Measuring unique users in a billion user network is hard - accurate counting is space consuming and not easily distributable.
In this talk I will describe HyperLogLog, a probabilistic cardinality estimation algorithm and data structure and how we used it to provide breakdowns of our billion user reach.
{kind=link}
{kind=link}
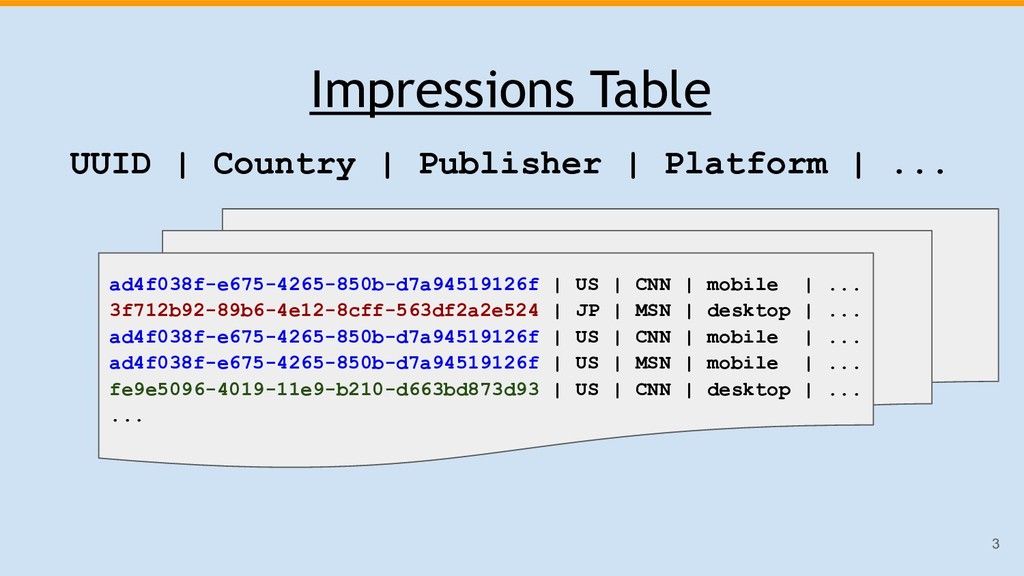{kind=link}
{kind=link}
{kind=link}
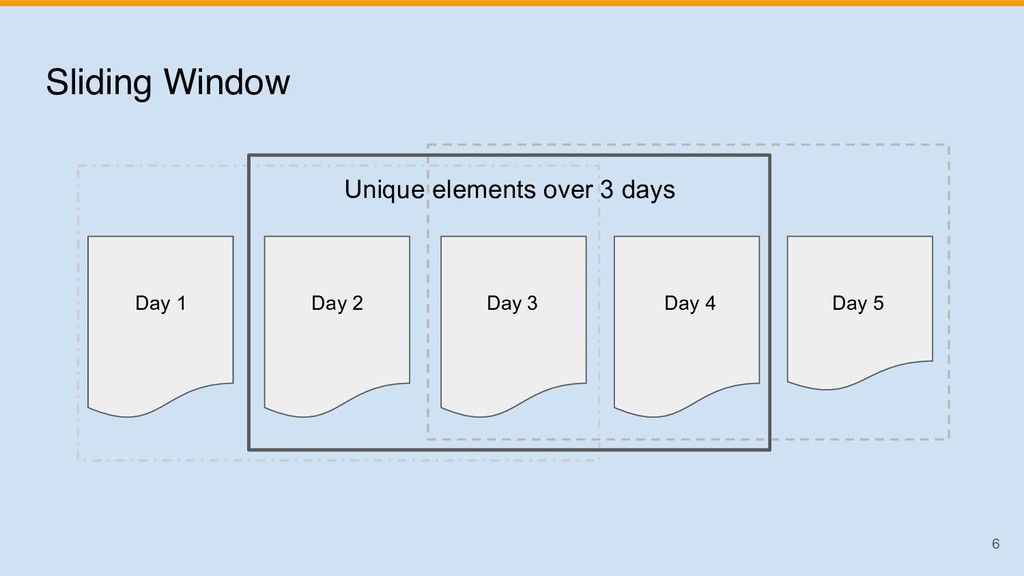{kind=link}
{kind=link}
{kind=link}
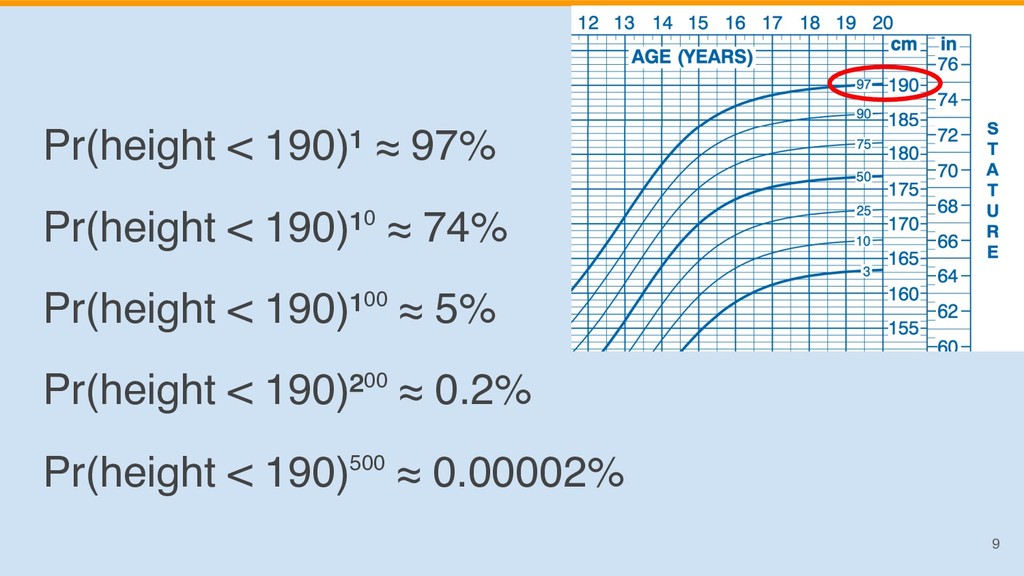{kind=link}
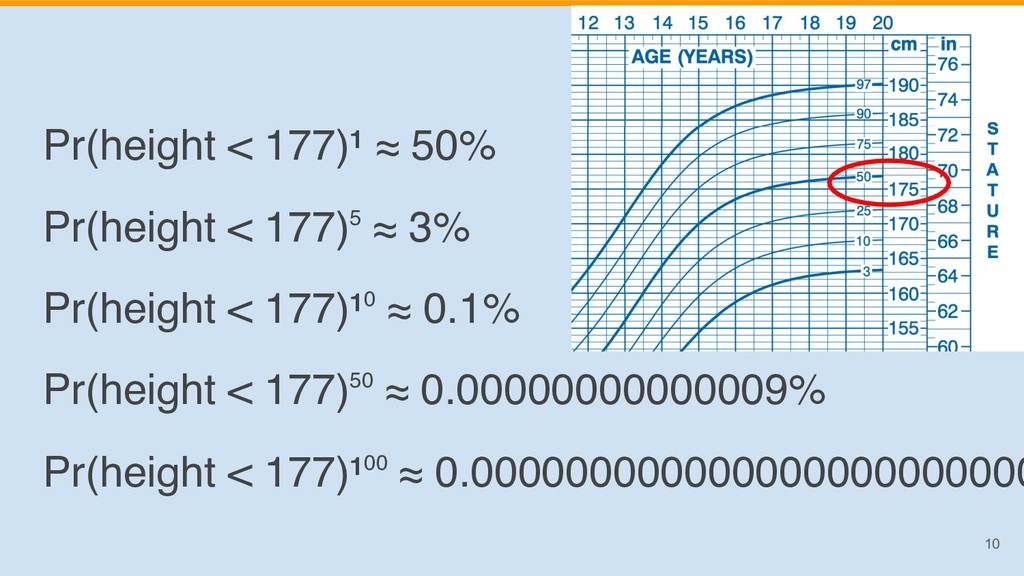{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![M[0..m-1]: Array of m