What?! Patroni is the tool for implementing PostgreSQL high-availability and automatic failover, isn't it already failsafe on its own?
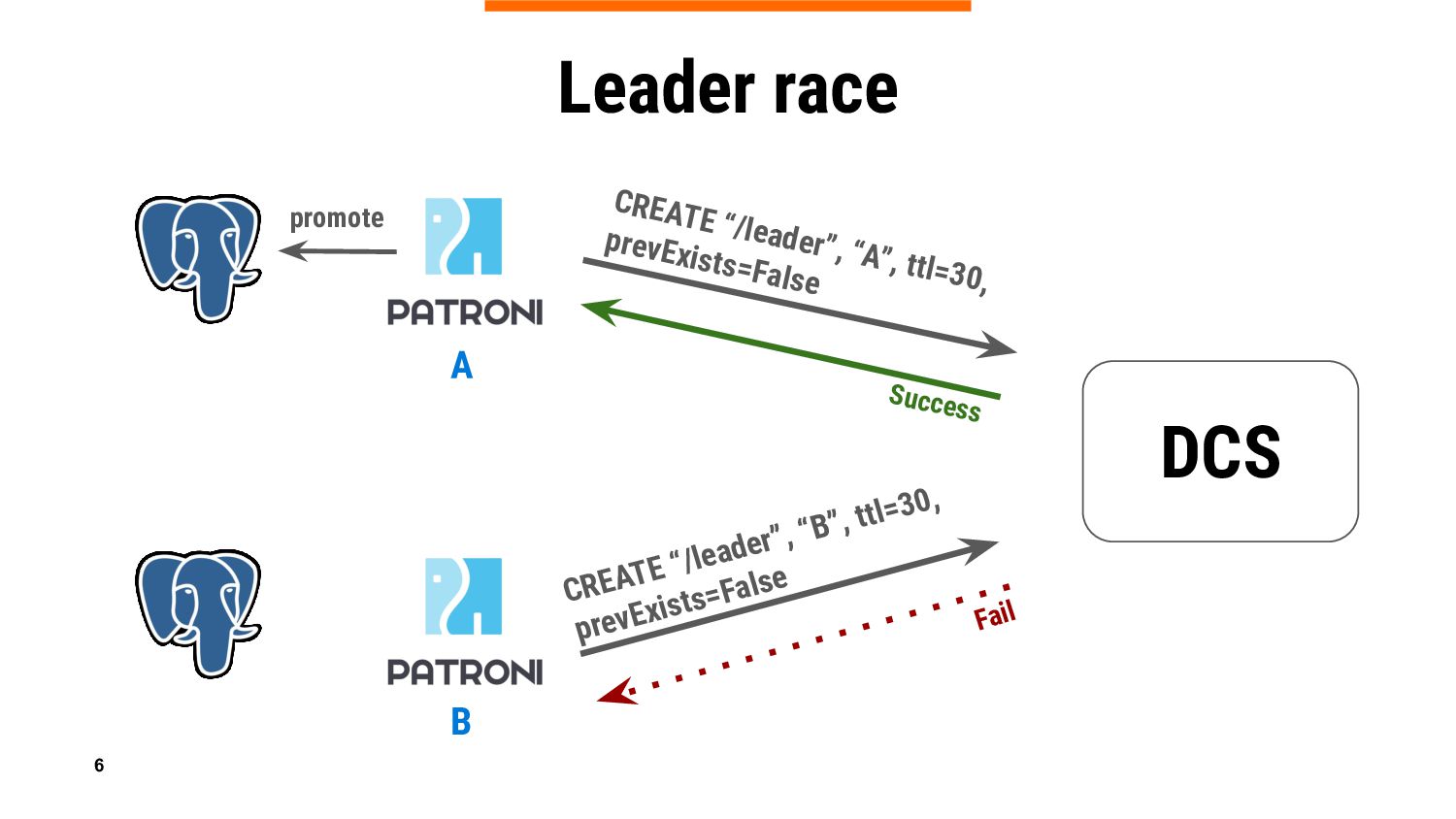
