Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Zennへのスパム投稿が急増したのでLLMでなんとかした話
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
dyoshikawa
September 19, 2024
1.5k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Zennへのスパム投稿が急増したのでLLMでなんとかした話
dyoshikawa
September 19, 2024
More Decks by dyoshikawa
See All by dyoshikawa
エンジニア向けコミュニティZennの開発チームを支える自動化の仕組み.pdf
dyoshikawa1993
0
2.6k
生PHPで学ぶSSRF.pdf
dyoshikawa1993
0
190
Google Cloud Vertex AIにおけるGemini vs Claude
dyoshikawa1993
0
240
OSSコミットしてZennの課題を解決した話
dyoshikawa1993
0
700
Featured
See All Featured
How STYLIGHT went responsive
nonsquared
100
6.2k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
410
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
Designing for Performance
lara
611
70k
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Into the Great Unknown - MozCon
thekraken
41
2.6k
Designing Experiences People Love
moore
143
24k
The Cult of Friendly URLs
andyhume
79
7k
Transcript
Zennへのスパム投稿が急増したので LLMでなんとかした話 Classmethod AI Talks 2024.9.17 クラスメソッド株式会社 Zennチーム dyoshikawa
自己紹介 @dyoshikawa 文系学部卒、元非エンジニア 2020年10月サーバサイドエンジニア枠で入社(今年で4年目) 2023年よりZennチームのソフトウェアエンジニア
自己紹介 フロントエンド: Next.js, React, Vue2など バックエンド: Ruby on Rails, Node.js+Express,
PHP+Laravelなど インフラ: Google Cloud, AWS 資格: 応用情報技術者、AWS Specialty Securityなど
Zennについて https://zenn.dev/ エンジニアのための情報共有コミュニティサービス 2023年12月に会員数10万|月間PV数1000万突破を発表 🎉
本題
生じた課題 👉
課題 2024年6月頃より、Zennにスパム投稿が急増 後で触れますが、多い月で約1500件検出される結果に ユーザの違反報告が増加したことで事態を認識することになった スパム投稿が読者の目に触れることが定常化することは避けたいた め、対策を講じることに
課題 しかし・・・ Zenn運営は4〜5人の少人数体制 人間の目ですべての投稿をチェックすることは現実的ではない 🤮 開発メンバーに自然言語処理や機械学習の専門的知見もない 🤔
LLM+プロンプトエンジニアリングなら? 💡
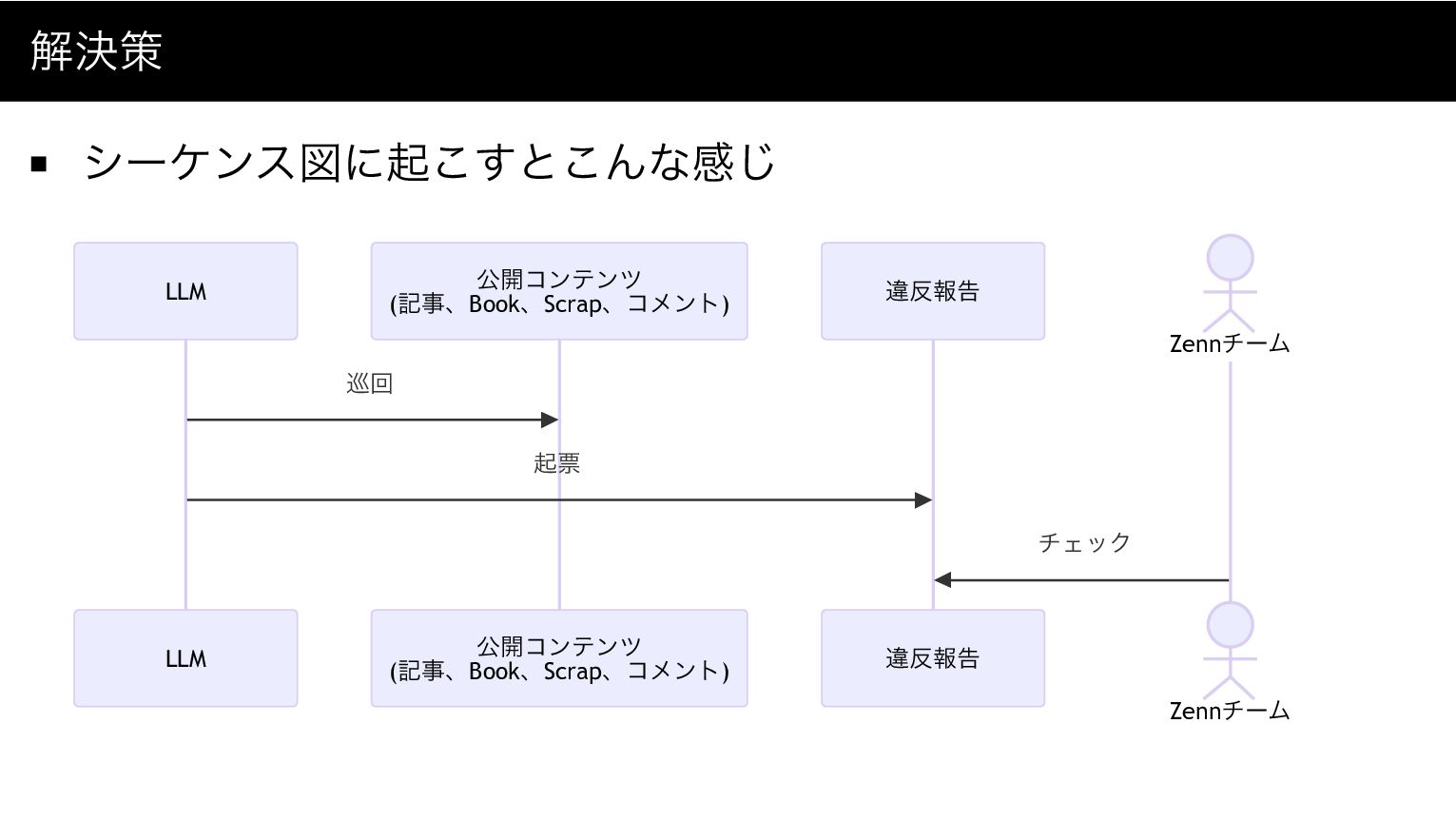