values (m=2 ), initialized to 0’s](https://files.speakerdeck.com/presentations/6c6074a08ebe4356bd543947b779be1f/slide_17.jpg){kind=link}
![M[]: !19 0 0 0 0 0 0 0 0](https://files.speakerdeck.com/presentations/6c6074a08ebe4356bd543947b779be1f/slide_18.jpg){kind=link}
![M[]: !20 0 0 3 0 0 0 0 0](https://files.speakerdeck.com/presentations/6c6074a08ebe4356bd543947b779be1f/slide_19.jpg){kind=link}
![M[]: !21 0 0 3 0 0 0 0 0](https://files.speakerdeck.com/presentations/6c6074a08ebe4356bd543947b779be1f/slide_20.jpg){kind=link}
![M[]: !22 0 0 3 0 0 0 4 0](https://files.speakerdeck.com/presentations/6c6074a08ebe4356bd543947b779be1f/slide_21.jpg){kind=link}
![M[]: !23 0 0 3 0 0 0 4 0](https://files.speakerdeck.com/presentations/6c6074a08ebe4356bd543947b779be1f/slide_22.jpg){kind=link}
![M[]: !24 0 0 3 0 0 0 4 0](https://files.speakerdeck.com/presentations/6c6074a08ebe4356bd543947b779be1f/slide_23.jpg){kind=link}
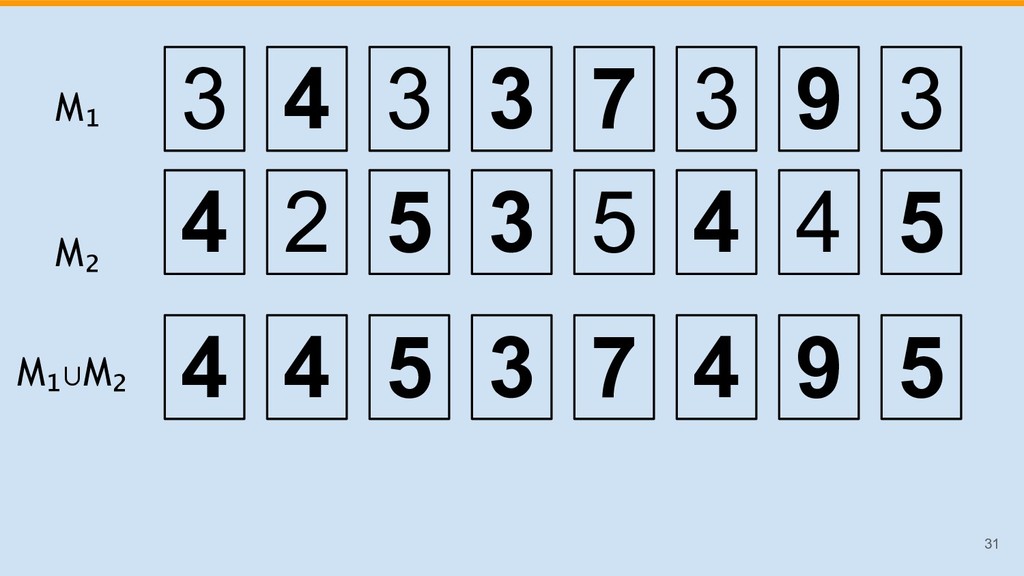
![M[]: !25 3 4 3 3 7 3 9 3](https://files.speakerdeck.com/presentations/6c6074a08ebe4356bd543947b779be1f/slide_24.jpg){kind=link}
{kind=link}
![M[0..m-1]: Array of m values logLogEstimate(M): Standard error ≈ 1.3/√m](https://files.speakerdeck.com/presentations/6c6074a08ebe4356bd543947b779be1f/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}