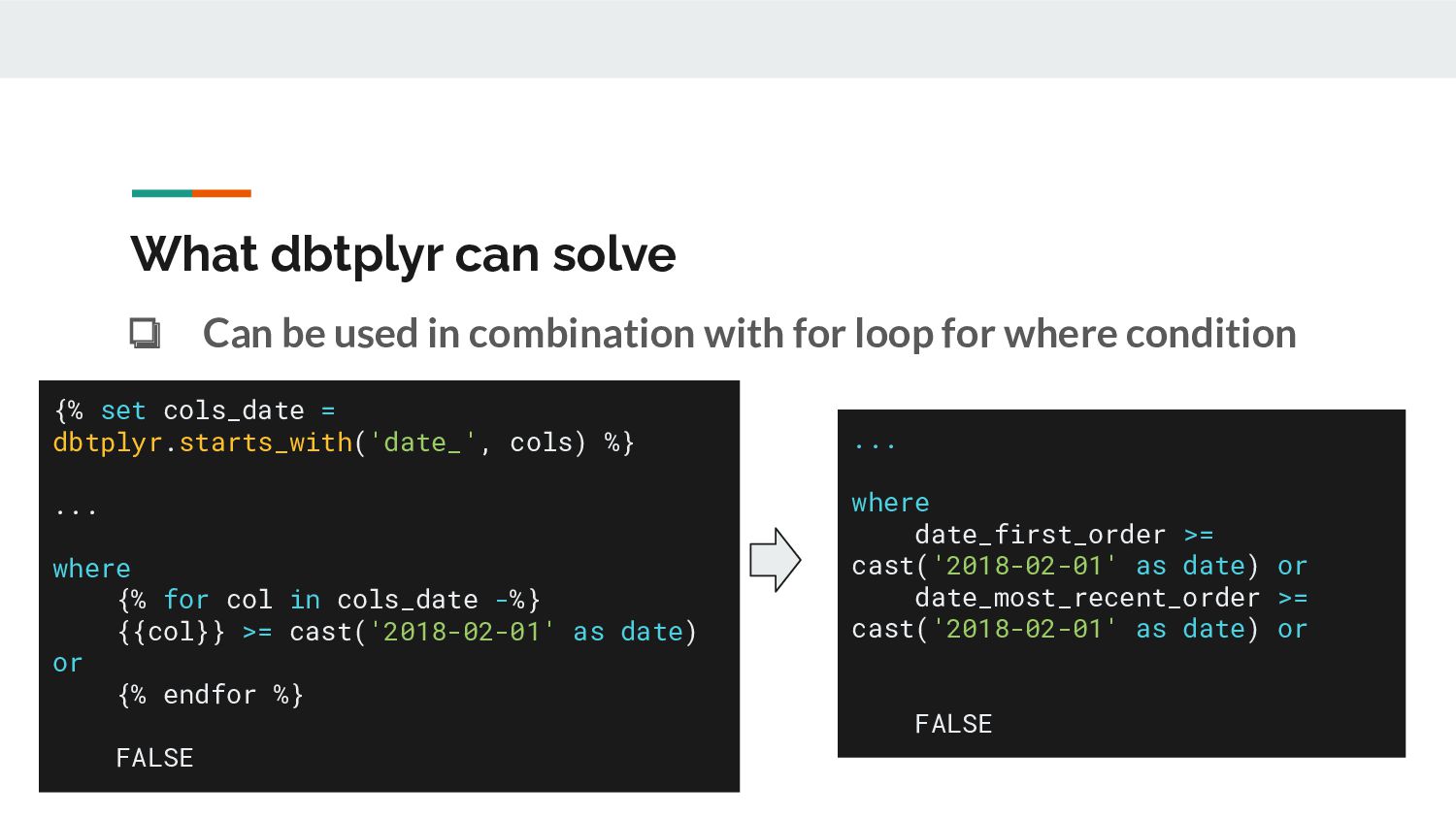
for col in cols_date -%} {{col}} >= cast('2018-02-01' as date) or {% endfor %} FALSE ... where date_first_order >= cast('2018-02-01' as date) or date_most_recent_order >= cast('2018-02-01' as date) or FALSE What dbtplyr can solve ❏ Can be used in combination with for loop for where condition
Science (dplyr) was introduced. ❏ The process used in SQL is simple and convenient, so dplyr may become popular in the dbt world. ❏ I will write a bit more about it in dbt Advent Calendar 2024 including the dbt installation process!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %} with](https://files.speakerdeck.com/presentations/58d884298be74000975c155c8a943aa6/slide_14.jpg){kind=link}
![{% macro get_payment_methods() %} ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] {% endmacro](https://files.speakerdeck.com/presentations/58d884298be74000975c155c8a943aa6/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}