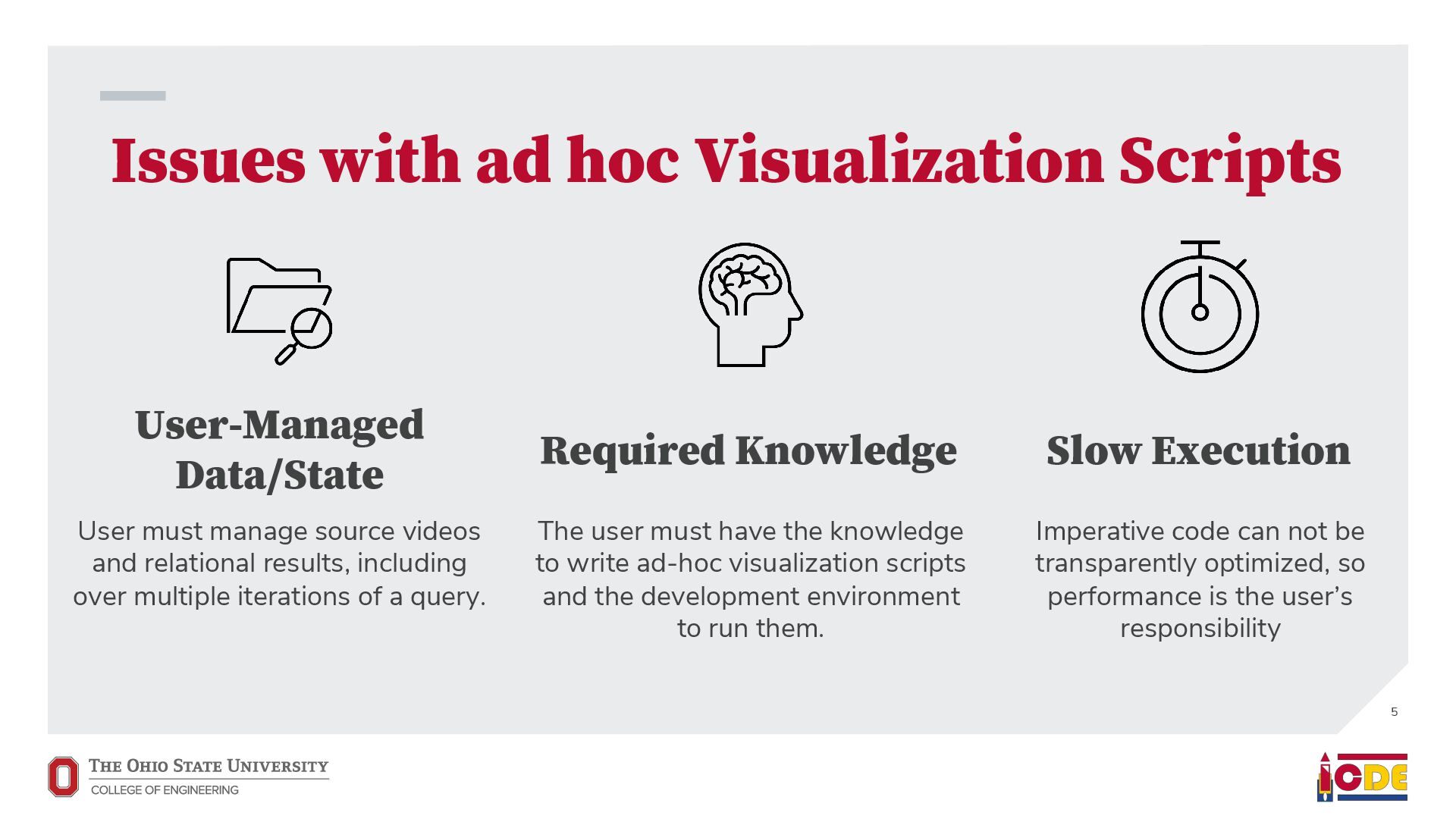
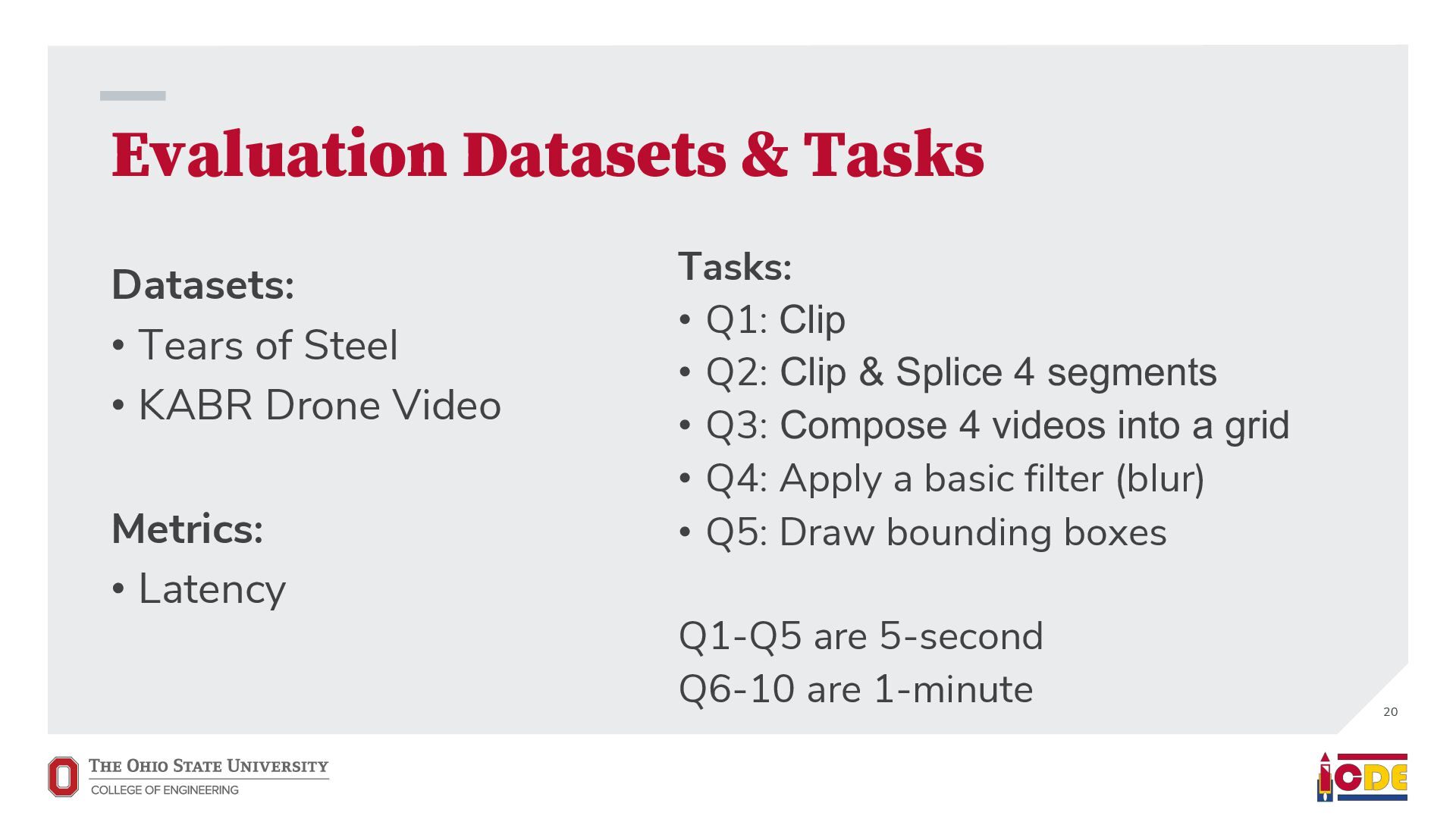
must manage source videos and relational results, including over multiple iterations