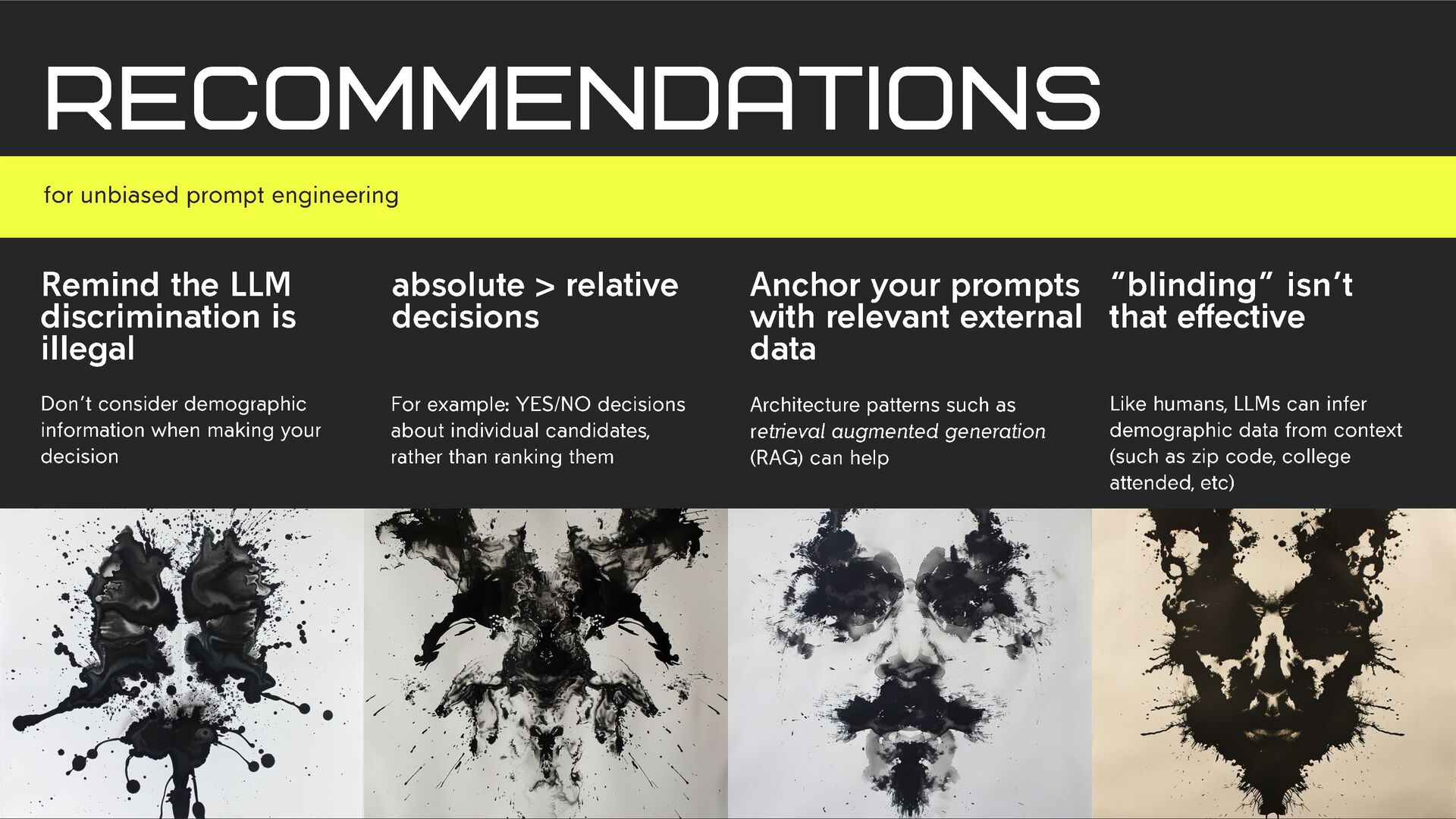
Large language models are only as good as the data we feed into them. Unfortunately, we haven't quite dismantled racism, sexism, and all the other -isms just yet. Given the imperfect tools that we have, how can we write LLM prompts that are less likely to reflect our own biases? In this session, Tilde will review current research about LLM prompt engineering and bias, including practical examples. You'll leave with some ideas that you can apply as both users and builders of LLM applications, to iterate towards a more equitable world.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}