Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Observability
Search
Daniel Temme
May 06, 2024
63
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Observability
Talk from DevConf 2024
Daniel Temme
May 06, 2024
More Decks by Daniel Temme
See All by Daniel Temme
Lean Startup Rubyfuza
dmt
4
150
Featured
See All Featured
The agentic SEO stack - context over prompts
schlessera
0
850
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Ethics towards AI in product and experience design
skipperchong
2
330
Bash Introduction
62gerente
615
220k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Context Engineering - Making Every Token Count
addyosmani
9
1k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
How to Ace a Technical Interview
jacobian
281
24k
Everyday Curiosity
cassininazir
0
260
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Transcript
Making Observability Tangible with the help of test automation
None
(slides and references are available online) Why I f ind
the topic interesting O11y 101 (a brief intro and some ideas) A playground to experiment Agenda
https://unsplash.com/photos/time-lapse-photo-of-lighted-ferris-wheel-at-park-during-nighttime-WnADr2BG174
(Reenactment) A long time ago...
https://unsplash.com/photos/yellow-and-black-bird-on-brown-wooden-post-q77K0zIDTmI
https://unsplash.com/photos/photography-of-theater-chairs-e_RpjNyMgEM
https://web.archive.org/web/20110128133821/https://www.net f lix.com/
Please hold for a brief interruption https://unsplash.com/photos/white-and-red-plastic-packs-9FDI-_E29 f k
The o11y building blocks O`bservabilit | wc - l `y
• Metrics • Traces • Logs
Metrics • High rate of events, with low cardinality at
a reasonable cost • Gauges and counters (and distributions/histograms from those) • Think CPU load, temperature, durations, number of requests
Traces • Medium rate of events, supplement metrics • Durations
across systems • Think waterfall graphs and pro f ilers (which some APM tools now also include in trace data)
Logs • Lower rate of events for comparable cost to
metrics but with higher cardinality of related data • Ideally structured, ideally one line per service per request
Lower level questions What questions to ask? • which of
my hosts have high cpu load? • which service is giving a lot of 500 error responses? • where is the time spent on this queue processing an event?
Slightly broader questions What questions to ask? • when will
I run out of my error budget for my SLO? • how many items are we selling compared to the same time last month? • how many instances can we turn off?
Higher level questions What questions to ask? • how much
of our daily sales are from repeat customers? • how many streams do our customers play on average per month over time? • how much are we paying per request handled?
https://unsplash.com/photos/a-sign-that-is-on-the-side-of-a-hill-jCfDzOQ2-C8
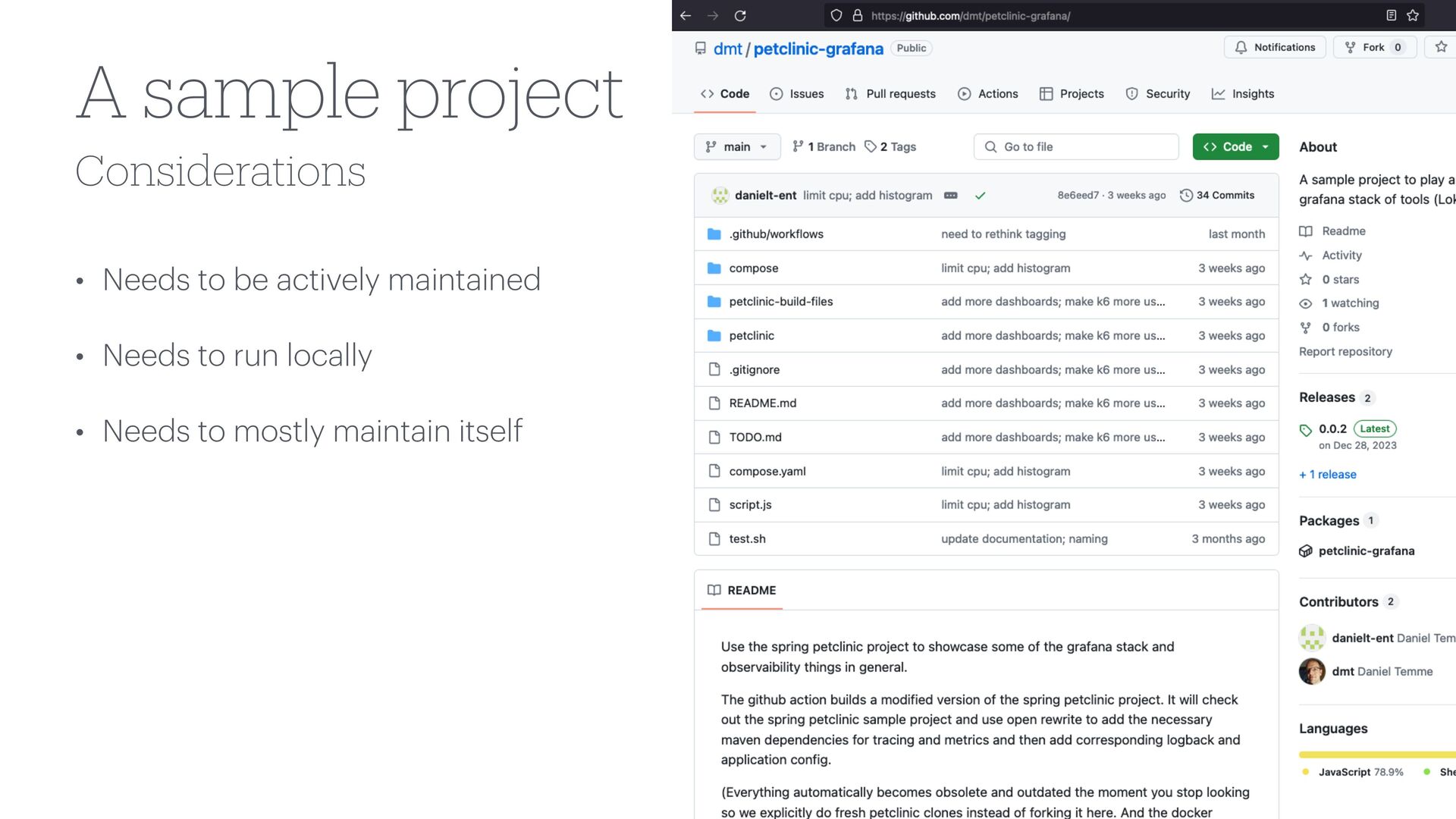
Considerations A sample project • Needs to be actively maintained
• Needs to run locally • Needs to mostly maintain itself
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}