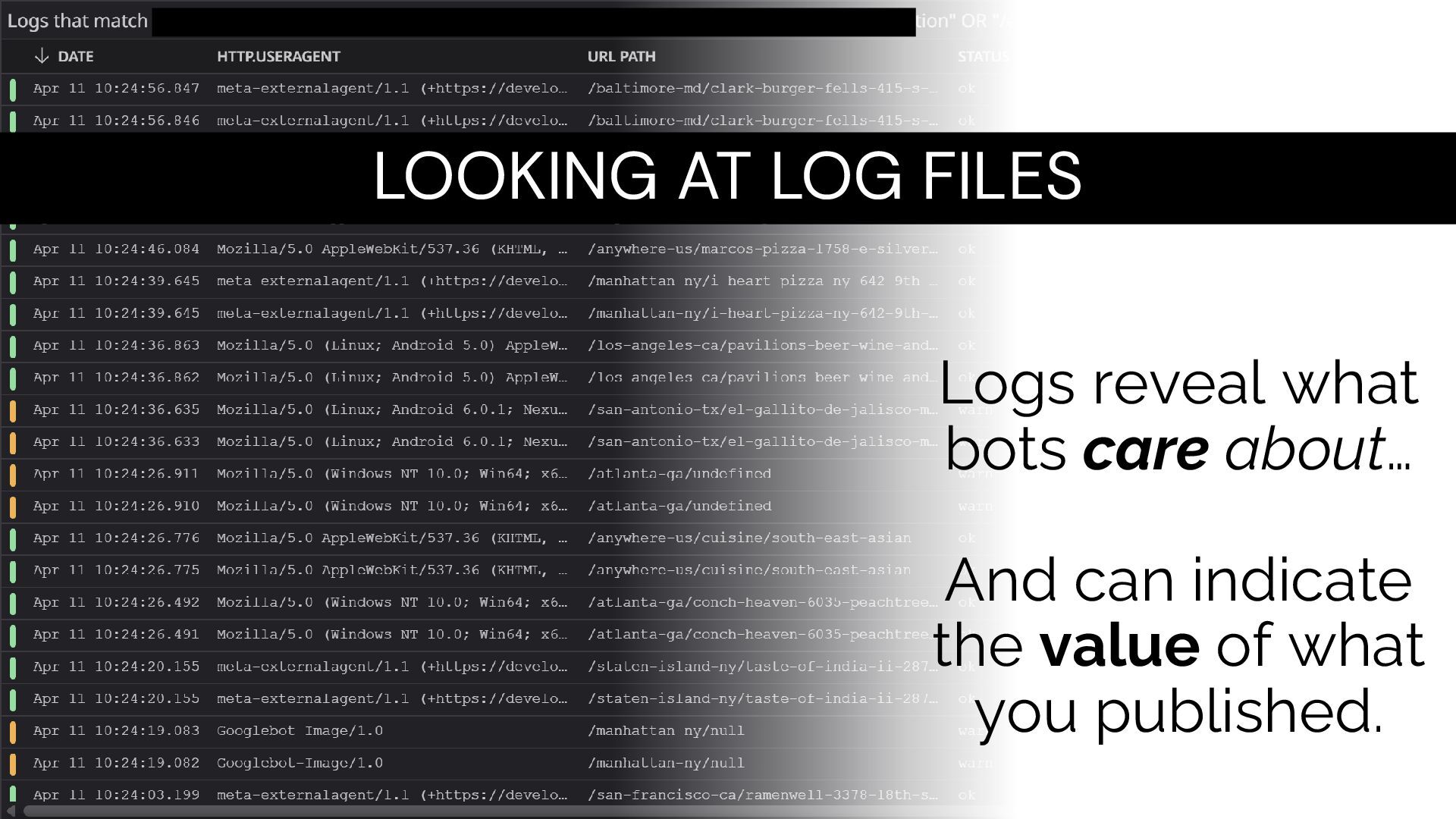
"Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; GPTBot/1.0; +https://openai.com/gptbot)" IP Address of GPTBot Timestamp of Request HTTP Method & URL Status User-Agent String Anatomy of a Log Line
/faq/refund-policy HTTP/1.1" 200 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; GPTBot/1.0; +https://openai.com/gptbot)" Timestamp of Request HTTP Method & URL Status User-Agent String Who & Where? What & How? When Anatomy of a Log Line
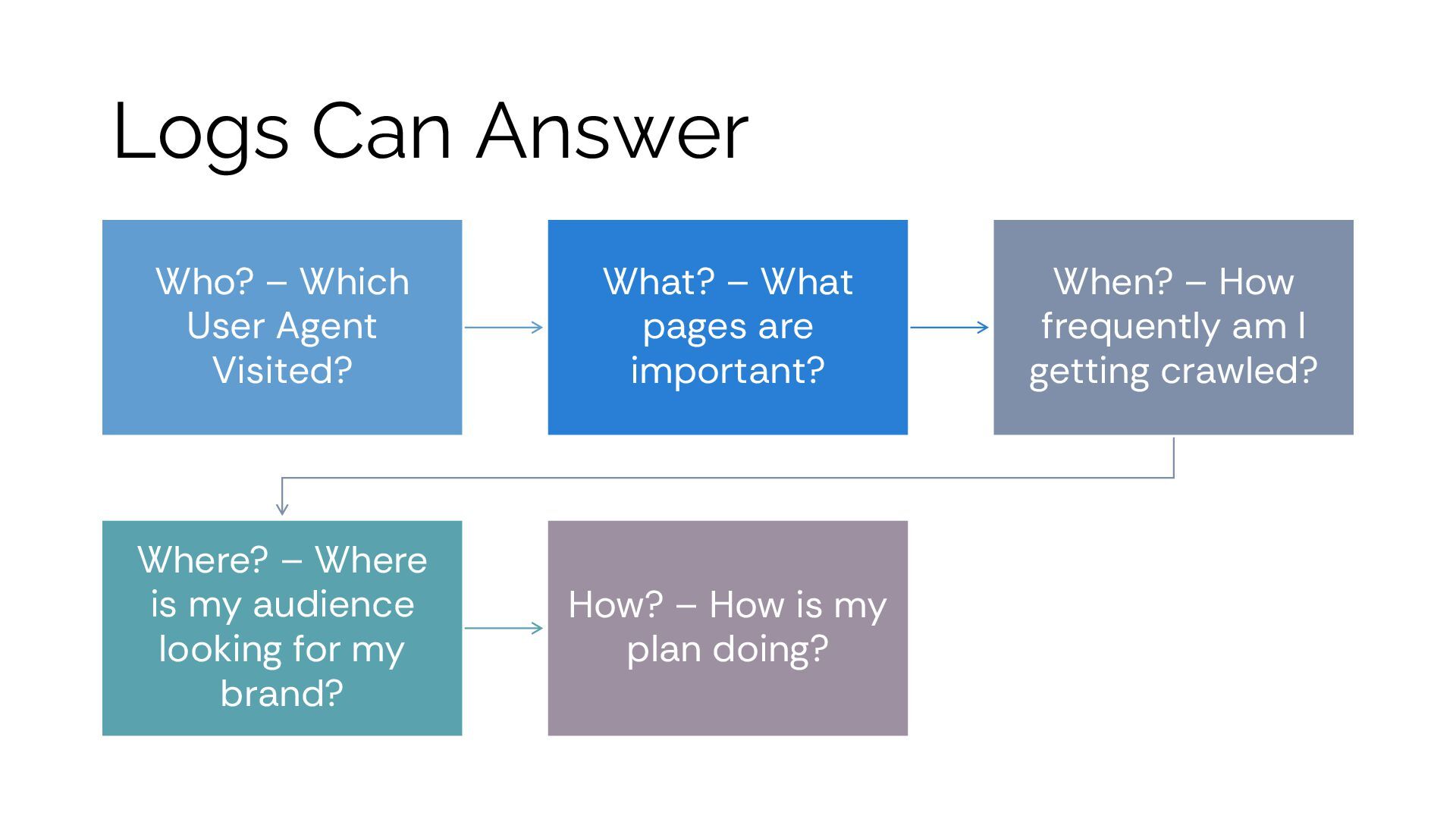
