Patroni is one of the most popular and advanced solutions for PostgreSQL high-availability. It is integrated with a variety of distributed configuration stores allowing Patroni to work with PostgreSQL cluster information in a consistent way ensuring that there is only one leader at a time. Unlike the majority of existing solutions for automatic failover, Patroni requires a minimal effort to configure the HA cluster and supports auto-discovery of new nodes.
This talk will consist of a short introduction to the ideas behind Patroni, overview of the major features that we have released lately, cover some interesting failure scenarios which were fixed, and share some plans for the future development. Of course, the talk will not be complete without showing a live demo of some brand-new features.
{kind=link}
{kind=link}
{kind=link}
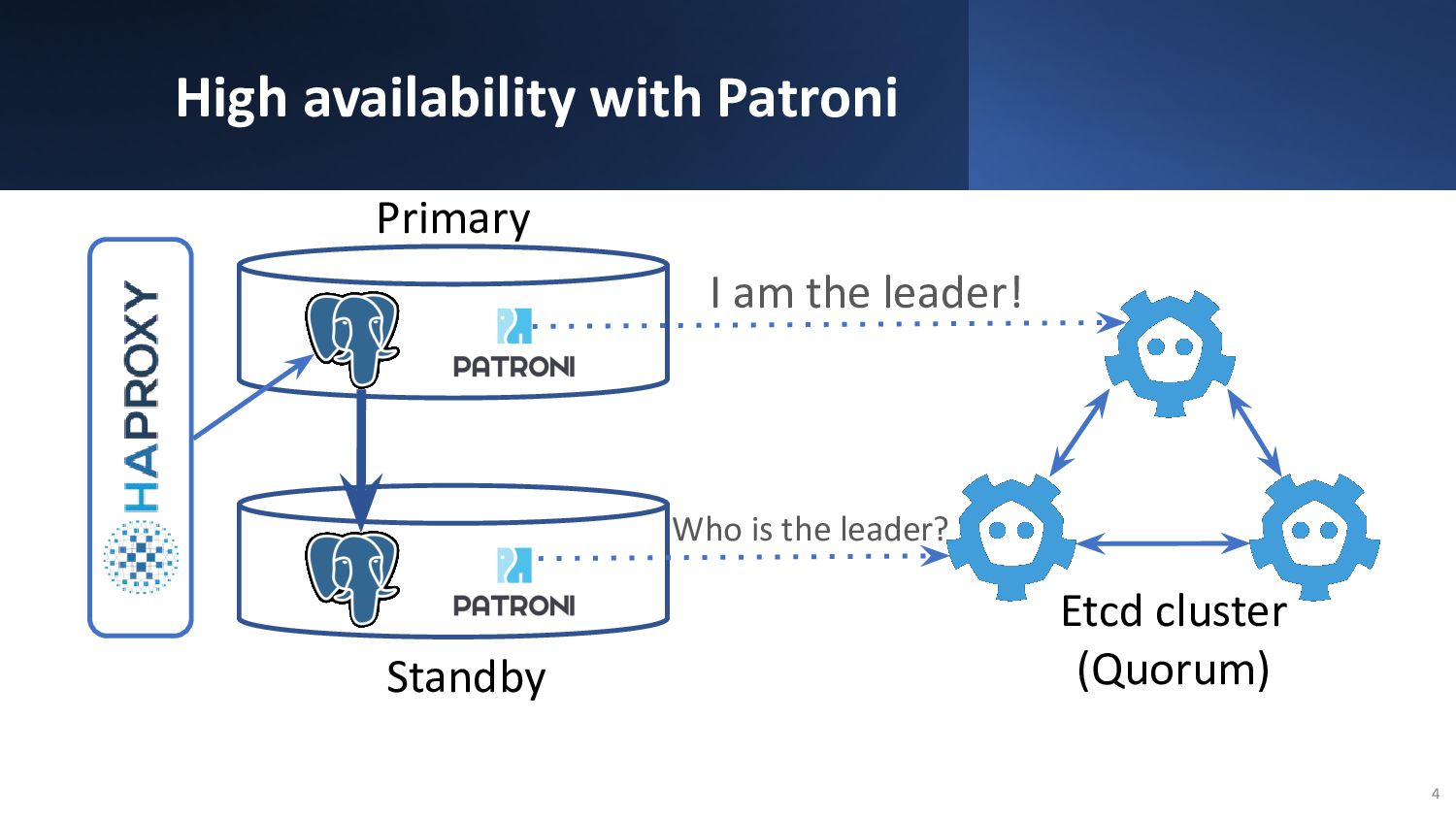{kind=link}
{kind=link}
