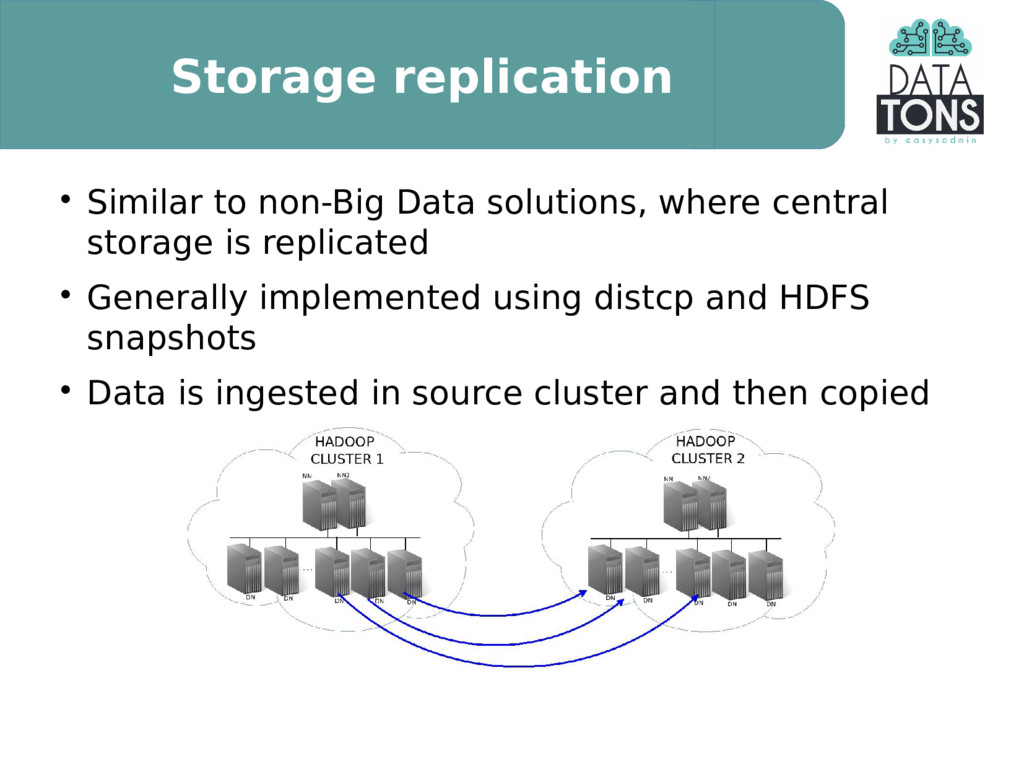
All modern Big Data solutions, like Hadoop, Kafka or the rest of the ecosystem tools, are designed as distributed processes and as such include some sort of redundancy for High Availability.
https://www.bigdataspain.org/2017/talk/disaster-recovery-for-big-data
Big Data Spain 2017
November 16th - 17th Kinépolis Madrid
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}