Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
OSSコミットしてZennの課題を解決した話
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
dyoshikawa
July 21, 2024
Technology
700
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
OSSコミットしてZennの課題を解決した話
dyoshikawa
July 21, 2024
More Decks by dyoshikawa
See All by dyoshikawa
エンジニア向けコミュニティZennの開発チームを支える自動化の仕組み.pdf
dyoshikawa1993
0
2.6k
生PHPで学ぶSSRF.pdf
dyoshikawa1993
0
190
Zennへのスパム投稿が急増したのでLLMでなんとかした話
dyoshikawa1993
0
1.5k
Google Cloud Vertex AIにおけるGemini vs Claude
dyoshikawa1993
0
240
Other Decks in Technology
See All in Technology
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
970
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
350
公式ドキュメントの歩き方etc
coco_se
1
120
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
260
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
690
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
0
230
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
0
230
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
320
Making sense of Google’s agentic dev tools
glaforge
1
300
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
11
4.1k
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
270
タスクの複雑さでモデルを選ぶ ── Thompson Samplingで動かす“トークン/コスト最適化
satohy0323
0
600
Featured
See All Featured
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
330
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
400
A Tale of Four Properties
chriscoyier
163
24k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
The Spectacular Lies of Maps
axbom
PRO
1
860
Between Models and Reality
mayunak
4
380
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Transcript
OSSコミットして Zennの課題を解決した話 2024.7.18 新規事業部Zennチーム dyoshikawa
2020年10月入社(今年で4年目) 2023年よりZennチーム バックエンドエンジニア ZennではRuby on Rails開発 Webフロントエンド(React|Next)も触ります 自己紹介
https://zenn.dev/ エンジニアのための情報共有コミュニティサービス 2023年12月に会員数10万|月間PV数1000万突破を発表 🎉 Zennについて
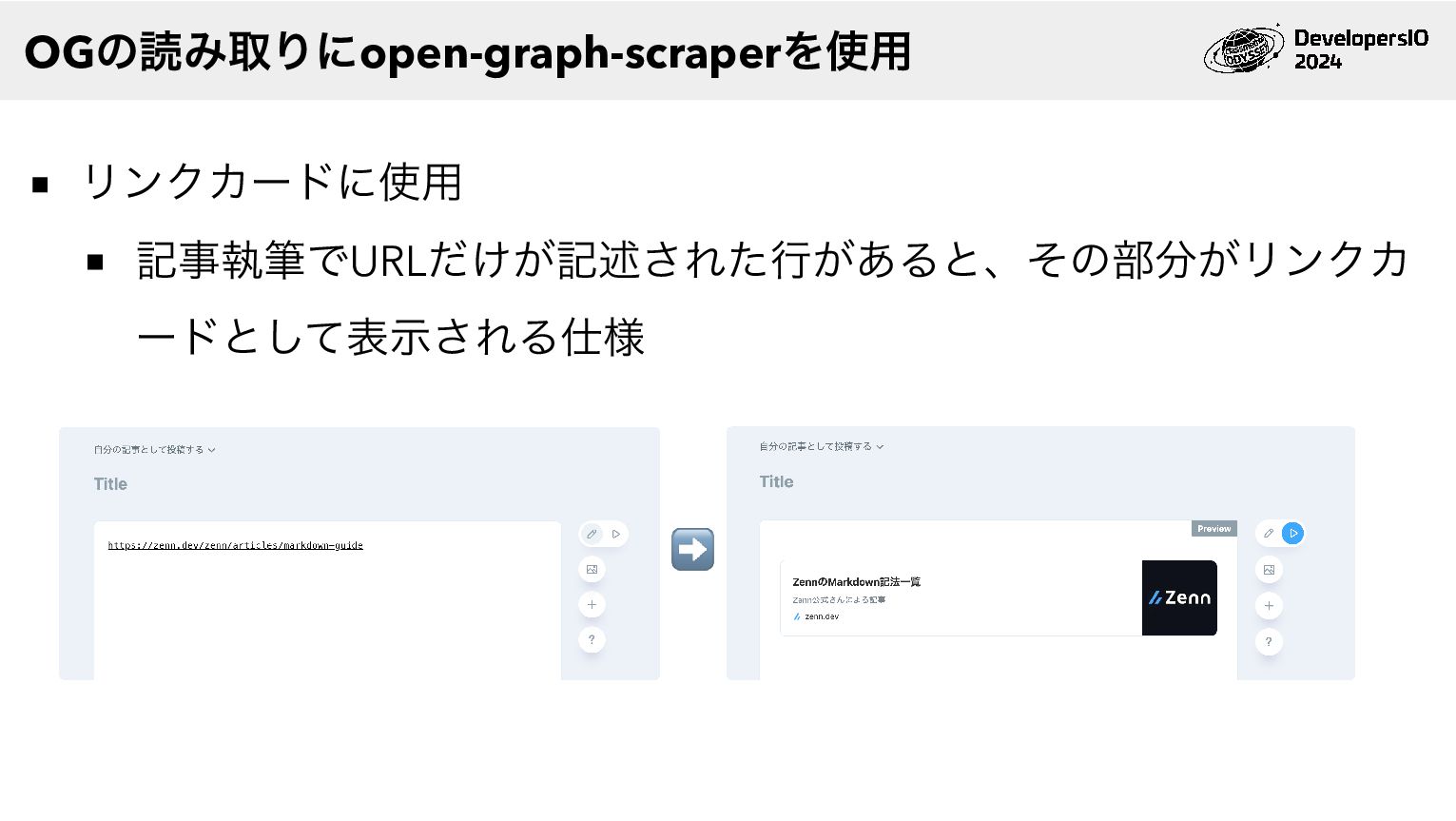
Zennではopen-graph-scraperというnpmパッケージを使っています https://github.com/jshemas/openGraphScraper Open Graph(OG)情報の読み取りを良い感じにやってくれる Open Graph protocol 今回はこのopen-graph-scraperの話 OGの読み取りにopen-graph-scraperを使用
