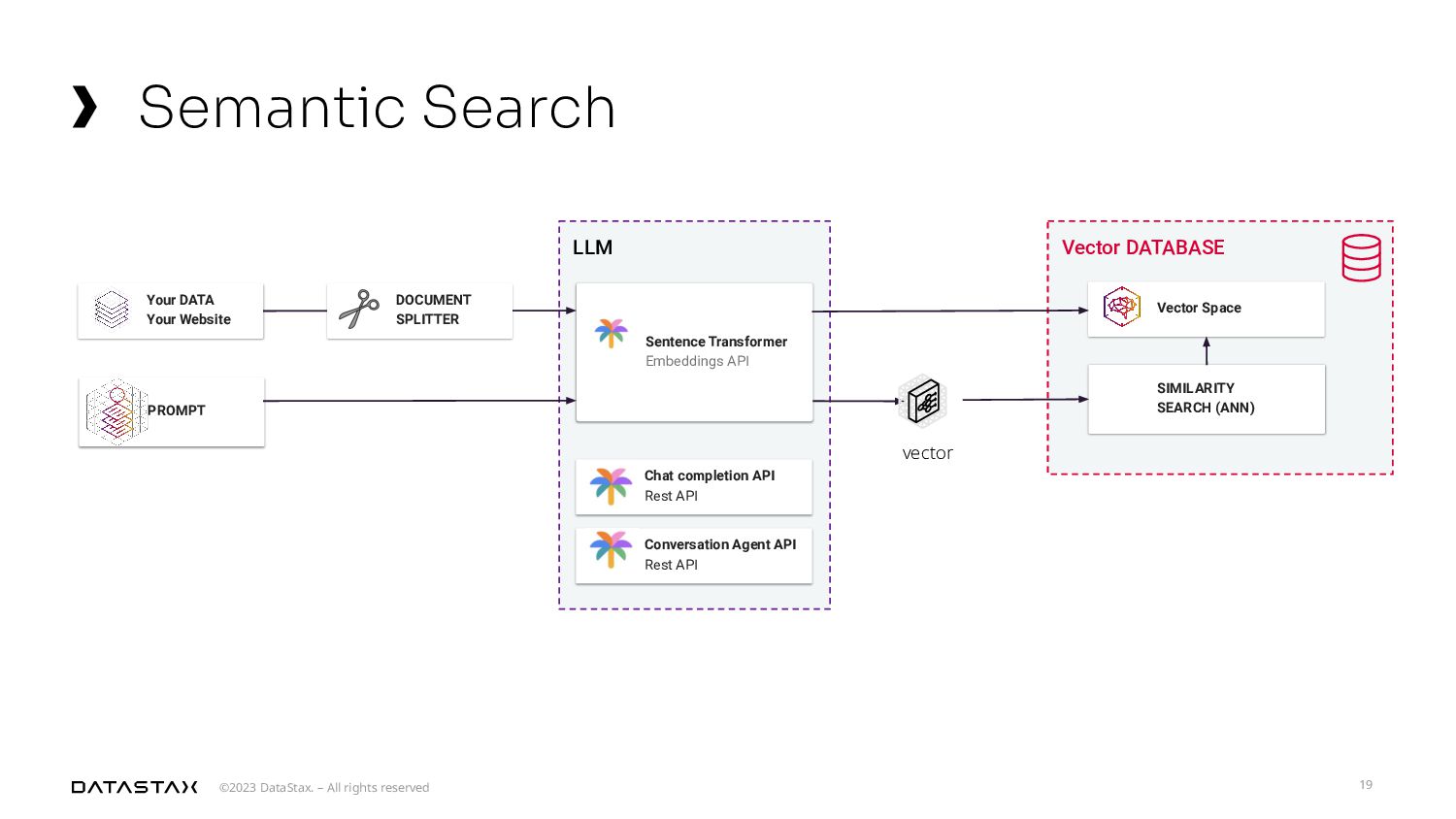
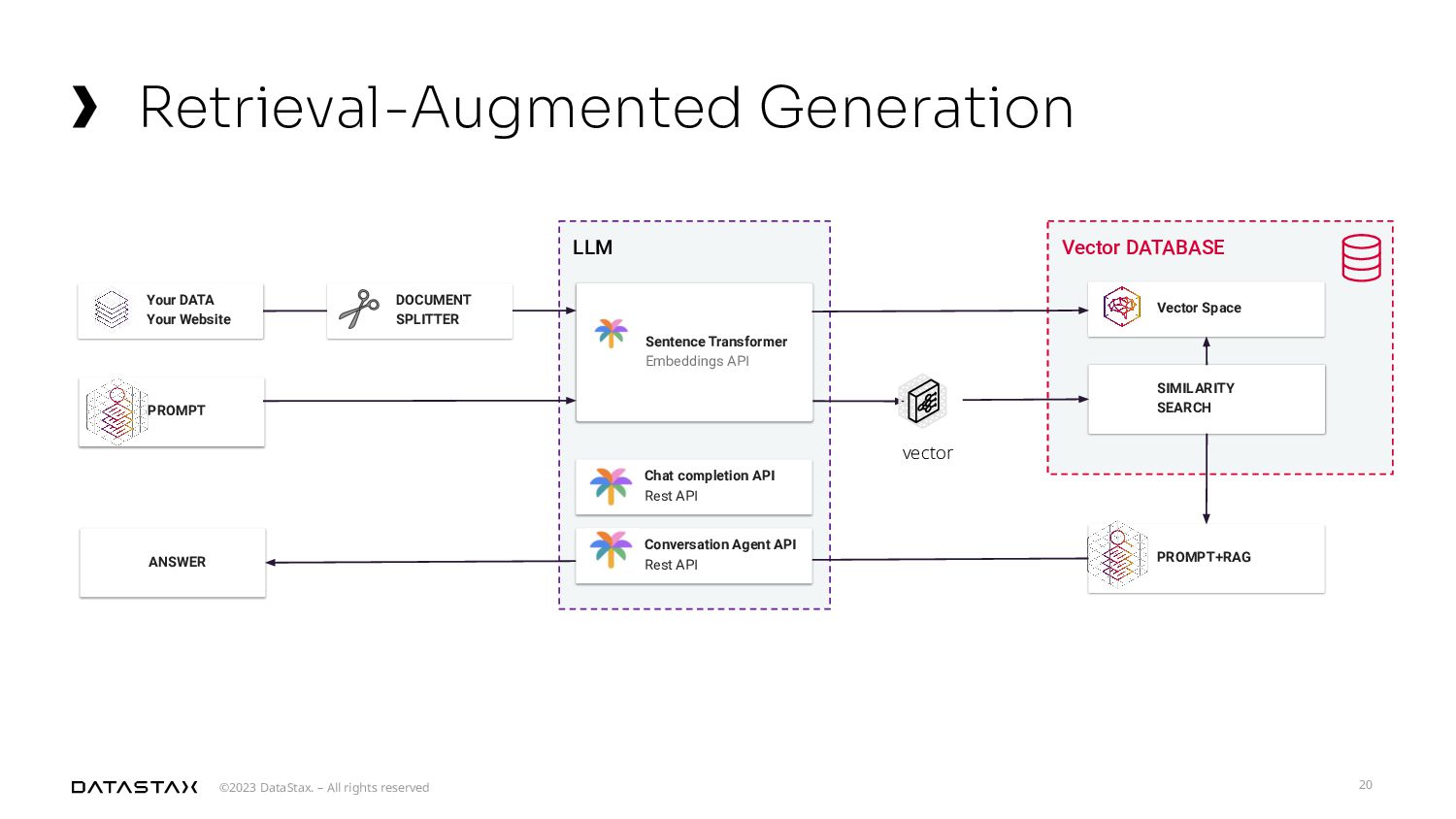
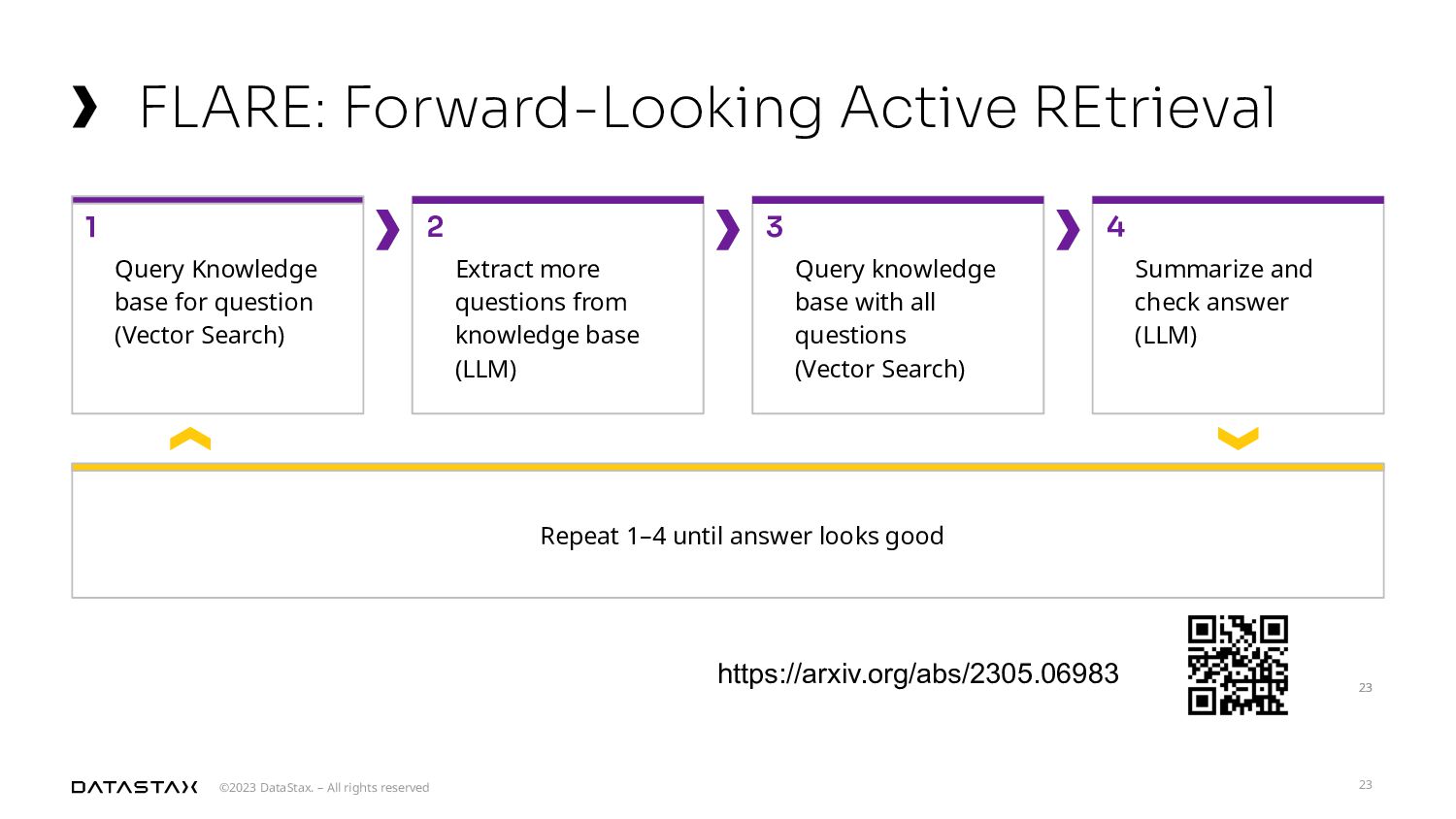
A laptop proof of concept won’t cut it for this impending era of generative AI. Let’s dig into the mechanics of building and using