Buscando Dados do DynamoDb via ElasticSearch em Tempo Real
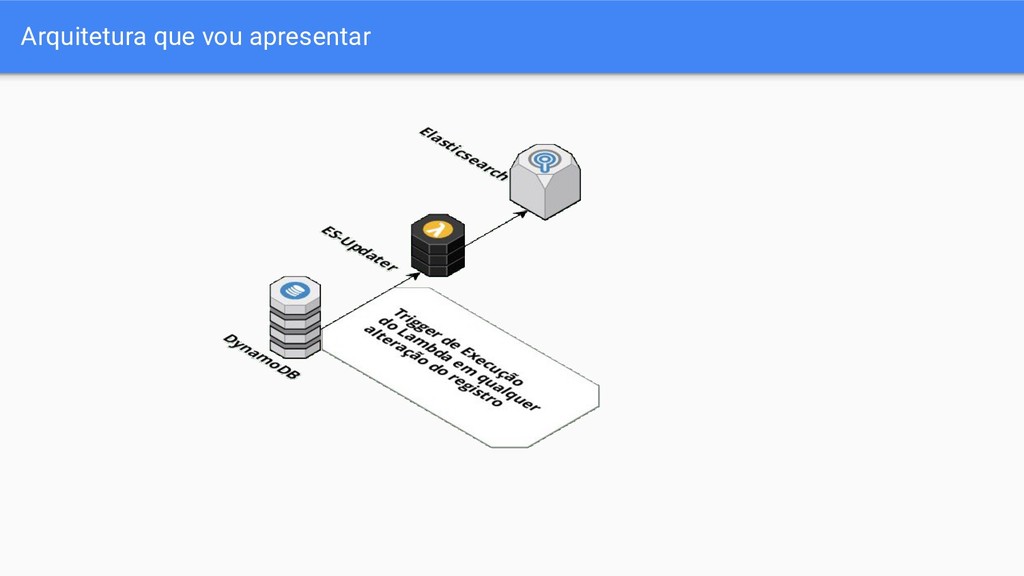
Nesta apresentação, eu faço um overview de uma arquitetura criada para fazer buscas em tempo real via Elasticsearch no DynamoDB.
Você vai ver:
Snippets de Código!
Dicas para o desenvolvimento!
Como resolver problemas comuns!
nossa plataforma com alta disponibilidade e alto potencial de personalização nas buscas. Requisitos • Novos dados devem ficar disponíveis em Near Real Time • É necessário fazer buscas por Latitude Longitude • É necessário filtrar elementos por características
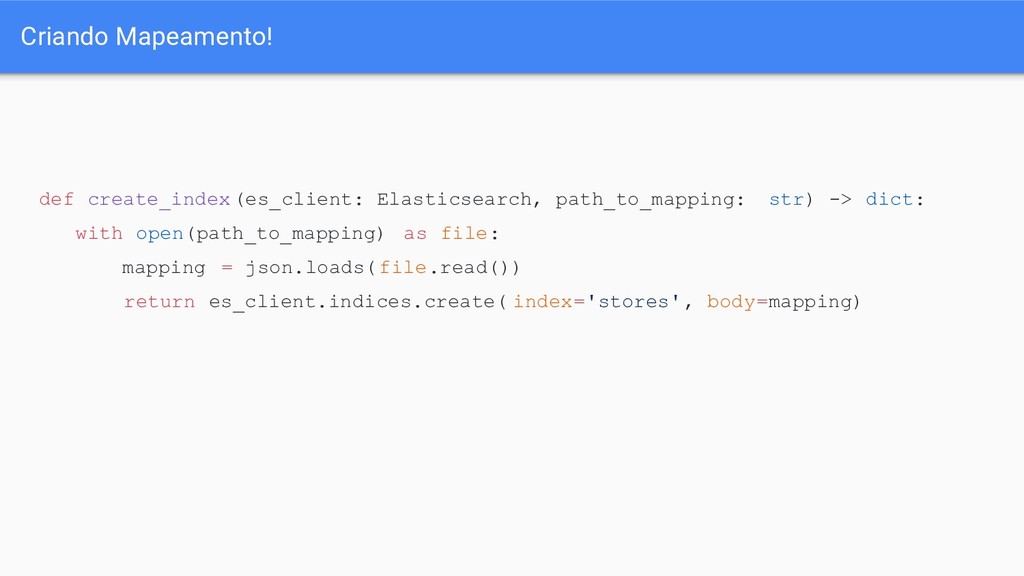
Pensar sempre nas queries que serão executadas, não na estrutura dos dados existentes ◦ Pense: Como serão as consultas? Quais os dados precisam ser retornados? Faz sentido trazer isso dessa forma? ◦ É muito provável que haverá bastante processamento antes de subir os dados do Dynamo para o ES ◦ É ainda necessário via Kibana ou outra interface, criar o mapeamento e o index. Nossa sorte que isso é bem simples em python!