浮かんだ解決策 LLM+プロンプトエンジニアリングでスパム投稿を自動検出する仕組 みを構築する あまりコア機能でないところに工数もかけたくないので、フロー全 体(検出データの蓄積からオペレーターによる目視確認とその処理 まで)は既存の違反報告機能を活用する 1. LLMが公開コンテンツを巡回 2. スパムと判定した場合、違反報告を起票
3. Zennチームが違反報告をチェック
解決策 シーケンス図に起こすとこんな感じ 違反報告 公開コンテンツ (記事、Book、Scrap、コメント) LLM 違反報告 公開コンテンツ (記事、Book、Scrap、コメント) LLM
Zennチーム 巡回 起票 チェック Zennチーム
前提 🔍
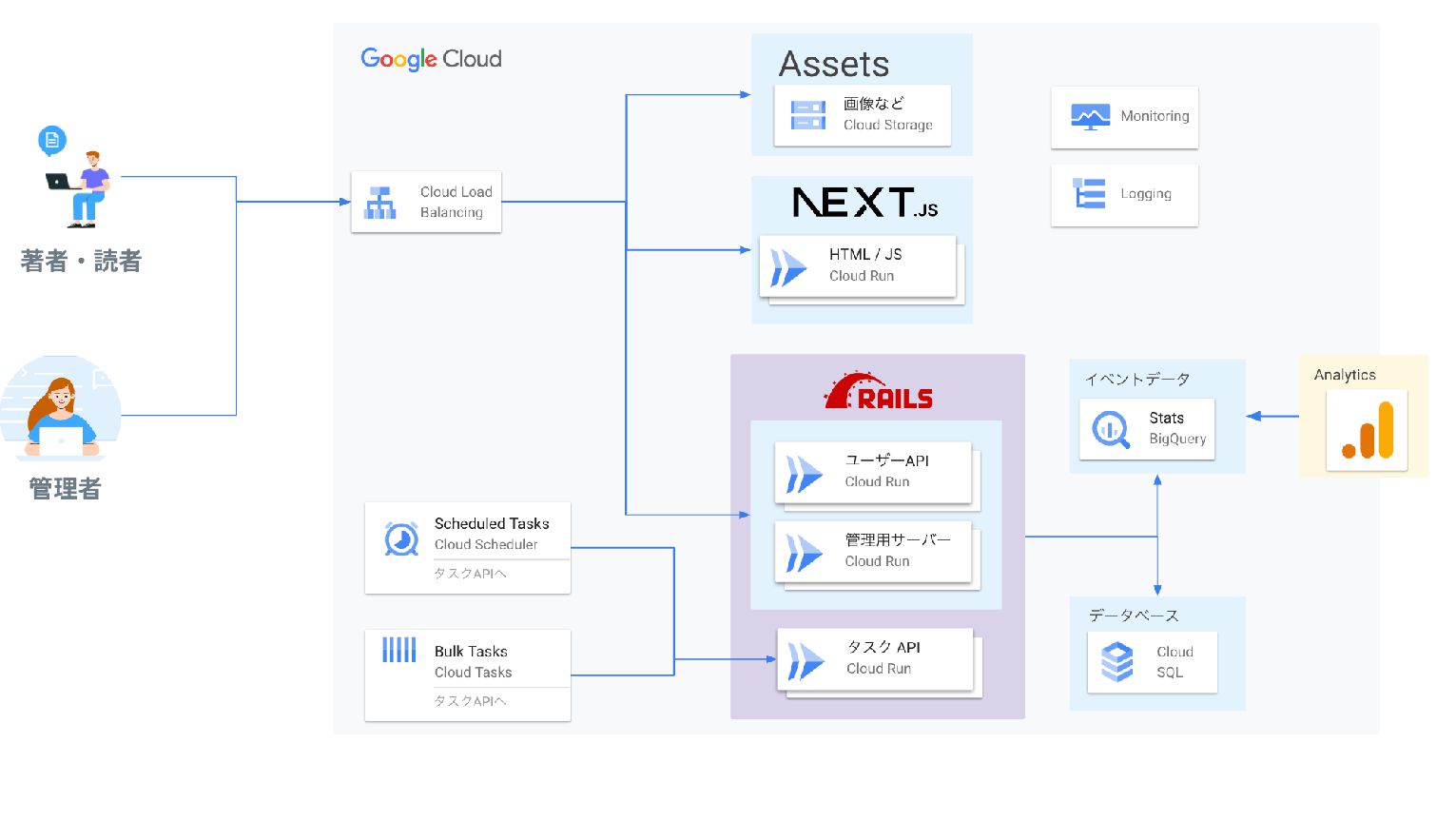
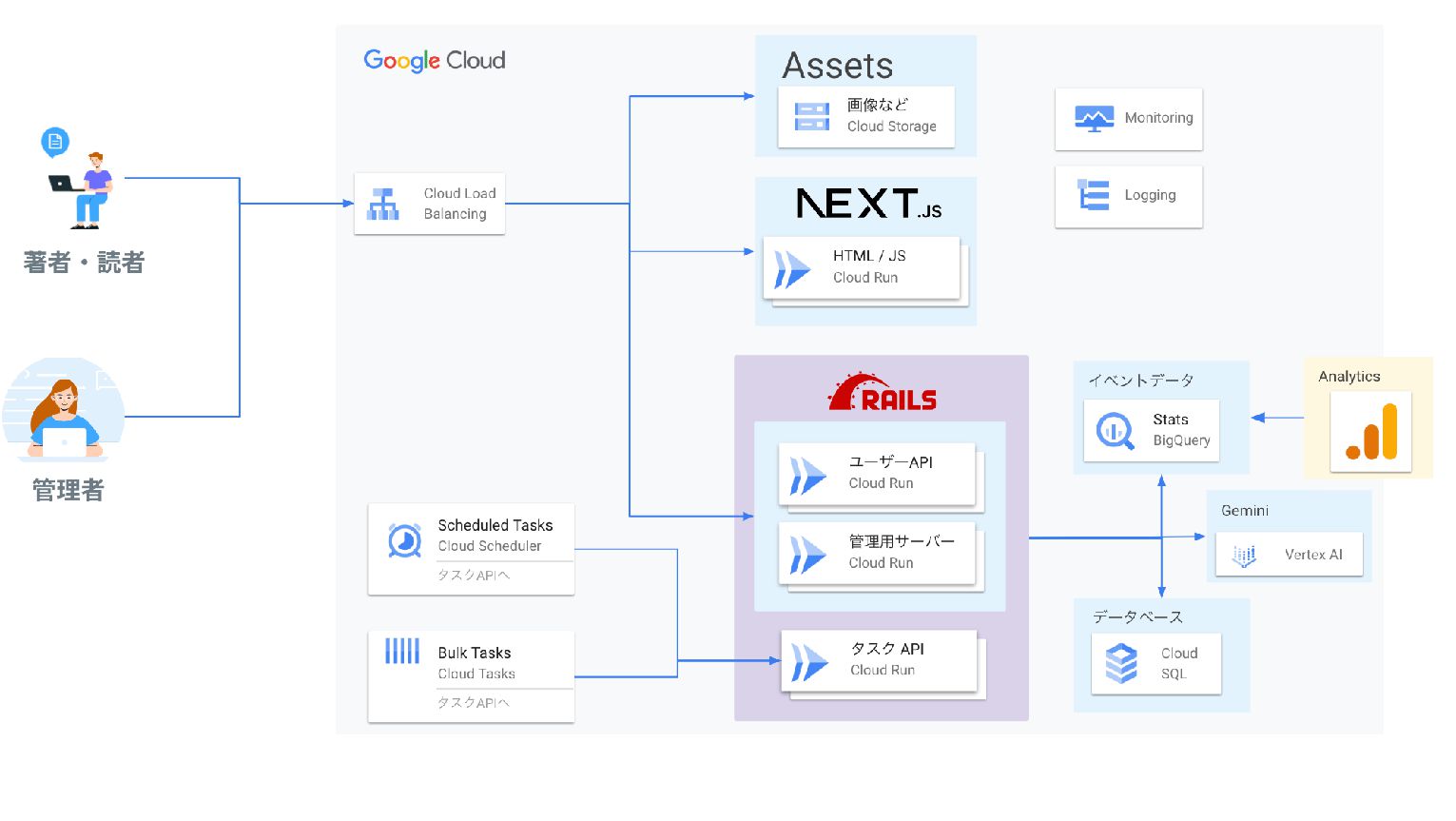
現状のZennの構成 🔧
None
そのため以下が前提になる インフラはGoogle Cloud Ruby on Railsバックエンドから呼び出す
やっていく 💪
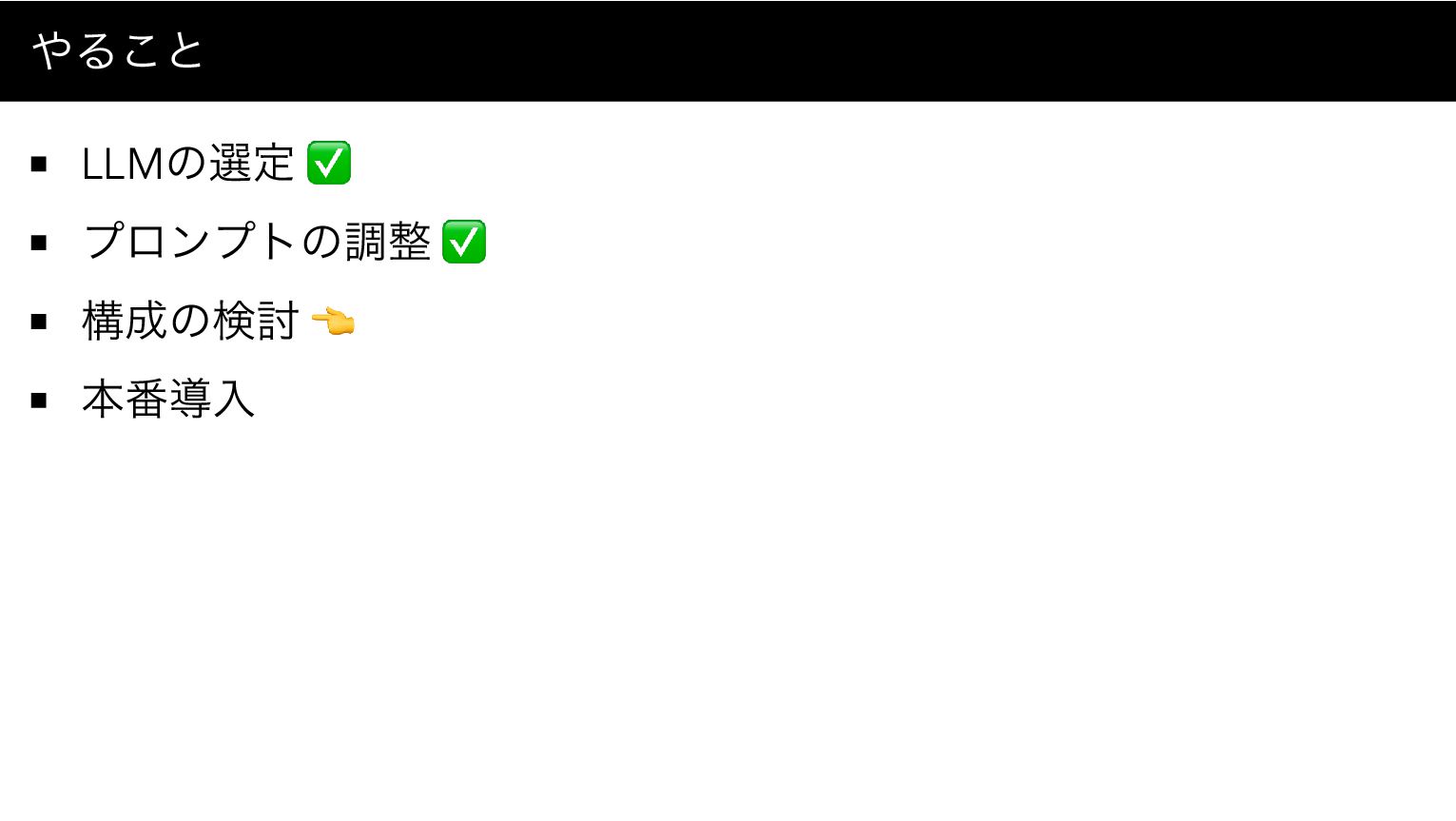
やること LLMの選定 プロンプトの調整 構成の検討 本番導入
やること LLMの選定 👈 プロンプトの調整 構成の検討 本番導入
LLMの選定 Google Cloud Vertex AIプラットフォームを使用 ZennのインフラがGoogle Cloudだから IAM権限管理などなど考えるとクラウドプラットフォームは寄せてし まった方が楽
Gemini?Claude? Vertex AIで使える2大モデル Gemini/Claude Claudeは特にAWSのBedrockを採用する場合においてファーストチ ョイス感があり、かつ評判も良い印象 しかしGoogleといえばGeminiか?