– What pages are important? When? – How frequently am I getting crawled? Where? – Where is my audience looking for my brand? How? – How is my plan doing?
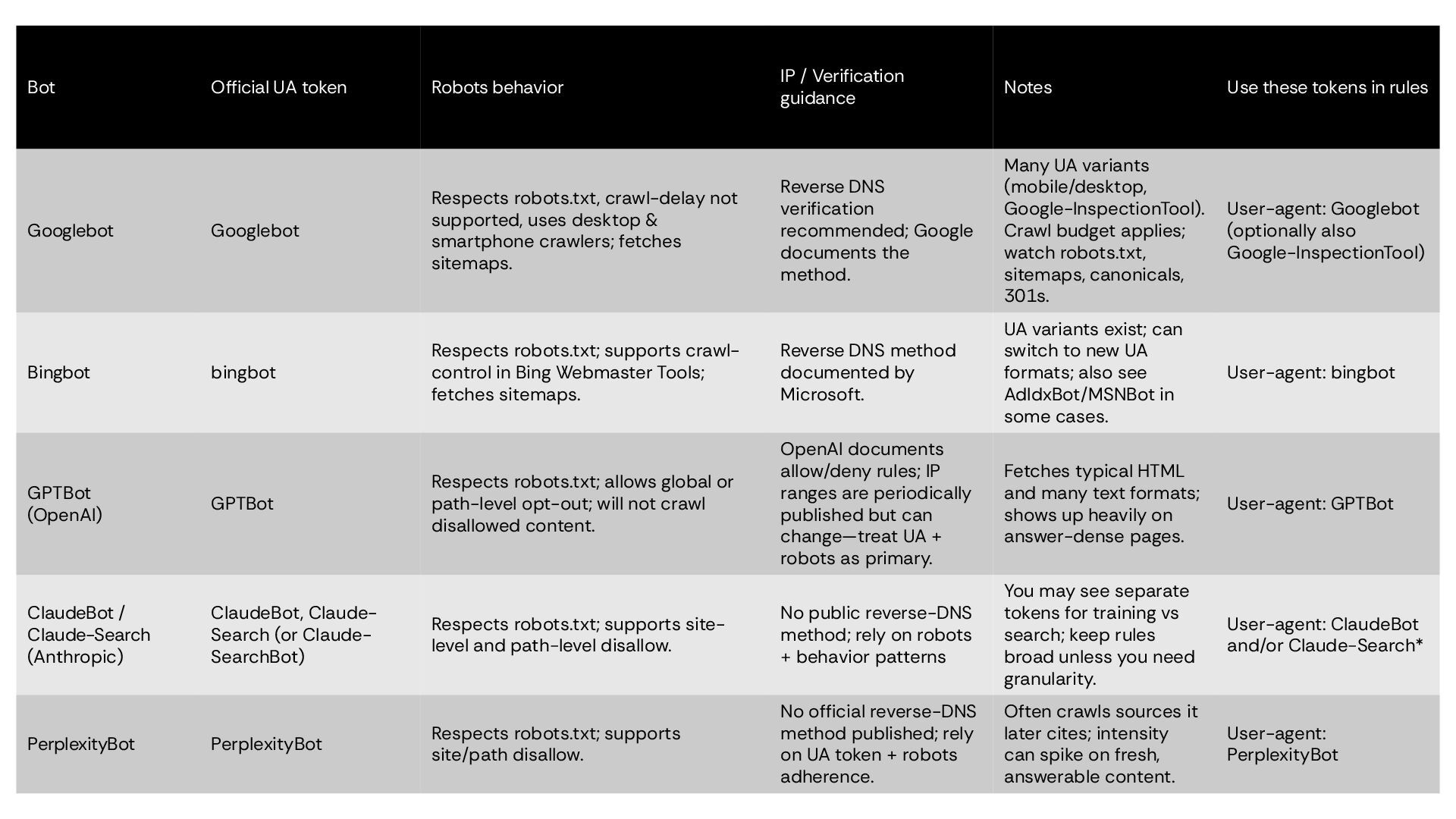
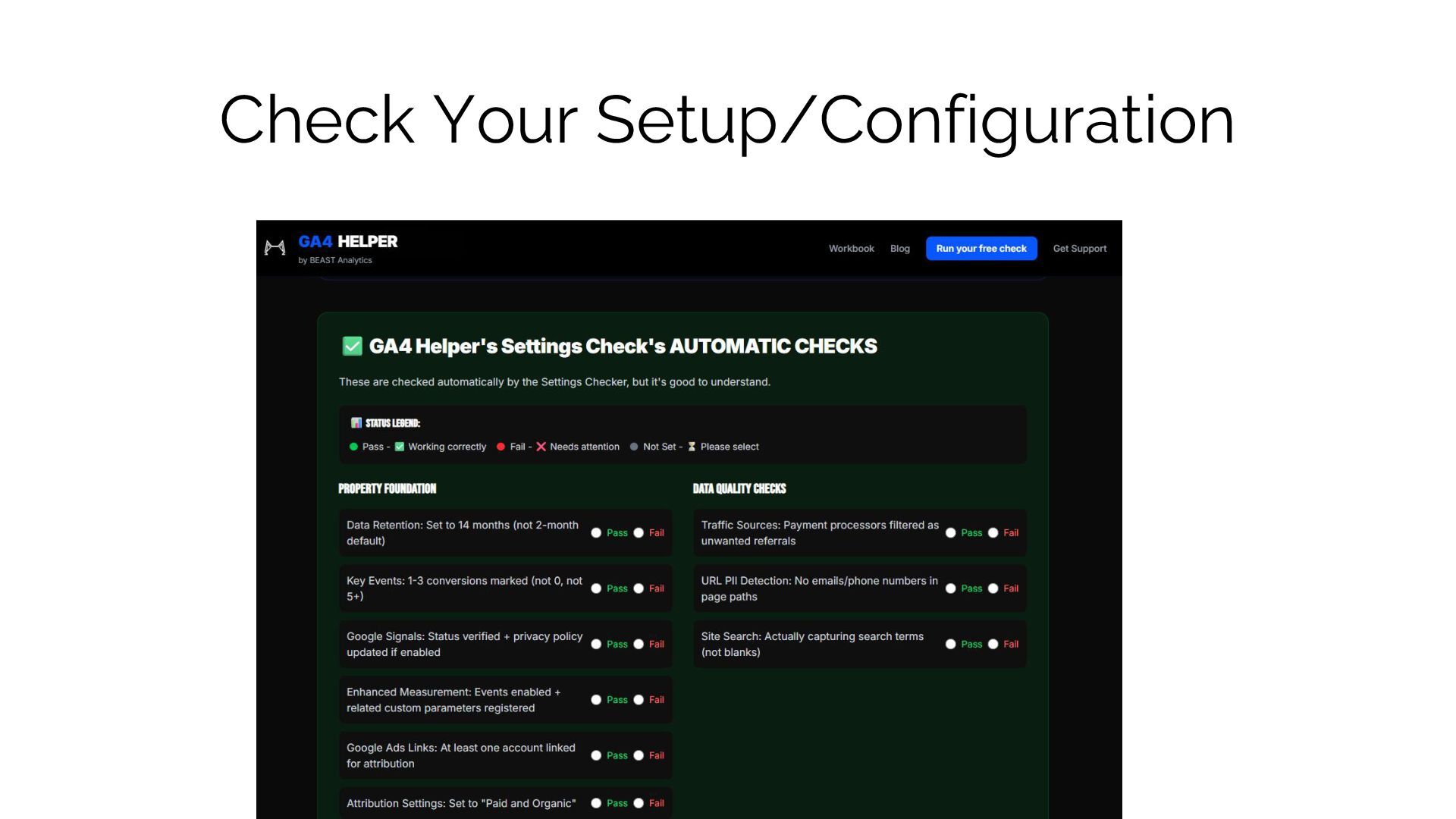
Notes Use these tokens in rules Googlebot Googlebot Respects robots.txt, crawl-delay not supported, uses desktop & smartphone crawlers; fetches sitemaps. Reverse DNS verification recommended; Google documents the method. Many UA variants (mobile/desktop, Google-InspectionTool). Crawl budget applies; watch robots.txt, sitemaps, canonicals, 301s. User-agent: Googlebot (optionally also Google-InspectionTool) Bingbot bingbot