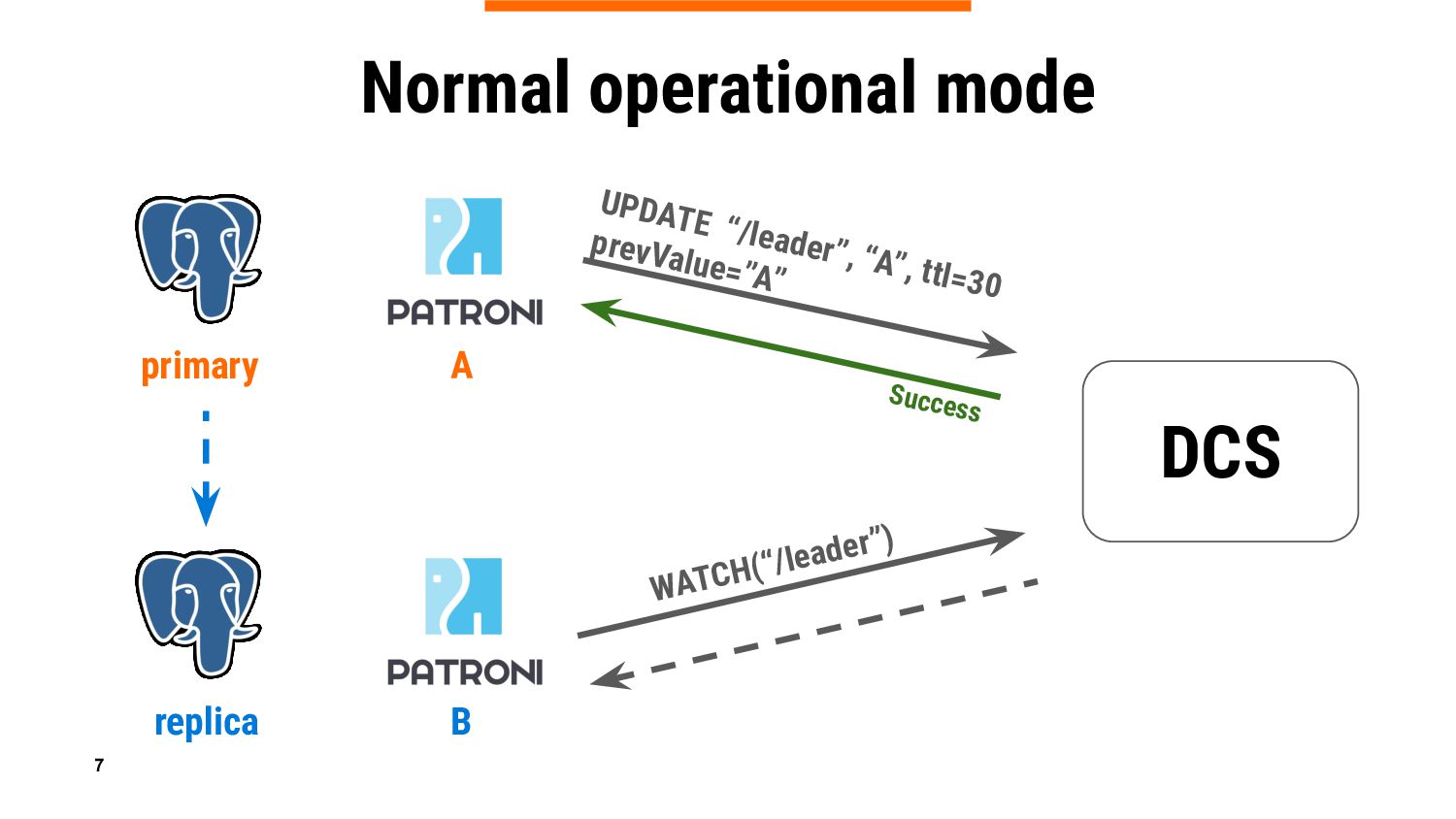
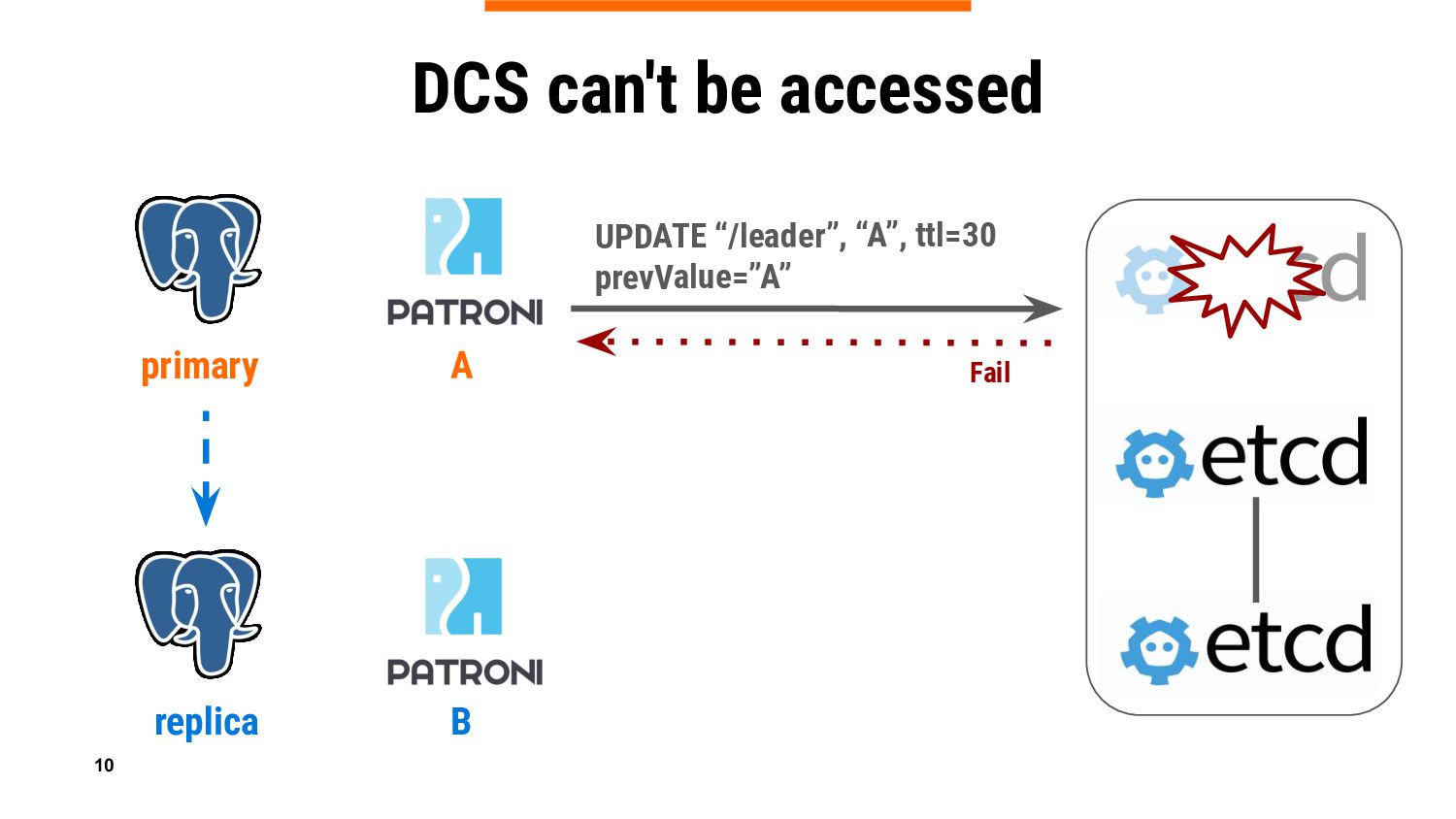
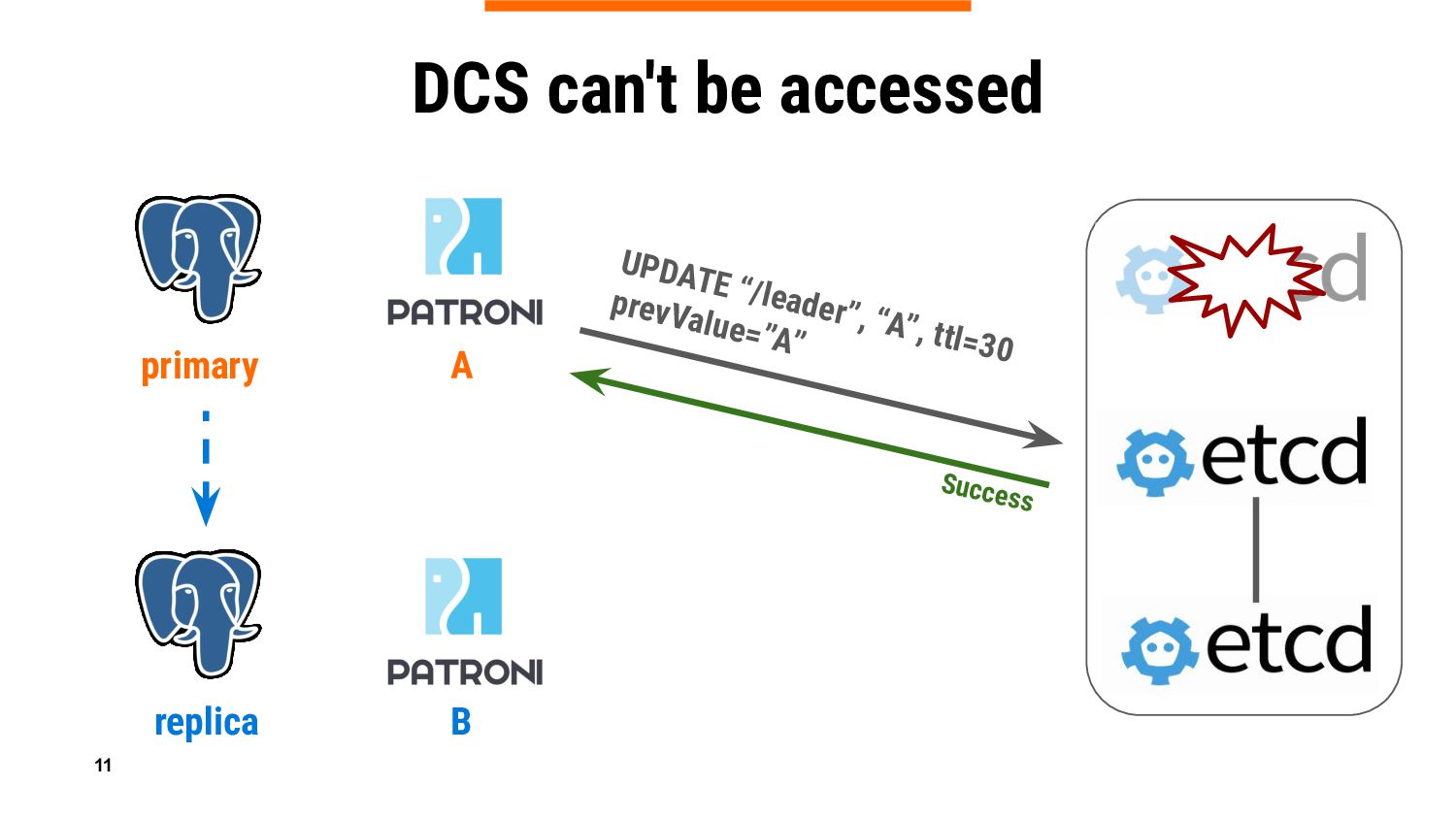
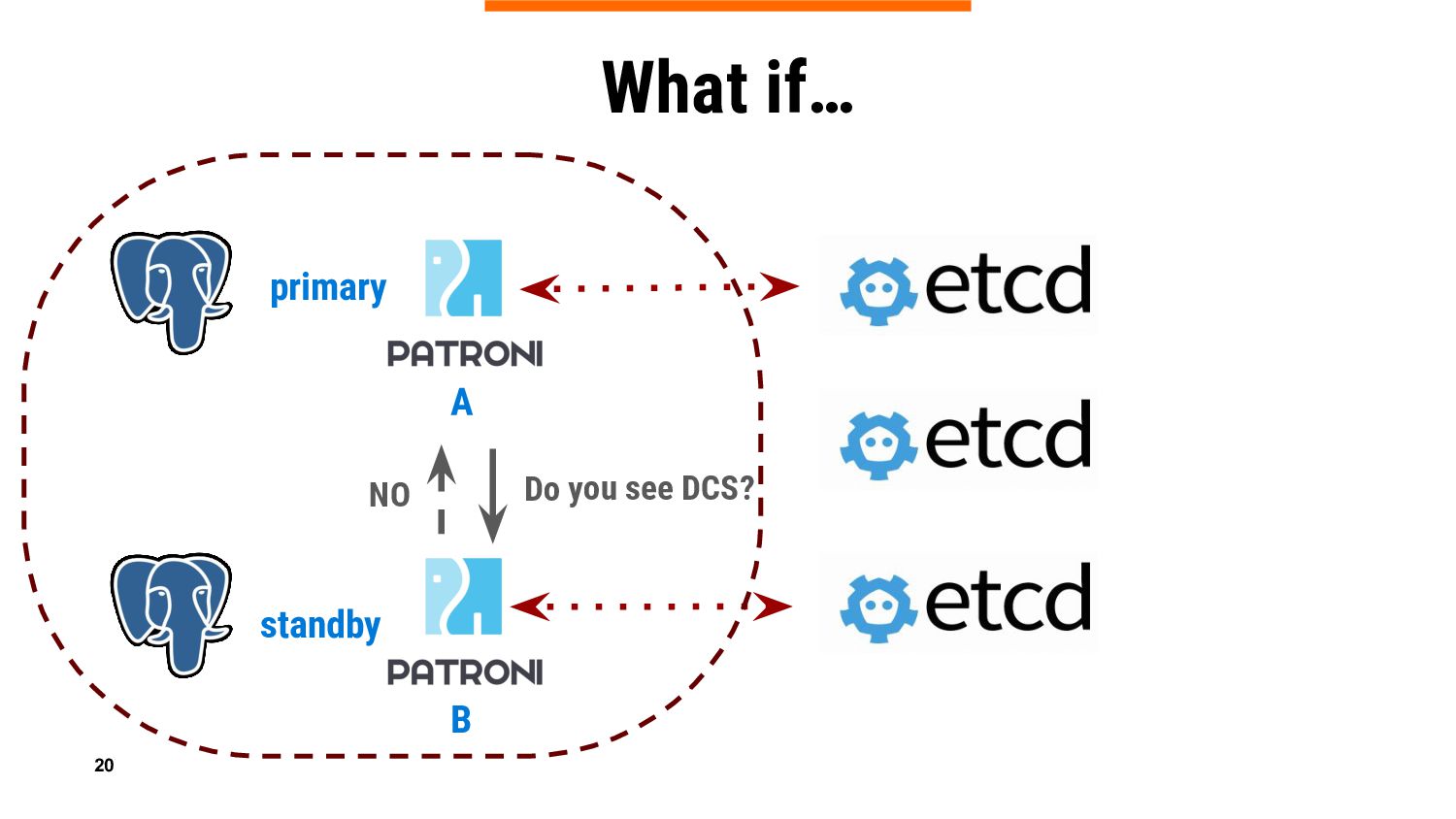
If you are an experienced Patroni user, you know