比較検討する ⚖️
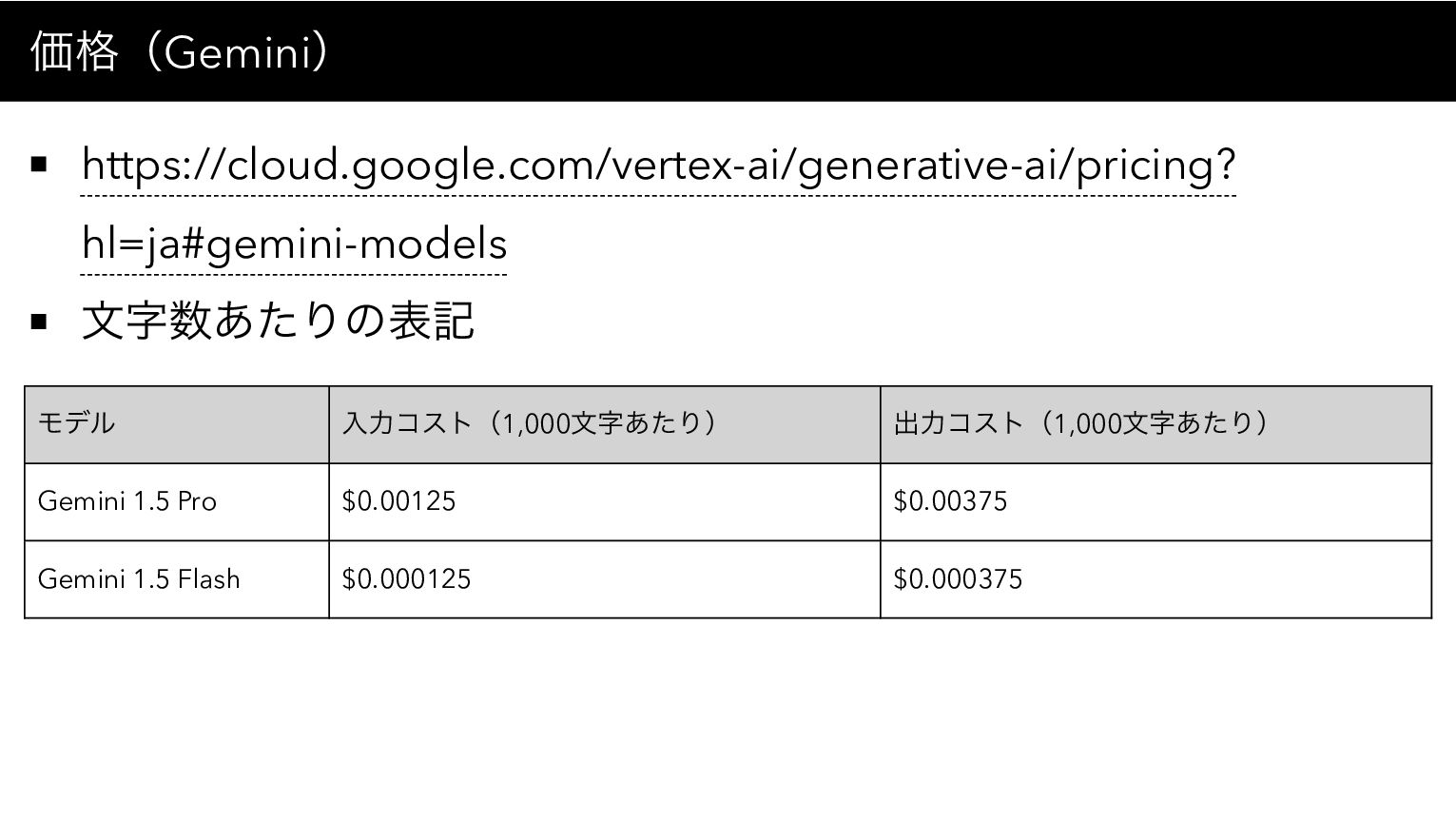
価格(Gemini) https://cloud.google.com/vertex-ai/generative-ai/pricing? hl=ja#gemini-models 文字数あたりの表記 モデル 入力コスト(1,000文字あたり) 出力コスト(1,000文字あたり) Gemini 1.5 Pro
$0.00125 $0.00375 Gemini 1.5 Flash $0.000125 $0.000375
価格(Claude) https://cloud.google.com/vertex-ai/generative-ai/pricing? hl=ja#partner-models トークン数あたりの表記 モデル 入力コスト (1,000トークンあたり) 出力コスト (1,000トークンあたり) Claude
3/3.5 Sonnet $0.003 $0.015 Claude 3 Haiku $0.00025 $0.00125
価格 1トークン≒1文字(日本語のマルチバイト文字換算で)と仮定すれ ば、Geminiの方が単価は安そう? Gemini 1.5 Pro 入力: $0.00125 / 1000文字あたり
Claude 3/3.5 Sonnet 入力: $0.003 / 1000トークンあたり
リージョン Claude Sonnet: us-central1 (Iowa), asia-southeast1 (Singapore) Haiku: us-central1 (Iowa),
europe-west4 (Netherlands) Geminiは東京リージョン(asia-northeast1)が使える
SDK対応状況 Ruby on Railsから使いやすいか? SDK対応状況 Gemini: Python, Node.js, Go, Dart,
Android(Java, Kotlin), Swift Claude: Python, Node.js
SDK対応状況 Rubyから呼び出すという点では同等 どちらもSDKがないため SDK対応言語はGeminiの方が多い
JSON出力 LLMをシステムに組み込む際は返答をJSONで出力してくれた方が何 かと都合がいい LLMによってJSON出力指示のベストプラクティスが異なる
JSON出力(Gemini) Gemini API を使用して JSON 出力を生成する | Google AI for
Developers generation_config に {"response_mime_type": "application/json"} を指定することでJSON形式の出力になる
JSON出力(Gemini) 構造はプロンプトで下記のように指示する PythonのType Hints風の記法 List 5 popQular cookie recipes. Using
this JSON schema: Recipe = {"recipe_name": str} Return a `list[Recipe]` 実際、手元の検証ではJSON Schemaで指示するよりJSONパース エラーが少なかったので上記がベスプラっぽい response_schema にJSON Schemaを渡す方法もある こちらの方が精度良さそう