リンクカードに使用 記事執筆でURLだけが記述された行があると、その部分がリンクカ ードとして表示される仕様 ➡️ OGの読み取りにopen-graph-scraperを使用
使い方の例 import ogs from "open-graph-scraper"; (async () => { const
data = await ogs({ url: "https://classmethod.jp/", }); console.log(JSON.stringify(data.result, null, 2)); })(); OGの読み取りにopen-graph-scraperを使用
クラスメソッドコーポレートサイトを読み取るとこんな感じ https://classmethod.jp/ { "success": true, "ogLocale": "ja_JP", "ogSiteName": "クラスメソッド株式会社", "ogType":
"article", "ogTitle": "クラスメソッド株式会社", "ogDescription": "クラスメソッドはクラウド、デジタル化、データの3つの分野を掛けあわせて、お客様のビジネス成長に向けた技術支援を行います。2022年に "以下省略": "..." } OGの読み取りにopen-graph-scraperを使用
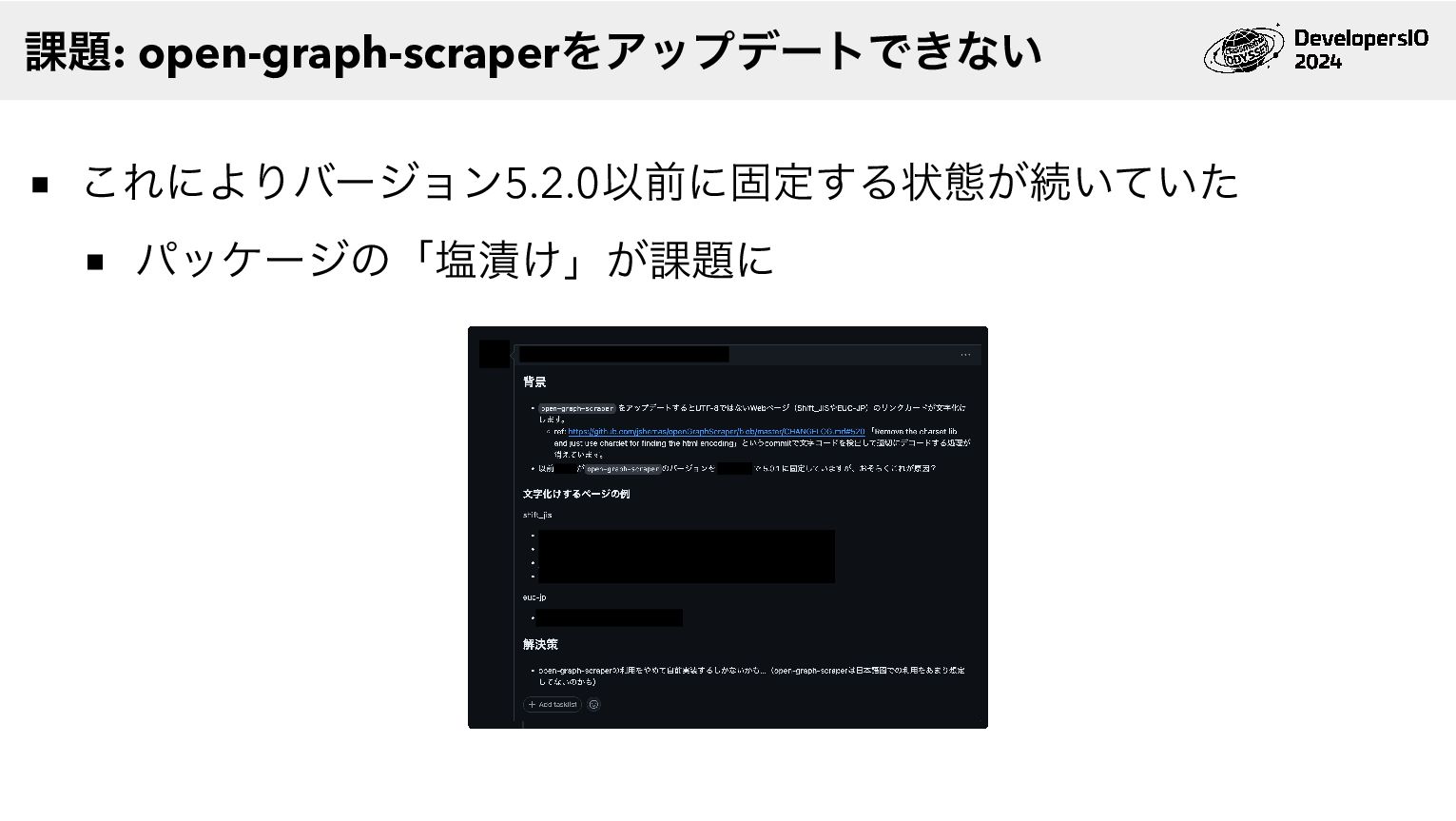
v5.2.0より文字コードごとのデコード処理がなくなり、アップデート するとUTF-8でないサイトで問題が発生するようになった Shift_JISやEUC-JPなどのWebページをopen-graph-scraperで読み 取ると結果が文字化けしてしまう 課題: open-graph-scraperをアップデートできない
これによりバージョン5.2.0以前に固定する状態が続いていた パッケージの「塩漬け」が課題に 課題: open-graph-scraperをアップデートできない
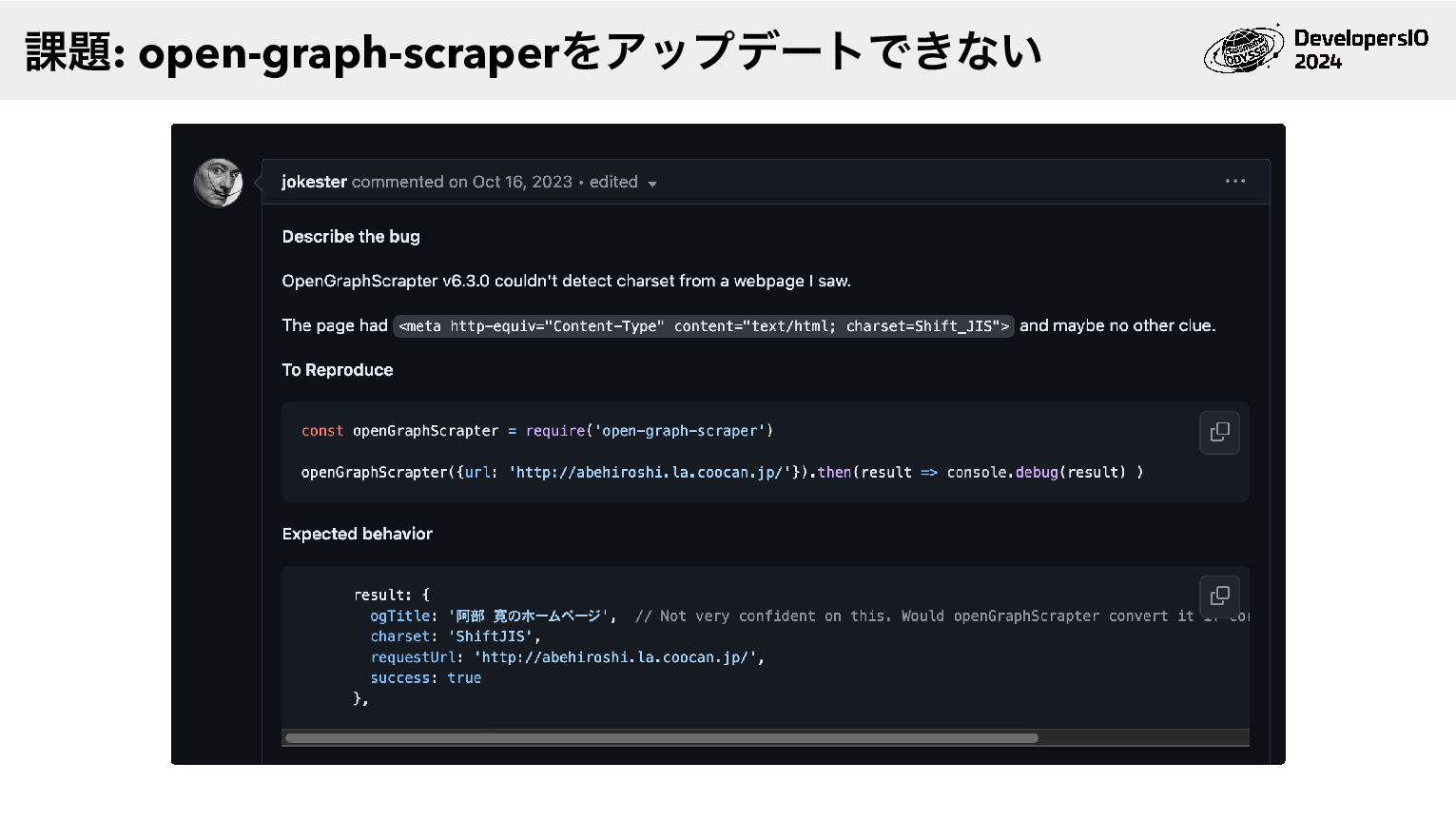
