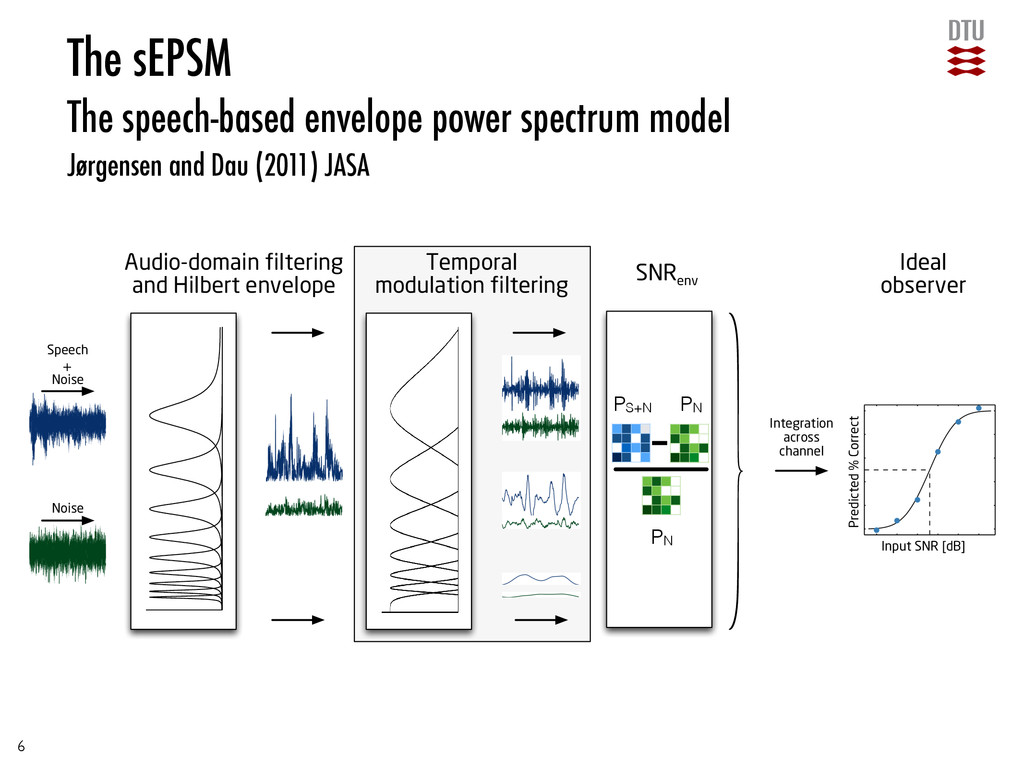
and Hilbert envelope Temporal modulation filtering SNR env Ideal observer Speech + Noise Noise Input SNR [dB] Predicted % Correct Integration across channel The sEPSM The speech-based envelope power spectrum model Jørgensen and Dau (2011) JASA PS+N PN PN
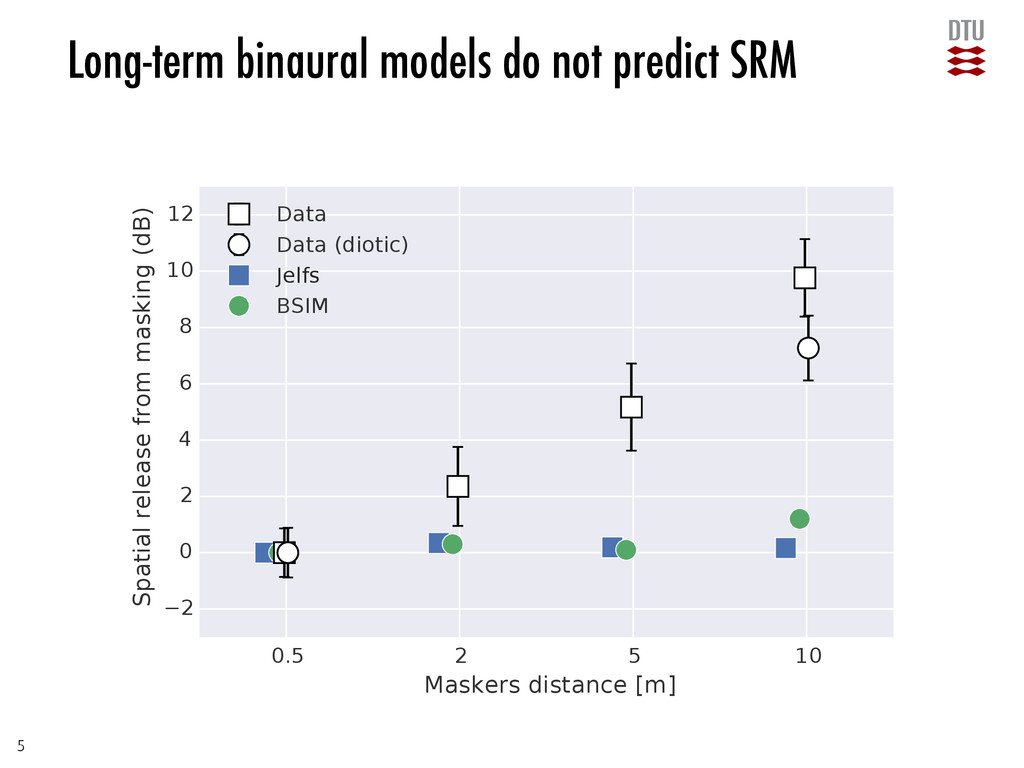
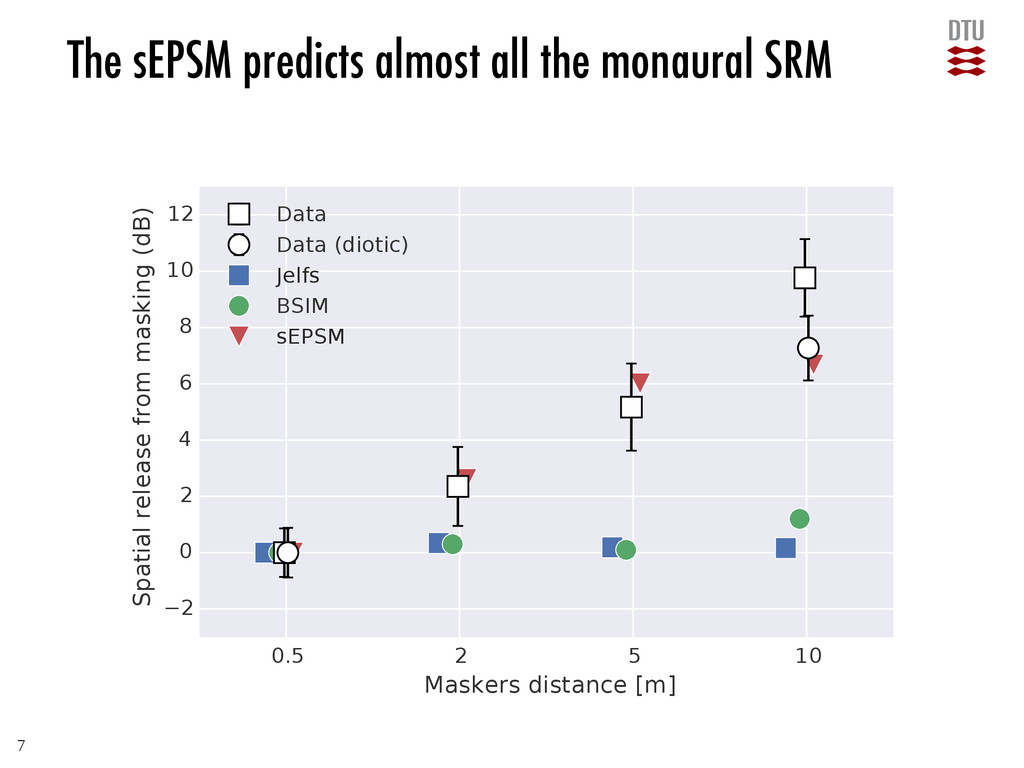
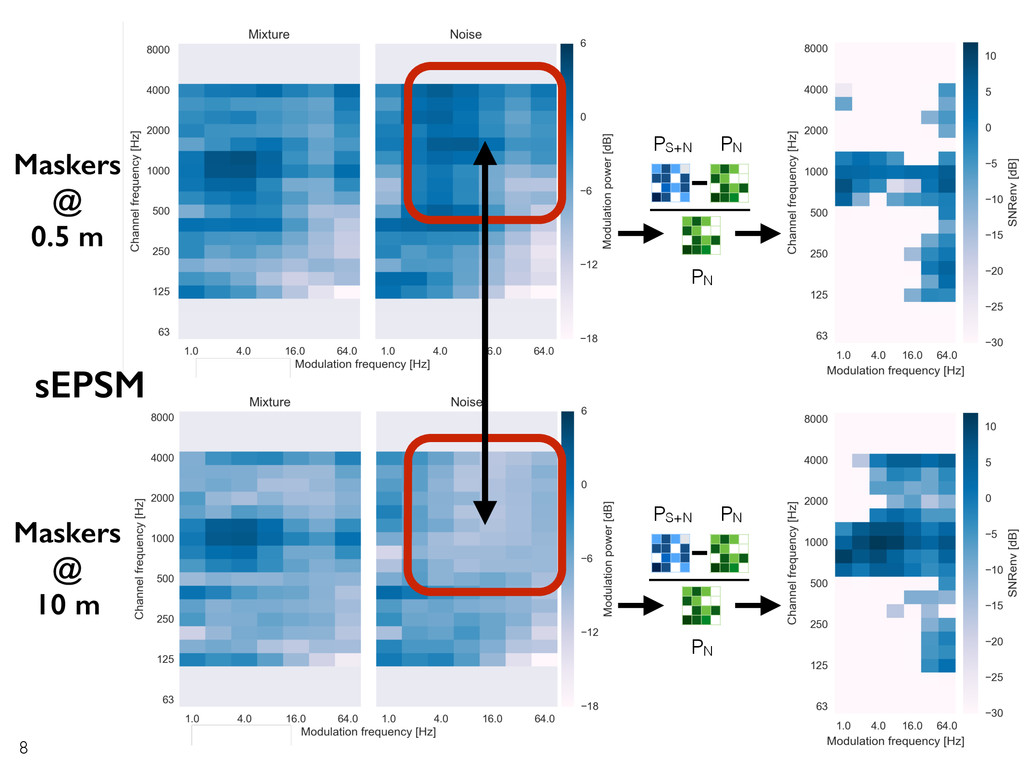
masking •The dominant factor seems to be release from informational masking, due to easier segregation. •Release from long-term modulation masking accounts for a large portion of the SRM. •… but is counteracted by increased masking from the maskers becoming more steady-state. •Release from long-term energetic masking does not contribute to SRM. •Long-term binaural processing does not provide and SRM. 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![0.5 2 5 10 Maskers distance [m] −2 0 2](https://files.speakerdeck.com/presentations/1a58bf501f19013285e132850c6494d8/slide_9.jpg){kind=link}
![0 2 10 5 10 0 Masker distance [m] Spatial](https://files.speakerdeck.com/presentations/1a58bf501f19013285e132850c6494d8/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}