Data DevOps and Support Solutions and Accelerators BIG DATA AND DATA SCIENCE PRACTICE 15+ World-Class Data Architects 200+ Big Data Engineers & Hadoop DevOps 10% Hadoop Certified Engineers 20+ Data Scientists
where he leads EMEA Big Data Competency Center. He has over 20 years of software engineering experience and built multiple systems in the area of low-latency and distributed data processing in financial, e-retail and advertising industries. During his career, Alexey has designed systems processing millions of messages per second and managing petabytes of stored data. He uses RDBMs, NoSQL, data grids, and Big Data toolchain in his daily work to help companies on their Big Data journey. Alexey Kharlamov EPAM Systems, Solution Architect
games, sensors, ad networks – Large volumes – Allow to build fine grained models of reality • Traits – ~1000 USD/TB – Hundreds of servers, thousands of rotational drives (Failure is a reality) – High performance server to server network – It takes days to copy data from a single server BIG DATA SYSTEM
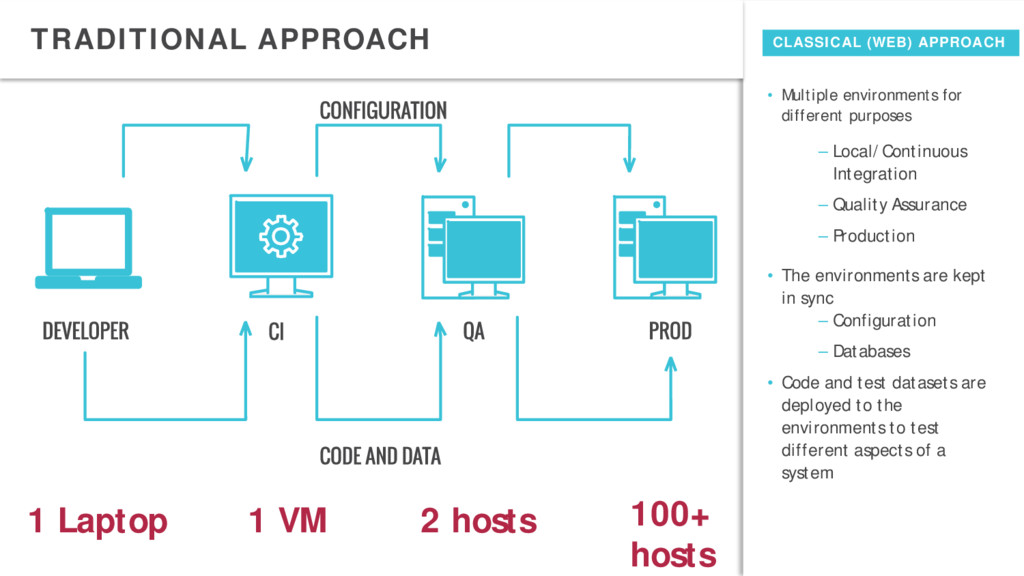
– Quality Assurance – Production • The environments are kept in sync – Configuration – Databases • Code and test datasets are deployed to the environments to test different aspects of a system CLASSICAL (WEB) APPROACH 1 Laptop 1 VM 2 hosts 100+ hosts TRADITIONAL APPROACH
PROD are constantly different • Test failure on CI and QA does not mean it will fail in PROD and visa versa • People stop to rely on additional environments to test their jobs • The most frequent bugs – Unexpected field value / rubbish – Input data change – Resource issue due data skew or growth • Environments have different hardware – Number of nodes – Generations of servers • Hard to synchronize configuration – Reprovisioning takes hours – Engineers tend to forget to copy configuration parameters • Hard to synchronize data – Different amount of disk space and CPU – Coping takes hours
– Test data do not cover all possible values – Sampled data may miss exactly this error – Need to test on production data • Incompatible change in data format – Frequently brought in by third-parties and unexpected – Fall through ETL layers – Need to test on production data • Resource issue due data skew or growth – Causes job termination or cluster failure – Must be tested on exactly the same hardware configuration – Need to test on production data
