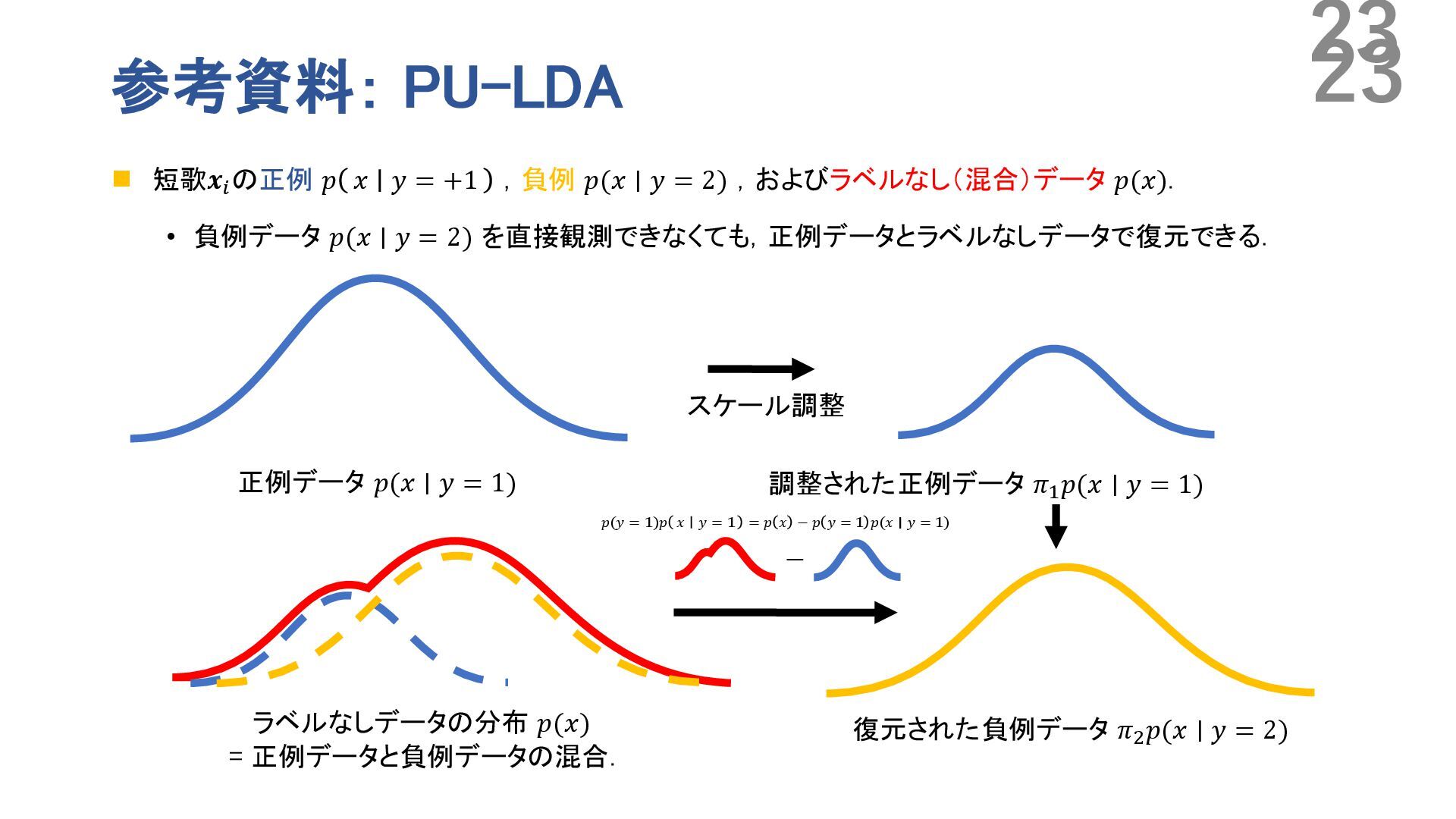
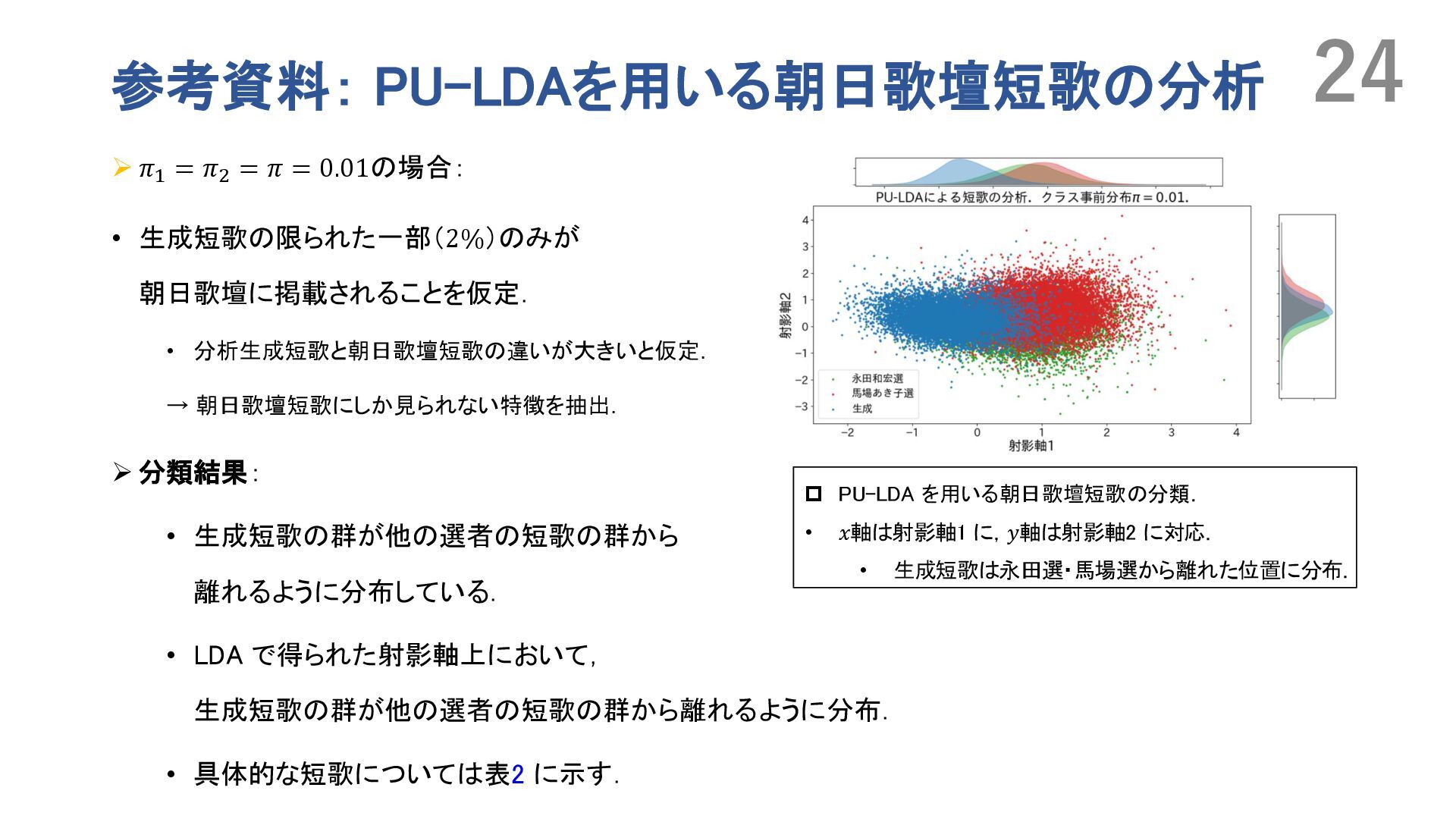
positive and unlabeled data,” in International Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery, 2008, p. 213–220. • S. Arora, Y. Liang, and T. Ma, “A simple but tough-to-beat baseline for sentence embeddings,” in International Conference on Learning Representations (ICLR), 2017. • Fisher, R. A.: The Use of Multiple Measurements in Taxonomic Problems, Annals of Eugenics, Vol. 7, No. 2, pp. 179–188 (1936). • 羽根田賢和,浦川通,田口雄哉,田森秀明,坂口慶祐,“RLHF を用いた「面白い」短歌の自動生成の試 み”,言語処理学会第30 回年次大会論文集,2024. • 新妻巧朗,田口雄哉,田森秀明: 計量テキスト分析のた めの文埋め込みによる探索的カテゴリ化,言語処 理学会 第 30 回年次大会,pp. 494–499 (2024). 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}