a petabyte-scale vector store and the future of handling data in generative AI models. This talk will focus on the work in the Apache Cassandra® project to develop a vector store capable of handling petabytes of data, discussing why this capacity is critical for future AI applications. I will also connect how this pertains to the exciting new generation of AI technologies like Improved Large Language Models (LLMs), Retrieval-Augmented Generation (RAG), and Forward-Looking Active Retrieval Augmented Generation (FLARE) that all contribute to the growing need for such scalable solutions. Finally, we’ll discuss the importance of planning for future scalability and how to effectively manage AI agents in this new age of data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
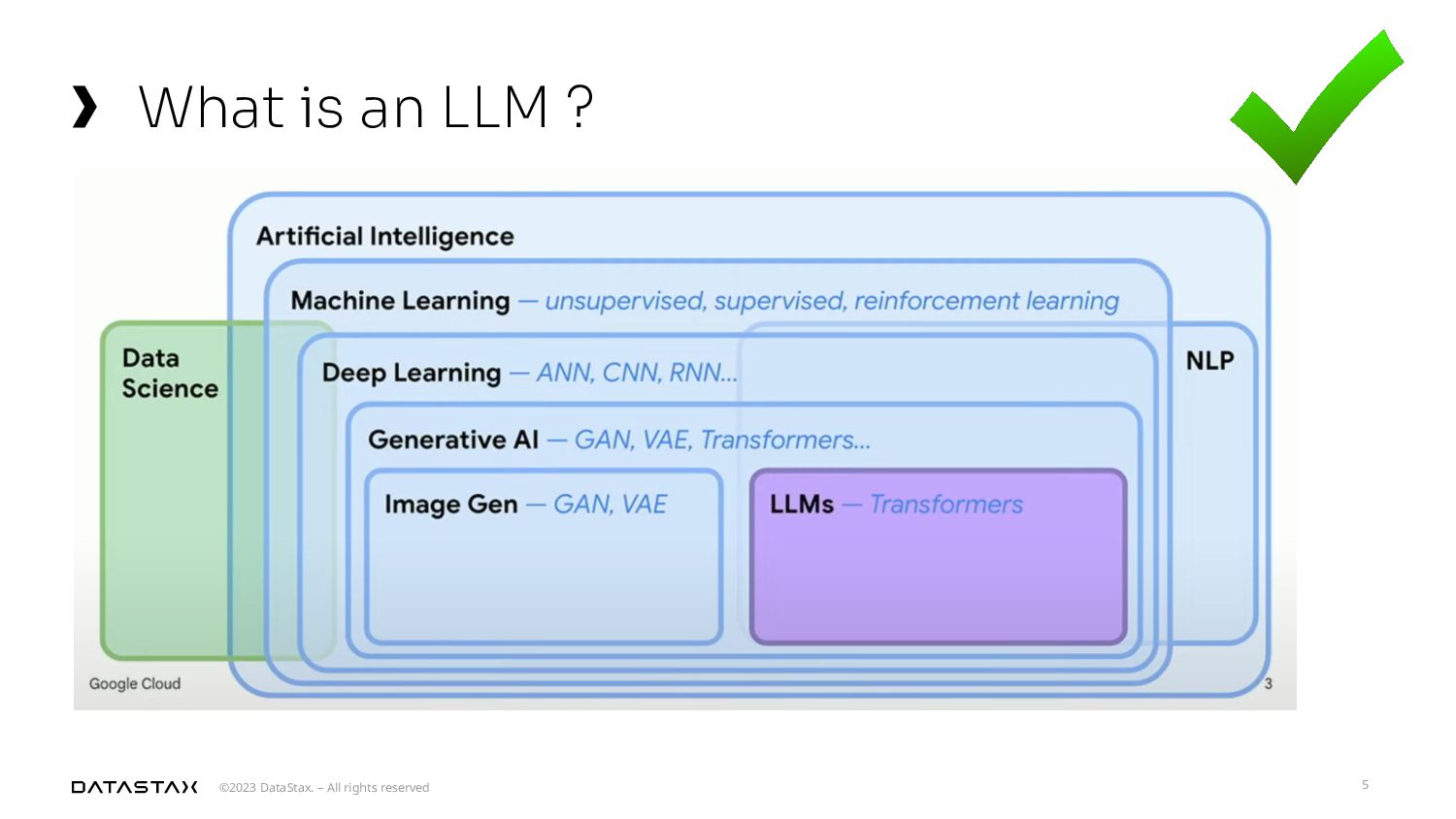{kind=link}
{kind=link}
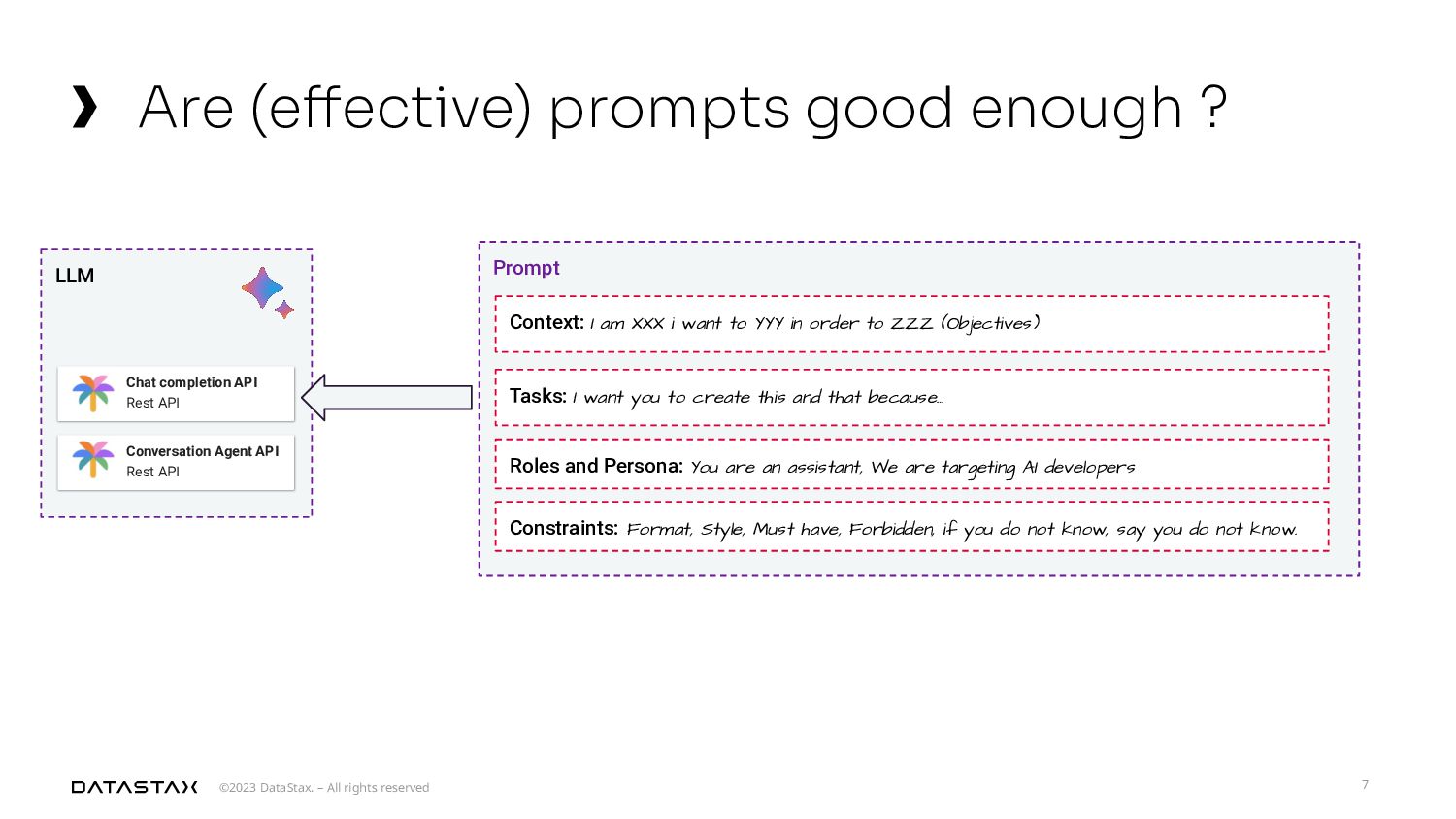{kind=link}
{kind=link}
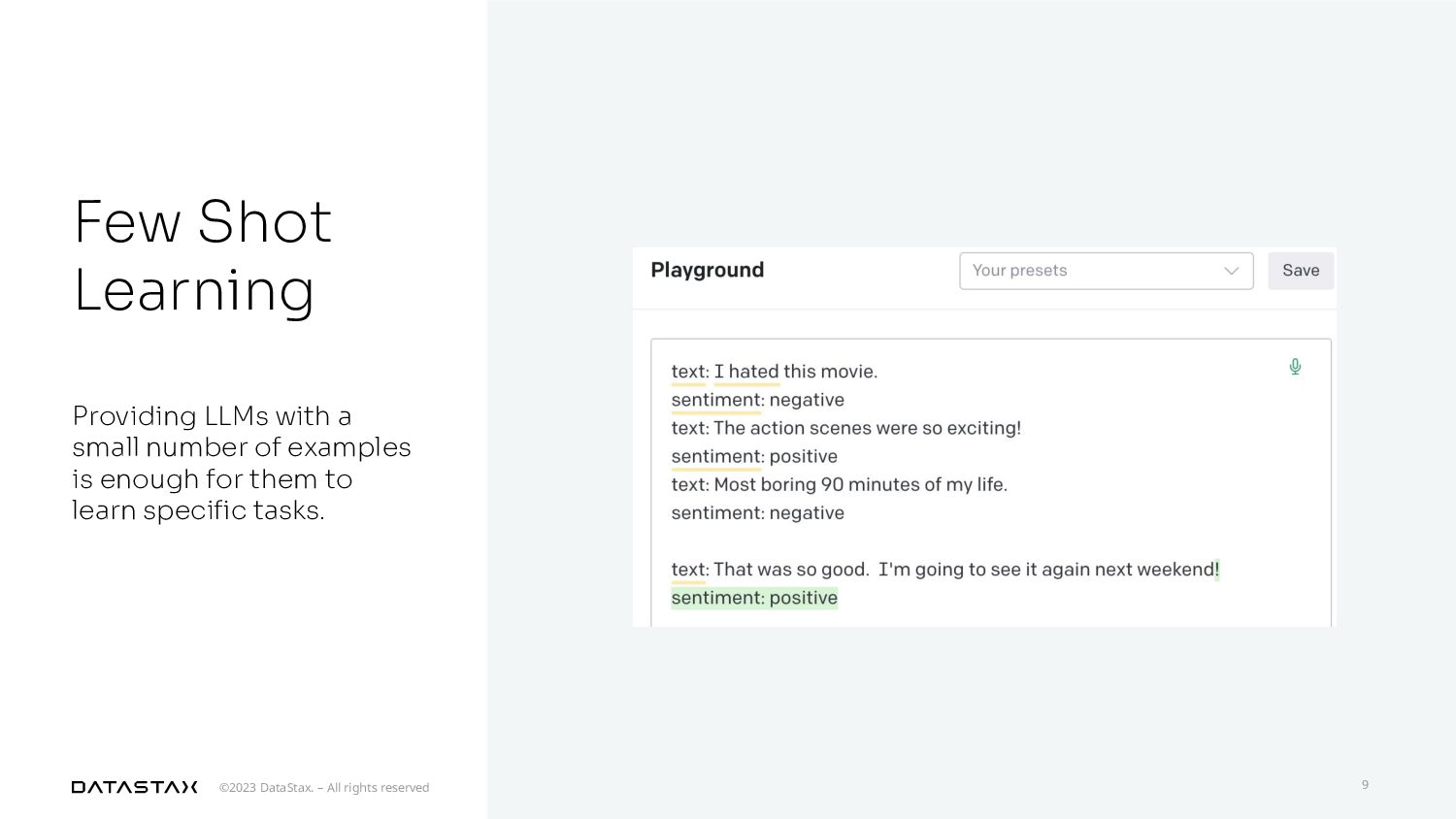{kind=link}
{kind=link}
{kind=link}
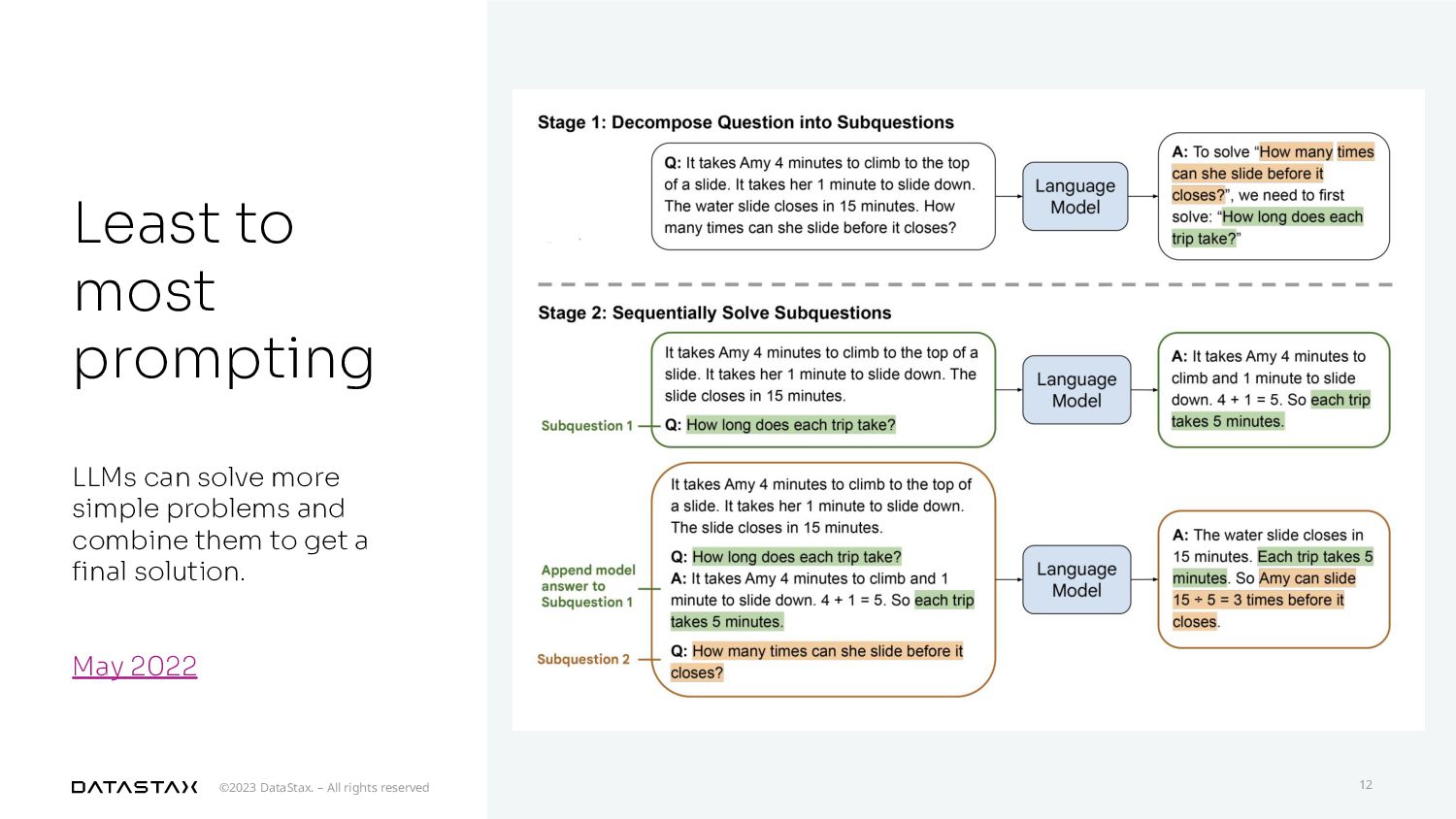{kind=link}
