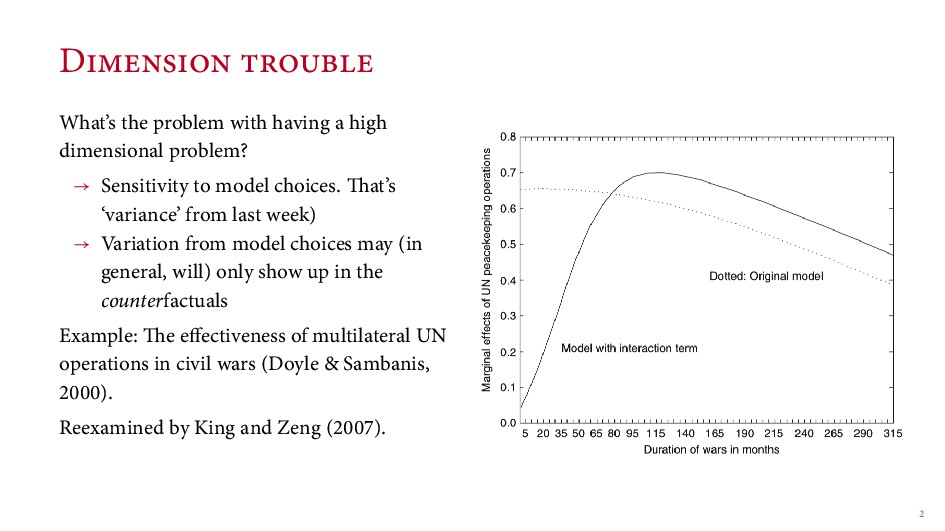
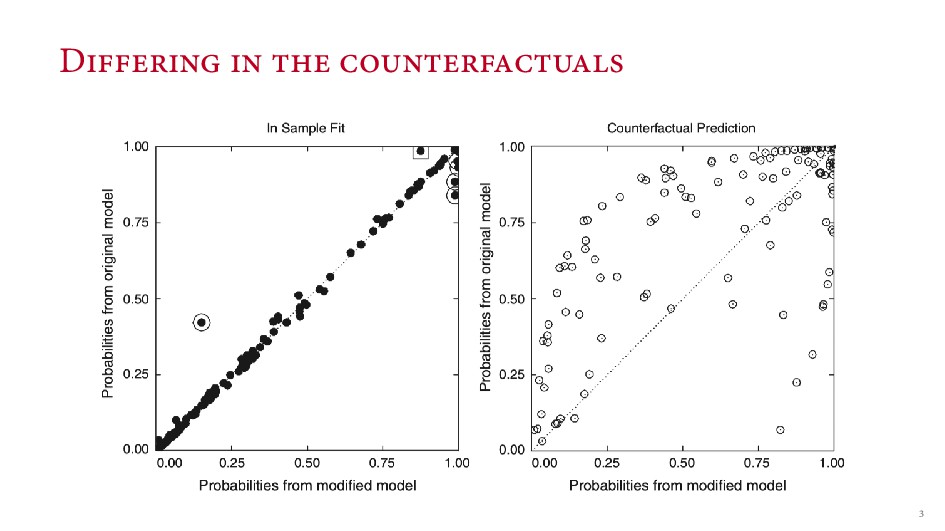
‘Generalized random forests’. Broockman, D. E. ( ). ‘Approaches to studying policy representation’. Legislative Studies Quarterly, ( ), – . Doyle, M. W. & Sambanis, N. ( ). ‘International peacebuilding: A theoretical and quantitative analysis’. American Political Science Review, ( ), – . King, G. & Zeng, L. ( ). ‘Improving forecasts of state failure’. World Politics, ( ), – . King, G. & Zeng, L. ( ). ‘When can history be our guide? the pitfalls of counterfactual inference’. International Studies Quarterly, ( ), – .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}