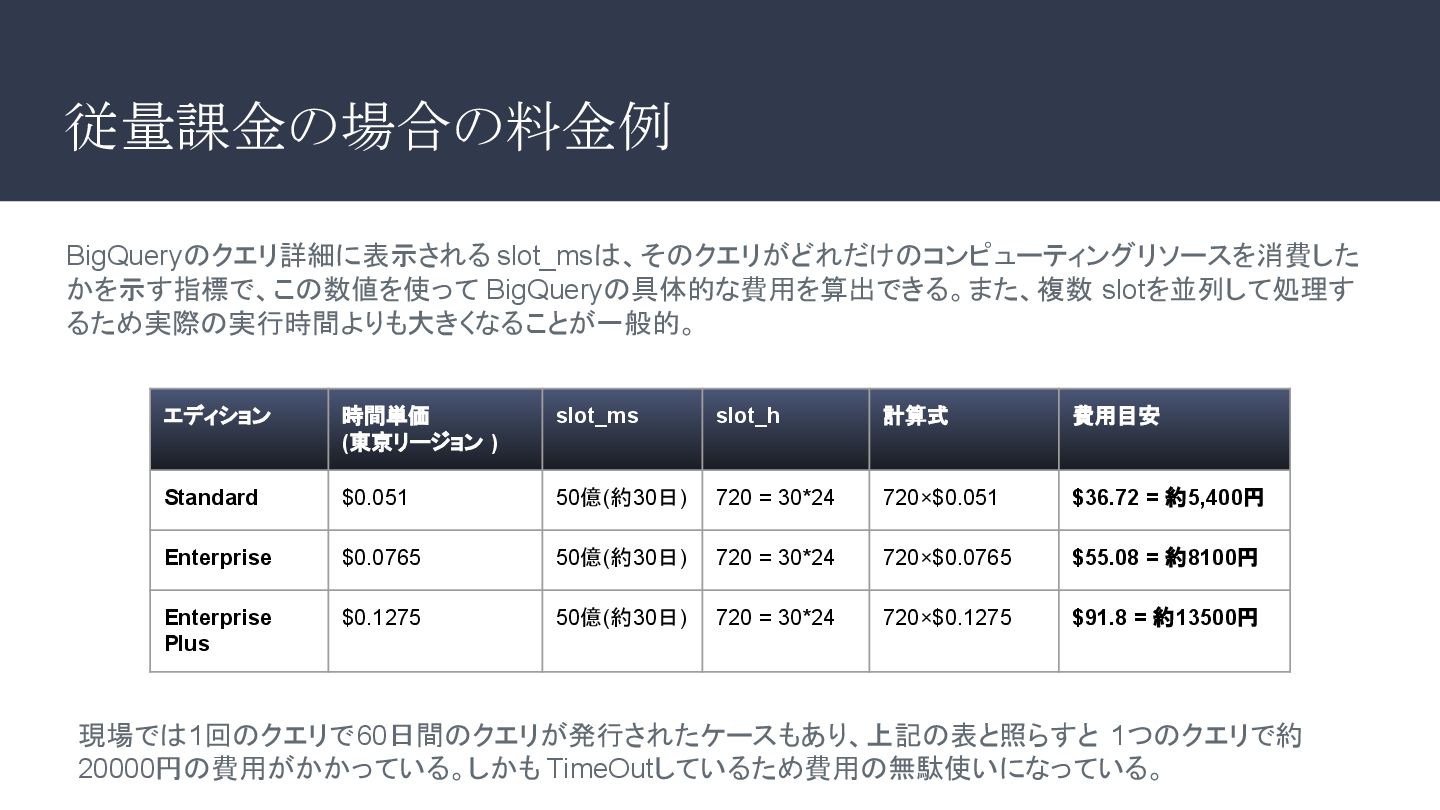
$0.051 50億(約30日) 720 = 30*24 720×$0.051 $36.72 = 約5,400円 Enterprise $0.0765 50億(約30日) 720 = 30*24 720×$0.0765 $55.08 = 約8100円 Enterprise Plus $0.1275 50億(約30日) 720 = 30*24 720×$0.1275 $91.8 = 約13500円 BigQueryのクエリ詳細に表示される slot_msは、そのクエリがどれだけのコンピューティングリソースを消費した かを示す指標で、この数値を使って BigQueryの具体的な費用を算出できる。また、複数 slotを並列して処理す るため実際の実行時間よりも大きくなることが一般的。 現場では1回のクエリで60日間のクエリが発行されたケースもあり、上記の表と照らすと 1つのクエリで約 20000円の費用がかかっている。しかも TimeOutしているため費用の無駄使いになっている。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}