that it relies on DCS (Distributed Configuration Store) to keep PostgreSQL cluster information in a consistent way ensuring that there is only one leader at a time. And of course, you also know that primary is demoted if Patroni can’t update the leader lock when DCS (Etcd, Consul, Zookeeper, or Kubernetes API) is not accessible or experiencing temporary problems, which could be very frustrating.
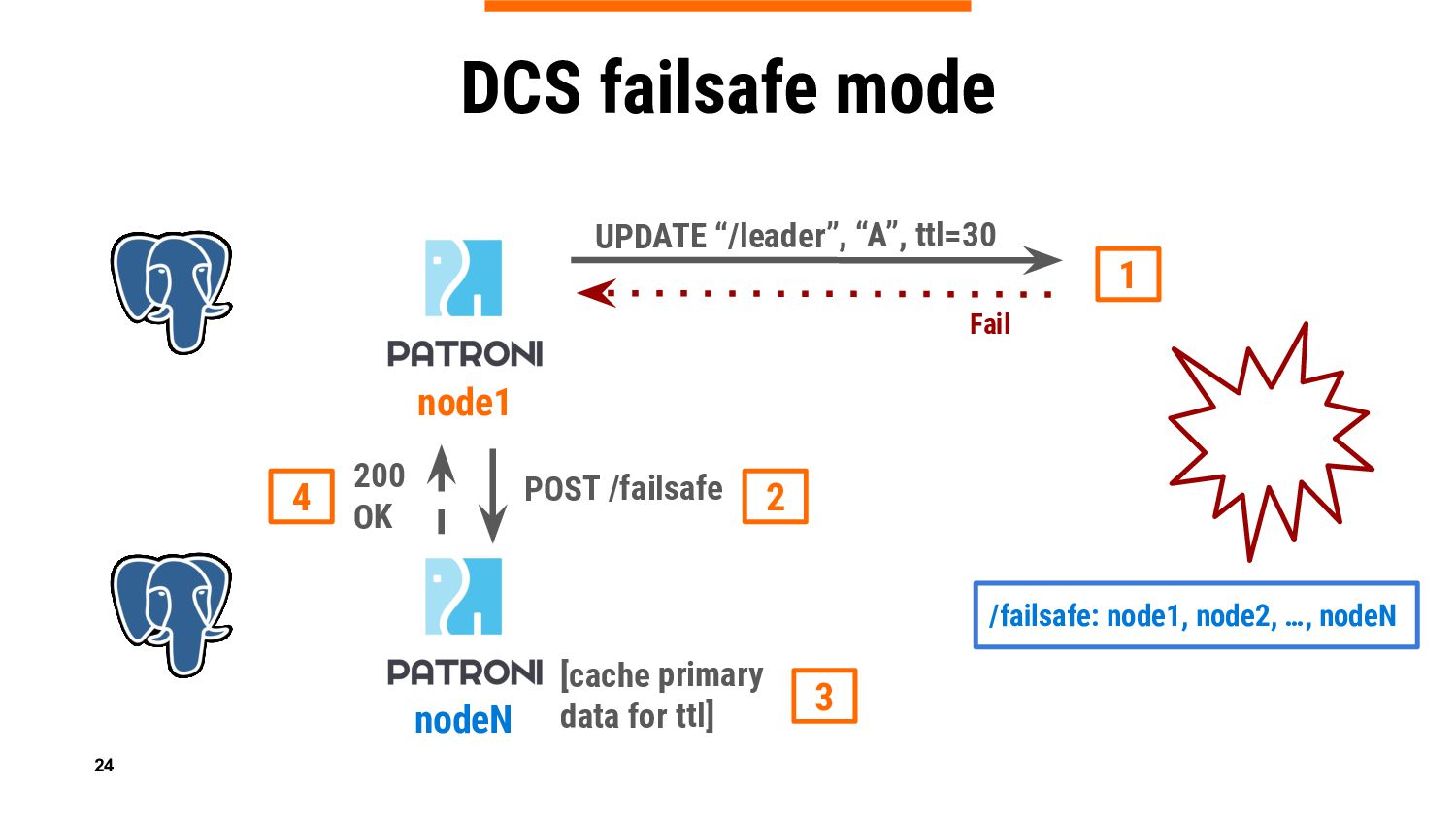
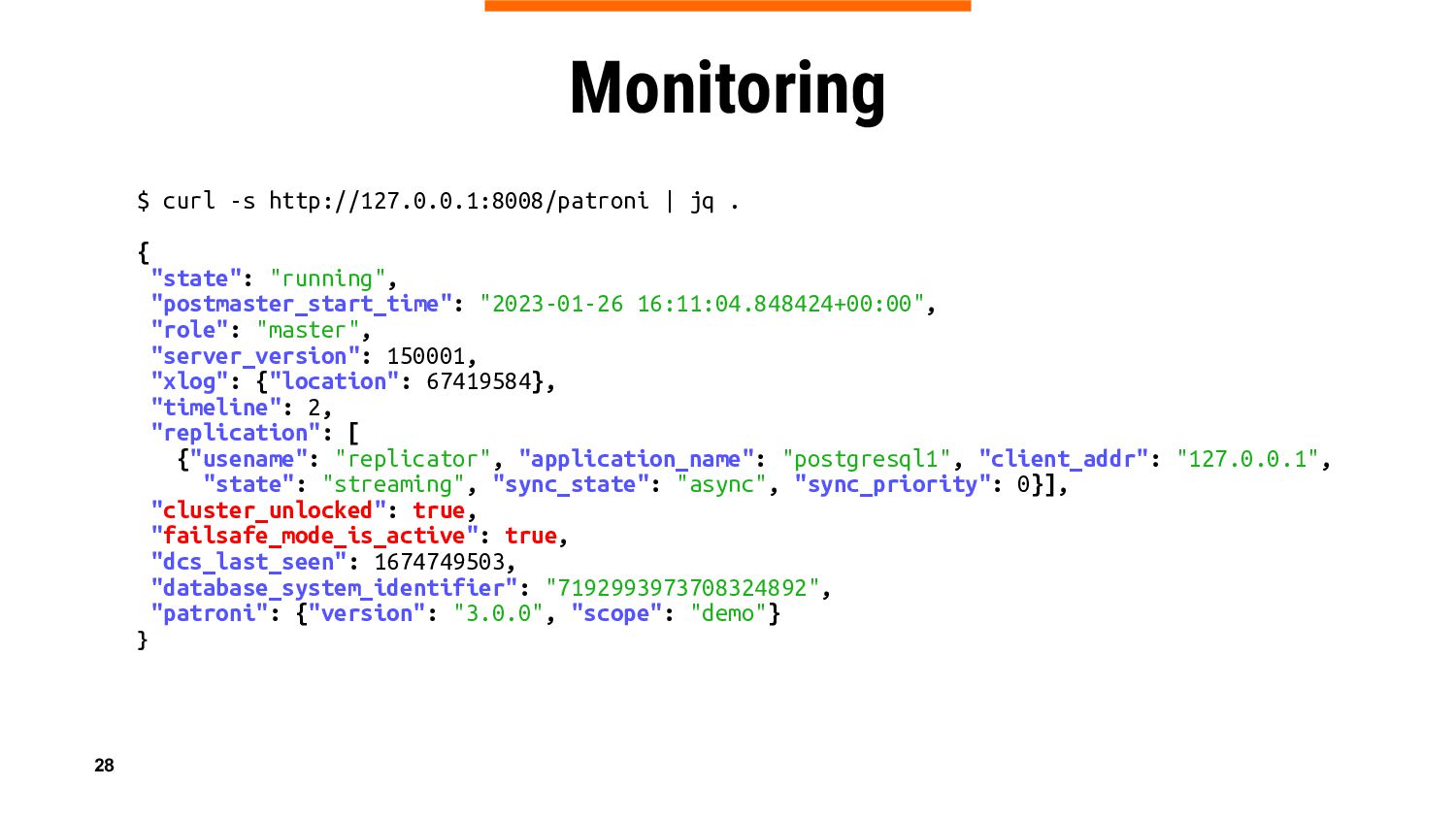
In this talk we will introduce a new Patroni feature – DCS failsafe mode, which is aimed at keeping