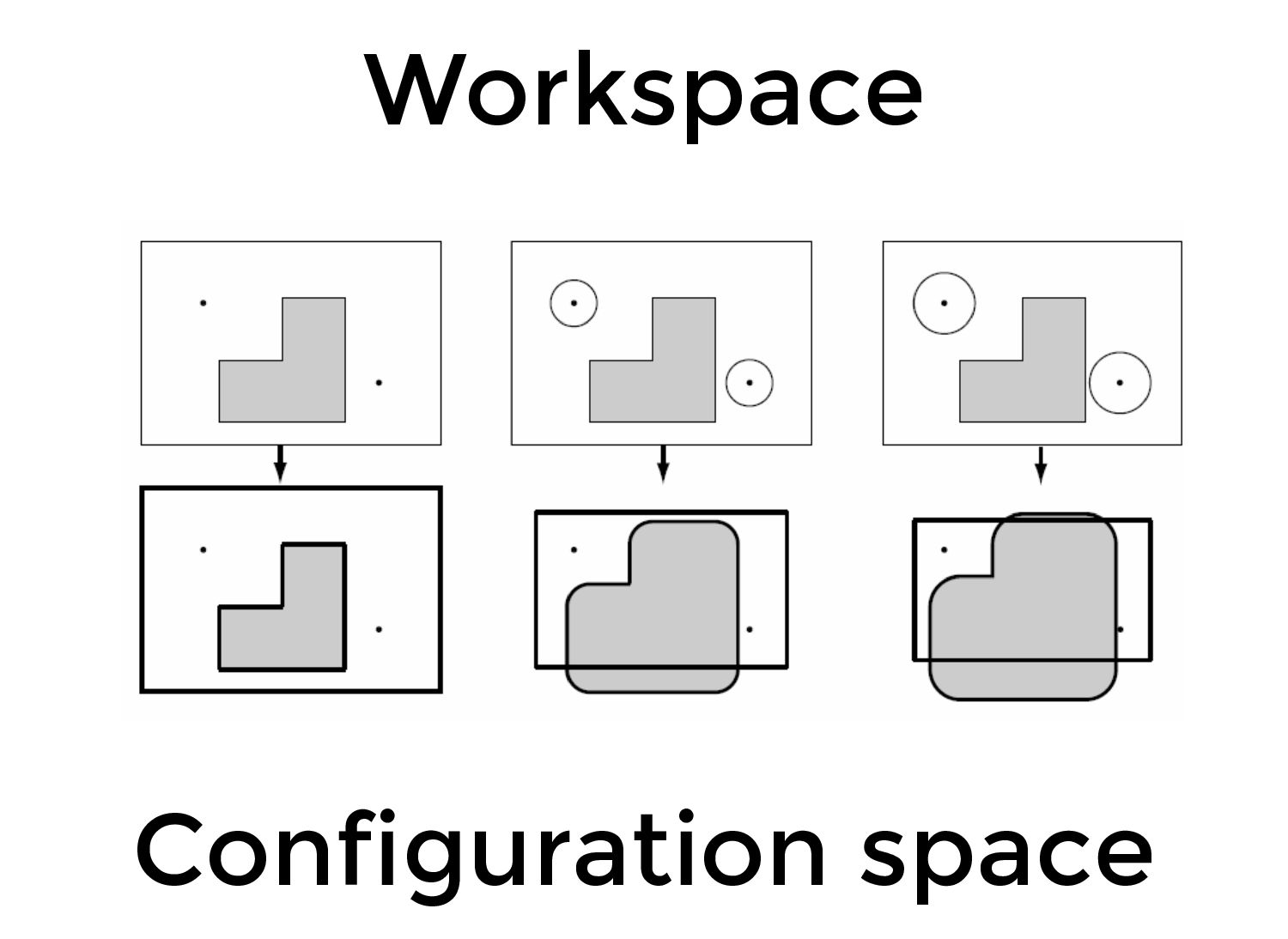
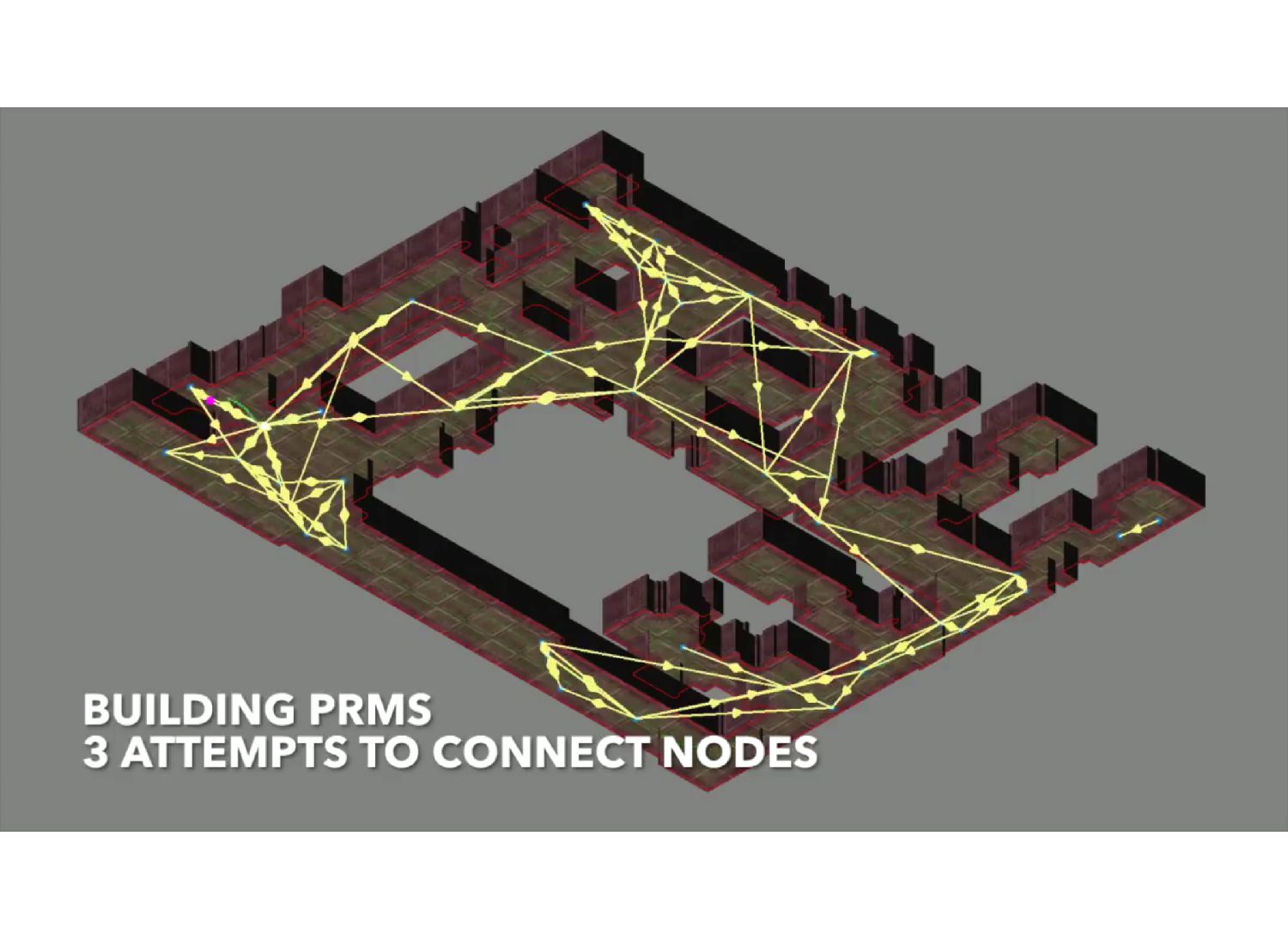
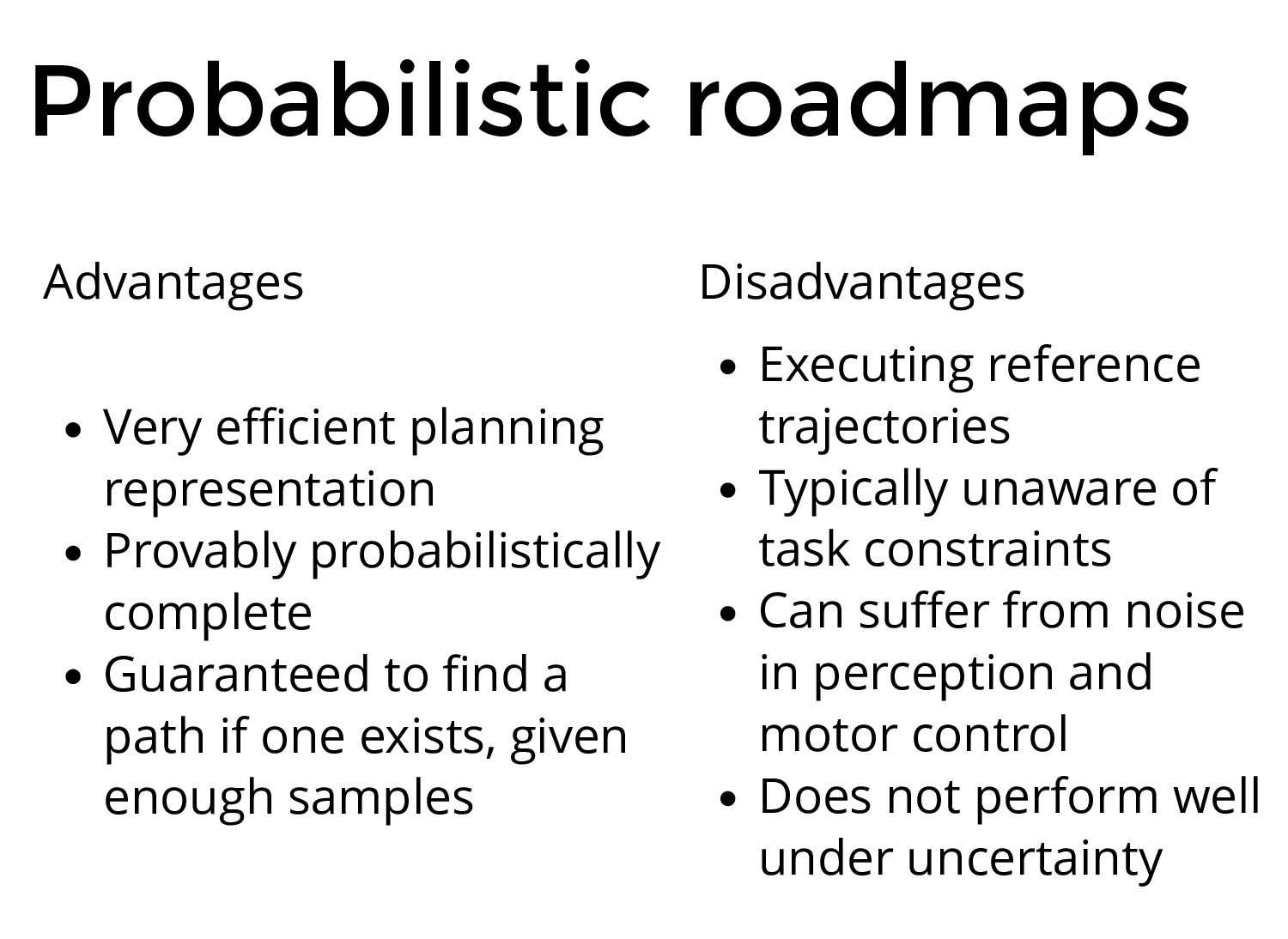
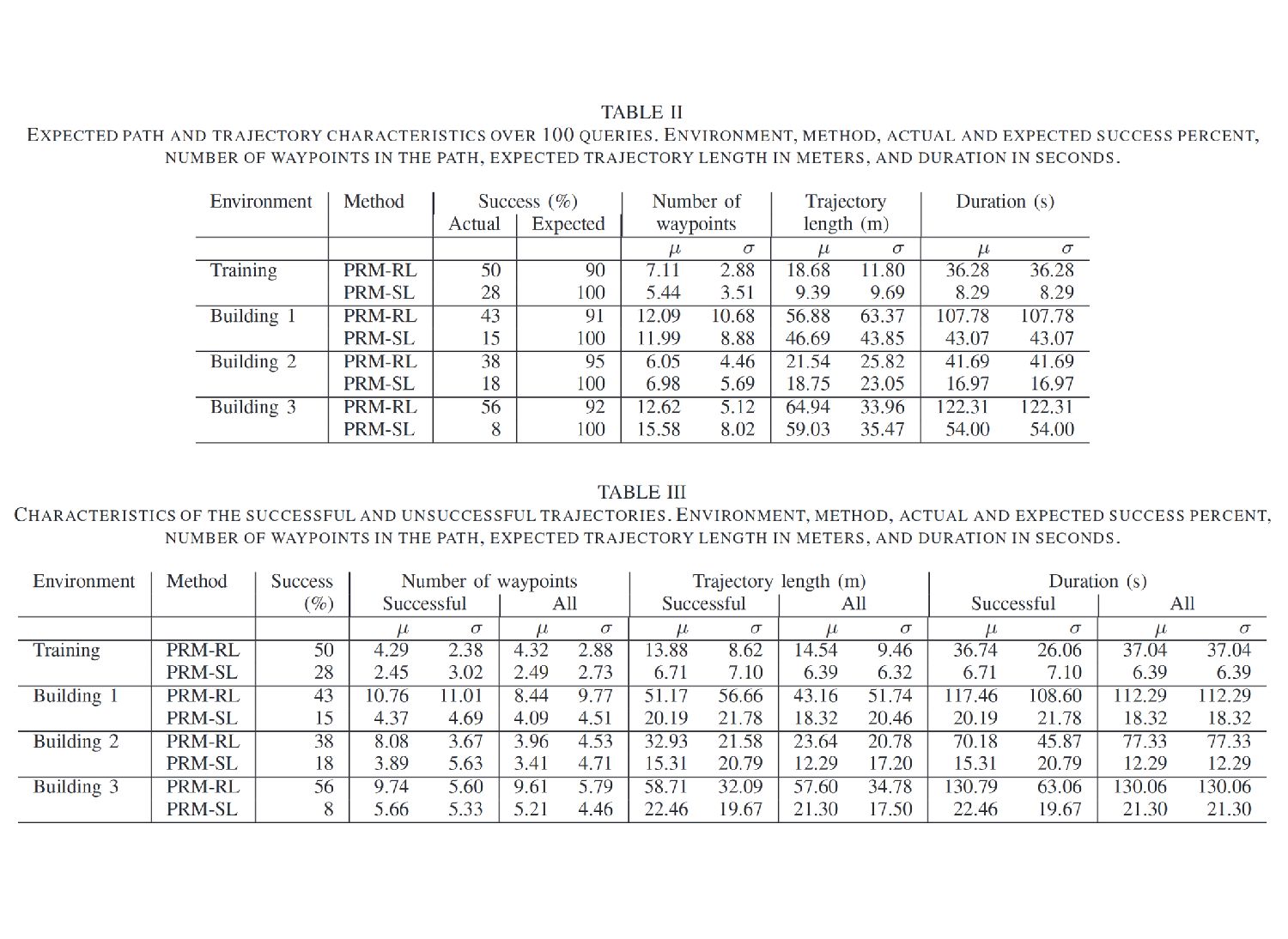
" Probabilistic roadmaps (PRMs) have a long and productive history in robotic motion planning. First conceived in 1996, they operate by sampling a set of points in configuration space and connecting these points using a simple line-of-sight algorithm. While PRM-based methods can construct efficient map representations, they share similar limitations with other sampling-based planners: PRMs do not consider external constraints such as the path feasibility and can suffer from unmodeled dynamics, sensor noise and non-stationary environments.