of a query. The user must have the knowledge to write ad-hoc visualization scripts and the development environment to run them. Required Knowledge Slow Execution Imperative code can not be transparently optimized, so performance is the user’s responsibility
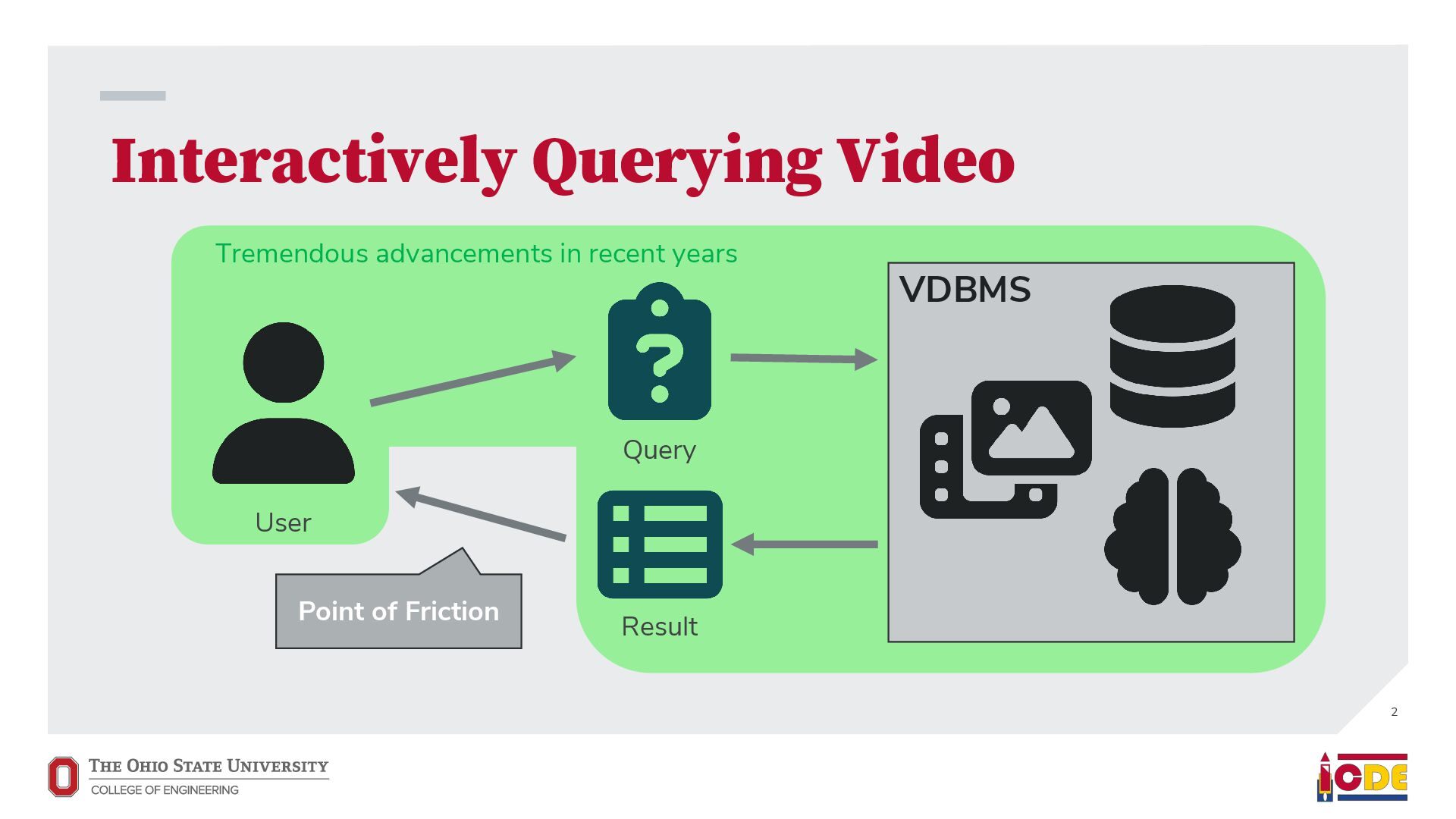
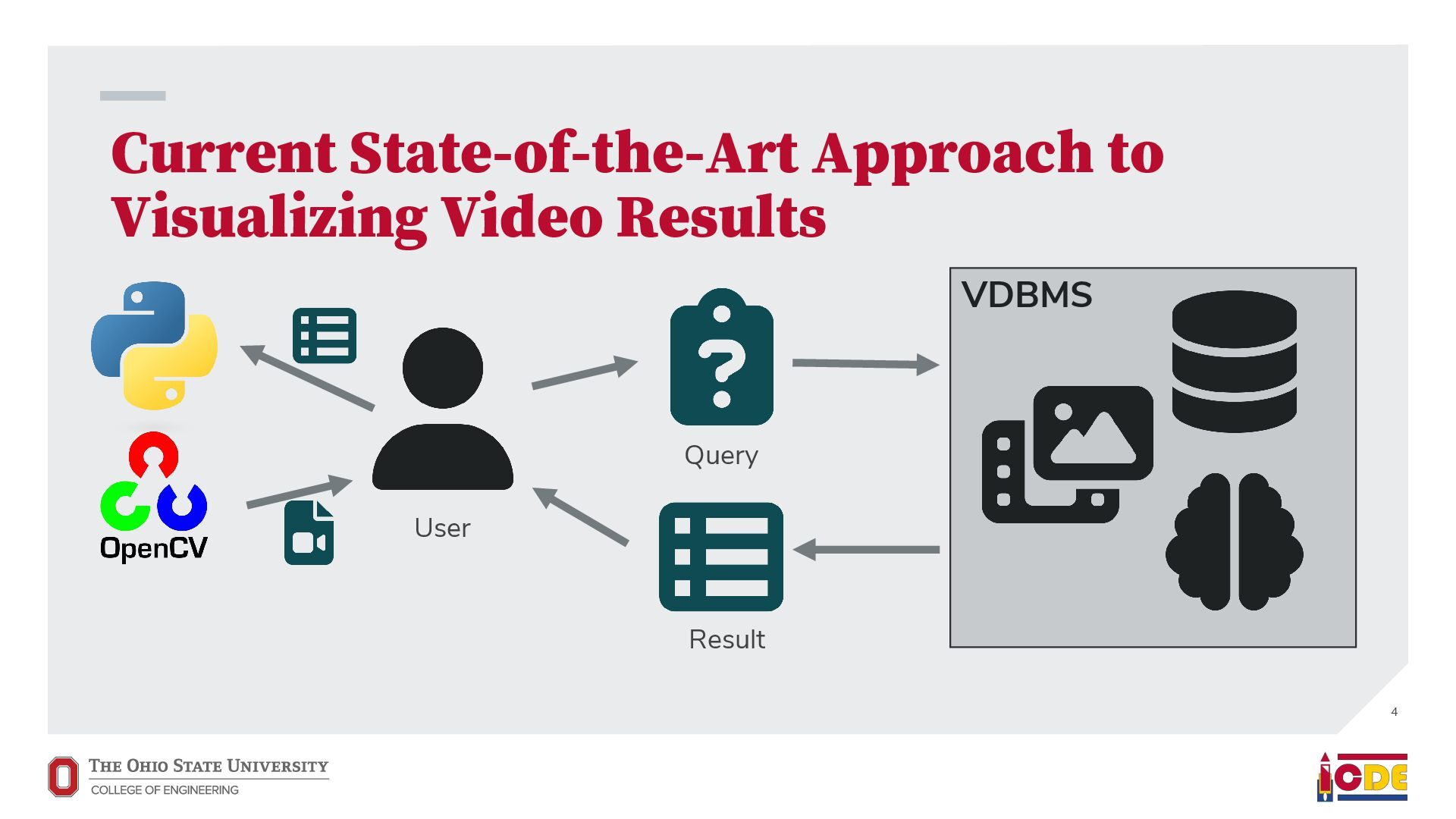