JSON出力(Claude) 出力フォーマットの制御 (JSONモード) - Anthropic LLM(assistant)の出力の一文字目に { を指定する messages: [
{ role: "user", content: [ { type: "text", text: "猫についての俳句を書いてください。“first_line”、“second_line”、“third_line”をキーとするJSON形式を使用してください。" }, ], role: "assistant", content: [ { type: "text", text: "{" # JSONの一文字目を入力しておく }, ], } ],
JSON出力(Claude) 構造の指定はどうする? ドキュメントの例はプロンプト内において 猫についての俳句を書いて ください。“first_line”、“second_line”、“third_line”をキーとす るJSON形式を使用してください。 JSON形式でチョコレートチップクッキ ーのレシピを生成してください。 といったややざっくりした指定 手元の検証ではPython風、JSON
Schemaいずれでもおおむね期待通 りの出力が得られた
回答精度 モデルごとの回答精度を評価したい 以下を数件用意し、各モデルに判定させる スパムでない投稿と判定されることを期待するコンテンツ スパム投稿と判定されることを期待するコンテンツ モデルごとにプロンプトは多少カスタマイズ
回答精度 判定結果よりスコア付けすると、おおむね次の結果になった Gemini 1.5 Flash < Claude 3 Haiku =
Claude 3 Sonnet = Claude 3.5 Sonnet < Gemini 1.5 Pro Gemini 1.5 Proでベースのプロンプトを作成したので、必ずしもフェ アではないかも LLMの定量的な評価は難しい 🤔 でも取れた結果を材料にするしかない
回答精度比較はほどほどで良い 現時点ではGPT/Claude/Geminiの御三家(?)であればどれを選ん でも大失敗することはないはず 回答精度は常にお互い抜きあっている状態 その時点で一番良いものを拘って選んでも、状況がすぐに変わる 失敗しないようにするのではなく、いざとなったらモデルを差し替 えることができる素結合なソフトウェア設計をすることが重要そう
Gemini独自の機能 Geminiのみ使える機能がある Context Caching 同じプロンプトを繰り返し使用する場合、コンテキストをキャッ シュしてコストの最適化ができる Batch Prediction リアルタイムな応答を必要としない用途の場合、バッチ処理でコ ストの最適化ができる
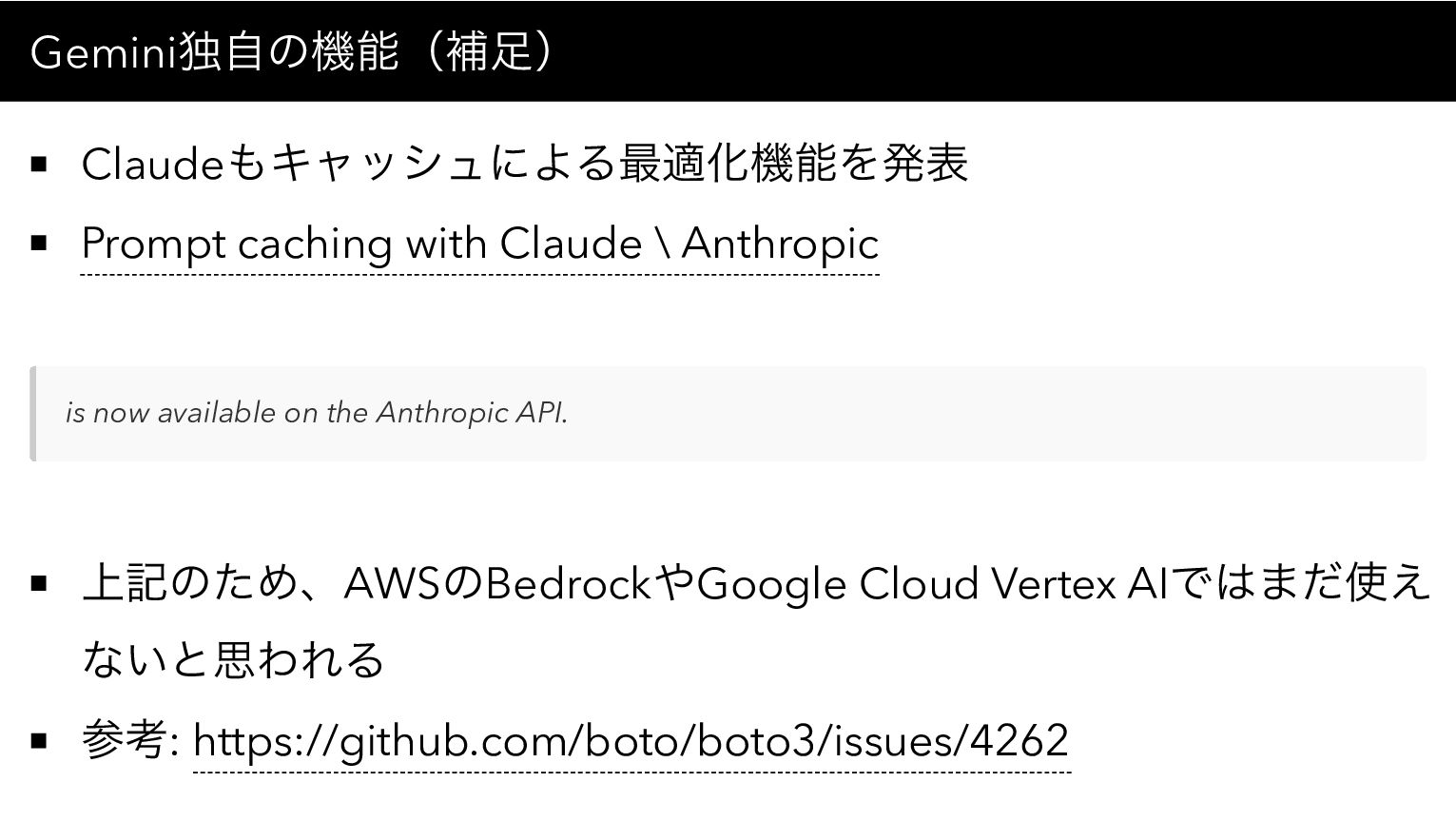
Gemini独自の機能(補足) Claudeもキャッシュによる最適化機能を発表 Prompt caching with Claude \ Anthropic is now
available on the Anthropic API. 上記のため、AWSのBedrockやGoogle Cloud Vertex AIではまだ使え ないと思われる 参考: https://github.com/boto/boto3/issues/4262
