inside • JSON-based query language • Developed by analytics SAAS company • Free and open source • Scalable to petabytes... • Optimized for time based data
customers cannot open a dashboard • Busy weekend to give Druid a shot • On Sunday morning - dashboard opens and works well!!! • Customer was happy!!! • We moved more and more customers to Druid
{kind=link}
{kind=link}
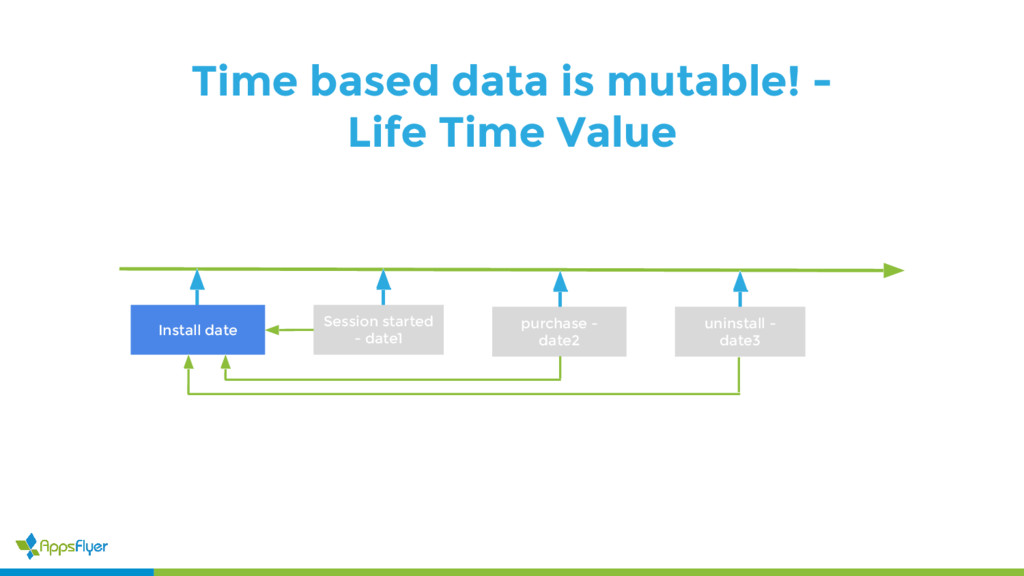{kind=link}