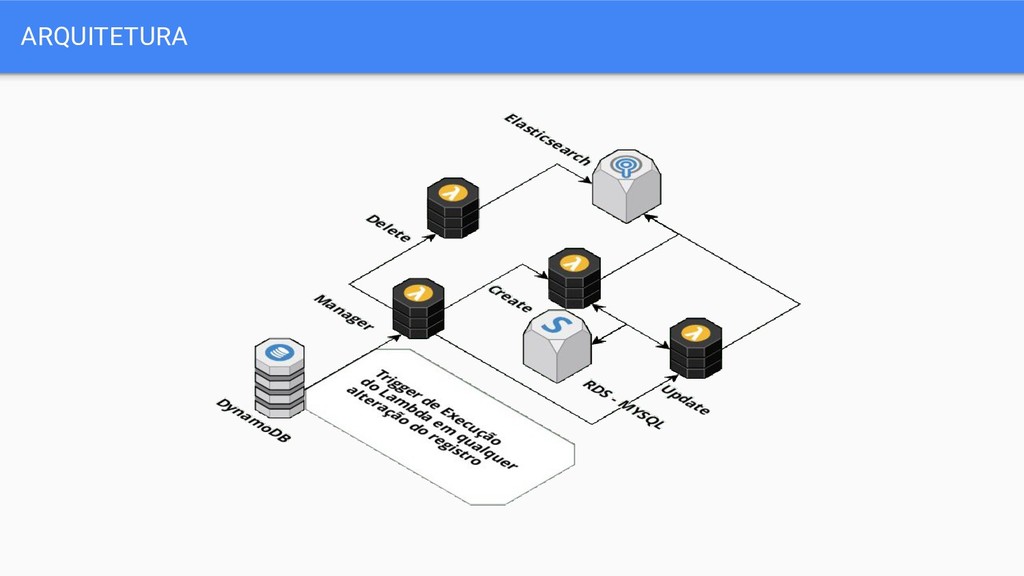
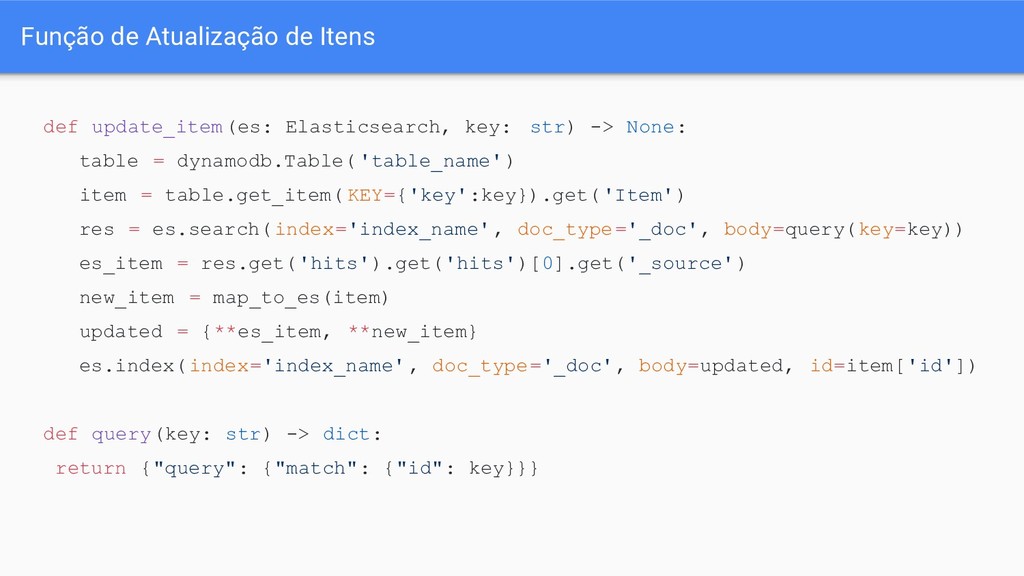
os dados, no DynamoDb é necessário ativar Stream da tabela que será assistida. ◦ Recomendação, criar uma função e fazer upload dela vazia que retorna o event pra teste, pra saber os tipos de dados que entram.
dynamodb e decidir o tipo de operação. ◦ REMOVE ◦ MODIFY ◦ INSERT • Cada operação necessita da sua própria implementação. ◦ É importante lembrar que o evento do Dynamo apenas retorna a chave do registro, então você vai ter que fazer a consulta de novo!