Gemini vs Claudeのまとめ ※あくまでVertex AI上で動かす場合の比較 項目 結果 価格 ほぼ同等。Context CachingやBatch
Predictionの存在を考えるとコストはGemini優位か リージョン Geminiは東京リージョンが使える JSON出力 両方できる。Gemini 1.5 Proはパラメータから厳密な指定が可能 SDK Gemini: Python, Node.js, Go, Dart, Android(Java, Kotlin), Swift Claude: Python, Node.js 回答精度 Gemini 1.5 Flash < Claudeの各モデル < Gemini 1.5 Pro(あくまで今回の検証において)
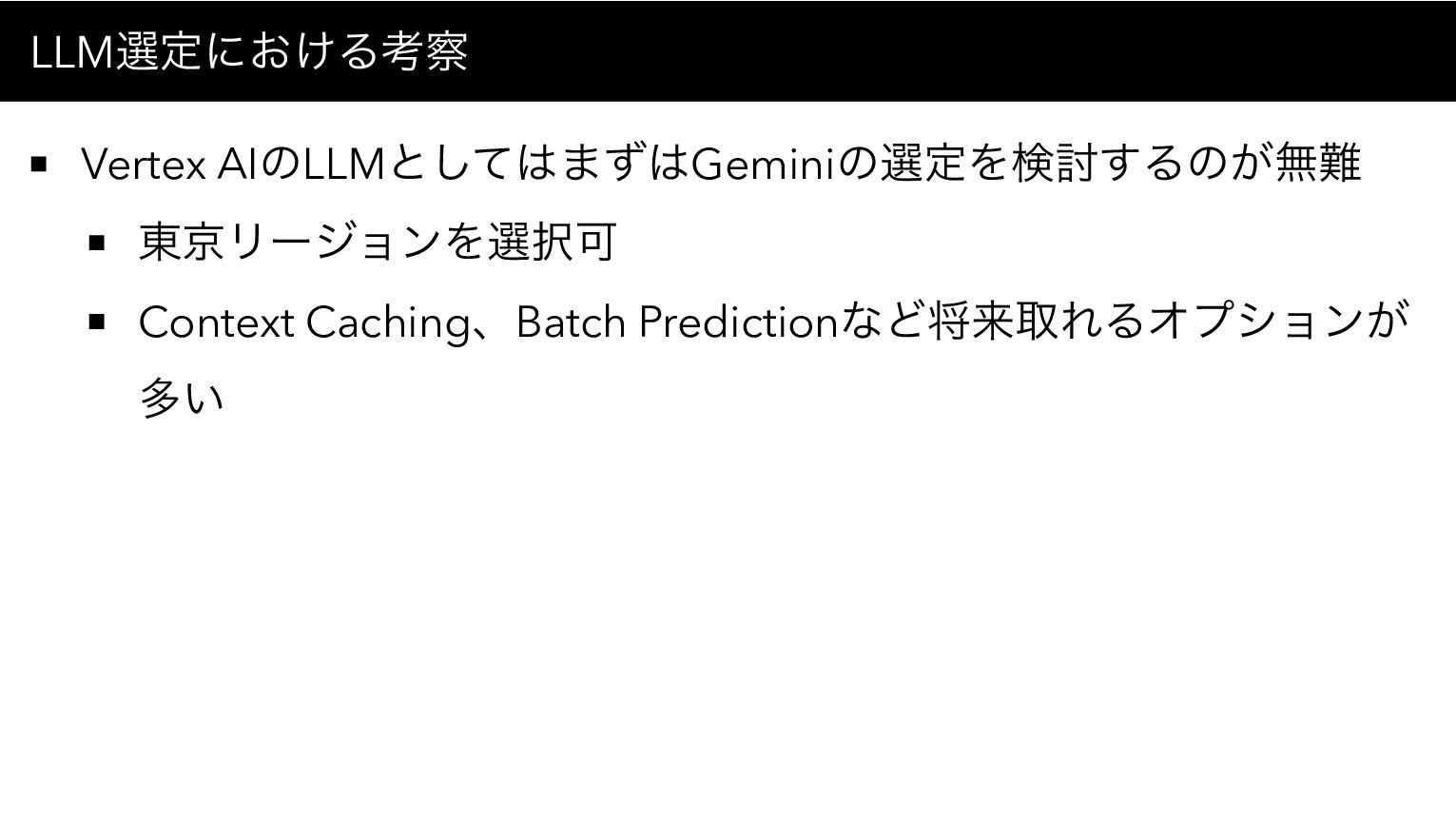
LLM選定における考察 Vertex AIのLLMとしてはまずはGeminiの選定を検討するのが無難 東京リージョンを選択可 Context Caching、Batch Predictionなど将来取れるオプションが 多い
今回はGemini 1.5 Proを選定 🤖
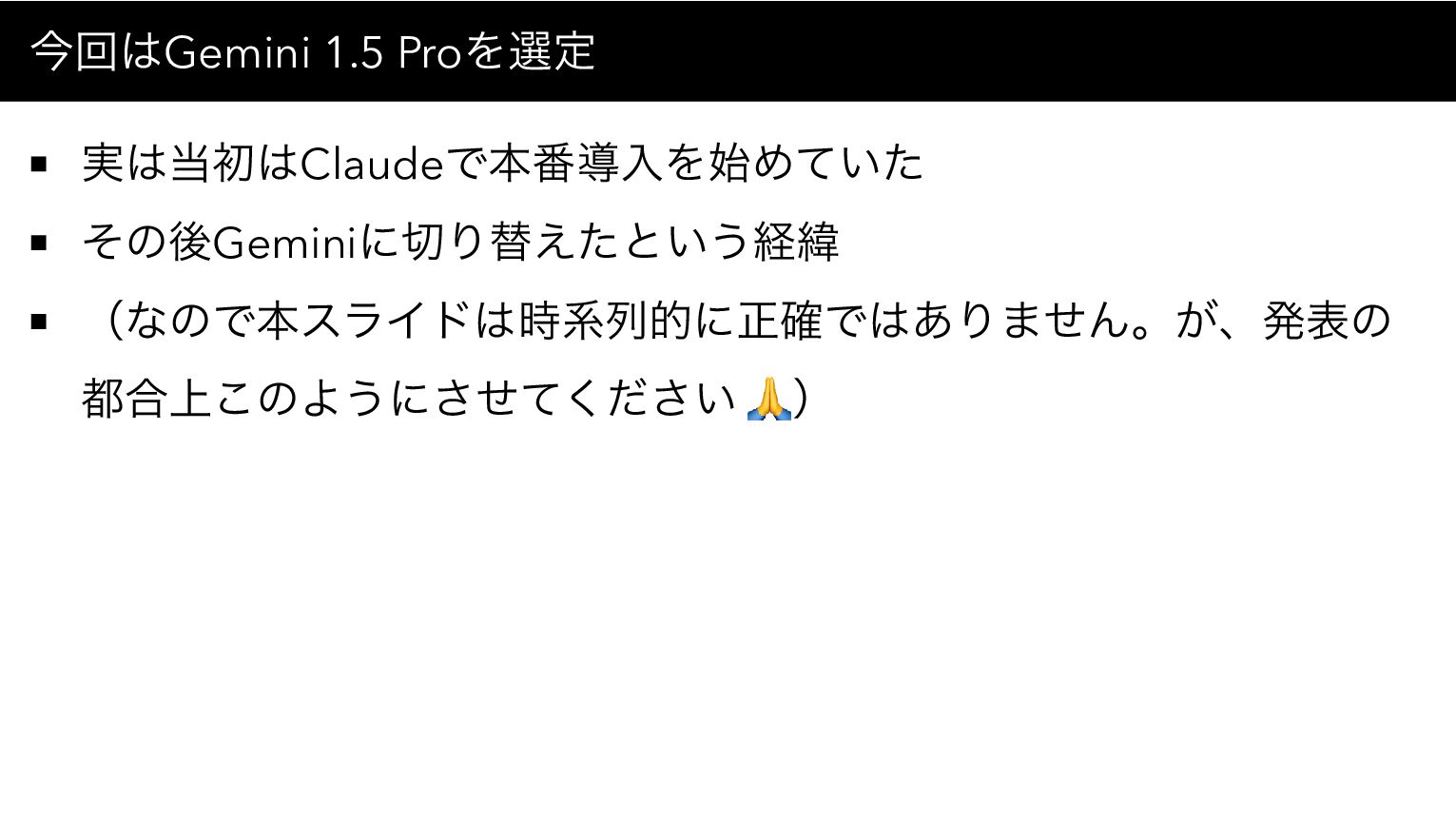
今回はGemini 1.5 Proを選定 実は当初はClaudeで本番導入を始めていた その後Geminiに切り替えたという経緯 (なので本スライドは時系列的に正確ではありません。が、発表の 都合上このようにさせてください 🙏)
LLMの選定おわり ✅
やること LLMの選定 ✅ プロンプトの調整 構成の検討 本番導入
やること LLMの選定 ✅ プロンプトの調整 👈 構成の検討 本番導入
プロンプトの調整 LLM選定時よりは手が込んだ検証をする 以下を十数件〜100件程度用意し、LLMに判定させる スパムでない投稿と判定されることを期待するコンテンツ スパム投稿と判定されることを期待するコンテンツ
プロンプトの調整 実行上の工夫として、テストデータのCSVファイル、検証用のカスタ ムrailsコマンドを作成しリポジトリにコミット。いつでも何度でも検 証しやすいようにする 判定 ↔️ プロンプト変更のサイクルを何度か回す
ほどほどにやる 事前のプロンプト調整と検証に時間はかけすぎない 「本番の」 「最新の」コンテンツで動かしてみないとわからないこ とも多い スパムの手口も刻一刻と変化する 精度が揺らいでも大惨事が起こる性質の取り組みではない 0% →90%にする労力 <<<<<
90% →99%にする労力 テストデータで90%程度の精度が出た時点で完了
プロンプトの調整おわり ✅
やること LLMの選定 ✅ プロンプトの調整 ✅ 構成の検討 本番導入
やること LLMの選定 ✅ プロンプトの調整 ✅ 構成の検討 👈 本番導入
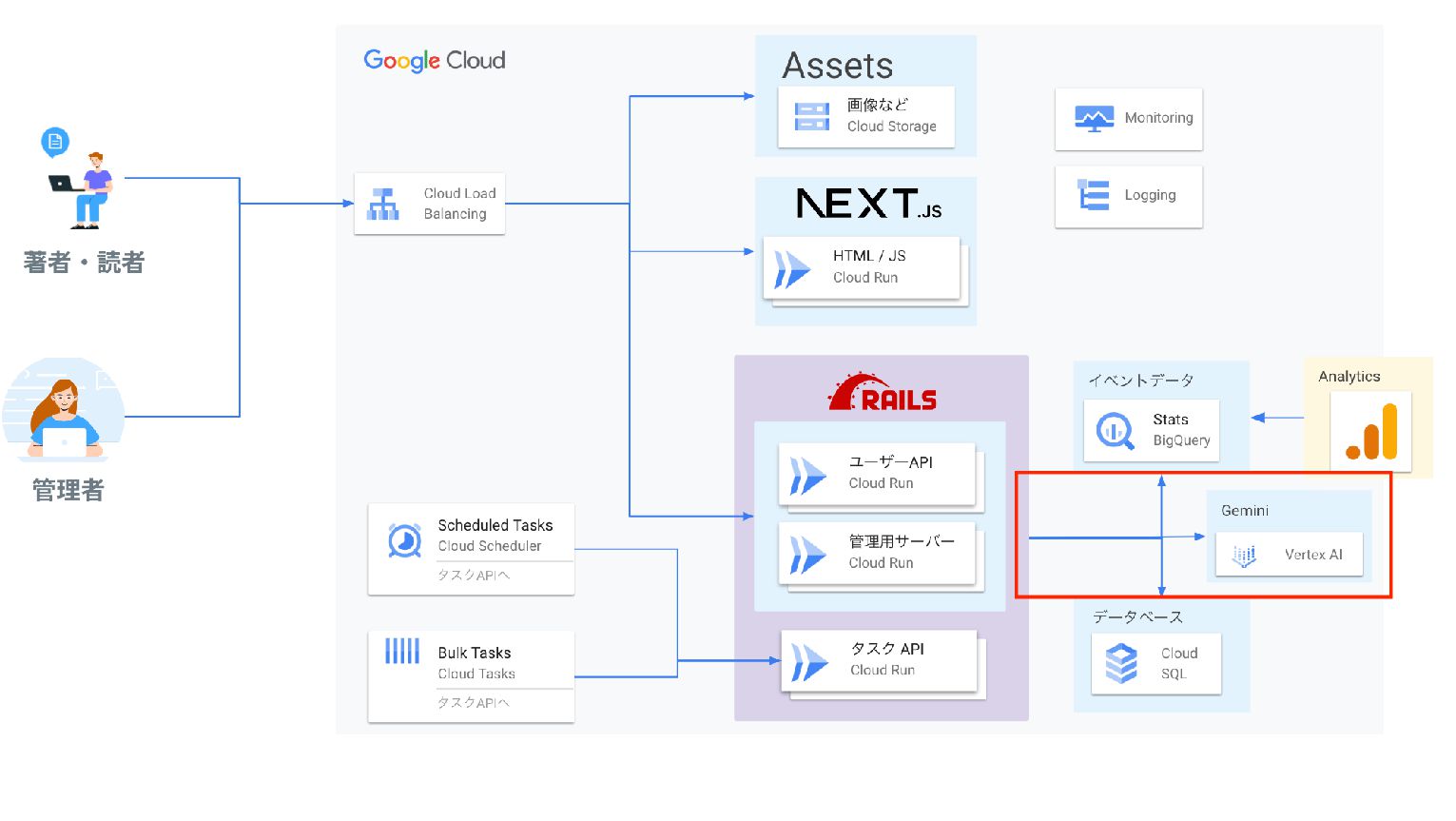
構成の検討 Railsで動作するタスクAPI(バッチ処理のためのワーカー)を使用 DBからコンテンツを取得 Geminiの判定にかける(スパムか否か) Cloud Schedulerで処理をキックして定期的に巡回させる
None
None