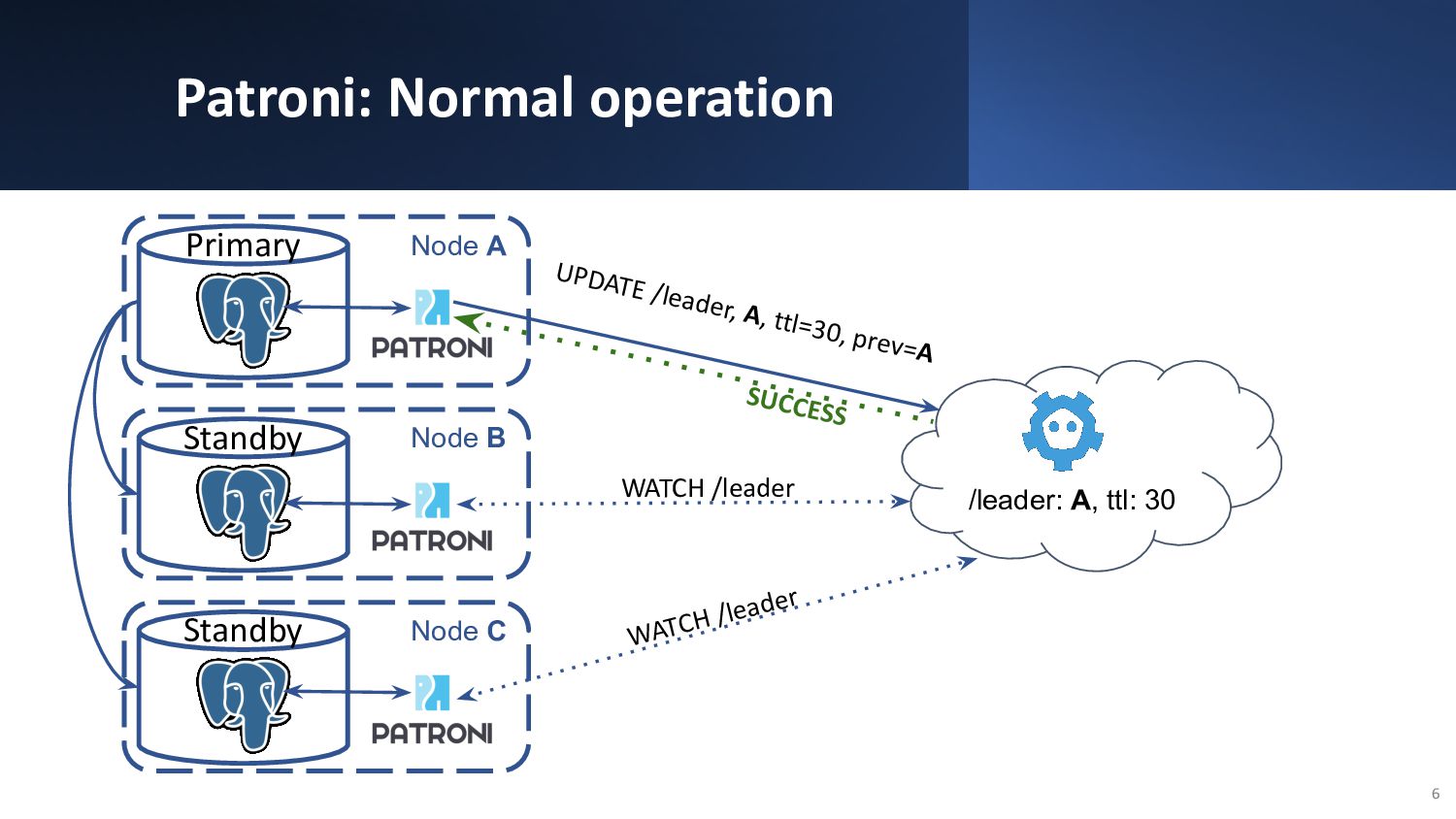{kind=link}
{kind=link}
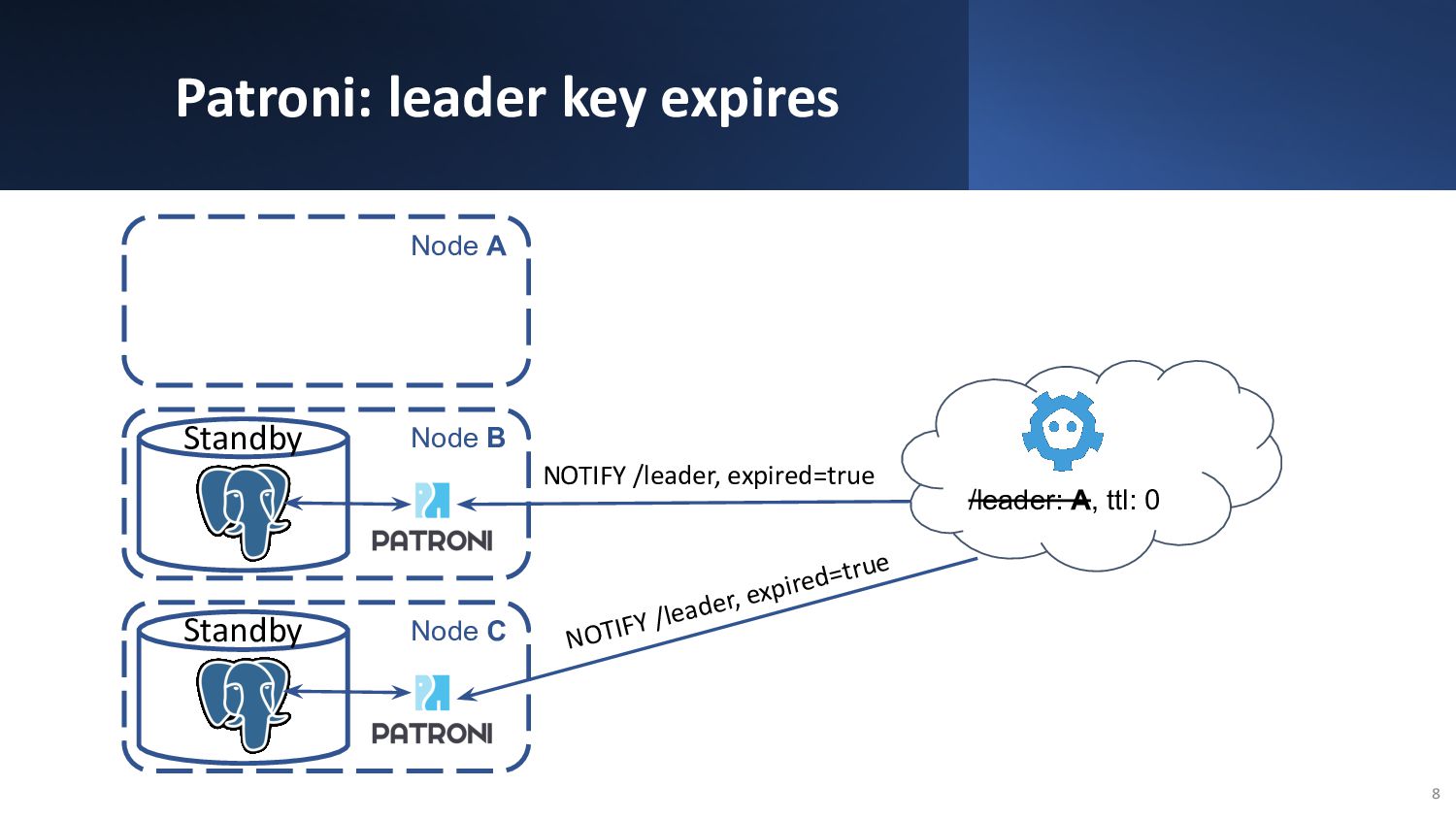{kind=link}
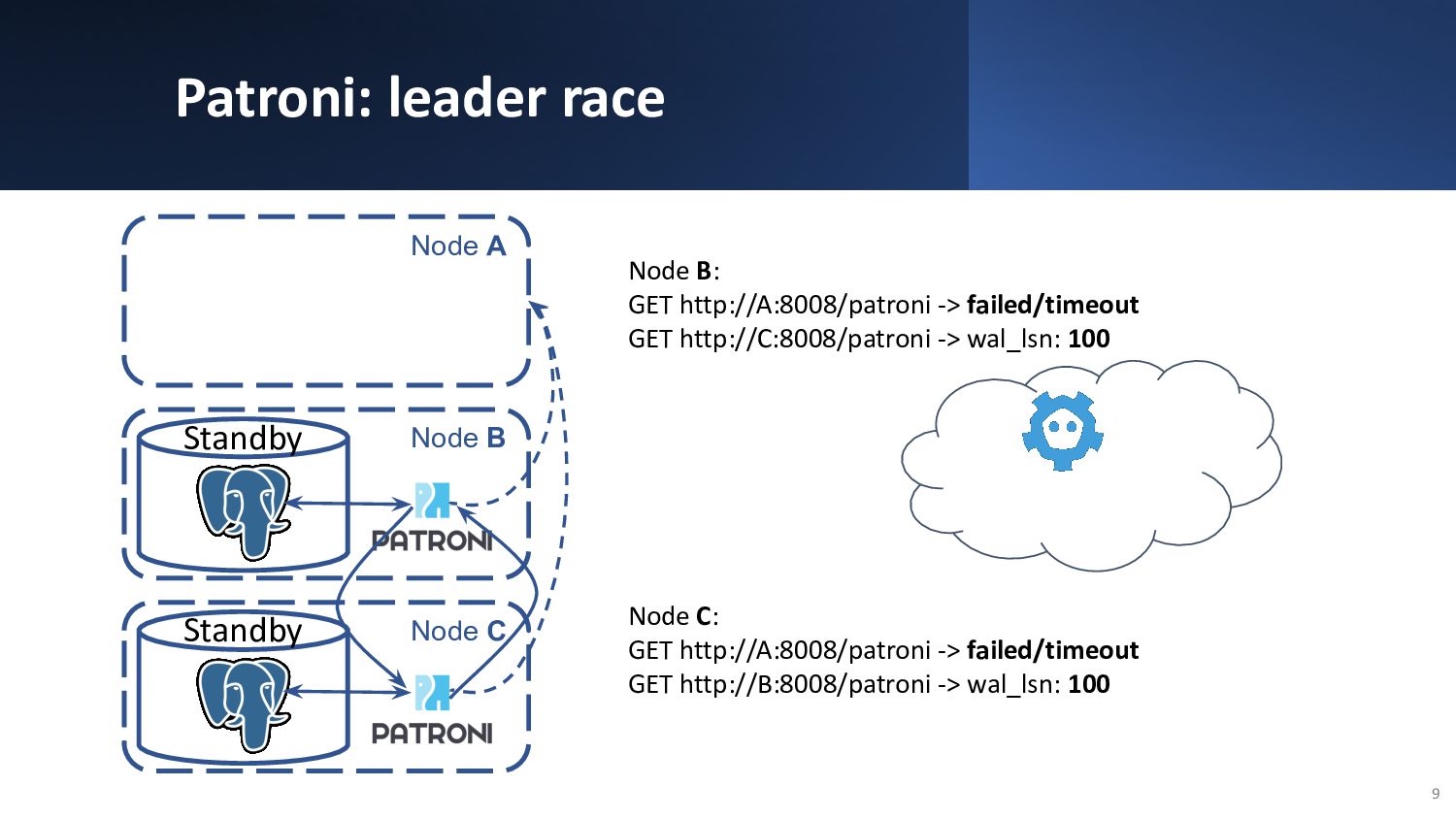{kind=link}
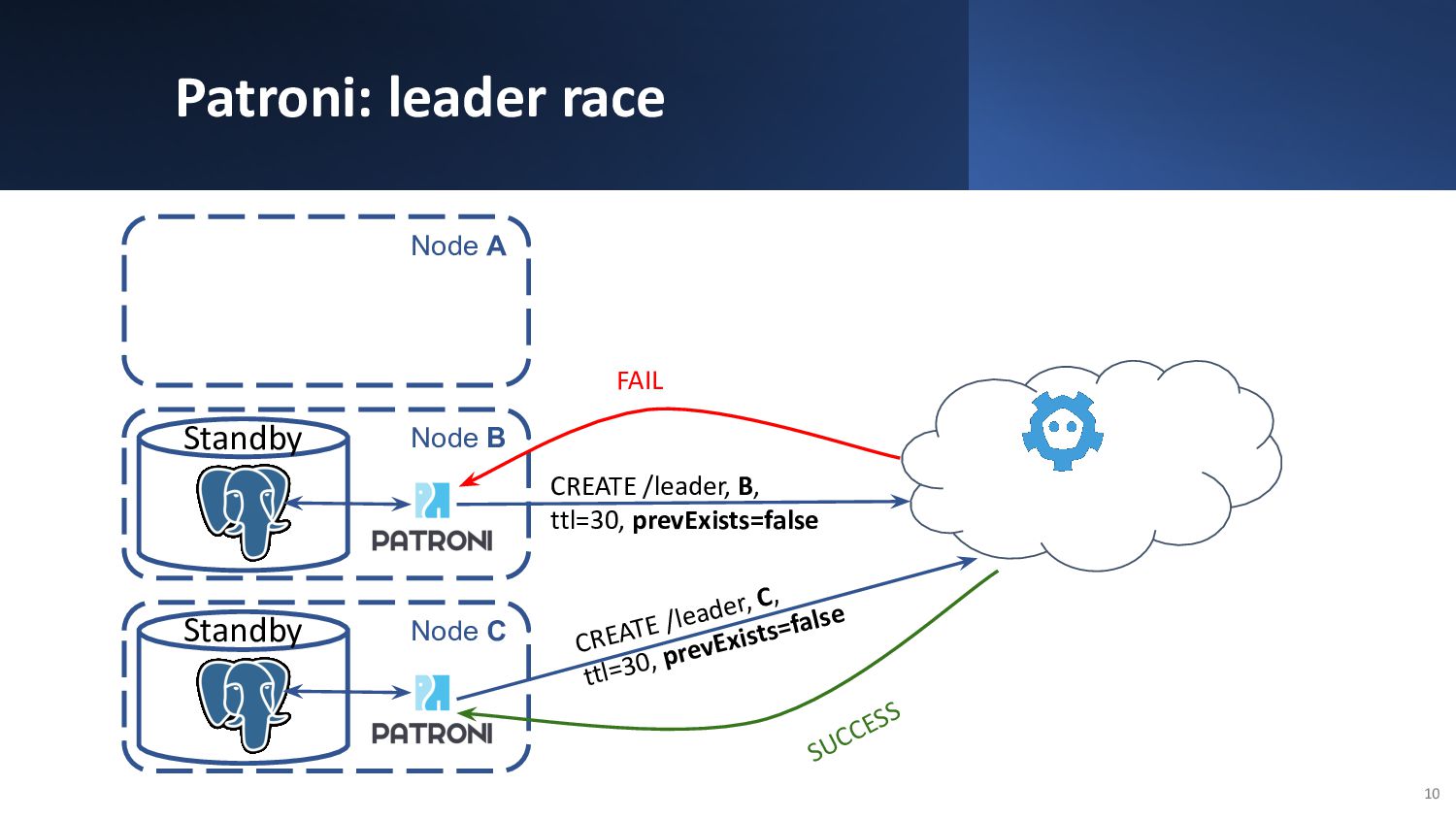{kind=link}