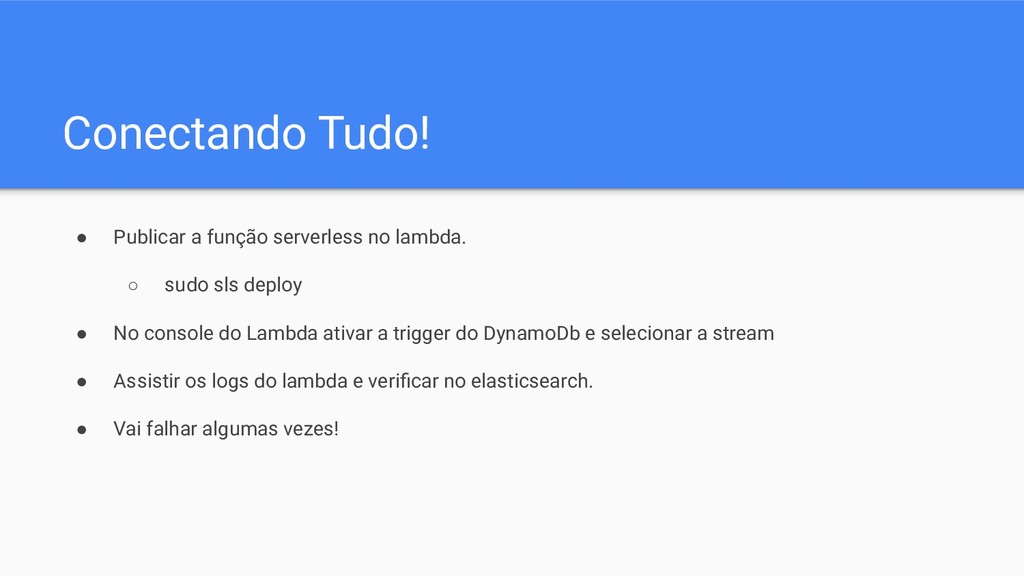
sudo sls deploy • No console do Lambda ativar a trigger do DynamoDb e selecionar a stream • Assistir os logs do lambda e verificar no elasticsearch. • Vai falhar algumas vezes!
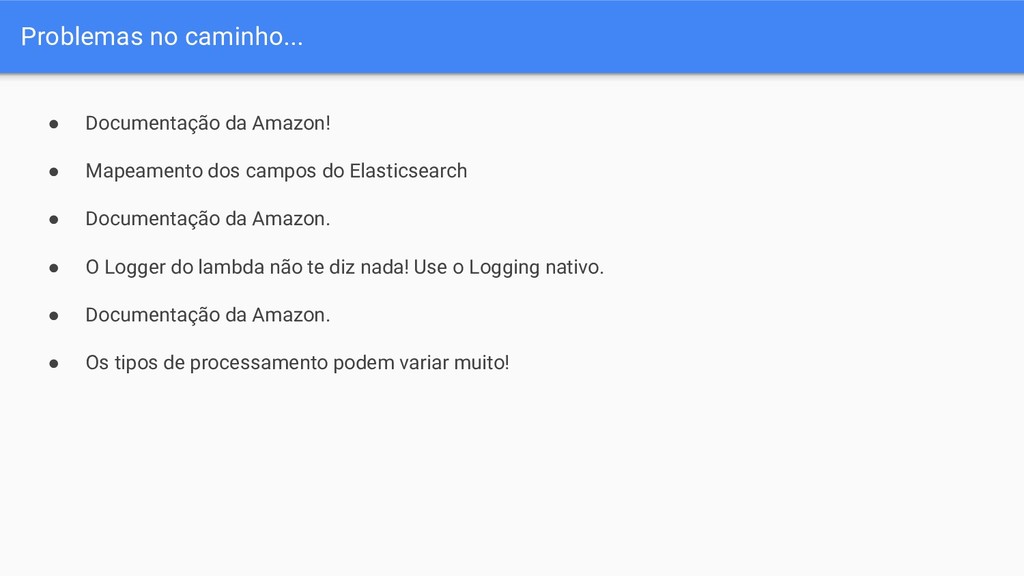
campos do Elasticsearch • Documentação da Amazon. • O Logger do lambda não te diz nada! Use o Logging nativo. • Documentação da Amazon. • Os tipos de processamento podem variar muito!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}