同じ問題がopenGraphScraperリポジトリのIssueに起票されていた 課題: open-graph-scraperをアップデートできない
課題: open-graph-scraperをアップデートできない
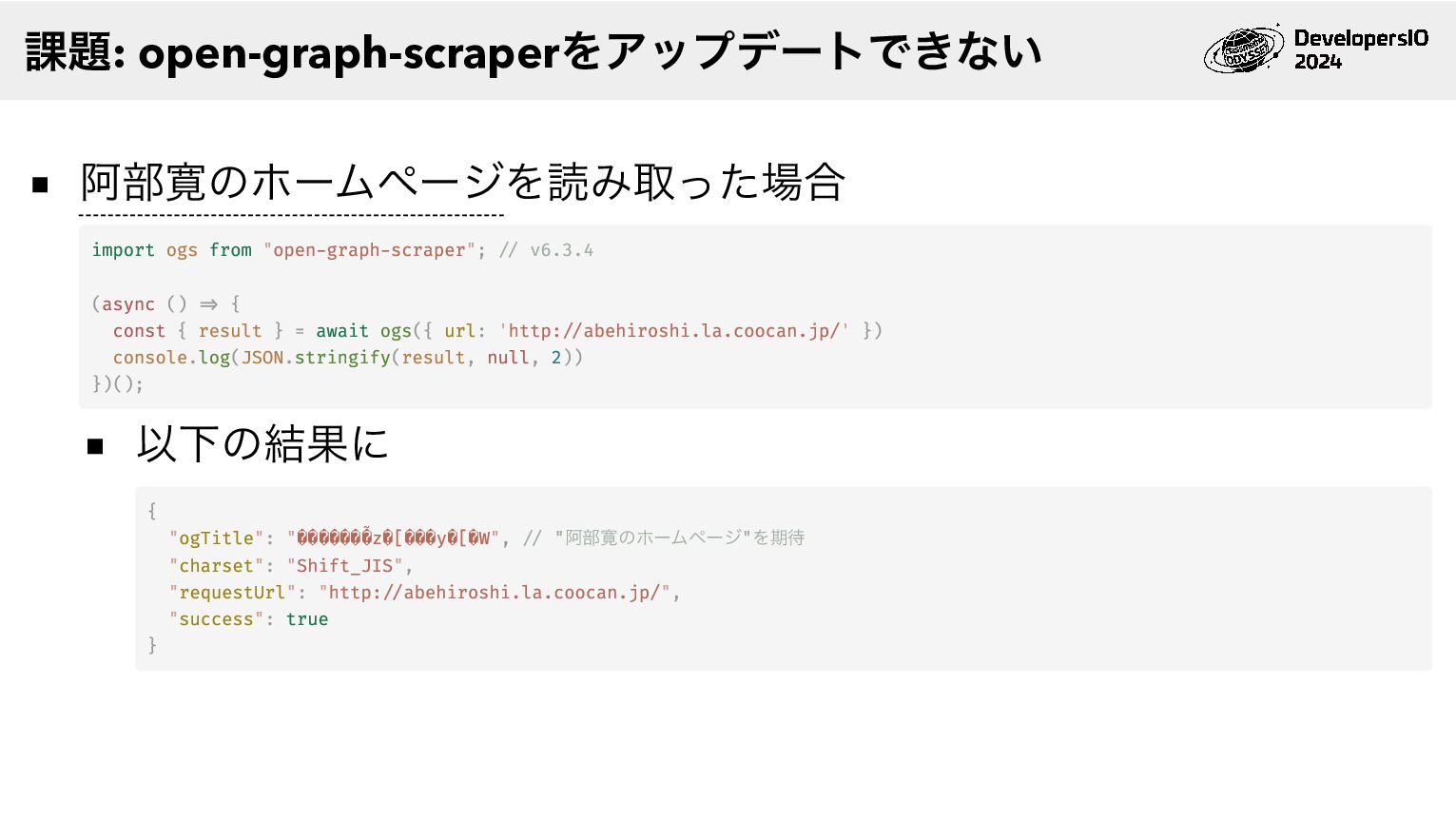
Shift_JIS Webページの例として阿部寛のホームページが取り上げられ ている 本発表でも例として使わせていただきます 🙏 課題: open-graph-scraperをアップデートできない
阿部寛のホームページを読み取った場合 import ogs from "open-graph-scraper"; // v6.3.4 (async () =>
{ const { result } = await ogs({ url: 'http://abehiroshi.la.coocan.jp/' }) console.log(JSON.stringify(result, null, 2)) })(); 以下の結果に { "ogTitle": "�������̃z�[���y�[�W", // "阿部寛のホームページ"を期待 "charset": "Shift_JIS", "requestUrl": "http://abehiroshi.la.coocan.jp/", "success": true } 課題: open-graph-scraperをアップデートできない
阿部寛のホームページ が �������̃z�[���y�[�W に文字化け なんかこう、うまくゴニョゴニョして �������̃z�[���y�[�W から復元 できたりしないものなの・・・? ここで文字化けがどのように起きるかをみてみる 文字化け部分を修復して使えないの?
最初の2文字 阿部 を例に まずはUTF-8の 阿部 をShift_JISとしてデコードするとどう文字化けす るか?をみる UTF-8の 阿部 のバイト列は
e998bfe983a8 阿 e998bf 部 e983a8 例1: UTF-8の文字列をShift_JISでデコードする場合
e998bfe983a8 をShift_JISでデコードすることを考える Shift_JISの定義表を見ながらバイト列を再解釈して文字を置換する JIS X 0208コード表 - CyberLibrarian 例1: UTF-8の文字列をShift_JISでデコードする場合