RubyからGeminiを利用する Geminiを呼び出すコード credentials = Google::Auth.get_application_default access_token = credentials.fetch_access_token!["access_token"] uri =
URI(API_URL) http = Net::HTTP.new(uri.host, uri.port) http.use_ssl = true request = Net::HTTP::Post.new(uri.request_uri) request["Authorization"] = "Bearer #{access_token}" request["Content-Type"] = "application/json" request.body = { contents: { role: "user", parts: [ { text: "こんにちは" } ], }, generation_config: { temperature: TEMPERATURE, max_output_tokens: MAX_TOKENS
RubyからGeminiを利用する ちなみにClaudeだとこんなコード request["Authorization"] = "Bearer #{access_token}" request["Content-Type"] = "application/json" request.body
= { anthropic_version: "vertex-2023-10-16", messages: [ { role: "user", content: [ { type: "text", text: "こんにちは" } ], } ], temperature: TEMPERATURE, max_tokens: MAX_TOKENS, stream: false }.to_json
構成の検討おわり ✅
やること LLMの選定 ✅ プロンプトの調整 ✅ 構成の検討 ✅ 本番導入
やること LLMの選定 ✅ プロンプトの調整 ✅ 構成の検討 ✅ 本番導入 👈
新施策の導入にあたっていつも考えること 相反する要求 スピード感は持ちたい 一方でそれにより生じるリスク・負の影響は最小化したい 両立するには・・・
段階的な導入 🚢
段階的な本番導入 できるだけ早い段階で小さく本番で動かす 素早くフィードバックを得られる 段階的に導入することで、何かあった時の負の影響を局所化する 負の影響の例: 管理画面の一覧に大量の誤検知が表示され、オペレ ーターが疲弊する
実際にやったこと 対象期間を絞る 対象コンテンツを絞る 記事のみなど 対象を絞ってスモールに導入し、様子を見る
実際にやったこと 徐々に他コンテンツ(Book・Scrap・コメント)に対象を拡大 対象期間も拡大 当初想定まで網羅できたら完了
本番導入おわり ✅
やること LLMの選定 ✅ プロンプトの調整 ✅ 構成の検討 ✅ 本番導入 ✅
結果 💥
結果 導入前と比べて3000%の検出件数 ユーザーより月間50件報告 →月間1500件検出(最大) ※ 報告されるユーザーやコンテンツの重複を含む スパム疑いのある投稿についてピーク時より約80〜90%の削減見込 み ユーザーがスパム投稿を目にする機会が減少