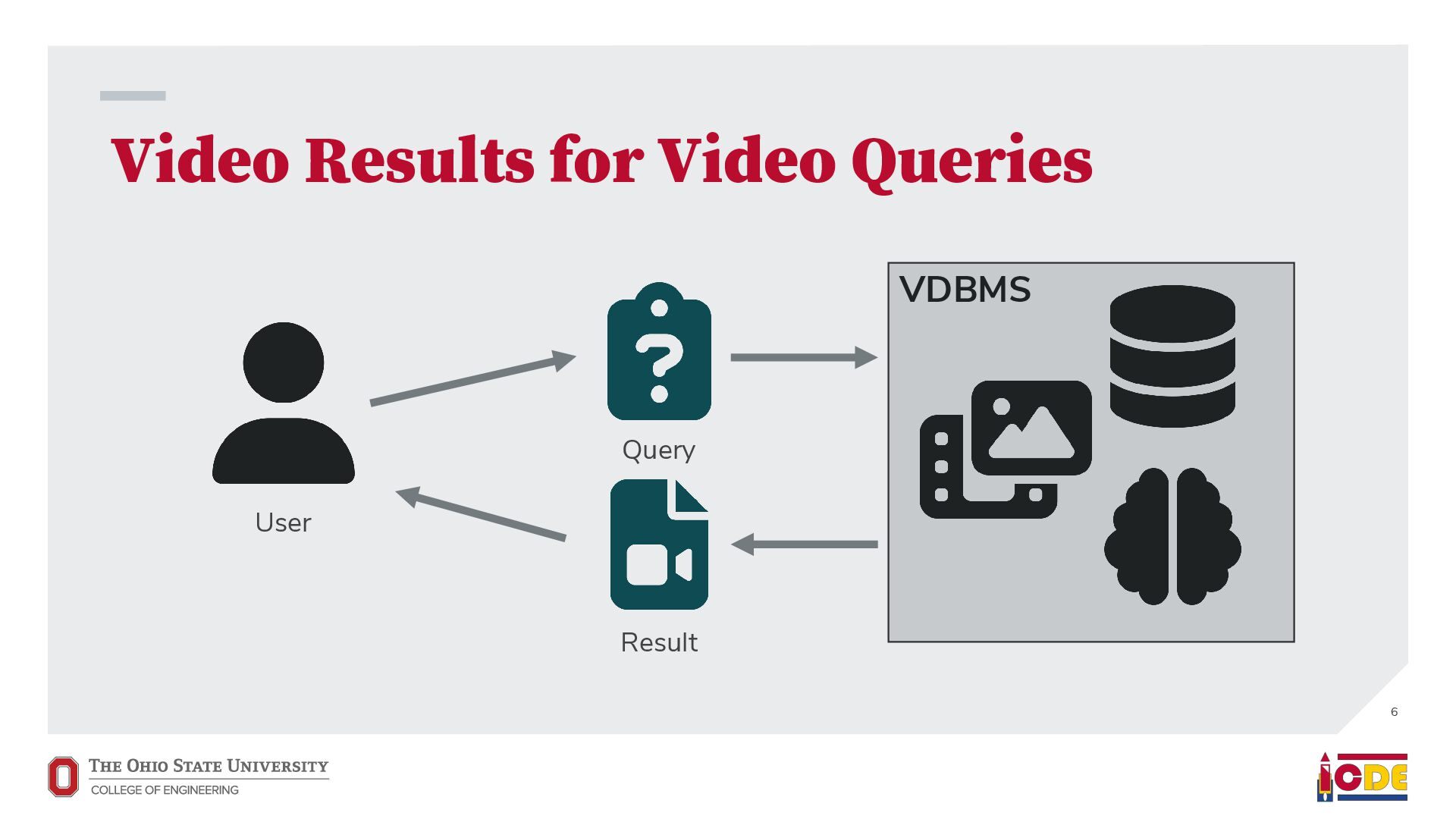
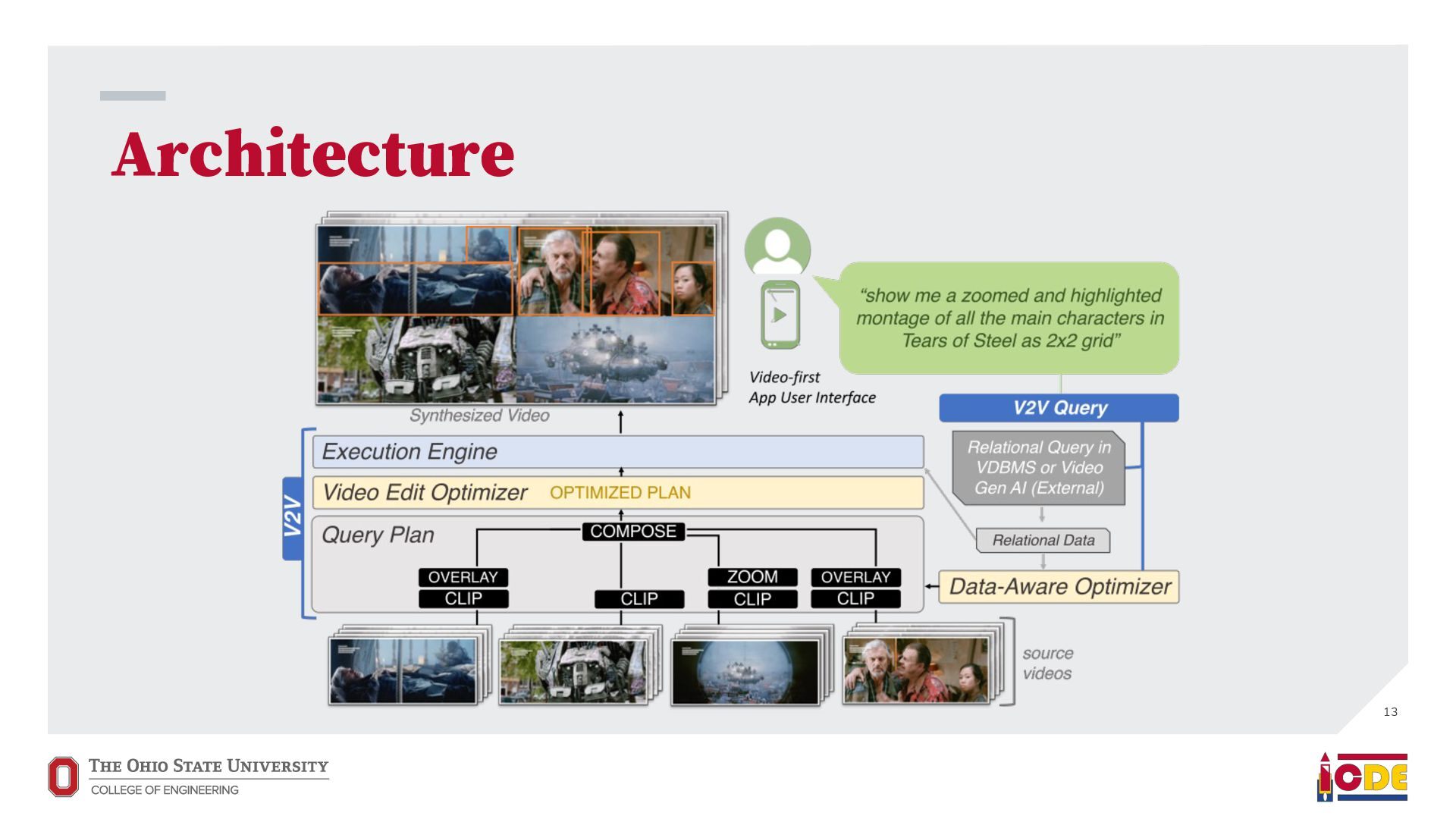
video results for video queries • Support broad use cases, not domain-specific tasks • Answer every query that starts with “show me…” • Video edits should be able to use relational data “show me” Query VDBMS Result Video
A data array is an array of data values Arrays are indexed by a rational number timestamp Index 0/24 1/24 2/24 3/24 4/24 … Value 3 4 5 2 4 … Array: Arrays can be backed by JSON, SQL, etc.