すると 阿部 は 髦ソ驛ィ になる これが文字化け! ➡️ 例1: UTF-8の文字列をShift_JISでデコードする場合 阿
e998bf 部 e983a8 UTF-8 髦 e998 ソ bf 驛 e983 ィ a8 Shift_JIS
e998bfe983a8 というバイト列はそのまま残っていることに注目 そのため、これをUTF-8に再度デコードすると 阿部 を復元できる ➡️ 髦ソ驛ィ は 阿部 に復元できる
髦 e998 ソ bf 驛 e983 ィ a8 Shift_JIS 阿 e998bf 部 e983a8 UTF-8
今度は逆にShift_JISからUTF-8にデコード 今回の問題はこっち Shift_JISの 阿部 はバイト列にすると 88a29594 になる 阿 88a2 部
9594 例2: Shift_JISの文字列をUTF-8でデコードする場合
88a29594 をUTF-8でデコードすることを考える ところが・・・?このバイト列に対してUTF-8の定義表から対応させ られる文字がない 例2: Shift_JISの文字列をUTF-8でデコードする場合
そういう場合はREPLACEMENT CHARACTER( � )の出番になる 実際手元で試すと 阿部 は ���� になった 88a29594
は4バイトなので、1バイト区切りで ���� になったと思 われる(デコーダの実装によりそう) ➡️ 例2: Shift_JISの文字列をUTF-8でデコードする場合 阿 88a2 部 9594 Shift_JIS � efbfbd � efbfbd � efbfbd � efbfbd UTF-8
バイト列が efbfbdefbfbdefbfbdefbfbd になってしまい、元の値 88a29594 を保持できていないことに注目 そのためREPLACEMENT CHARACTERに置換されてしまった場合は元 の文字列に戻すことは困難(おそらくできない) REPLACEMENT CHARACTERは復元が困難
🤔「 阿部寛のホームページ の文字化け後の �������̃z�[���y�[�W には � じゃない文字も含まれてるけど?」 ちなみに: 文字化けに �
でない文字がある件
Shift_JISにおいて 阿部寛のホームページ のバイト列は 88a295948ab082cc837a815b83808379815b8357 になる 一部UTF-8としてデコードできる文字がある ちなみに: 文字化けに � でない文字がある件