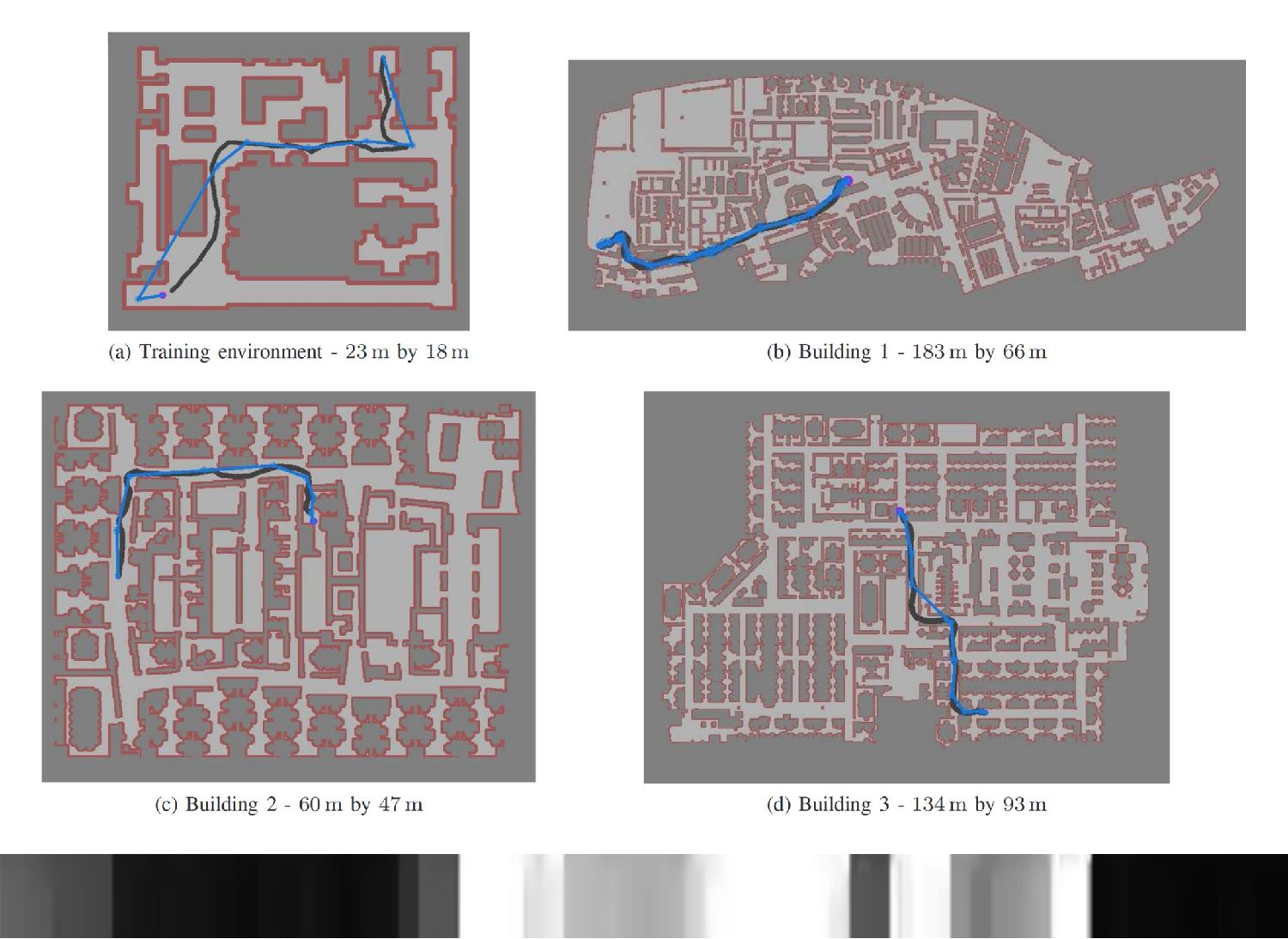
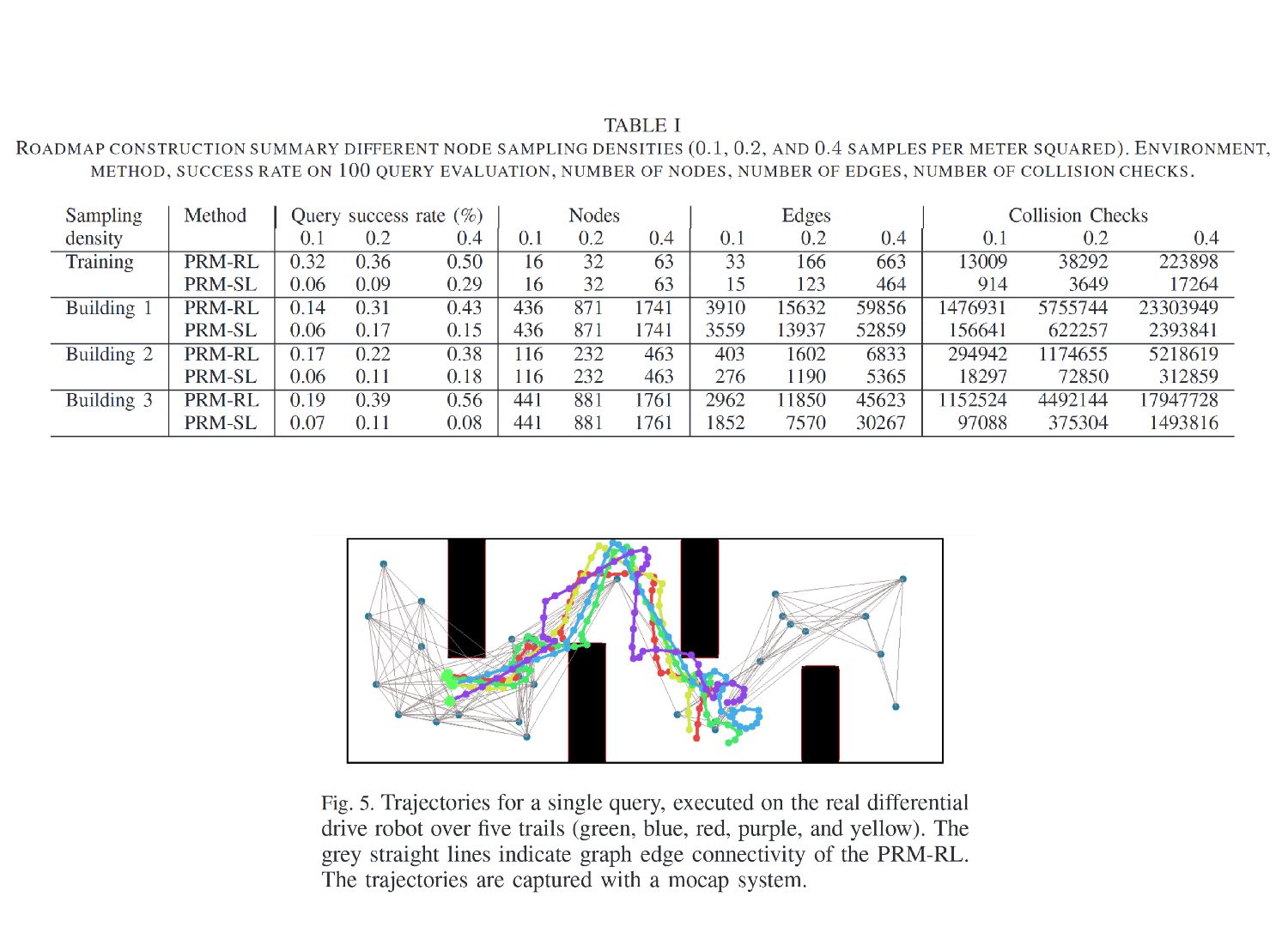
Correspondingly, RL algorithms such as DDPG and CAFVI suggest promising new alternatives to learn policies over long time horizons, by decomposing the learning task into a set of goals and subgoals. These algorithms can be robust to sensor noise, motion stochasticity, and are resilient to (moderate) changes in the environment but require efficient state representations and can often suffer from poor local minima. By combining PRMs and RL techniques, the authors present a compelling case for learning robot dynamics separately from the environment, a technique that is shown to scale to environments up to 63 million times larger than in simulation.