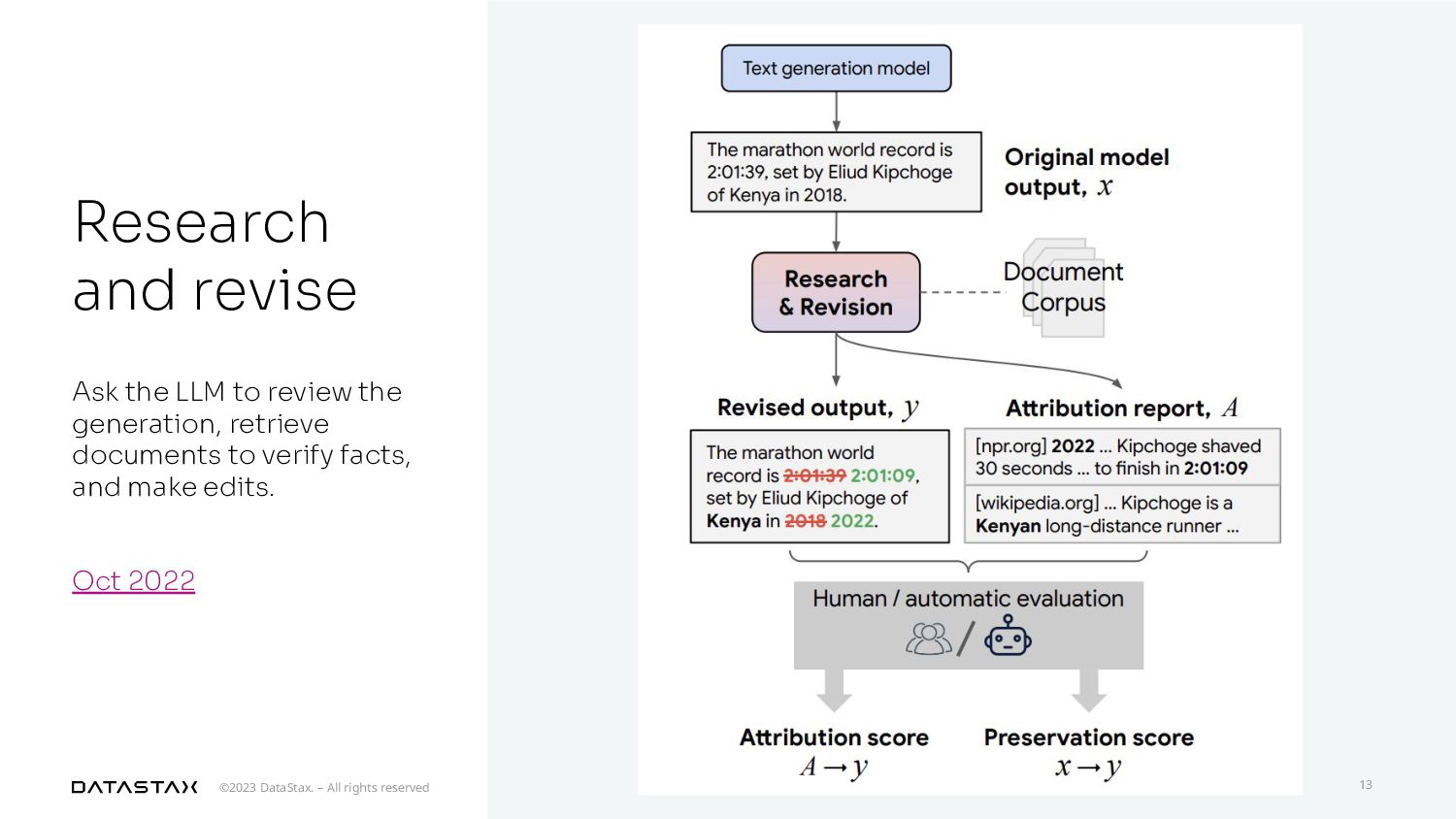{kind=link}
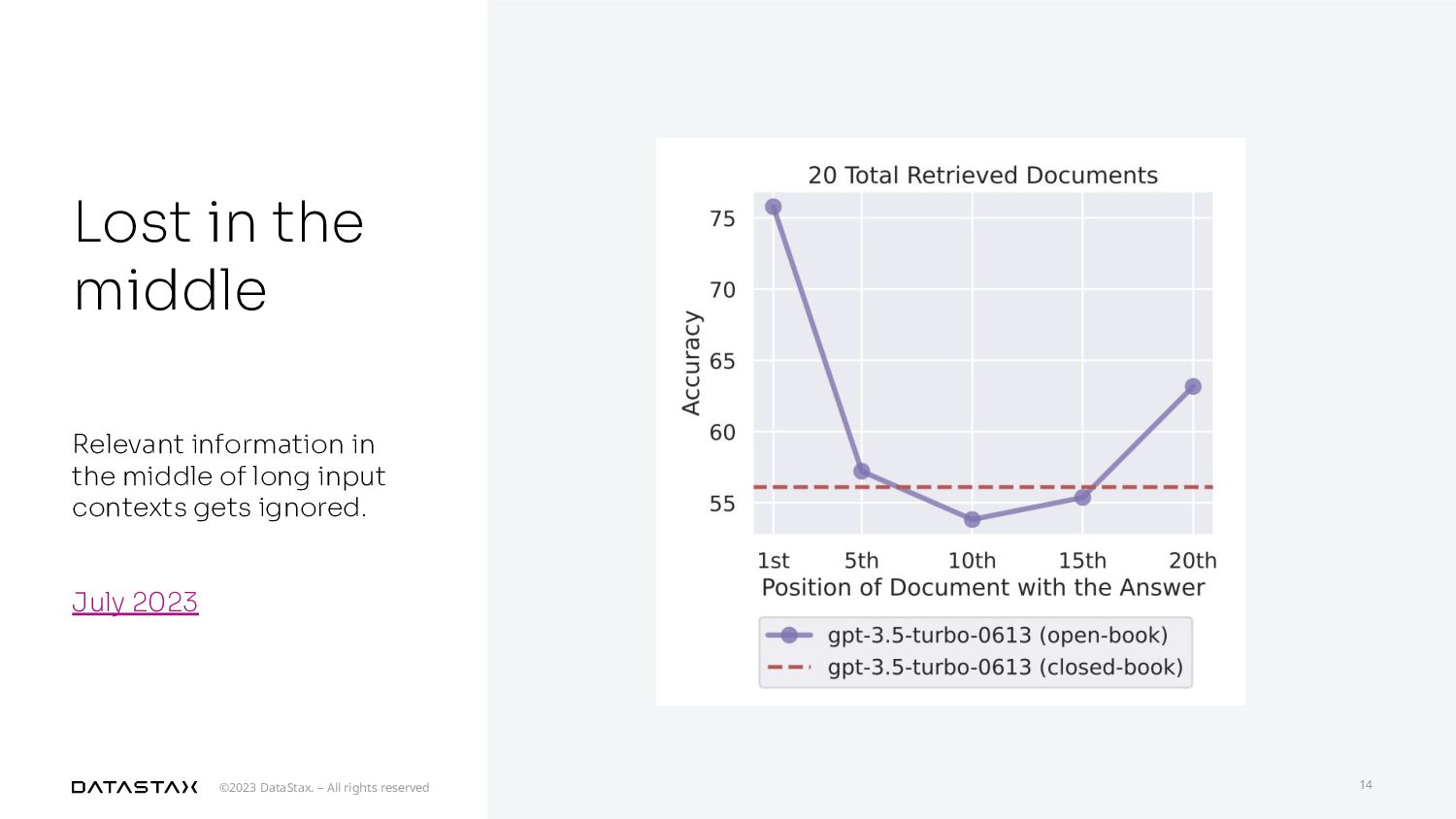{kind=link}
{kind=link}
{kind=link}
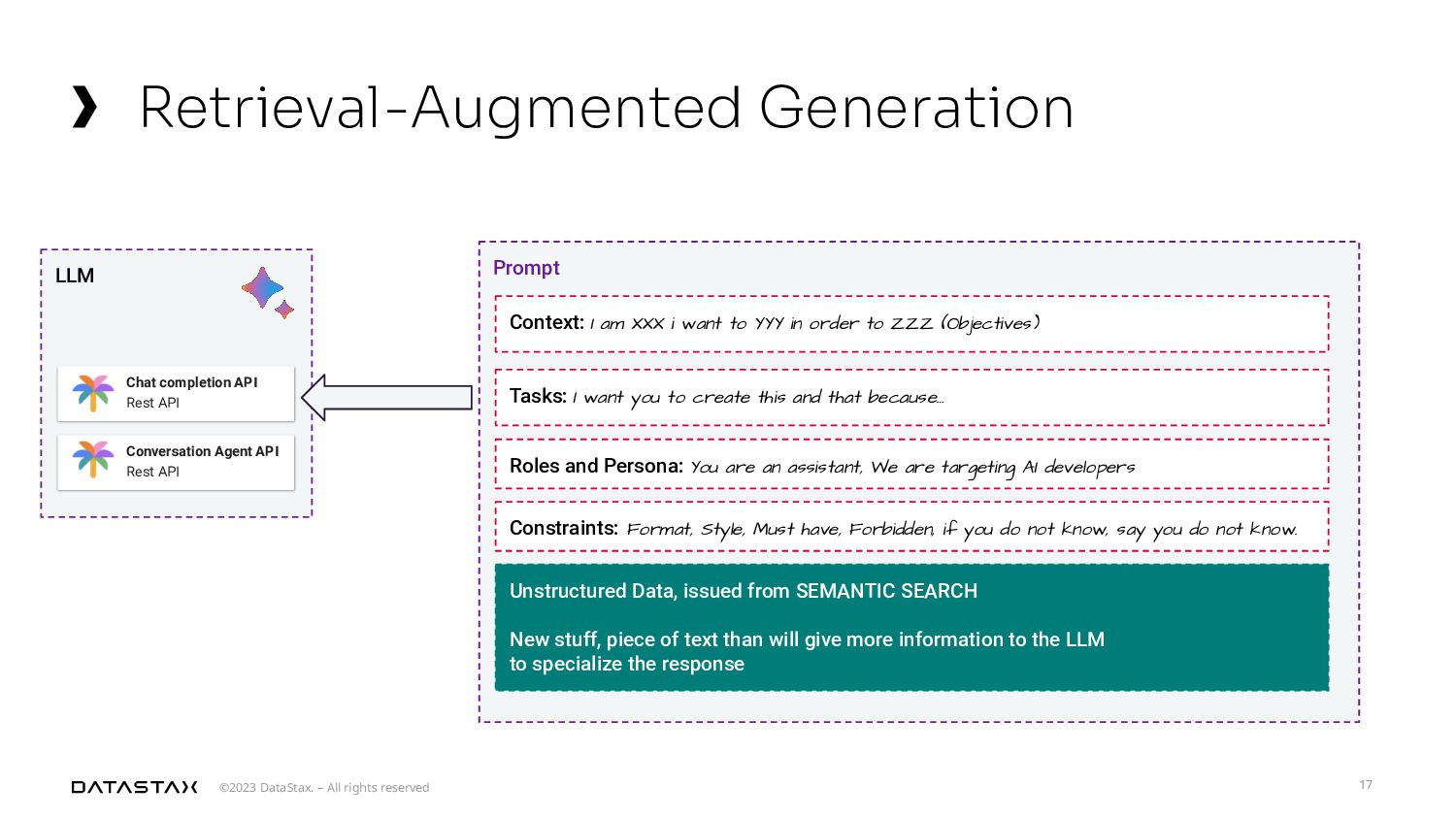{kind=link}
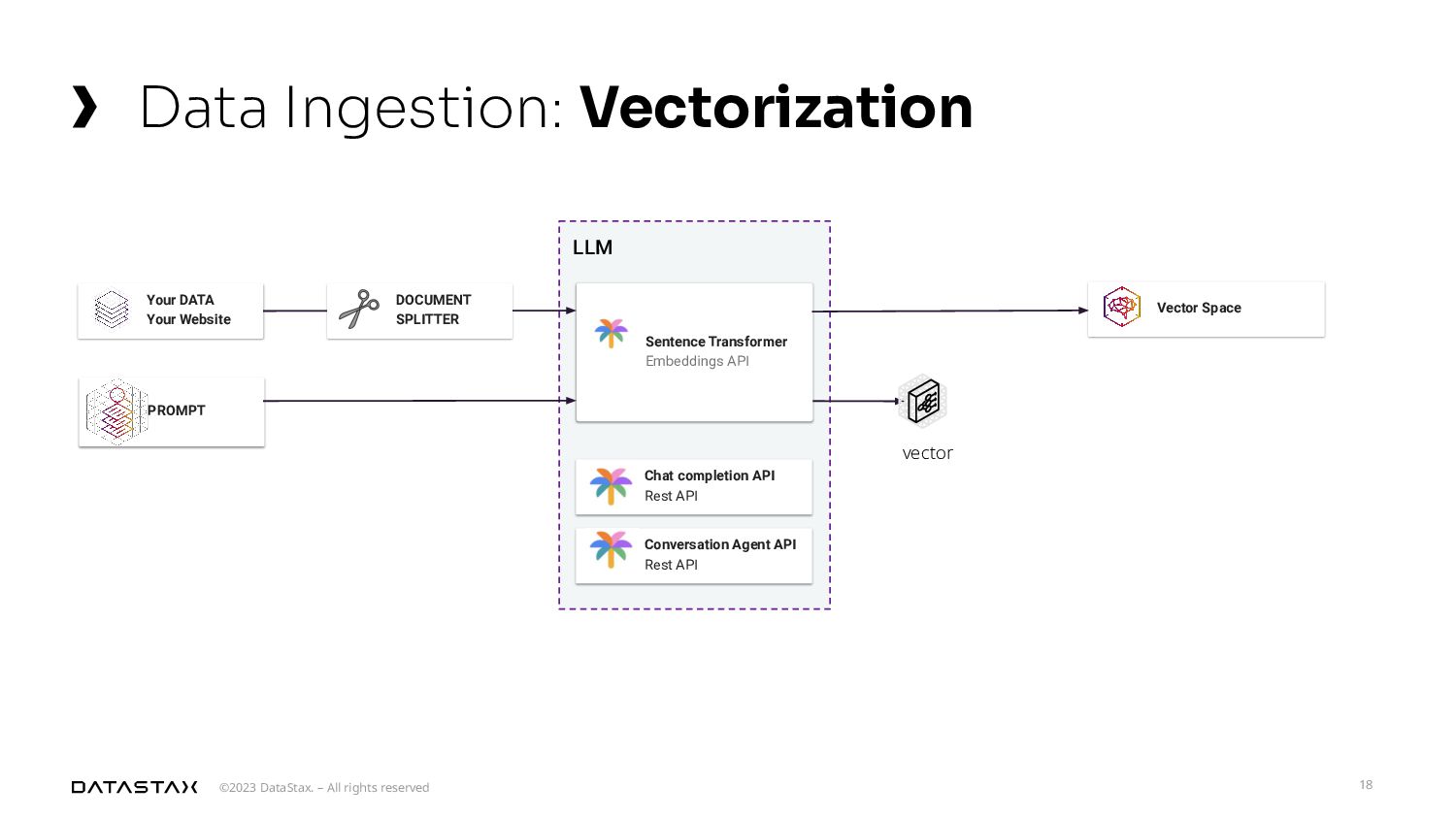{