������� 88a295948ab082 ~ cc83 z 7a � 81 [ 5b �� 838083 y 79 � 81 [ 5b � 83 W 57 UTF-8
UTF-8での cc83 Unicodeでは U+0303 のチルダ ~ はCOMBINED TILDEといって、他の文字と組み合わせて使うものらしい REPLACEMENT CHARACTER
� と組み合わさって �̃ になる 発音表記などで使われる ちなみに: 文字化けに � でない文字がある件
話を戻して・・・ 解決するため、OSSコントリビューションすることに 解決策: OSSコントリビューションする
理由 自前で実装し直すよりライブラリにパッチを当てた方が工数がかか らない open-graph-scraperを使い続けることで、本OSSの今後のエンハン スの利益を受け続けることができる 他の非英語圏ユーザにも役に立つと思った 幸い、活発に開発が続いている状況だったので、プルリクエストが受 け入れられる可能性は高いと思った 解決策: OSSコントリビューションする
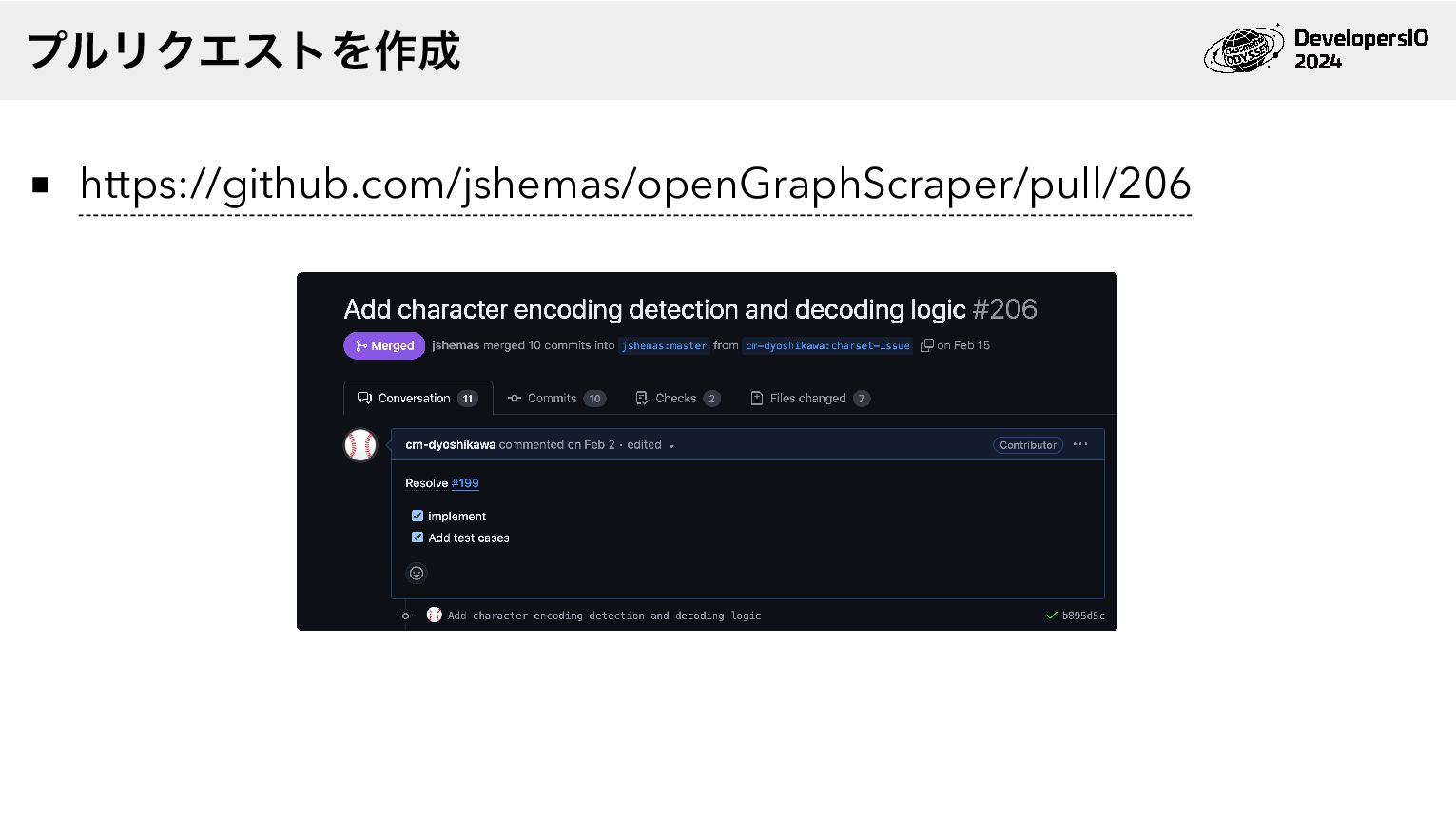
https://github.com/jshemas/openGraphScraper/pull/206 プルリクエストを作成
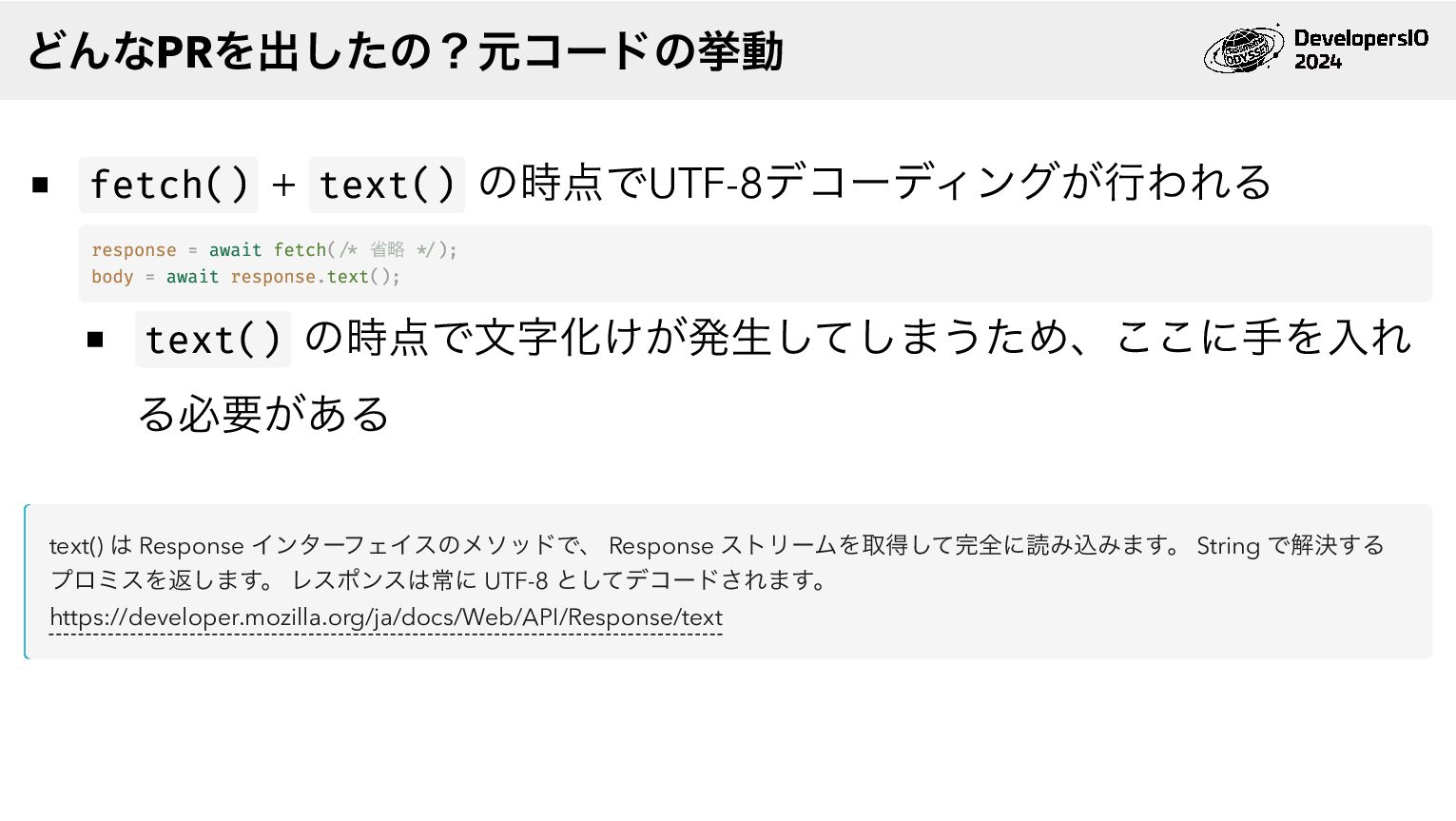
fetch() + text() の時点でUTF-8デコーディングが行われる response = await fetch(/* 省略 */);
body = await response.text(); text() の時点で文字化けが発生してしまうため、ここに手を入れ る必要がある text() は Response インターフェイスのメソッドで、 Response ストリームを取得して完全に読み込みます。 String で解決する プロミスを返します。 レスポンスは常に UTF-8 としてデコードされます。 https://developer.mozilla.org/ja/docs/Web/API/Response/text どんなPRを出したの?元コードの挙動