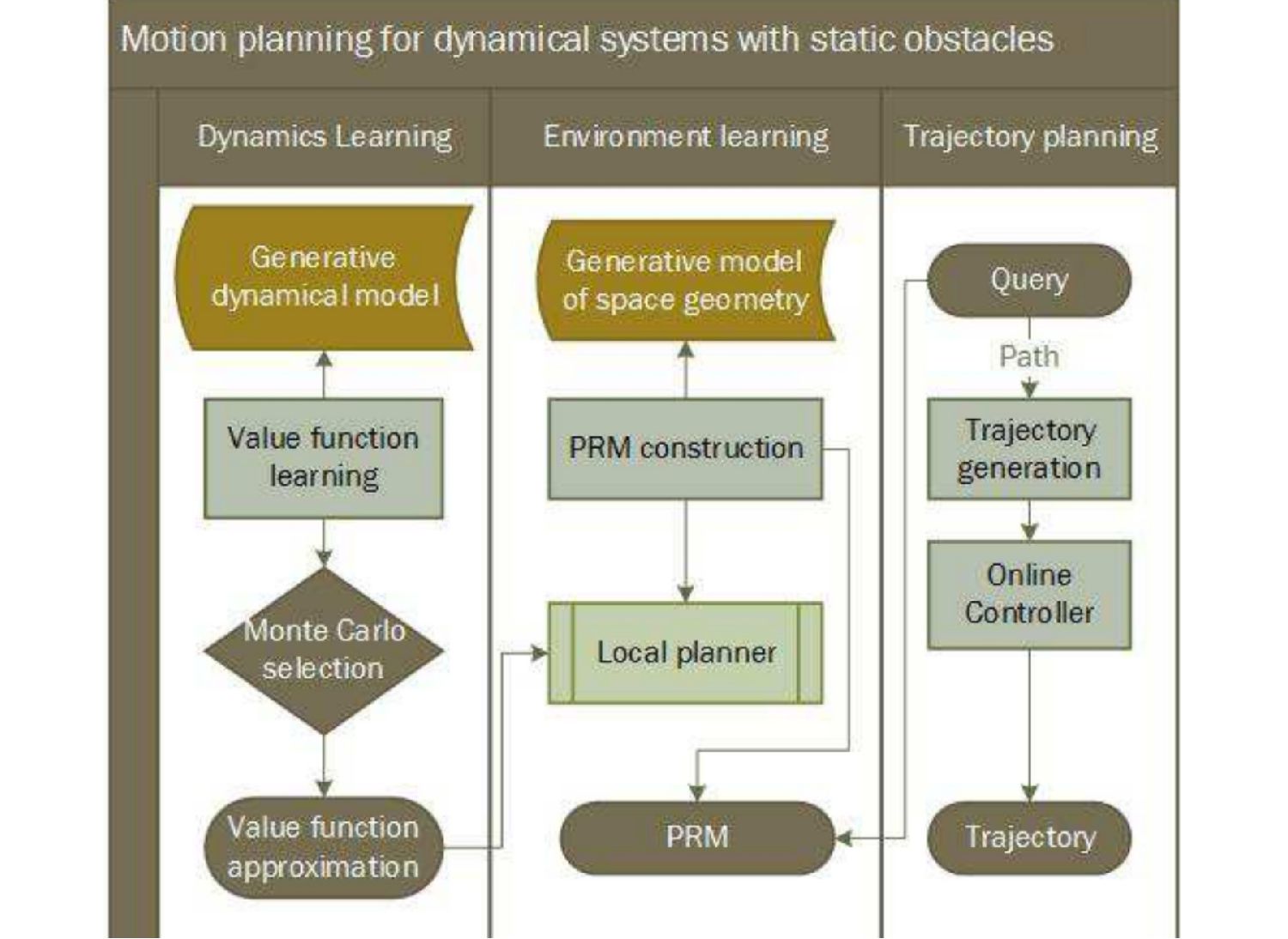
Fig. 4. PRM-RL: a prosperous handshake between of RL and classical robotics.
Specifically, the authors decouple the dynamics and noise estimation from the environment itself. First they learn the dynamics in a small training environment, and use that model to inform the local graph connectivity within the target environment. Instead of adding edges along all collision- free paths, they only draw edges which can be successfully navigated by the dynamics model in a high percentage of simulations. This process generates a roadmap that is more robust to noise and motion error and simultaneously less prone to poor local minima exhibited by naive HRL planners, ensuring continuous progress towards the goal state.
