Hanjun Dai, Bo Dai, Le Song presentation by Breandan Considine McGill University [email protected] March 12, 2020 Breandan Considine (McGill) Discriminative Embeddings March 12, 2020 1 / 20
space to a feature space: ϕ : Input space Rn → Feature space Rm (1) A kernel function k is a real-valued function with two inputs: k : Ω × Ω → R (2) Kernel functions generalize the notion of inner products to feature maps: k(x, y) = ϕ(x) ϕ(y) (3) Gives us ϕ(x) ϕ(y) without directly computing ϕ(x) or ϕ(y). Breandan Considine (McGill) Discriminative Embeddings March 12, 2020 2 / 20
∈ RN2 is positive definite if x Kx > 0, ∀x ∈ RN \0. Positive Definite Kernel A symmetric kernel k is called positive definite on Ω if its associated kernel matrix K = [k(xi , xj )]N i,j=0 is positive definite ∀N ∈ N, ∀{x1, . . . , xN} ⊂ Ω. http://www.math.iit.edu/~fass/PDKernels.pdf Breandan Considine (McGill) Discriminative Embeddings March 12, 2020 6 / 20
be a vector space over R. A function f : X → R is linear iff f (αx) = αf (x) and f (x + z) = f (x) + f (z) for all α ∈ R, x, z ∈ X. Inner product space X is an inner product space if there exists a symmetric bilinear map ·, · : X × X → R if ∀x ∈ X, x, x > 0 (i.e. is positive definite). Cauchy-Schwartz Inequality If X is an inner product space, then ∀u, v ∈ X, | u, v |2 ≤ u, u · v, v . Scalar Product Vector Dot Product Random Variable x, y := xy x1 . . . xn , y1 . . . yn := xTy X, Y := E(XY ) Breandan Considine (McGill) Discriminative Embeddings March 12, 2020 7 / 20
X → R≥0 be a metric on the space X. Cauchy sequence A sequence {xn} is called a Cauchy sequence if ∀ε > 0, ∃N ∈ N, such that ∀n, m ≥ N, d(xn, xm) ≤ ε. Completeness X is called complete if every Cauchy sequence converges to a point in X. Separability X is called separable if there exists a sequence {xn}∞ n=1 ∈ X s.t. every nonempty open subset of X contains at least one element of the sequence. Hilbert space A Hilbert space H is an inner product space that is complete and separable. Breandan Considine (McGill) Discriminative Embeddings March 12, 2020 8 / 20
The inner product ·, · H : H × H → R is a positive definite kernel: n i,j=1 ci cj (xi , xj )H = n i=1 ci xi , n j=1 cj xj H = n i=1 ci xi 2 H ≥ 0 Reproducing Kernel Hilbert Space (RKHS) Any continuous, symmetric, positive definite kernel k : X × X → R has a corresponding Hilbert space, which induces a feature map ϕ : X → H satisfying k(x, y) = ϕ(x), ϕ(y) H. http://jmlr.csail.mit.edu/papers/volume11/vishwanathan10a/vishwanathan10a.pdf https://marcocuturi.net/Papers/pdk_in_ml.pdf Breandan Considine (McGill) Discriminative Embeddings March 12, 2020 9 / 20
dimensional feature spaces: µX := EX [φ(X)] = X φ(x)p(x)dx : P → F (13) By choosing the right kernel, we can make this mapping injective. f (p(x)) = ˜ f (µx ), f : P → R (14) T ◦ p(x) = ˜ T ◦ µx , ˜ T : F → Rd (15) Breandan Considine (McGill) Discriminative Embeddings March 12, 2020 10 / 20
dimensional feature spaces: µX := EX [φ(X)] = X φ(x)p(x)dx : P → F (16) By choosing the right kernel, we can make this mapping injective. f (p(x)) = ˜ f (µx ), f : P → R (17) T ◦ p(x) = ˜ T ◦ µx , ˜ T : F → Rd (18) Breandan Considine (McGill) Discriminative Embeddings March 12, 2020 11 / 20
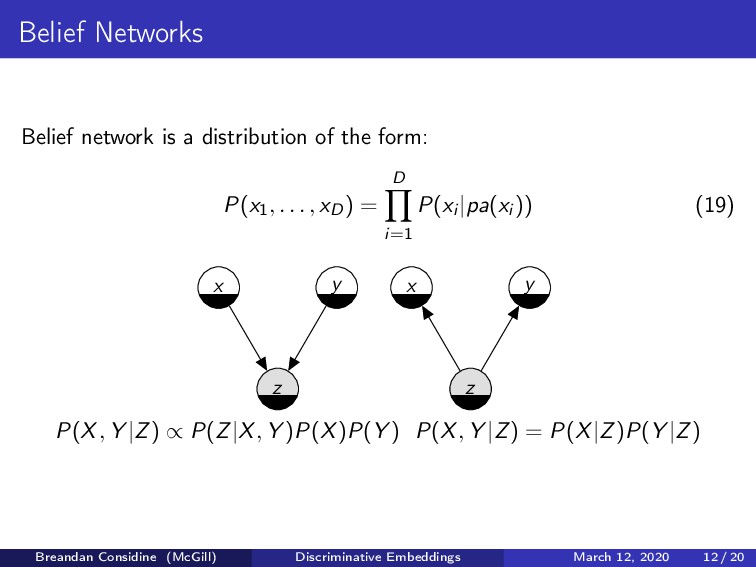
P(x1, . . . , xD) = D i=1 P(xi |pa(xi )) (19) z x y z x y P(X, Y |Z) ∝ P(Z|X, Y )P(X)P(Y ) P(X, Y |Z) = P(X|Z)P(Y |Z) Breandan Considine (McGill) Discriminative Embeddings March 12, 2020 12 / 20
Cristianini and Shawe-Taylor, Kernel Methods for Pattern Analysis Kriege et al., Survey on Graph Kernels Panangaden, Notes on Metric Spaces Fasshauer, Positive Definite Kernels: Past, Present and Future Cuturi, Positive Definite Kernels in Machine Learning Gormley and Eisner, Structured Belief Propagation for NLP Forsyth, Mean Field Inference Tseng, Probabilistic Graphical Models Görtler, et al. A Visual Exploration of Gaussian Processes Breandan Considine (McGill) Discriminative Embeddings March 12, 2020 20 / 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}