一応、ミニマムなコードで動作を確認してみる (async () => { const response = await fetch("http://abehiroshi.la.coocan.jp/");
const body = await response.text(); // 243文字目が<title />の中身の `�` にあたる console.log(body[243], dummy.charCodeAt(243).toString(16)); // � fffd })(); dummy.charCodeAt(243) の結果(Code Unit)が fffd であり、こ れはUTF-16における � のバイト列である Node.jsは内部的にUTF-16を採用している つまり、やはり元のバイト列は残っておらず復元は困難である どんなPRを出したの?元コードの挙動
text() ではなく arrayBuffer() を使うことでデコード前のバイト 列を取得し、 bodyArrayBuffer 変数で保持しておく bodyArrayBuffer を保持したままUTF-8デコードを行い、 <meta
charset="{charset}" /> を取得するなどして文字コードを特定する 特定した文字コードで bodyArrayBuffer をデコードする const bodyArrayBuffer = await response.arrayBuffer(); const bodyText = Buffer.from(bodyArrayBuffer).toString('utf-8'); const charset = getCharset(bodyText, bodyArrayBuffer, load(bodyText)); if (charset.toLowerCase() === 'utf-8') { body = bodyText; } else { body = decode(Buffer.from(bodyArrayBuffer), charset); } どんなPRを出したの?こう変更した
いろいろとやりとりや確認待ちもあり、2週間ほどかかったがマージさ れる ほどなくして本プルリクエストの変更内容を取り込んだv6.4.0もリリ ースされる 動作確認し文字化け問題が直っていることを確認 Zennにも最新版を適用しリリースできた 付き合っていただいたメンテナに感謝 🎉 結果: 無事マージされる