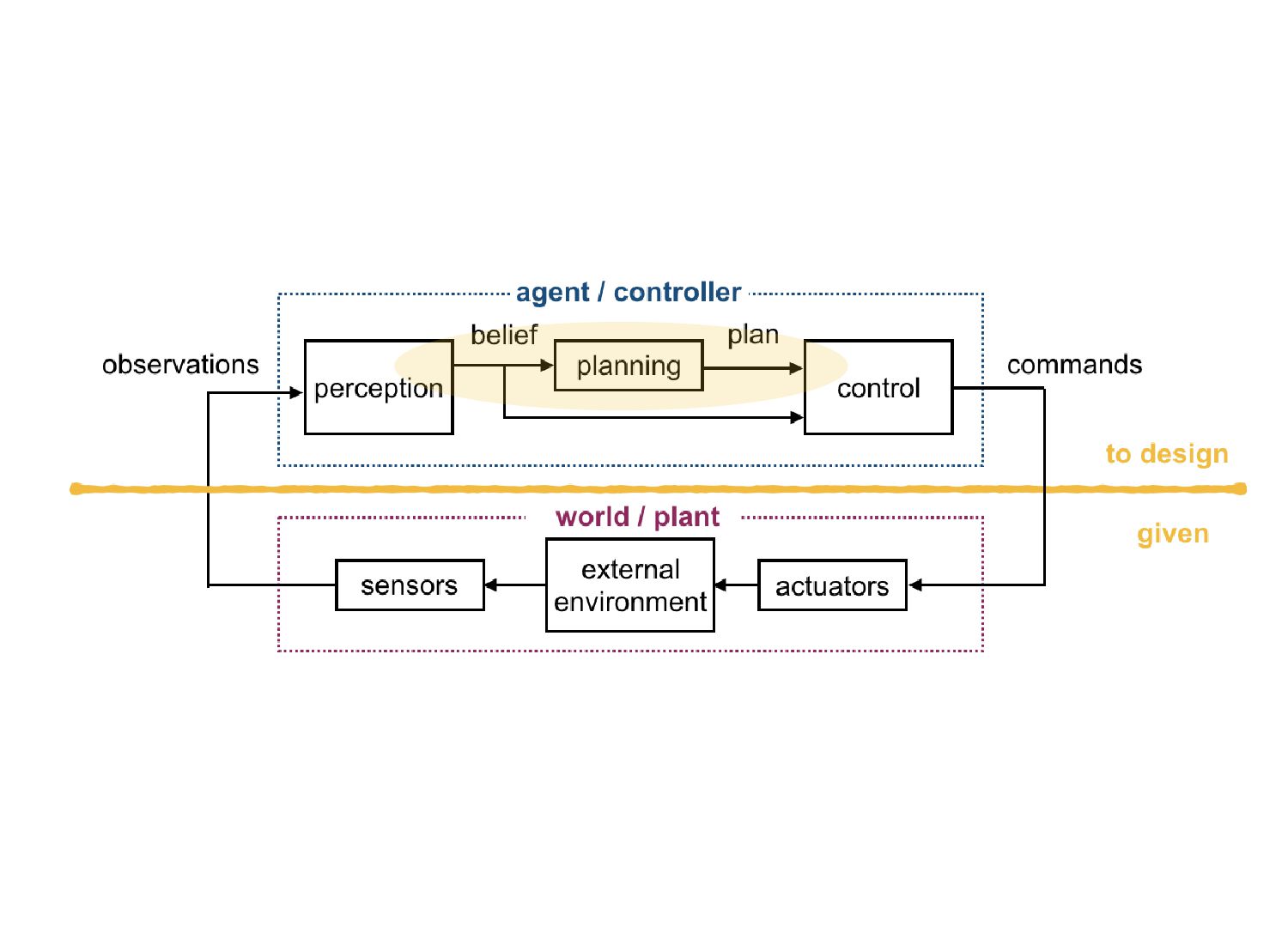
In this talk we will explore how to construct a dynamically feasible roadmap using RL, how to train a dynamics model using policy gradients and value function approximation, and finally how to query the PRM to produce practical reference trajectories. No prior understanding about motion planning, HRL or robotics is assumed or required. "
When: Monday, 05/11/18 at 2.00pm
Where: PAA 3195
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}