Reshef Mann and Oren Kaniel Just completed Round B funding - total of $28M Processing 3.5B daily events (it was 1.9B just 2 months ago and 250M at the start of 2014!) 13 people in the development team (we were just 6 people 12 months ago!) AppsFlyer Who?!
of “Big Data”- we were just occupied with making the system work • Even though we were ignorant of the future, we tried to adhere to a few abstractions: - Small isolated services - Central concept of message delivery via - Different tech for different tasks A message-bus
up with view generation • Python processes that read from the message bus (via pub sub) couldn't keep up with the amount of data • The split between aggregated and raw data was good, but caused discrepancies because each service failed at a different time • If the message bus failed (Redis), all other services were also in a fail state – single point of failure First Creaks In The System
CouchDB to Google's Bigquery (easiest solution at the time) • Rewrite some of the Python services in a new language that: – Deals better with strings and allocation of memory – Can help us scale out – Has a great ecosystem – Functional
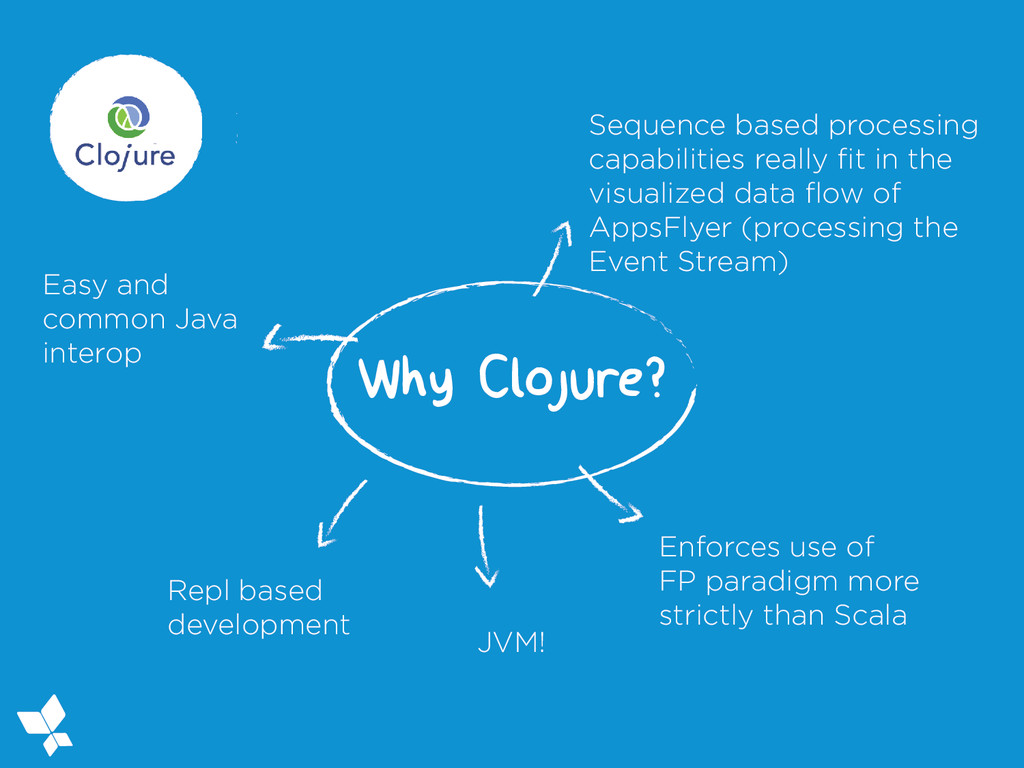
visualized data flow of AppsFlyer (processing the Event Stream) Enforces use of FP paradigm more strictly than Scala Repl based development Easy and common Java interop JVM!
Each service encapsulates its own data (if it has any) and he exposes it over a well known interface Data objects are always POCO/POJO (simple data structures represented in JSON or EDN) Preference for queues and buffers that pass isolated data for total async processing How We Model
read from the event stream to its heart content - regular Kafka consumers behavior Each new service handles real life traffic and real life load because it's connected to the event stream Test DB if needed is easy to spin up on the cloud Once deemed ready, just throw the switch to on
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}