結果 月間140時間の運用工数を削減 新しく投稿されるすべてのコンテンツを人力・目視でチェックす る場合、月間70〜140時間要する(推定) AIに自動チェックさせることで上記工数をほとんど削減できたこ とになる
今後の展望 プロンプトのさらなる最適化 モデル選定の定期的な見直し 本事例を学びとして他の側面へのLLM応用の余地を検討 コンテンツ執筆の品質向上サポート ユーザー体験の改善
まとめ LLMを活用してスパム投稿自動検出の仕組みを構築した 🤖 ユーザーと運営双方の負担を軽減できた 🎉 継続的に改善しつつ別の応用機会を探っていく 💪
最後に宣伝 📢
None
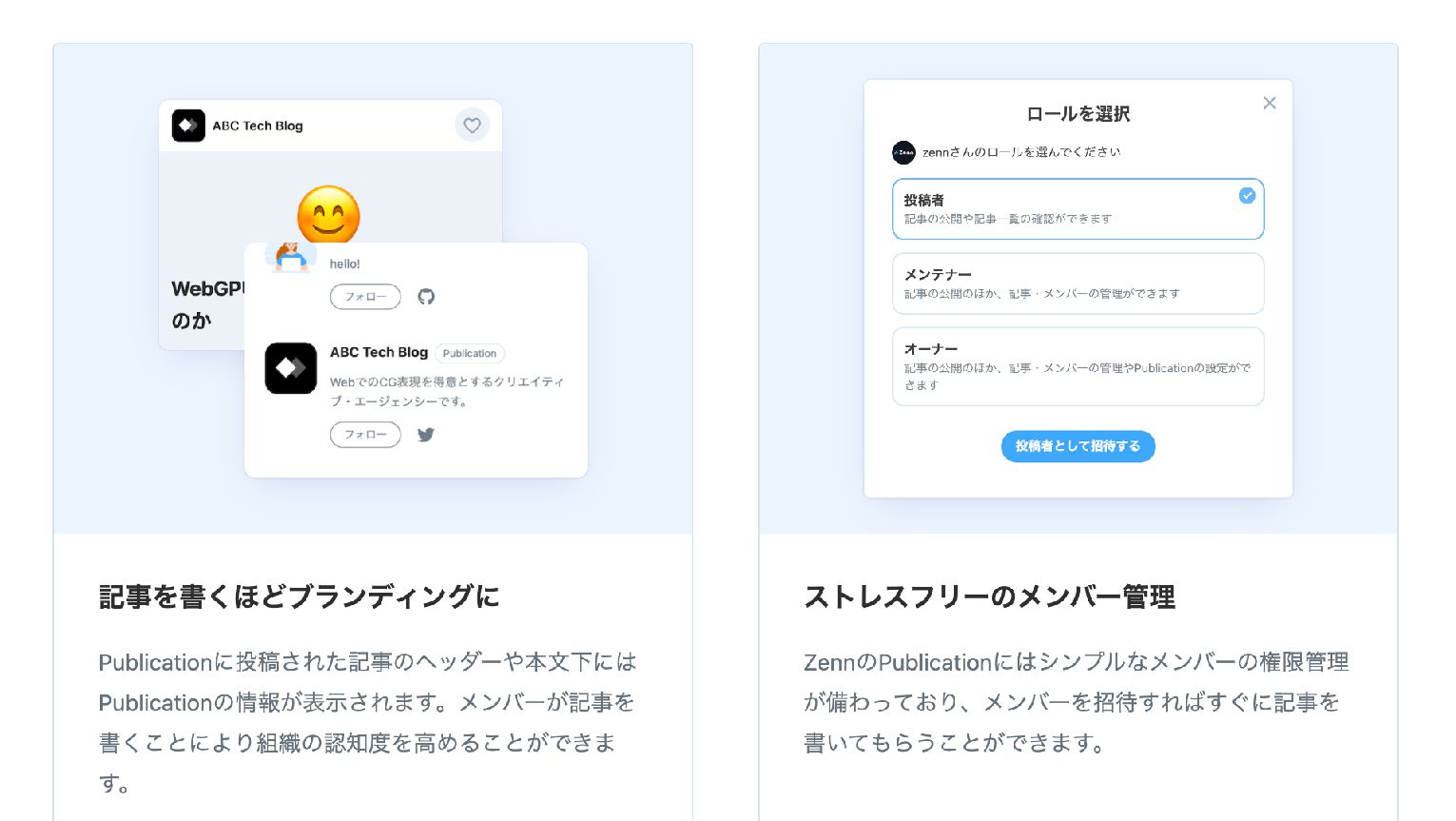
最後に宣伝 ZennのPublication機能をご利用いただくと、企業や組織の単位でテ ックメディアを立ち上げられます
None
None
None
ご清聴ありがとうございました 質問・フィードバックよろしくお願いします 🙏
参考 https://cloud.google.com/vertex-ai/generative-ai/pricing?hl=ja https://ai.google.dev/gemini-api/docs/quickstart?hl=ja https://console.cloud.google.com/vertex- ai/publishers/anthropic/model-garden/claude-3-haiku https://ai.google.dev/gemini-api/docs/json-mode https://docs.anthropic.com/ja/docs/control-output-format https://ai.google.dev/gemini-api/docs/caching
参考 https://cloud.google.com/vertex-ai/generative- ai/docs/multimodal/batch-prediction-gemini
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RubyからGeminiを利用する Geminiを呼び出すコード credentials = Google::Auth.get_application_default access_token = credentials.fetch_access_token!["access_token"] uri =](https://files.speakerdeck.com/presentations/a5b82619fdac4ea5ad5881110756af73/slide_53.jpg){kind=link}
![RubyからGeminiを利用する ちなみにClaudeだとこんなコード request["Authorization"] = "Bearer #{access_token}" request["Content-Type"] = "application/json" request.body](https://files.speakerdeck.com/presentations/a5b82619fdac4ea5ad5881110756af73/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}