Respects robots.txt; supports crawl- control in Bing Webmaster Tools; fetches sitemaps. Reverse DNS method documented by Microsoft. UA variants exist; can switch to new UA formats; also see AdIdxBot/MSNBot in some cases. User-agent: bingbot GPTBot (OpenAI) GPTBot Respects robots.txt; allows global or path-level opt-out; will not crawl disallowed content. OpenAI documents allow/deny rules; IP ranges are periodically published but can change—treat UA + robots as primary. Fetches typical HTML and many text formats; shows up heavily on answer-dense pages. User-agent: GPTBot ClaudeBot / Claude-Search (Anthropic) ClaudeBot, Claude- Search (or Claude- SearchBot) Respects robots.txt; supports site- level and path-level disallow. No public reverse-DNS method; rely on robots + behavior patterns You may see separate tokens for training vs search; keep rules broad unless you need granularity. User-agent: ClaudeBot and/or Claude-Search* PerplexityBot PerplexityBot Respects robots.txt; supports site/path disallow. No official reverse-DNS method published; rely on UA token + robots adherence. Often crawls sources it later cites; intensity can spike on fresh, answerable content. User-agent: PerplexityBot
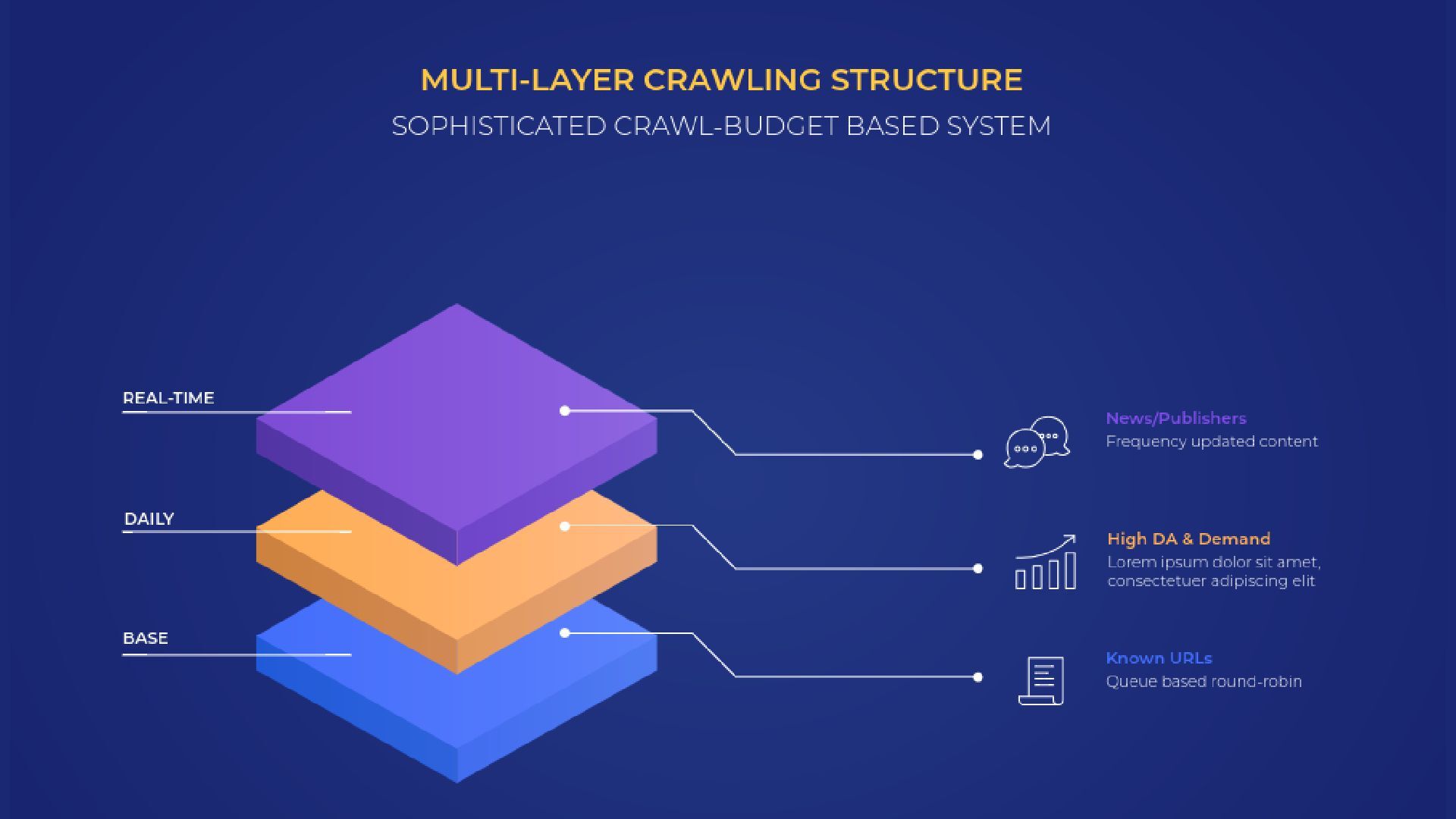
Per-URL scheduling: minutes to months based on PageRank + freshness No transparent scheduling; burst activity during training cycles Crawl Budget System Sophisticated: capacity limit + demand signals No documented budget system; often overload servers Depth of Crawl Follows internal link structure Less systematic; may focus on specific high-value pages Revisit Logic Based on budget & freshness Training cycles: periodic bulk collection, then dormant Time of Day Patterns Distributed for crawl capacity limits Burst patterns: spikes during training data collection
