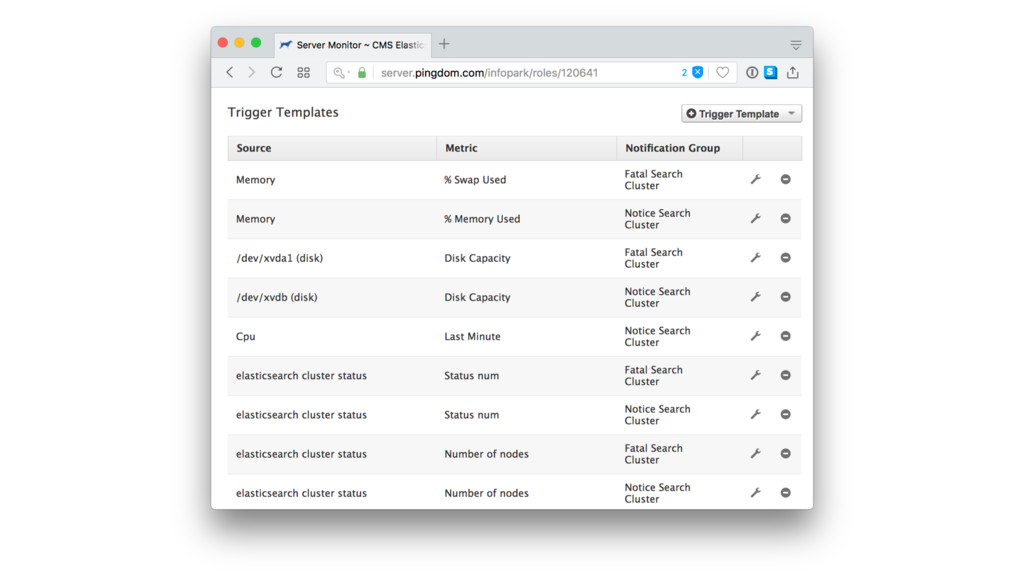
At todays "Search Usergroup Berlin" ([1]) I gave this talk about how we operate Elasticsearch in production here at Infopark ([2]).
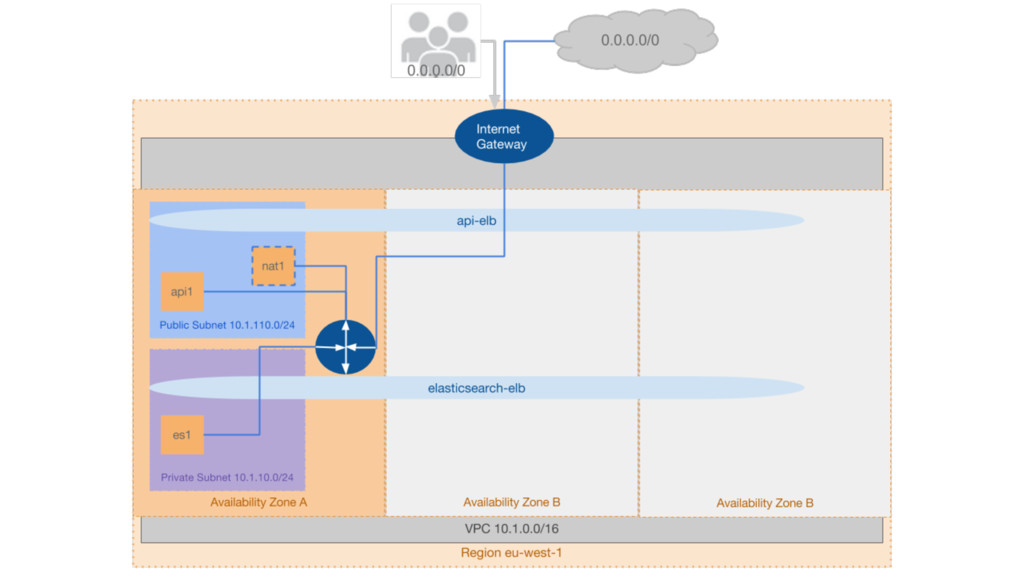
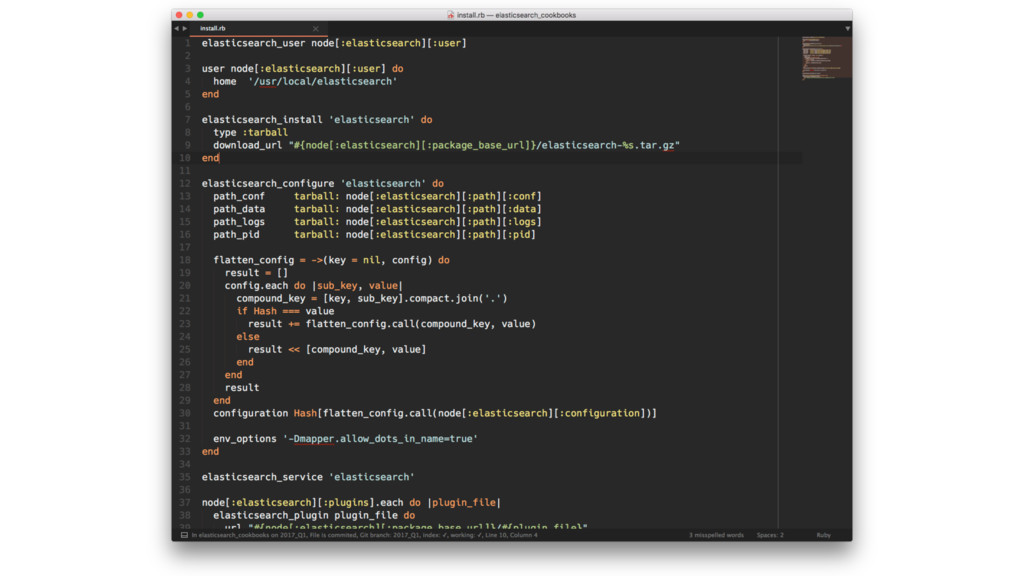
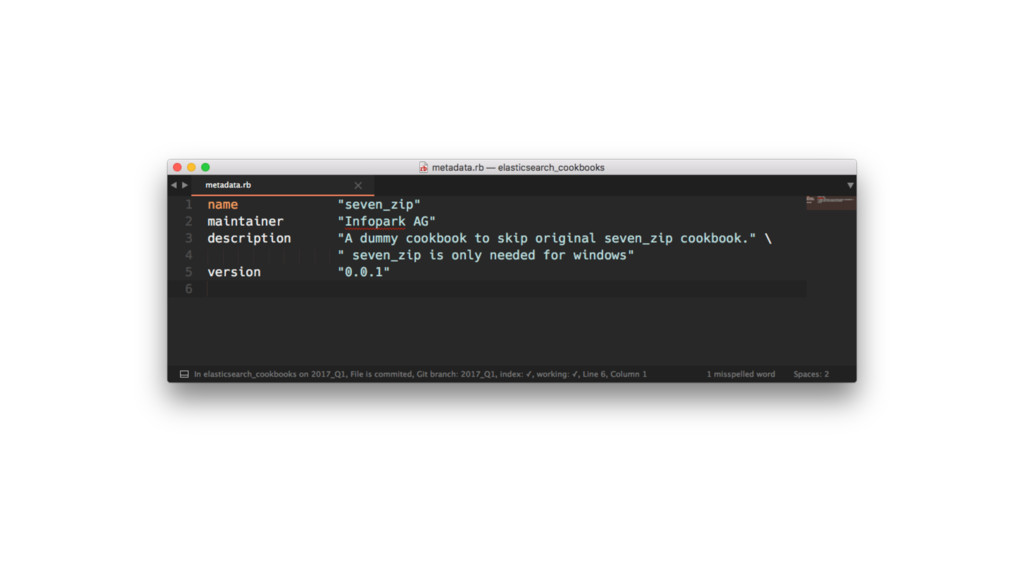
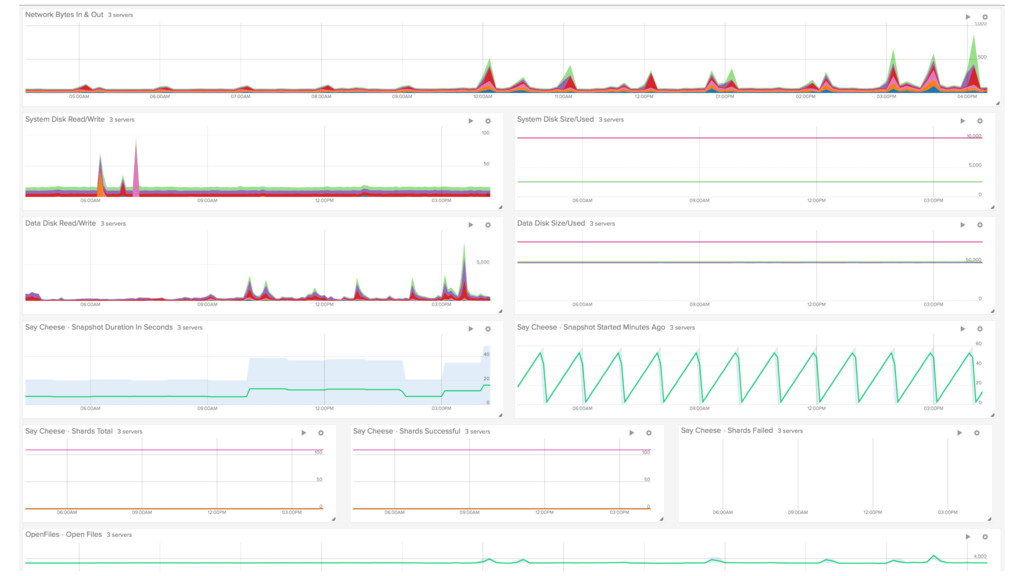
In this presentation I show our Elasticsearch cluster setup and what lessons we learned over the years.
This presentation was prepared by Anne Schulz ([3]) and me ([4]). All not referenced cat pictures are by Anne.
[1] https://www.meetup.com/de-DE/Search-UG-Berlin/events/239101829/
[2] https://infopark.com/
[3] https://twitter.com/AnneMoneSchulz
[4] https://twitter.com/_apepper
{kind=link}
![Alexander Pepper [email protected] +49 30 747993-0 @apepper @_apepper](https://files.speakerdeck.com/presentations/41390227b00c4c718f74cffa0435a042/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you for your attention! Alexander Pepper [email protected] +49 30](https://files.speakerdeck.com/presentations/41390227b00c4c718f74cffa0435a042/slide_36.jpg){kind=link}
{kind=link}