cluster – Full processing capacity available – Always up-to-date data and configuration – No environment synchronization needed • Cluster becomes multitenant – Partitions must be isolated! – Code must be portable! • Developers need more – Faster turnaround times – Easy interactive debugging and cross- process traceability QA: SINGLE CLUSTER FOR EVERYTHING
Cluster in a single JVM – Job Driver – NameNode – DataNode – Hive – Hbase • Step Into... Hadoop and debug – MapReduce Jobs – User Defined Functions – Coprocessors – Queries
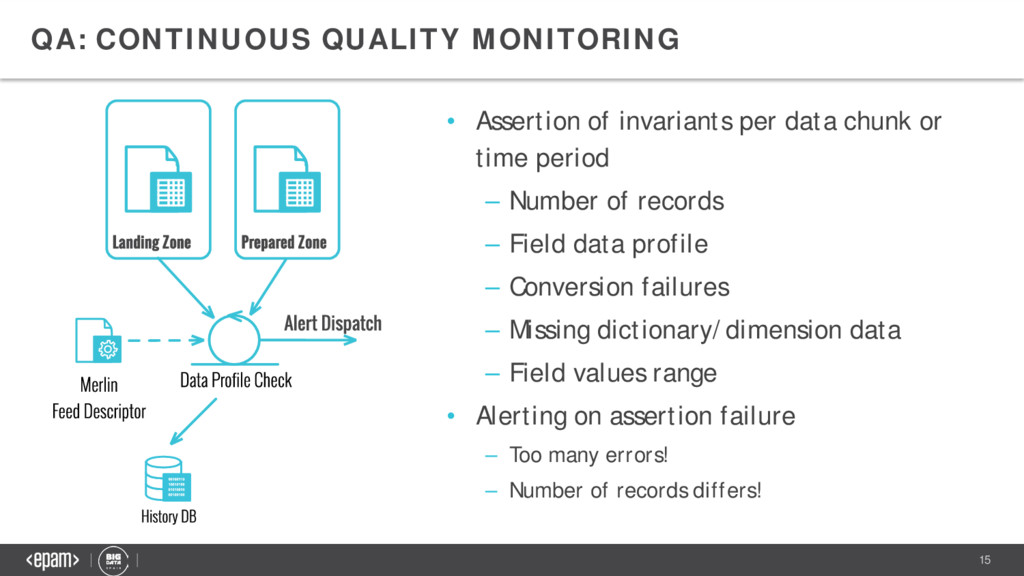
data chunk or time period – Number of records – Field data profile – Conversion failures – Missing dictionary/dimension data – Field values range • Alerting on assertion failure – Too many errors! – Number of records differs!
like to get more • Wants independence from others • Do not want to be bothered by other, but can throw a party from time to time APARTMENT RENTAL TENANT • Provides unit fulfilling tenant needs • Fixes broken facilities • Ensures tenants follow rules • Evicts misbehaving tenants LANDLORD
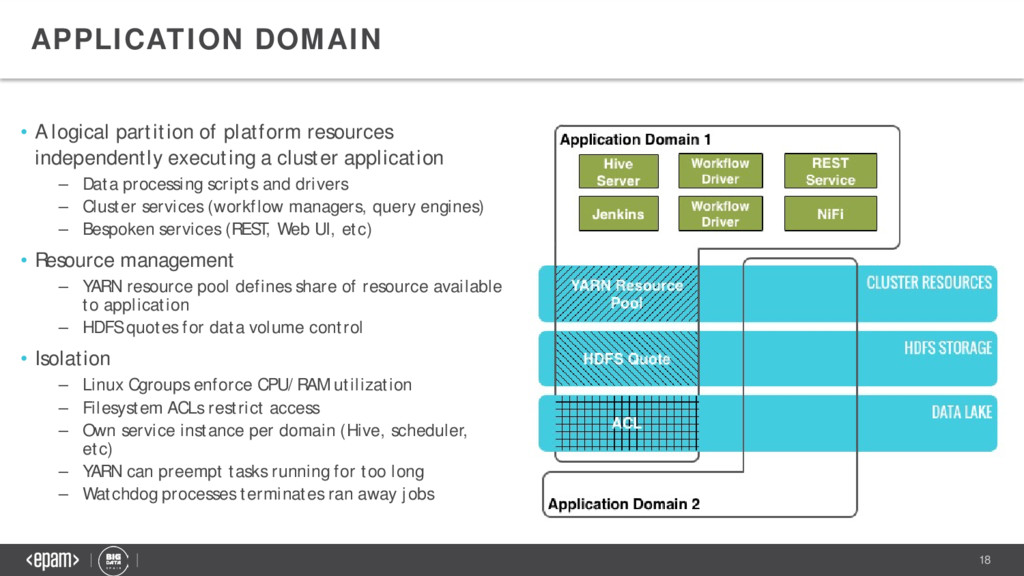
a cluster application – Data processing scripts and drivers – Cluster services (workflow managers, query engines) – Bespoken services (REST, Web UI, etc) • Resource management – YARN resource pool defines share of resource available to application – HDFS quotes for data volume control • Isolation – Linux Cgroups enforce CPU/RAM utilization – Filesystem ACLs restrict access – Own service instance per domain (Hive, scheduler, etc) – YARN can preempt tasks running for too long – Watchdog processes terminates ran away jobs APPLICATION DOMAIN
need a playground • Application domains need to dynamically allocate resources – Metal as a Service – Virtualization – Containerization • Containers are perfect for portable code bundling – Statelessness encourages externalization of configuration – All dependencies included – Explicit amount of resources allocated – Easy migration between hosts
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![21 THANK YOU [email protected] @aih1013](https://files.speakerdeck.com/presentations/3581cc3767f64badb6effbdf4aed52d3/slide_20.jpg){kind=link}