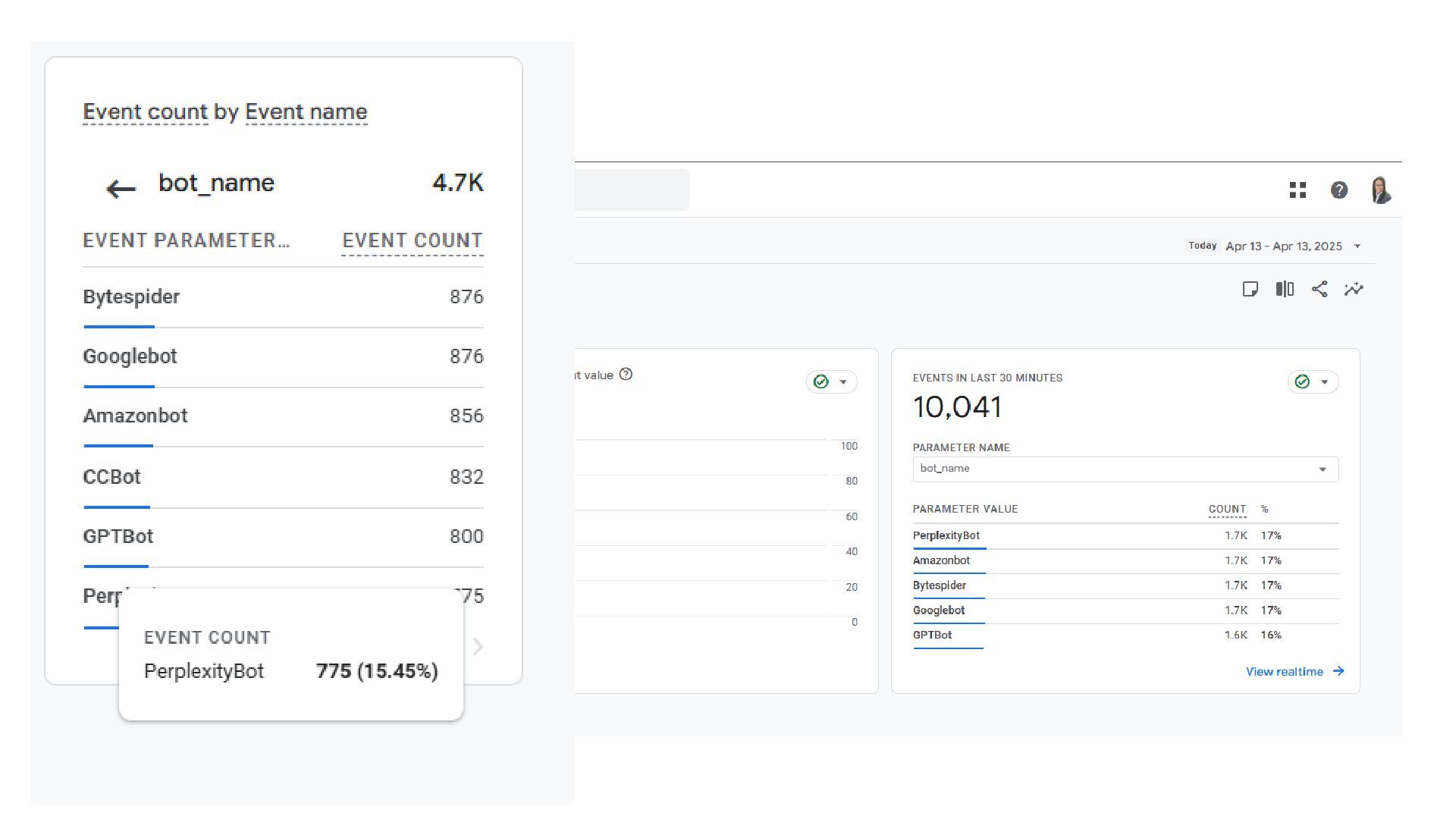
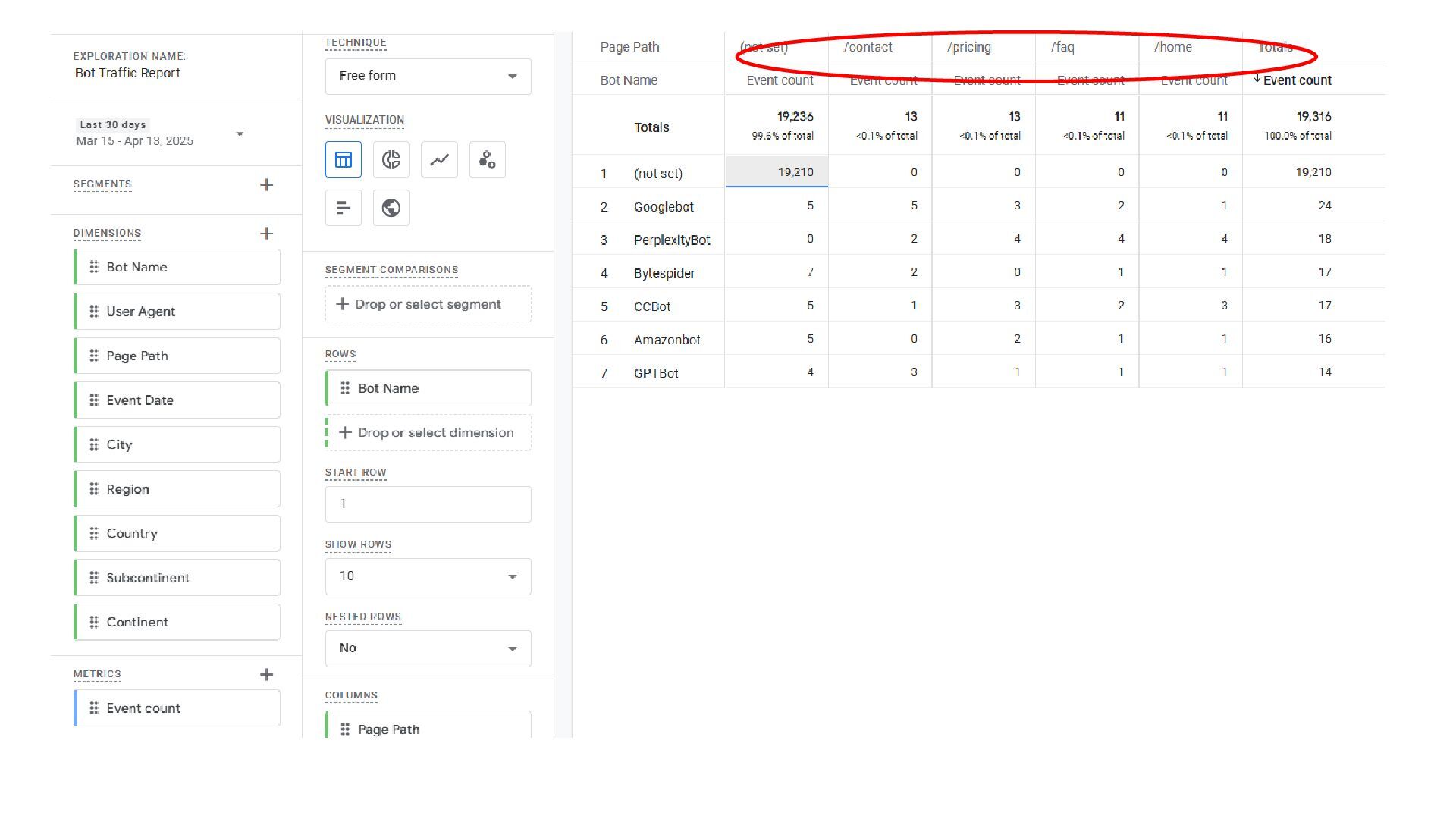
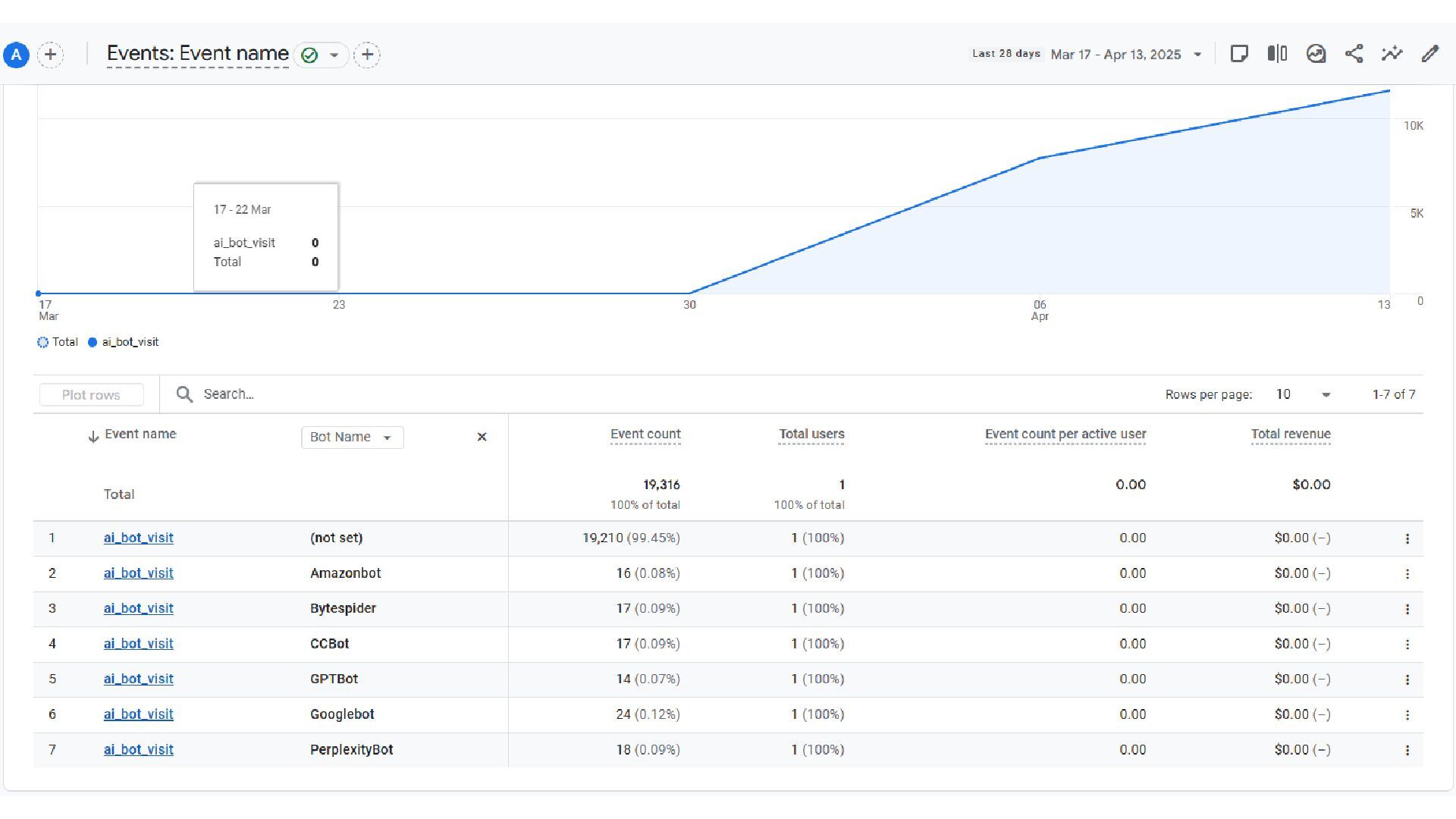
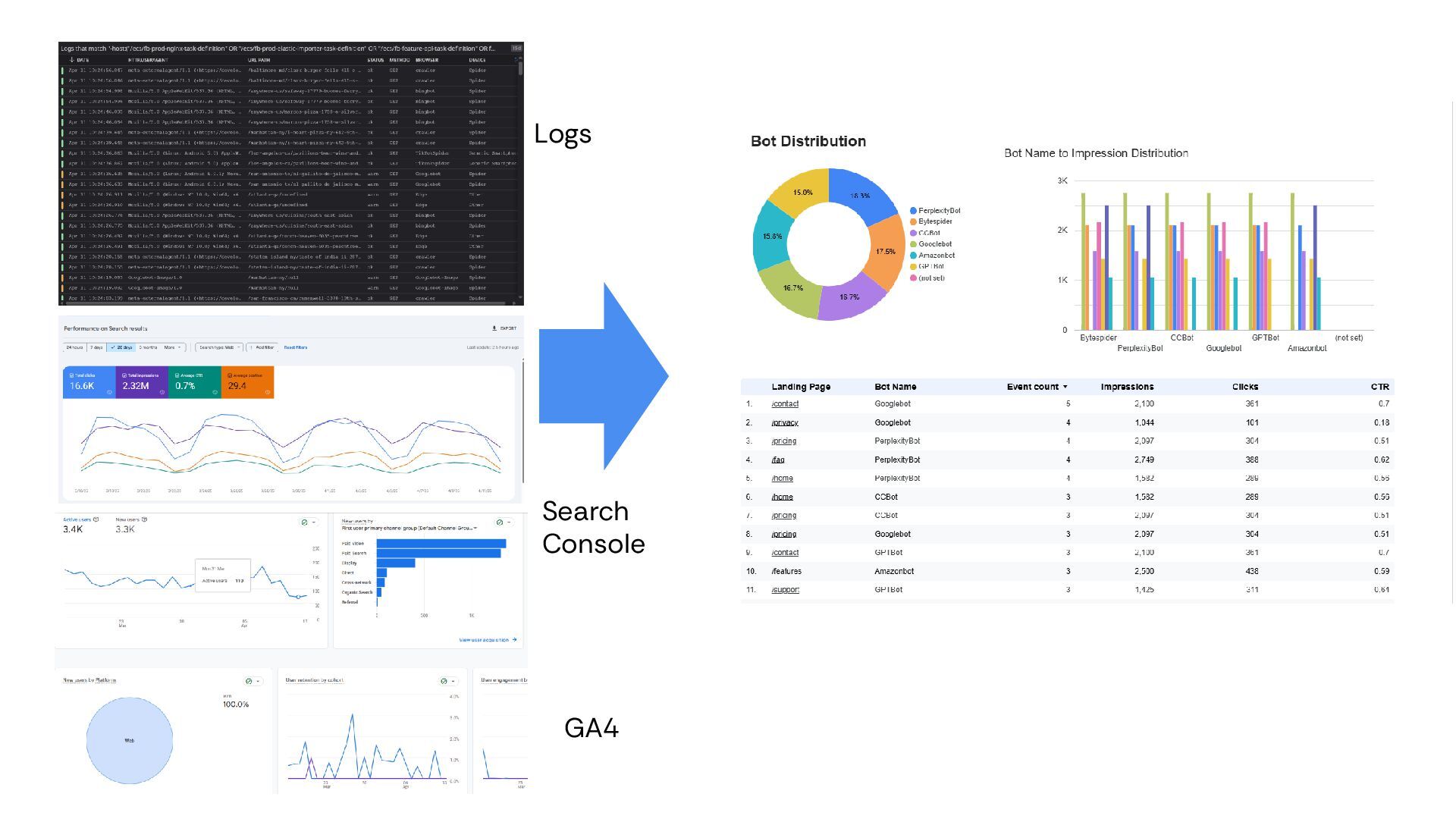
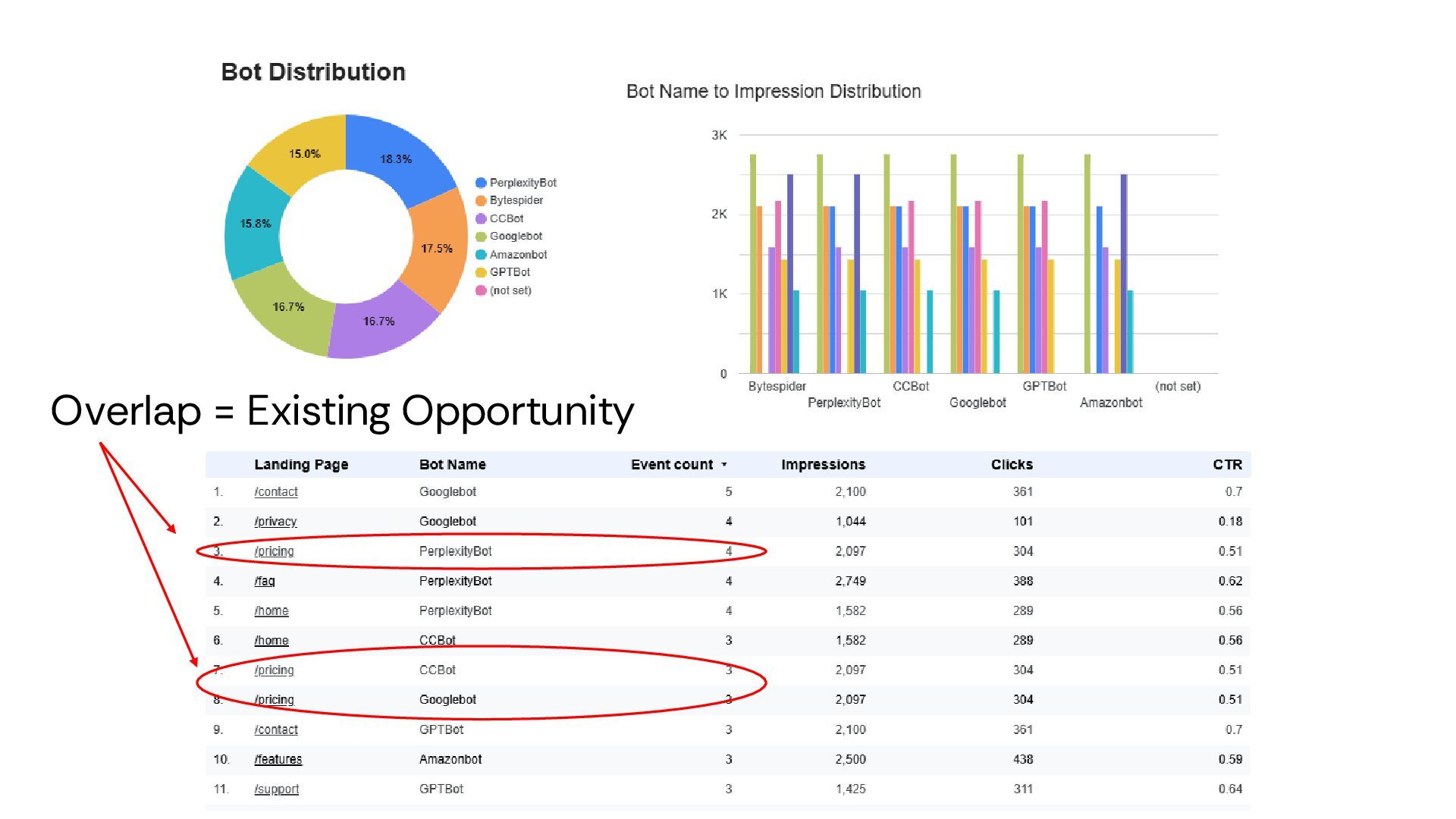
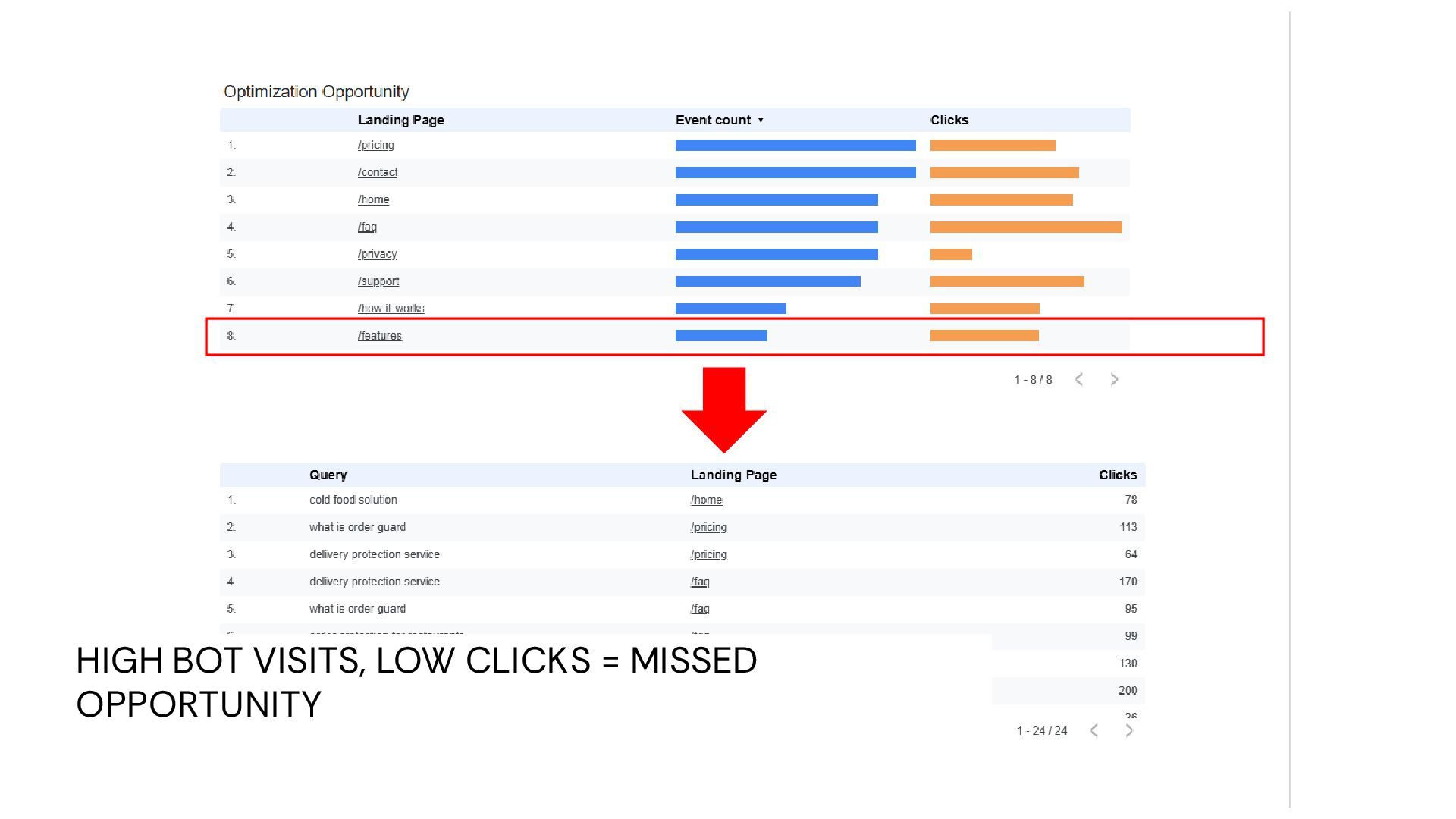
Test Against • Referrals by Bot/LLM • Conversion by Bot/LLM • % of Touches w/ Data-Driven Attribution View • Crawl intensity by bot • Bot Distribution • Time to Recrawl • Launch Your Tests & Re-Run for New LLM Bots
use web snapshots + RAG pipelines. You need to make your site “learnable.” Actions: Include clear brand + product definitions above the fold (on homepage and key pages) Publish FAQ-style Q&A for your domain (“What is X?” “How does Y work?”) Add named entity references (your brand, features, categories) with internal links Submit to Perplexity’s “Pro” knowledge base or cite-able resources Ensure your sitemap.xml and robots.txt expose these pages (Getttummm Crawled)
passages, not whole pages. You need snippet-optimized content. Actions: Build high-authority explainer blocks: •Start with the answer → support with examples → cite yourself Use bullet summaries, step-by-step guides, or glossaries Add linkable anchors (#how-it-works, #pricing-explained) Use OpenGraph and meta descriptions that summarize function, audience, and value
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![104.28.10.1 - - [11/Apr/2025:14:22:11 +0000] "GET /faq/refund-policy HTTP/1.1" 200 "-"](https://files.speakerdeck.com/presentations/69bac43b4bba456ba091da8aecf10730/slide_6.jpg){kind=link}
![IP Address of GPTBot 104.28.10.1 - - [11/Apr/2025:14:22:11 +0000] "GET](https://files.speakerdeck.com/presentations/69bac43b4bba456ba091da8aecf10730/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}