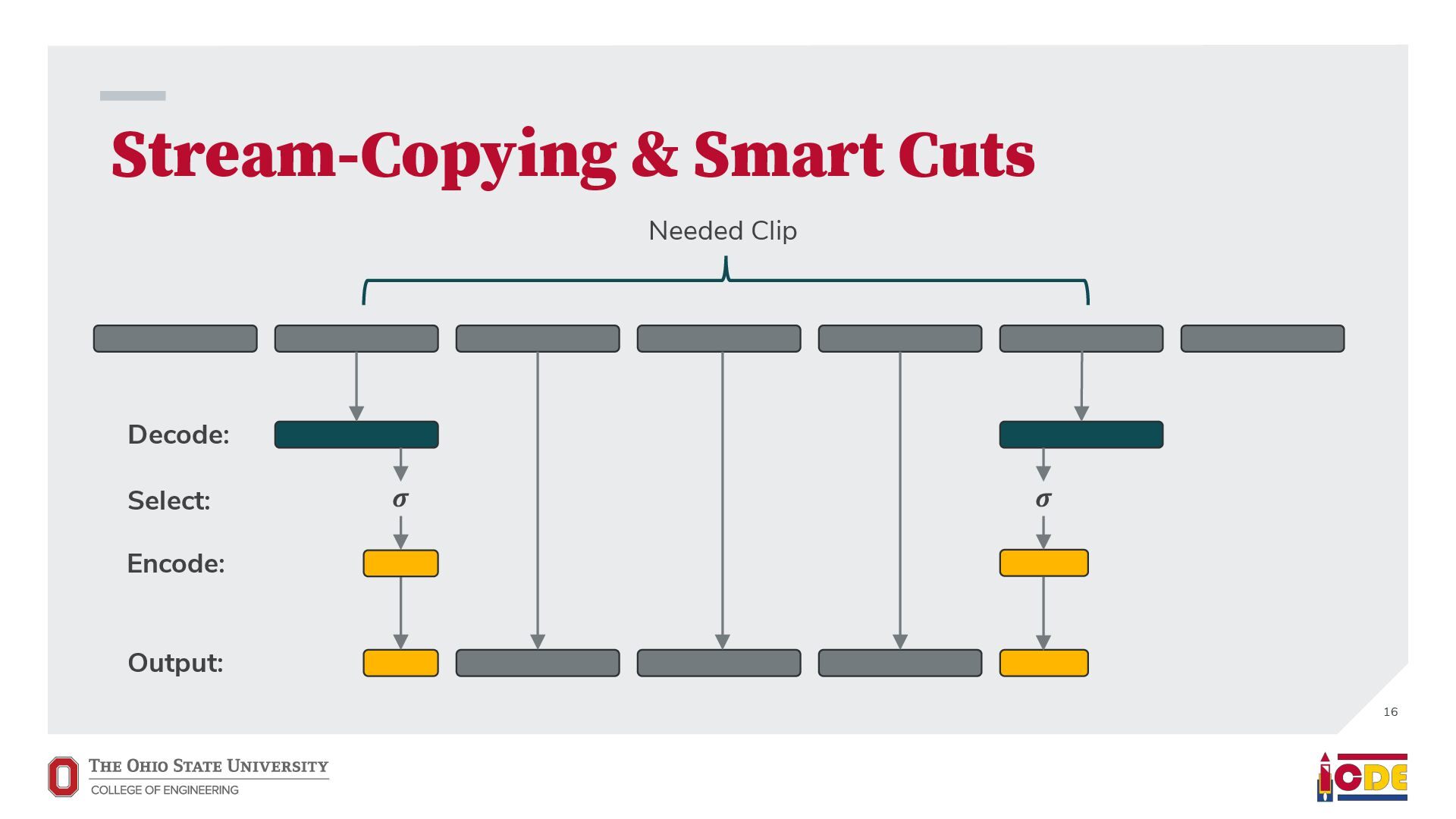
video processing optimizations: • Temporal sharding • Operator merging • Stream copying & smart cuts All plans are reduced into FFmpeg commands for execution 14
further optimize editing • Every filter has a data-dependent equivalence (DDE) function • Specs are run twice, first the DDEs with data values and symbolic frames, then the actual filter with data values and actual frames 17
the identity filter iff there are no objects drawn on that frame 18 BoundingBoxdde(𝑥: Frame, 𝑏: List<ObjectBound>) = > 𝑥, 𝑏 = 0 BoundingBox(𝑥, 𝑏), 𝑏 > 0
= BoundingBox(vid1[t], vid1_bb[t]) Given a spec: We can evaluate it with DDE functions to find an equivalent optimized spec on the specific data values: TimeDomain = Range(0, 300) Render(t) = match t { t in Range(0, 100) => vid1[t], t in {101, 102, 103} => BoundingBox(vid1[t], vid1_bb[t]), t in Range(104, 300) => vid1[t], } Start and end of video can now be stream-copied
they are generated • Hardware-Accelerated Processing • Hardware-accelerated processing could significantly lower latency • Natural Language Querying • Ideally, we should be able to answer any “show me …” style query 22
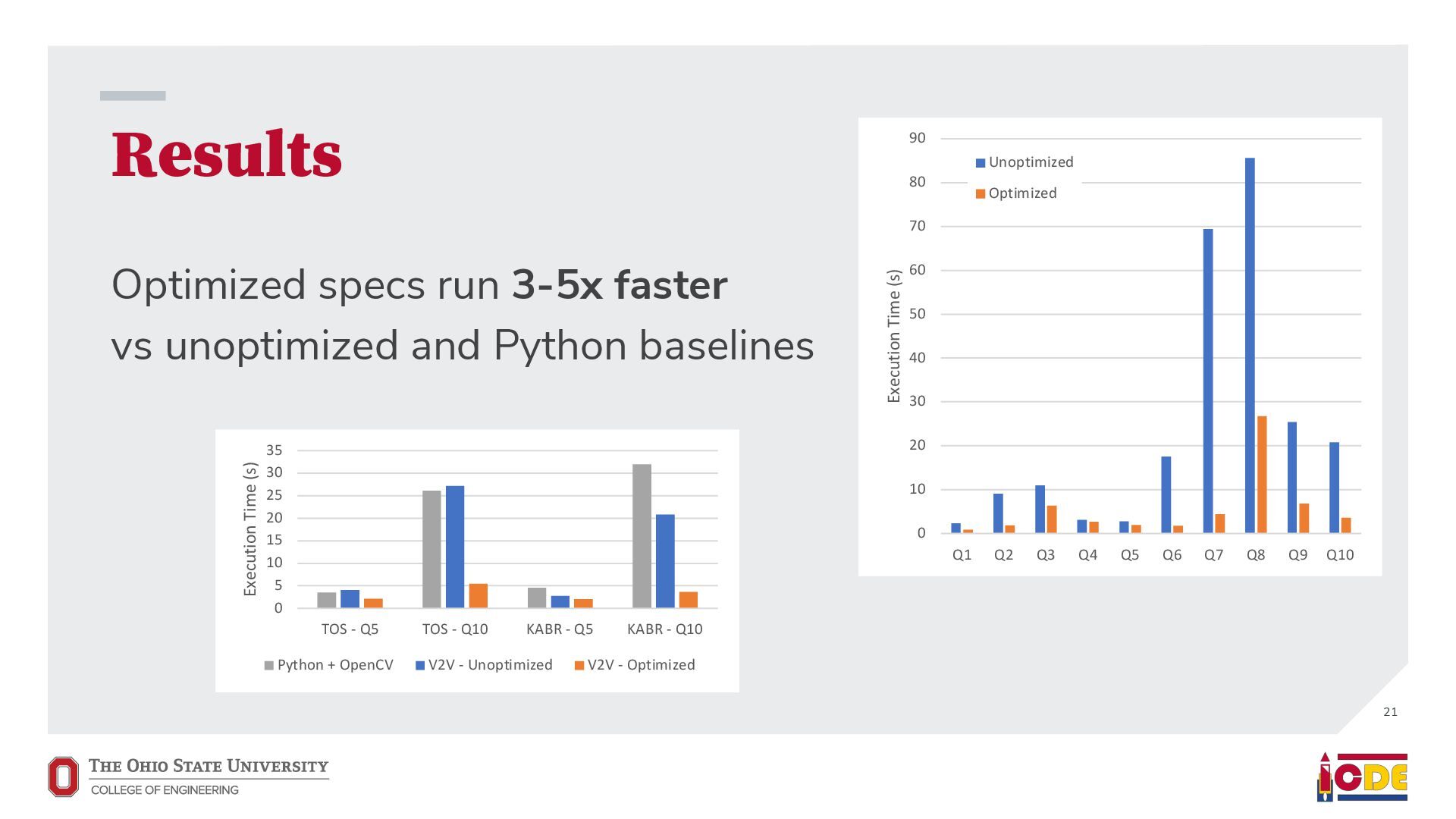
engine • We use an intermediate DSL representation of edited result videos, and then uses DBMS-style optimizations to run them • Our implementation, V2V, has optimizations which consistently deliver speedups over 3x 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}