primary running in case of a DCS failure. We will reveal some ideas behind, share important implementation details, do a live demo, and give guidance on considerations whether the feature should be used in specific environments, or it is better to refrain from it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
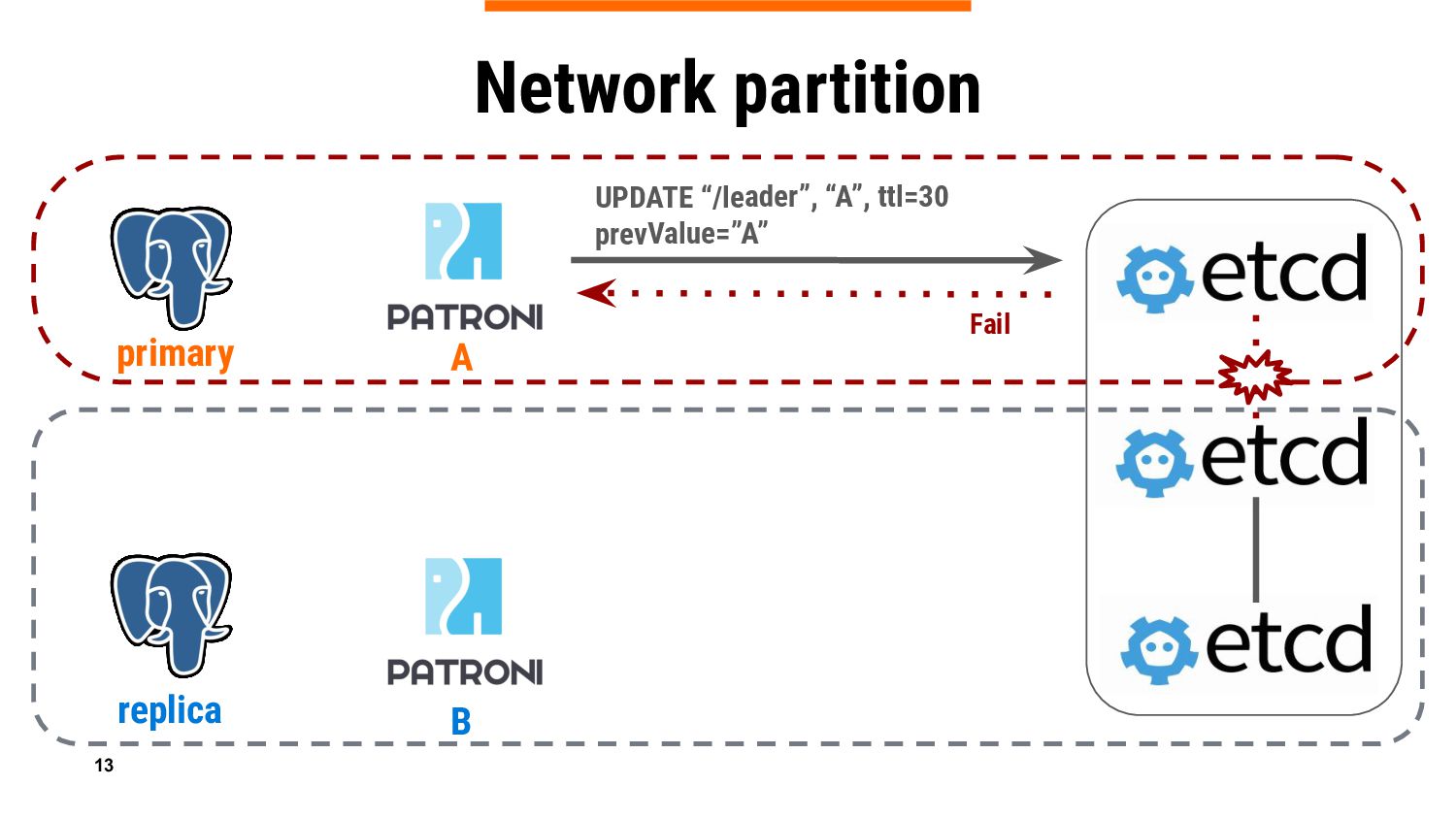{kind=link}
{kind=link}