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
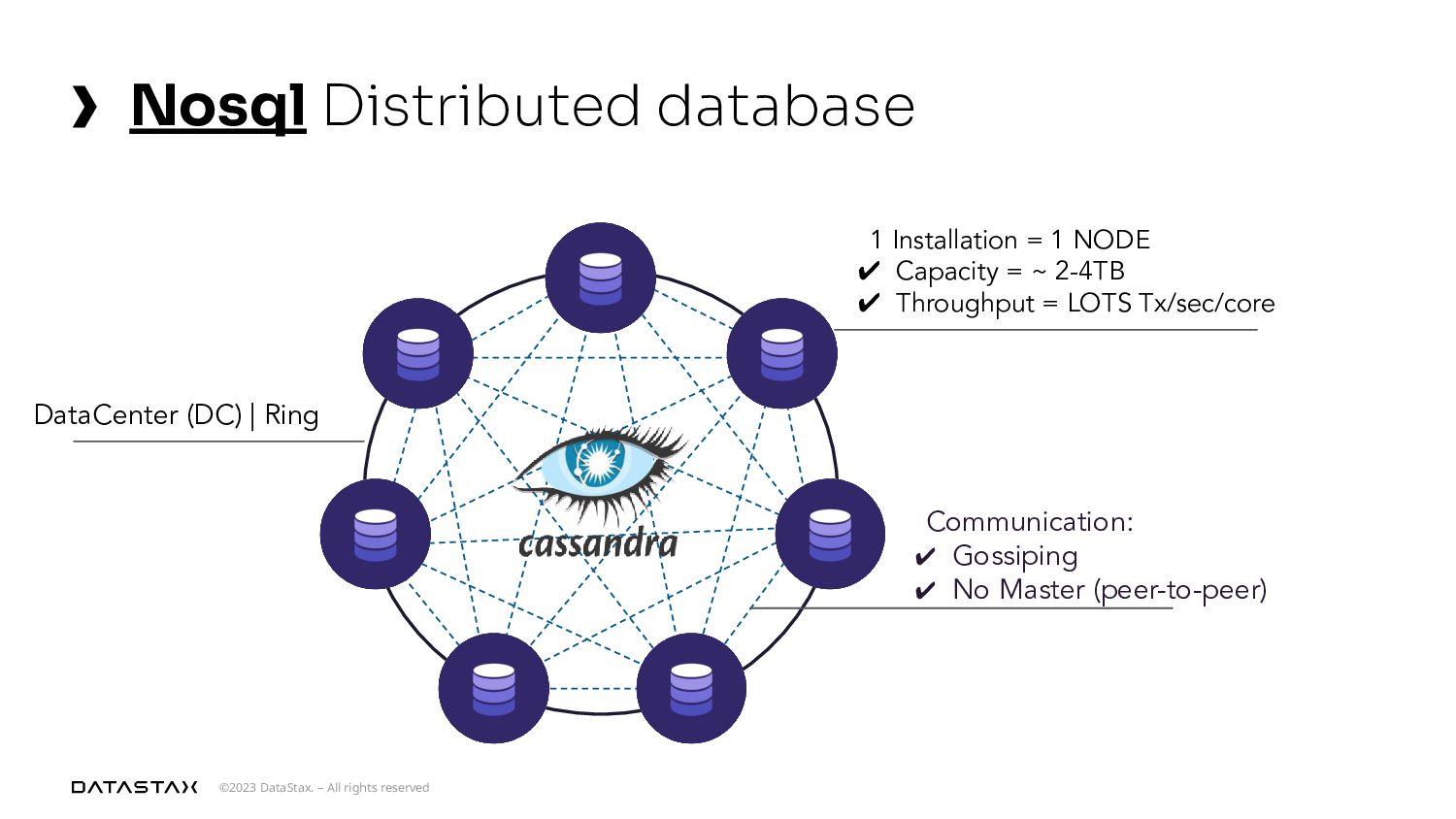{kind=link}
{kind=link}
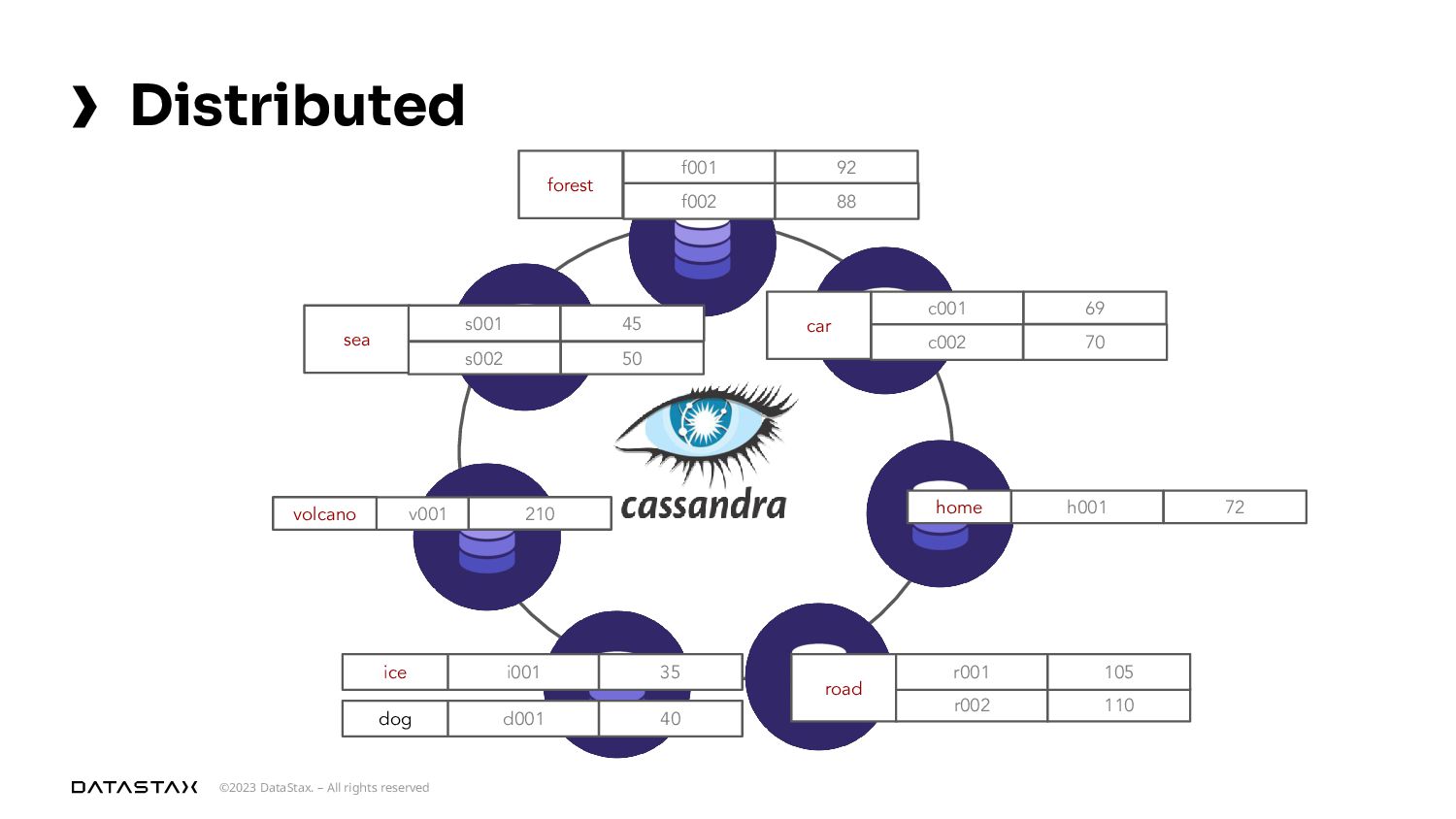{kind=link}
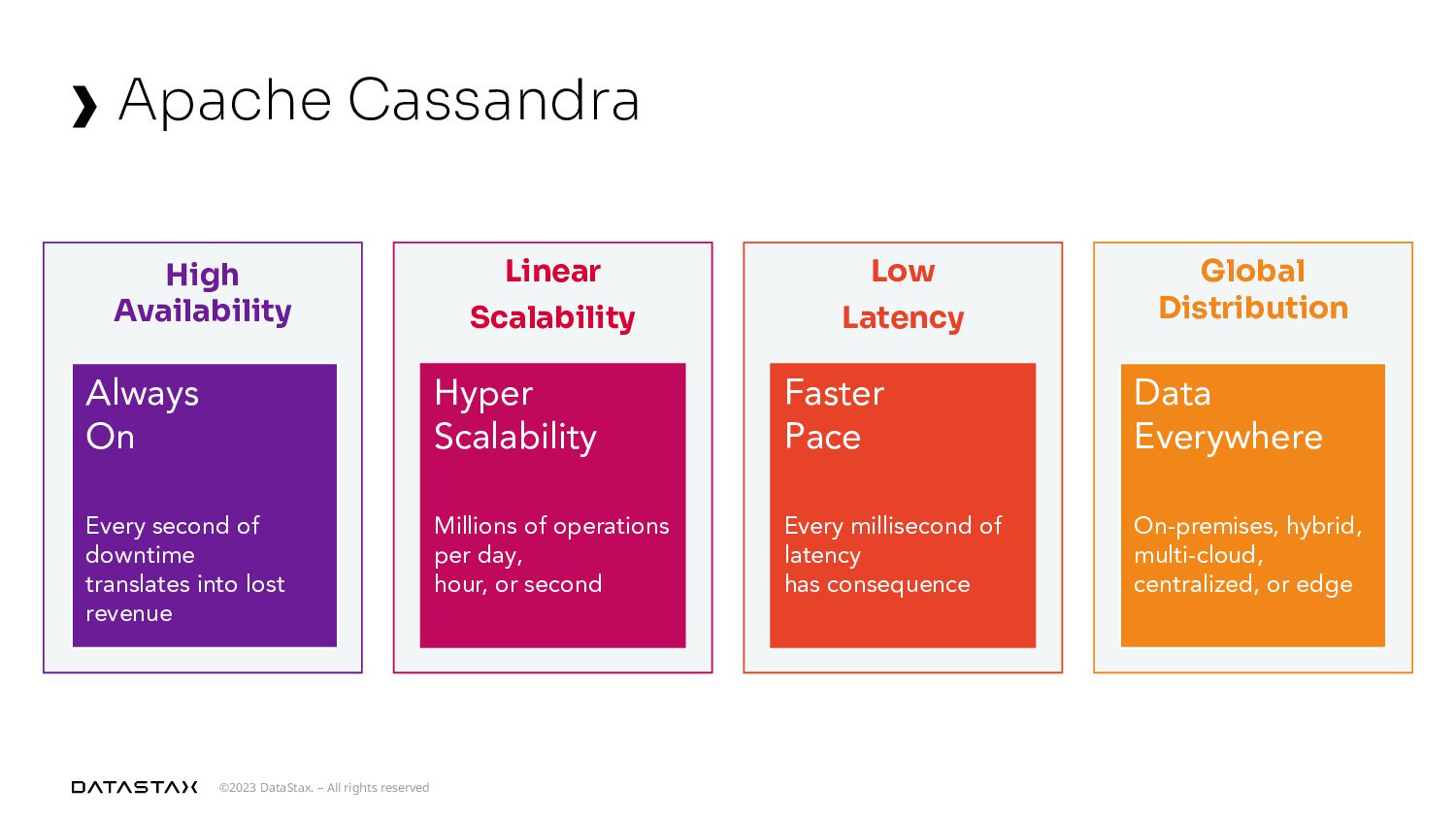{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