🎉
リンクカードの実装にはopen-graph-scraperを使うと楽 文字化けは復元できる場合と困難な場合がある 「OSSを乗り換える」 「OSSを使うのをやめる」の他に「OSSに貢献す る」の選択肢を持ってみると良さそう まとめ
本日のお話は下記にもう少し詳しく書いています OSSにコミットしてサービスの課題を解決した話 文字コード入門 文字化けはなぜ起こるのか?どういう時に復元できるのか? ブログ記事
筆者は文字コードや符号化方式の専門家ではないため、勉強しながら 本課題に取り組みました 理解が間違っている箇所があればご指摘ください 🙏 ここまでお聞きいただきありがとうございました さいごに
特殊用途文字 (Unicodeのブロック) - Wikipedia とほほの文字コード入門 - とほほのWWW入門 UTF-8 - Wikipedia
JIS X 0208コード表 - CyberLibrarian 文字列とUnicode · JavaScript Primer #jsprimer JavaScript における文字コードの初歩 - 30歳からのプログラミング (プログラマのための)いまさら聞けない標準規格の話 第2回 文字コー ド実践編 | オブジェクトの広場 参考
XML用語事典 [シフトJIS(Shift_JIS) ] Shift_JIS 文字コード表 特殊用途文字 (Unicodeのブロック) - Wikipedia 合成可能なダイアクリティカルマーク
- Wikipedia ability to validate UTF-8 encoding · Issue #83 · ashtuchkin/iconv-lite 参考
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![XML用語事典 [シフトJIS(Shift_JIS) ] Shift_JIS 文字コード表 特殊用途文字 (Unicodeのブロック) - Wikipedia 合成可能なダイアクリティカルマーク](https://files.speakerdeck.com/presentations/eeef3c7eb2314a15a492725e1c416f07/slide_36.jpg){kind=link}