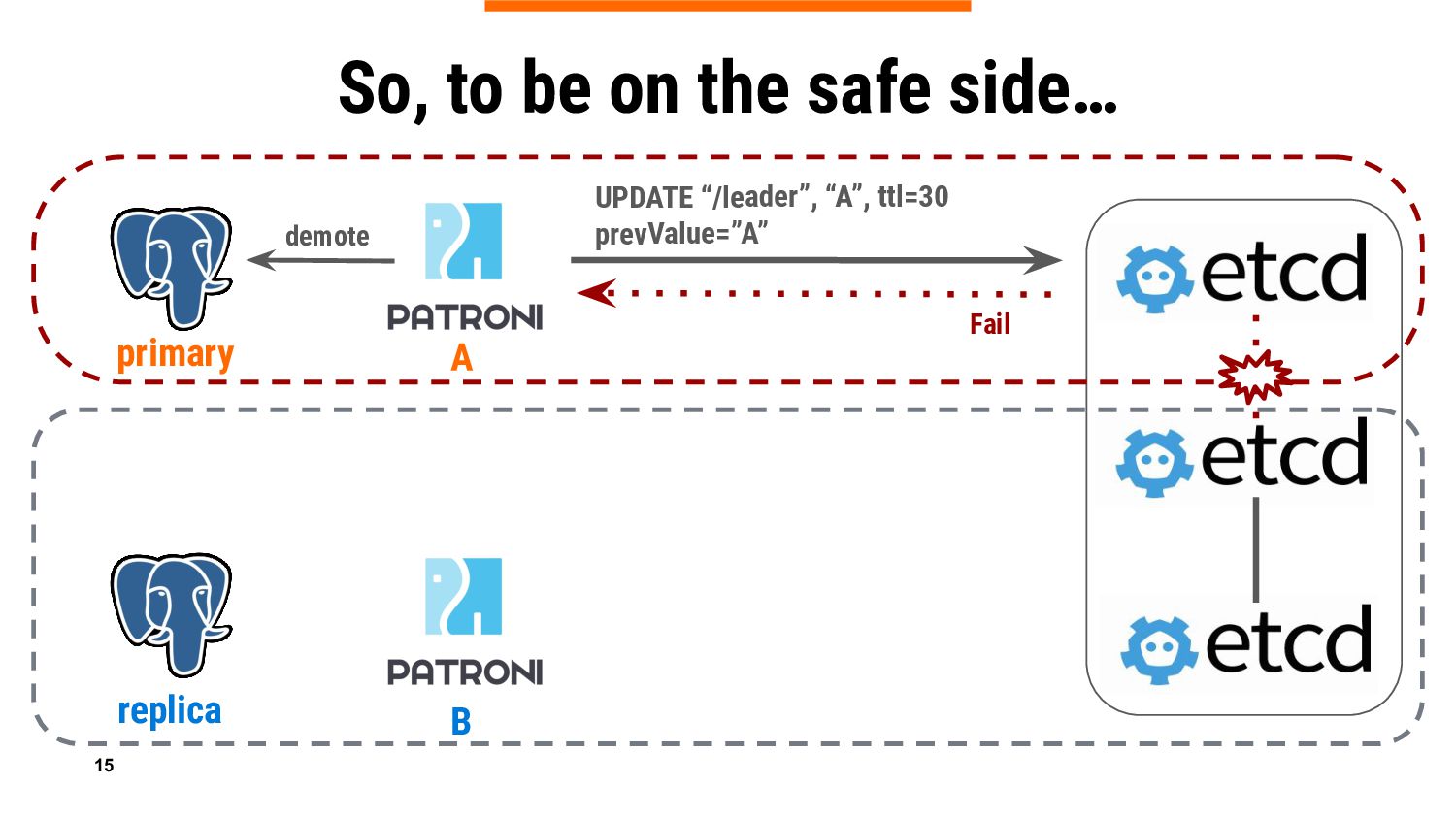{kind=link}
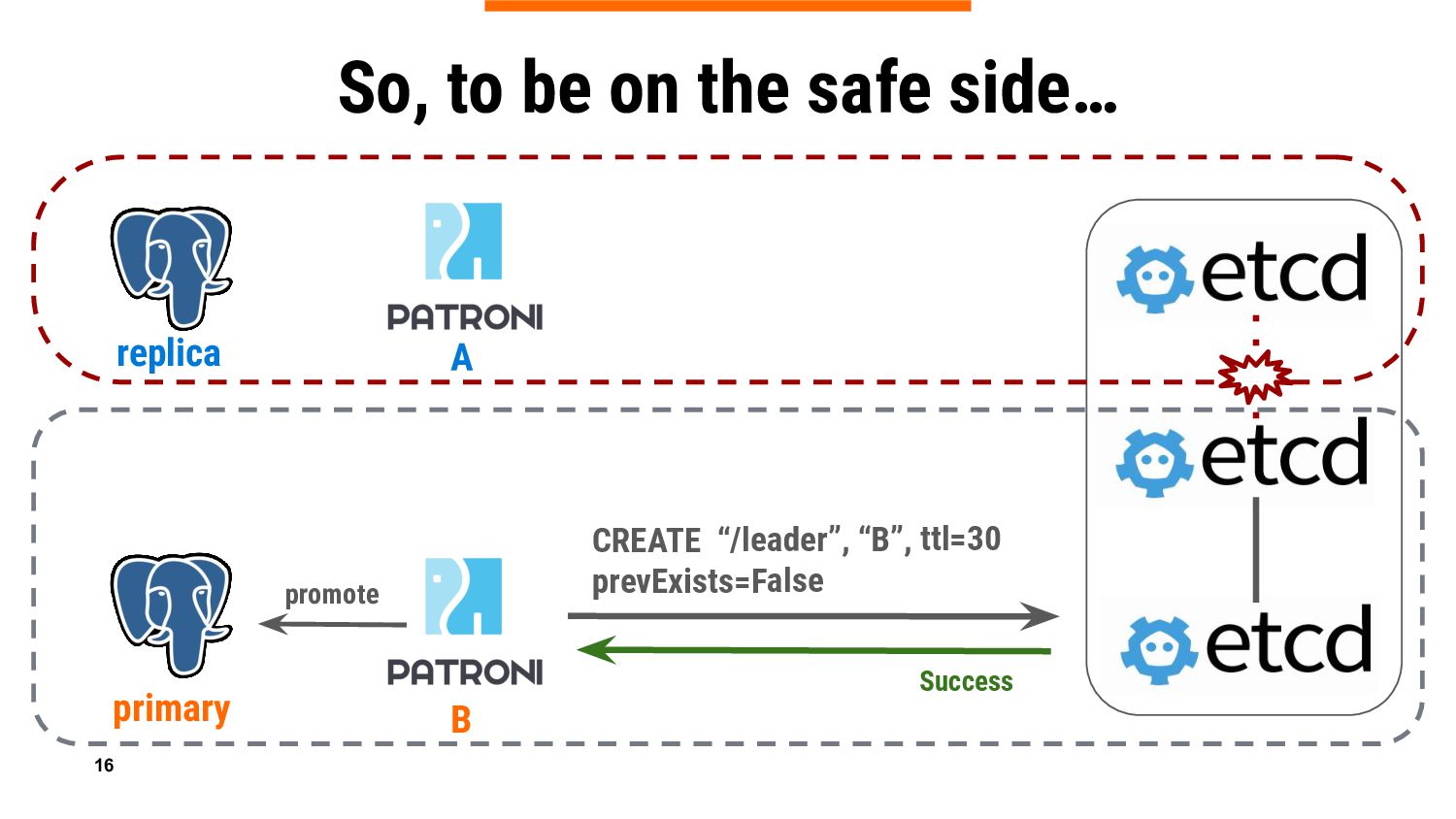{kind=link}
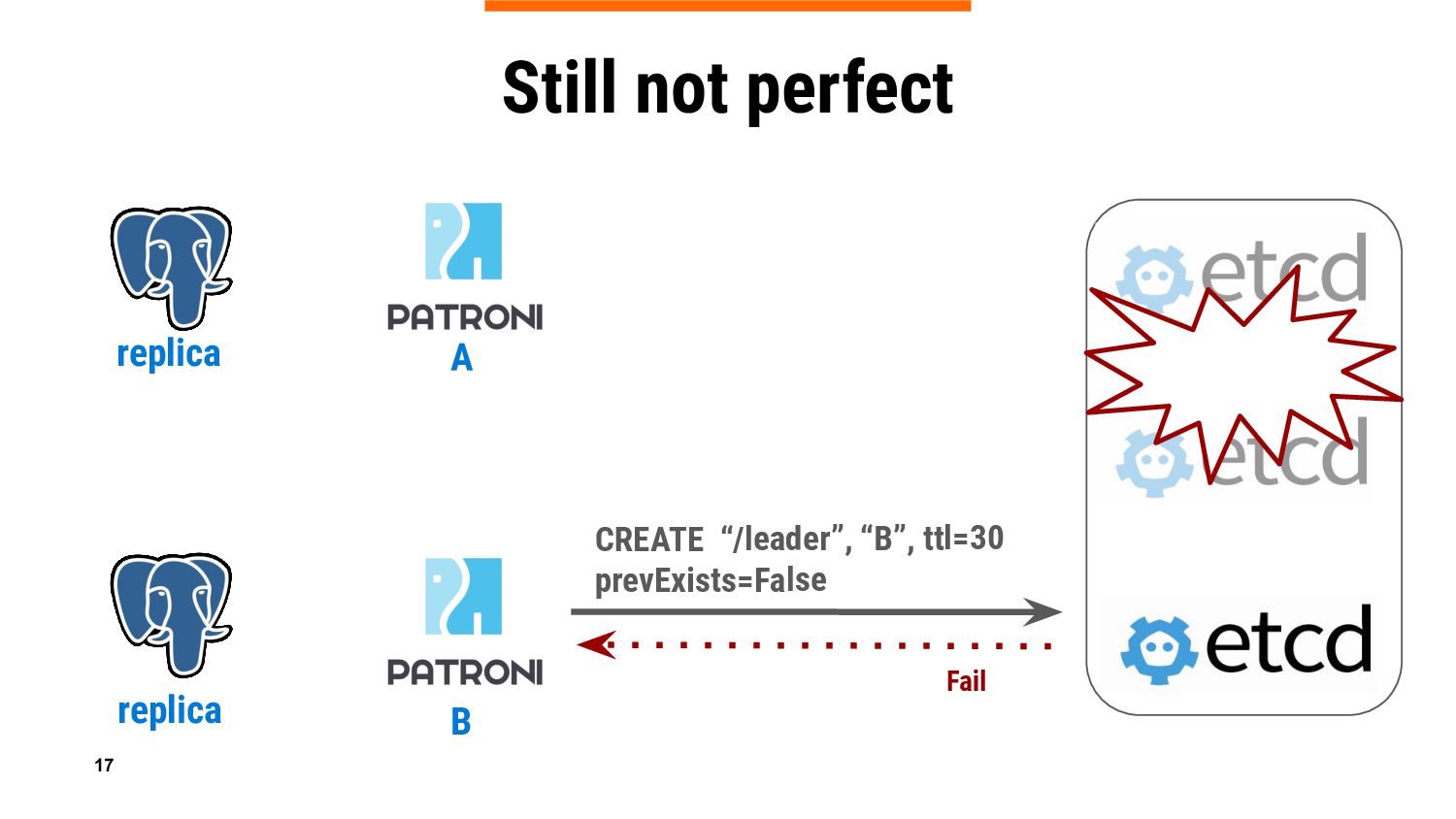{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}