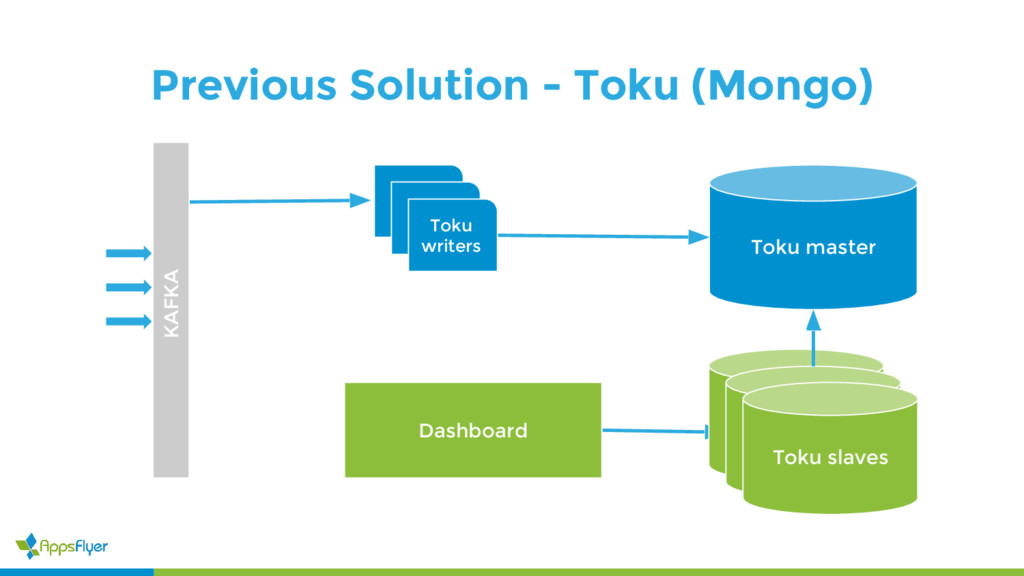{kind=link}
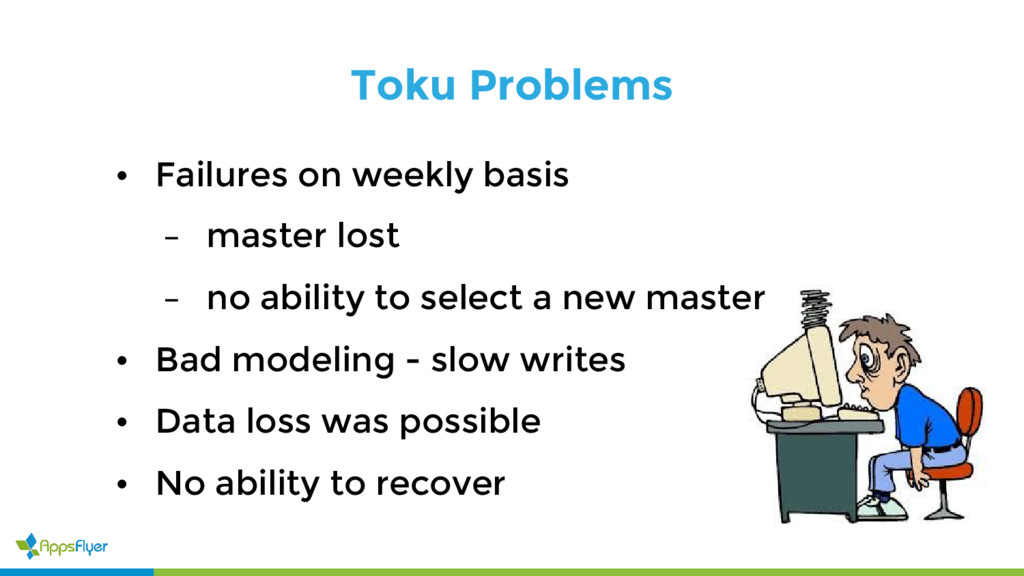{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
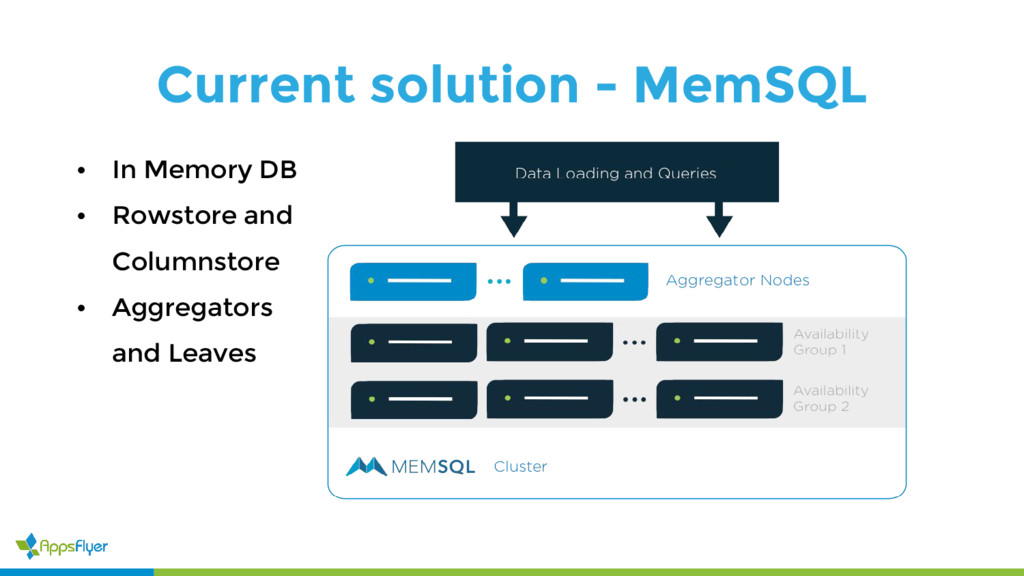{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you Join the Data Team! [email protected]](https://files.speakerdeck.com/presentations/eb5fbe8a03be4eaf892a1bcbb4633198/slide_19.jpg){kind=link}