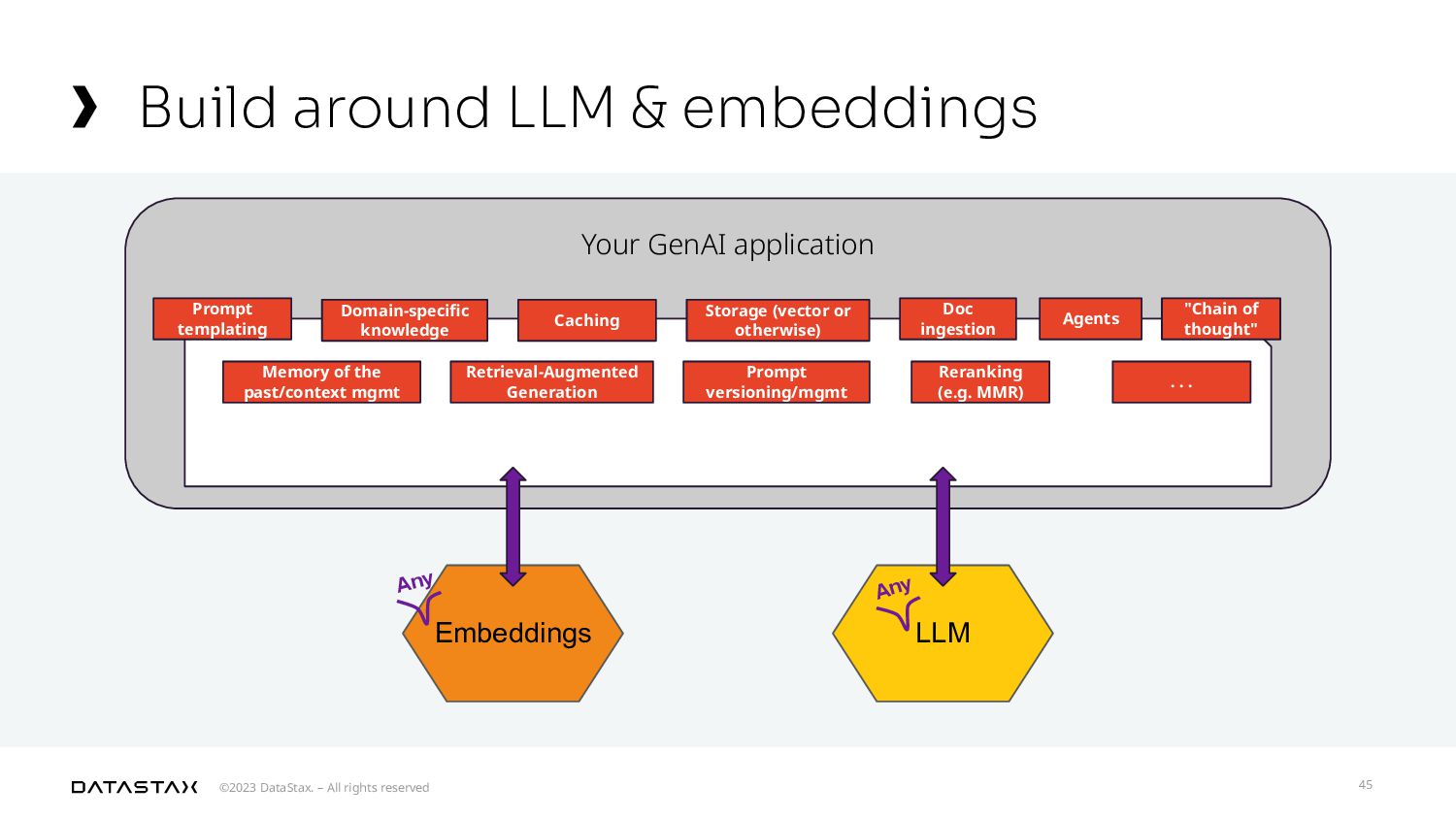{kind=link}
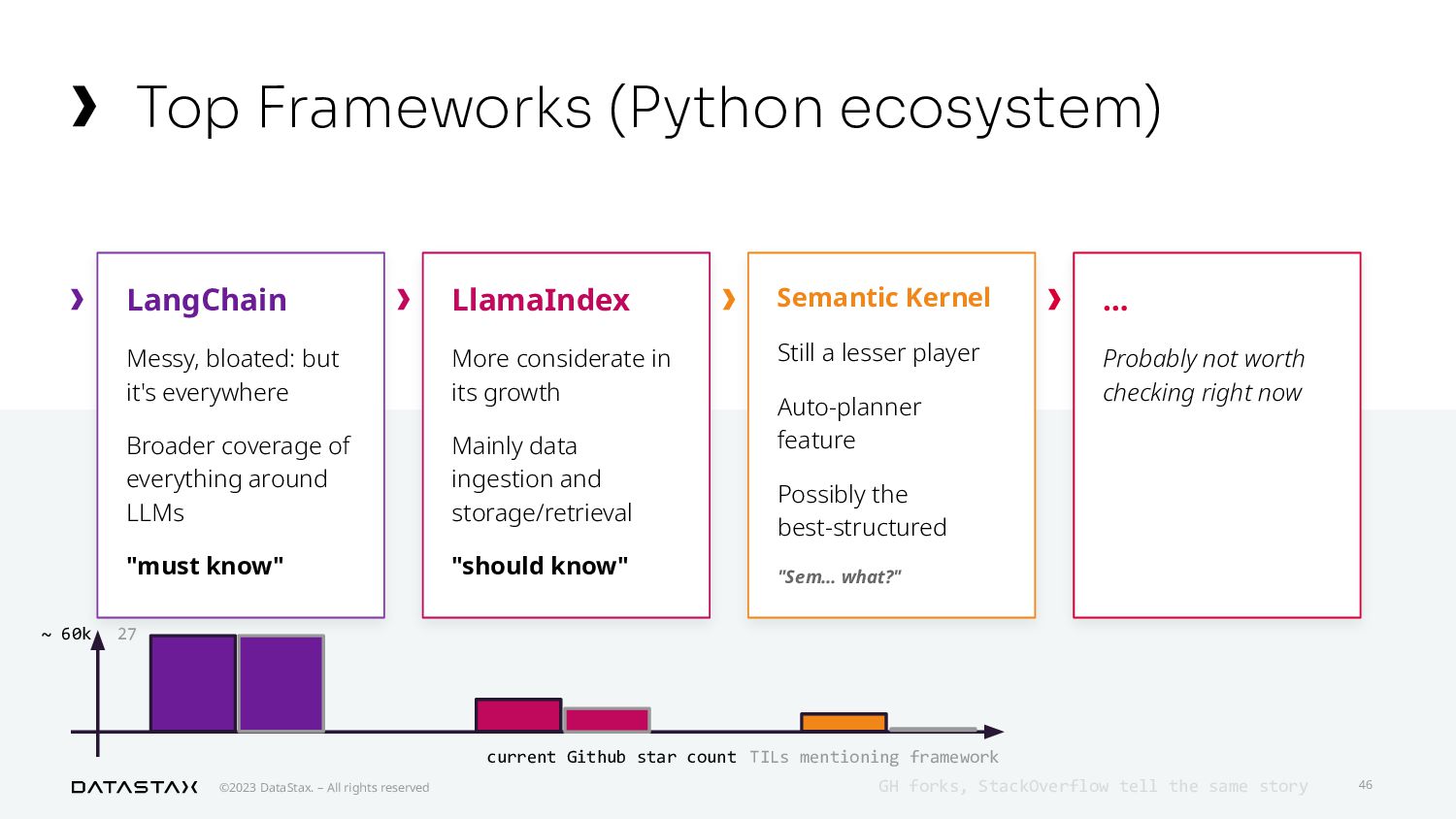{kind=link}
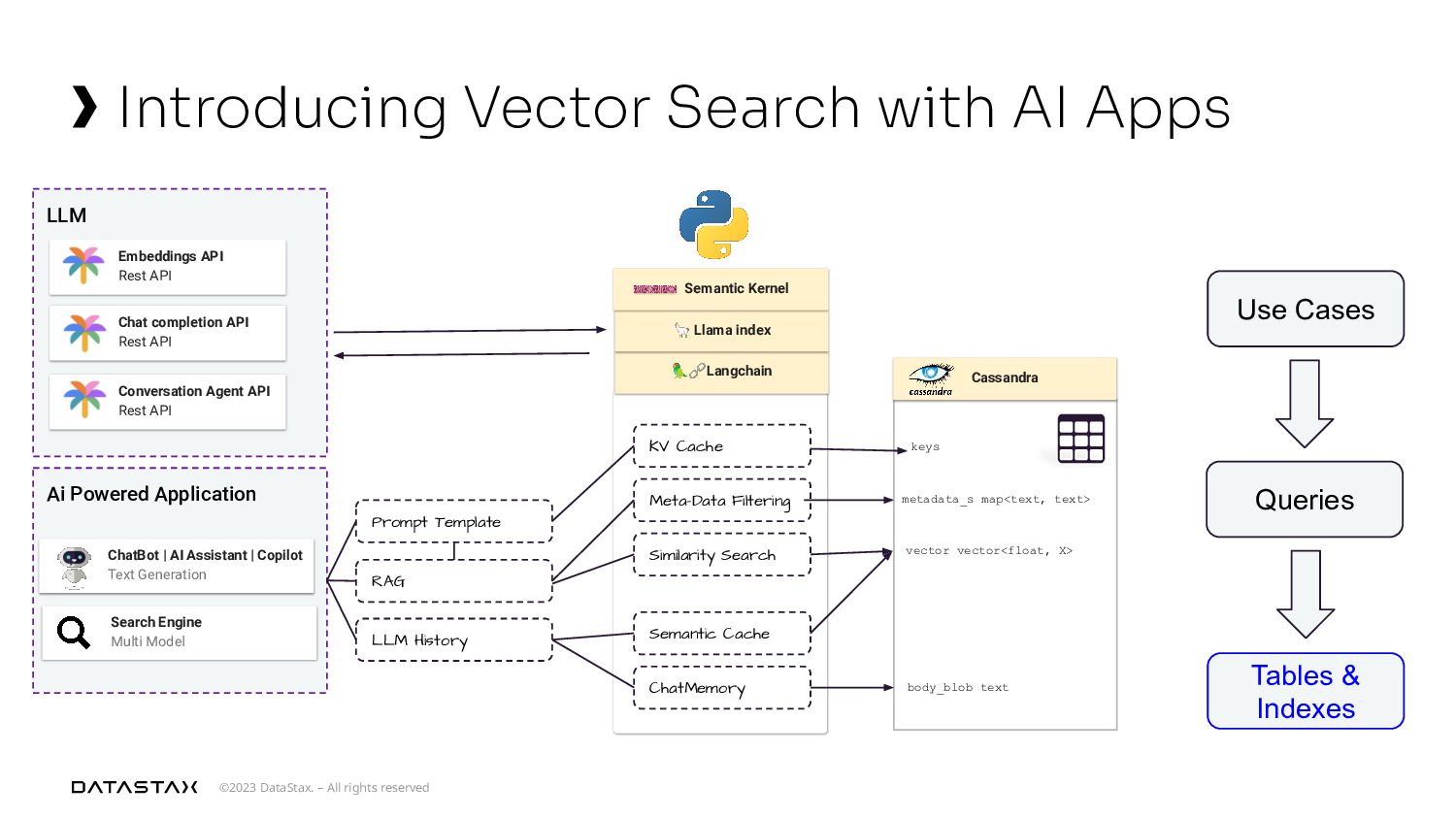{kind=link}
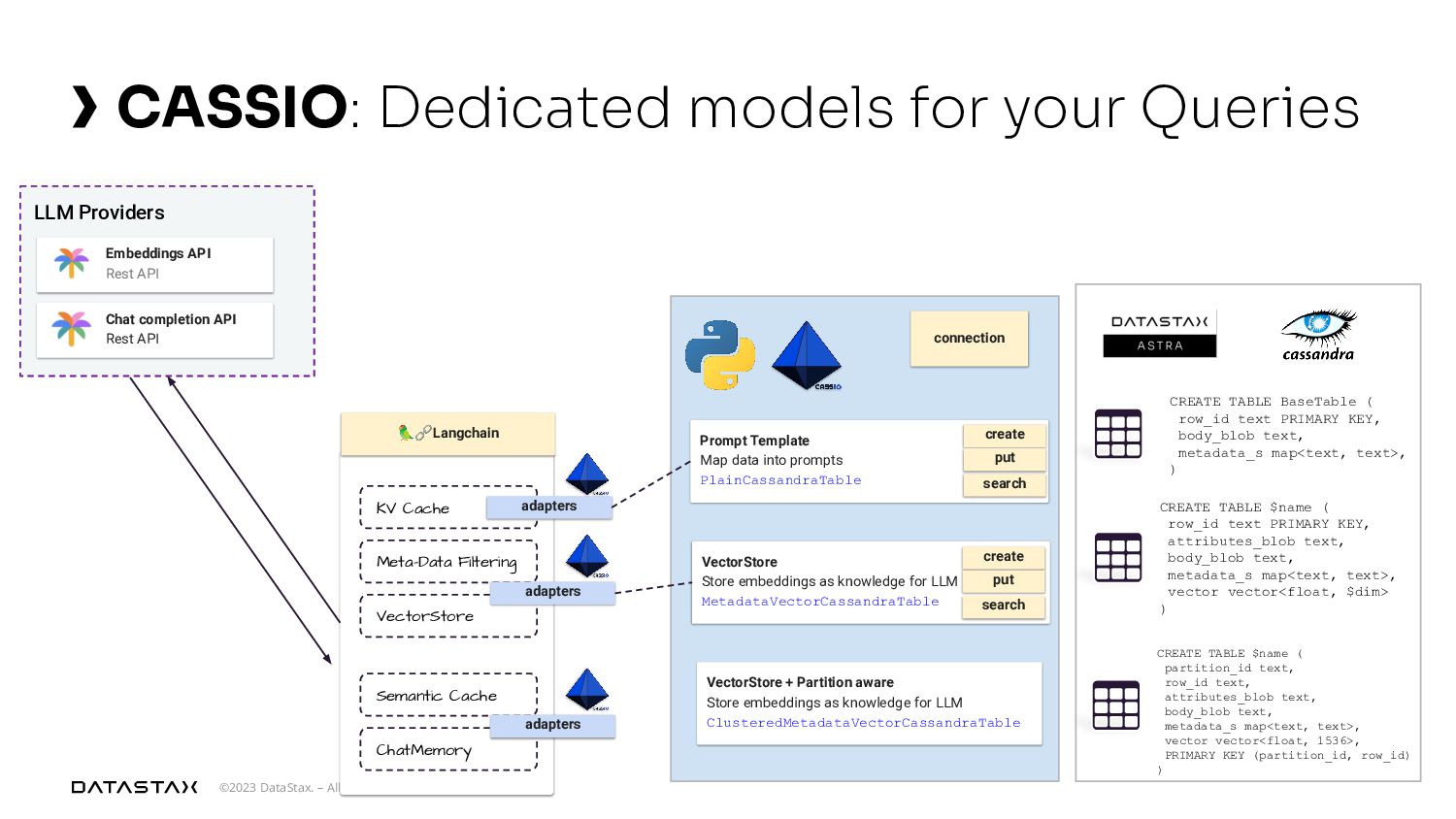{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}