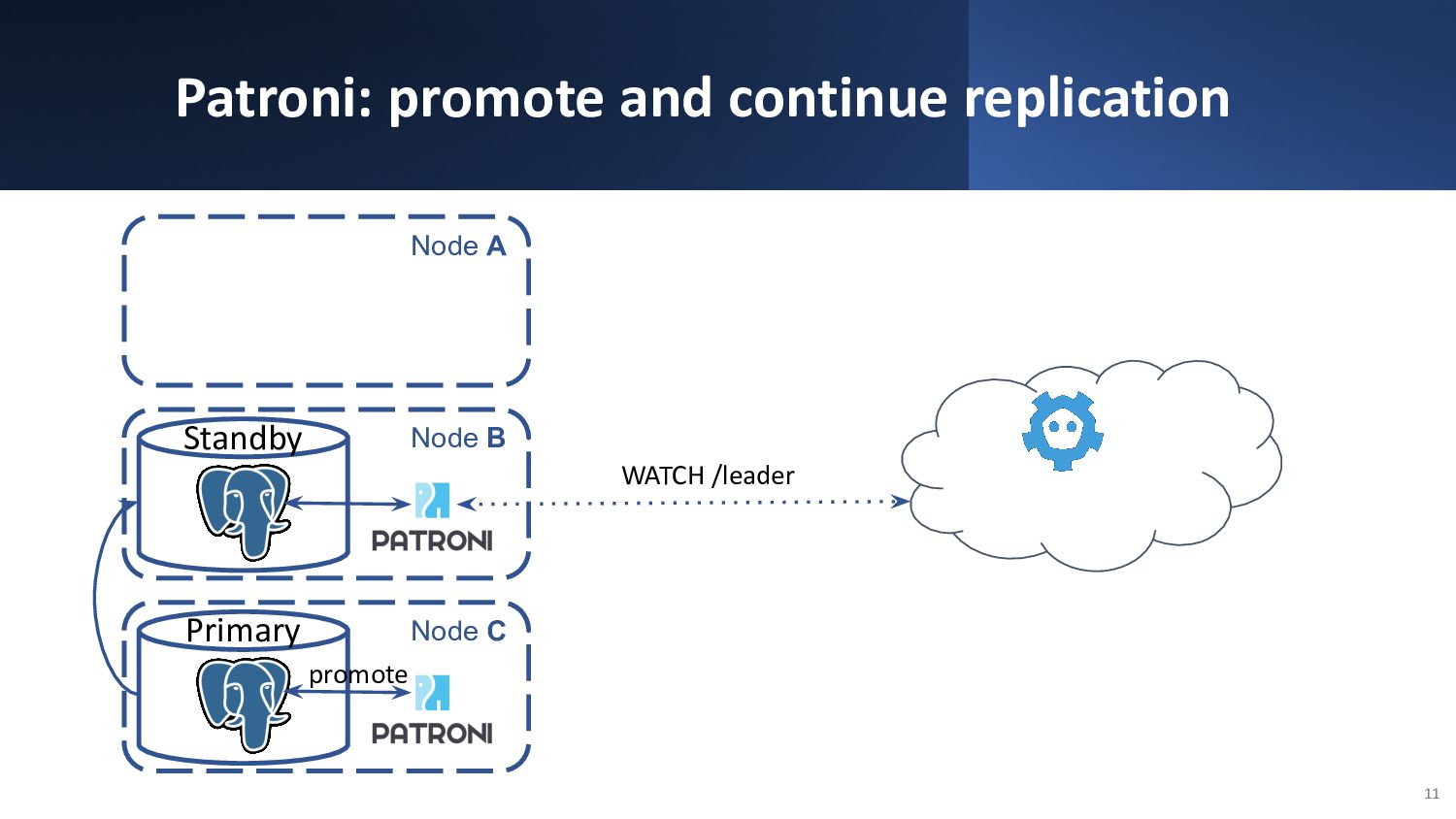{kind=link}
{kind=link}
{kind=link}
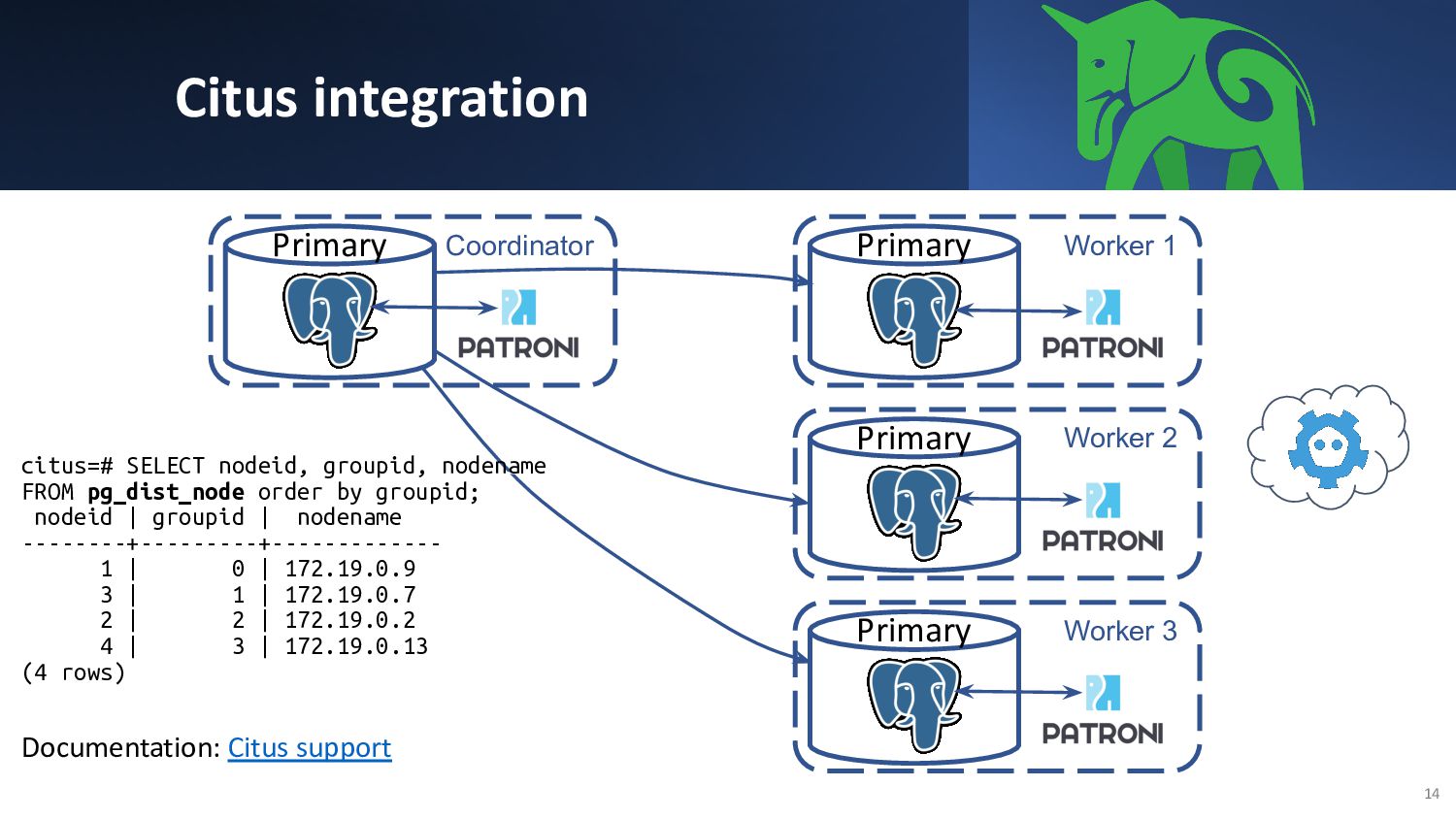{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}