(i = 1, . . . , n) • ϕ : Rd × W → [−1, 1]: feature map • Q: probability measure(distribution) on W • We only consider the following kernel: positive-semidefinite, continuous, shift-invariant and properly-scaled KQ (x, x′) = ∫ ϕ(x, w)ϕ(x′, w)dQ(w) (3) 10 / 24
KQ over all distribution in some large set P of possible distributions on random features. max Q∈P ∑ i,j KQ (xi, xj)yiyj (= ⟨KQ , yy⊤⟩F ) (4) • Alignment: like cosine similality of matrix (uses Frobenius norm) A(K1 , K2 ) = ⟨K1 , K2 ⟩F √ ⟨K1 , K1 ⟩F ⟨K2 , K2 ⟩F (5) 11 / 24
on the space of probability distributions: for user-defined P0 and f-fivergence, P := {Q : Df (Q||P0 ) = ∫ f ( dQ dP0 ) dP0 ≤ ρ}, ρ > 0. (6) • For wi iid ∼ P0 , i ∈ [Nw ], define the discrete approximation of P: PNw := {q : Df (q||1/Nw ) ≤ ρ} (7) • empirical version of alignment maximization (4): max q∈PNw ∑ i,j yiyj Nw ∑ m=1 qm ϕ(xi, wm)ϕ(xj, wm) (8) RFF feature map • (8): find weights ˆ q that describe the underlying dataset well 12 / 24
the paper. (Alignment) Consistency • When n → ∞ and Nw → ∞ respectively, is alignment provided by the estimated distribution ˆ q nearly optimal? ˠ Yes!! Generalization peformance • Show the risk bound of (14) estimator. • Tools: consistency result + [Cortes2010] 16 / 24
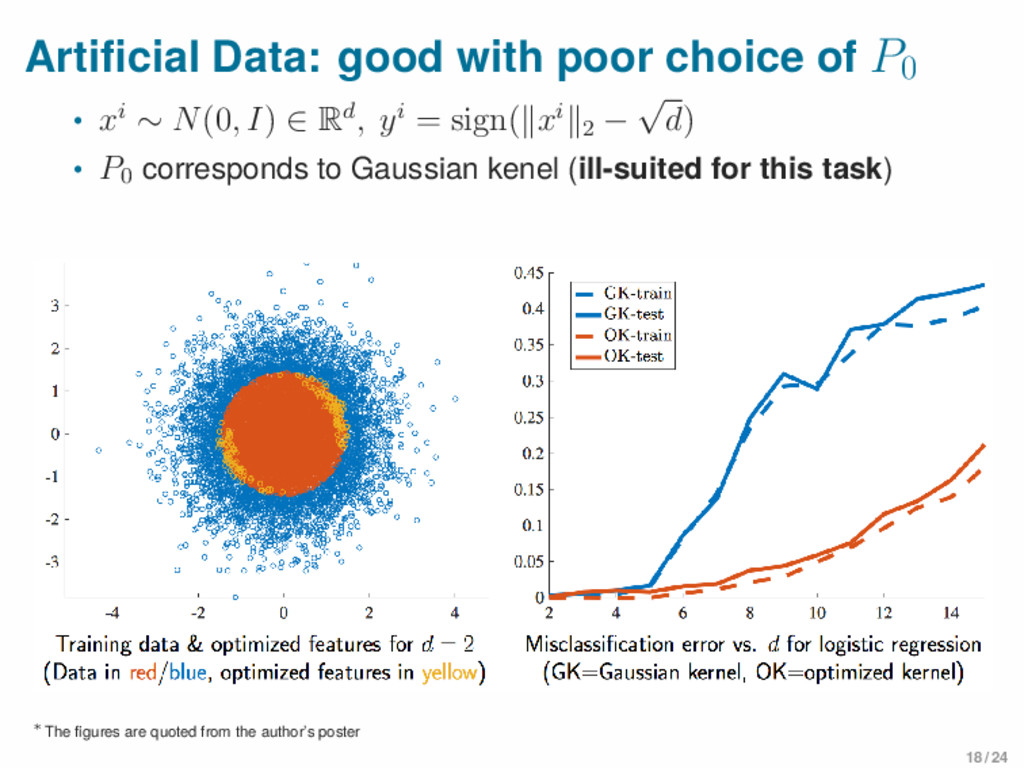
∼ N(0, I) ∈ Rd, yi = sign(∥xi∥2 − √ d) • P0 corresponds to Gaussian kenel (ill-suited for this task) ∗The figures are quoted from the author’s poster 18 / 24
fast kernel-learning optimization procedure • Show that optimization procedure is consistent, and proposed estimator generalizes well • Emprirical results indicate we learn new structure, and we attain competitive results faster than other methods Thank you for linstening! 21 / 24
V Le et al. “Fastfood - Computing Hilbert Space Expansions in loglinear time”. In: Proceedings of the 30th International Conference on Machine Learning. 2013. [Rahimi2007] Ali Rahimi et al. “Random Features for Large-Scale Kernel Machines”. In: Advances in Neural Information Processing Systems 20. 2007. [Rahimi2008] Ali Rahimi et al. “Weighted sums of random kitchen sinks: Replacing minimization with randomization in learning”. In: Advances in Neural Information Processing Systems 21. 2008. [Sinha2016] Aman Sinha et al. “Learning Kernels with Random Features”. In: Advances in Neural Information Processing Systems 29. 2016. [Sriperumbudur2015] Bharath K. Sriperumbudur et al. “Optimal Rates for Random Fourier Features”. In: Advances in Neural Information Processing Systems 28. 2015. [Sutherland2015] Dougal J Sutherland et al. “On the Error of Random Fourier Features”. In: Uncertainty in Artificial Intelligence. 2015. 22 / 24
Random Fourier Features: A Theoretical and Empirical Comparison”. In: Advances in Neural Information Processing Systems. 2012. [Yu2016] Felix X. Yu et al. “Orthogonal Random Features”. In: Advances In Neural Information Processing Systems 29. 2016. • Lelated to fast kernel machine: [Achlioptas2001] Dimitris Achlioptas et al. “Sampling Techniques for Kernel Methods”. In: Advances in Neural Information Processing Systems 14. 2001. [Dai2014] Bo Dai et al. “Scalable Kernel Methods via Doubly Stochastic Gradients”. In: Advances in Neural Information Processing Systems 27. Curran Associates, Inc., 2014, pp. 3041–3049. [Drineas2005] Petros Drineas et al. “On the Nyström Method for Approximating a Gram Matrix for Improved Kernel-Based Learning”. In: Journal of Machine Learning Research 6.12 (2005), pp. 2153–2175. [Williams2000] Christopher K. I. Williams et al. “Using the Nyström Method to Speed Up Kernel Machines”. In: Advances in Neural Information Processing Systems 13. 2000. 23 / 24
Bounds for Learning Kernels”. In: Proceedings of the 27th International Conference on Machine Learning. 2010. [Cristianini2001] Nello Cristianini et al. “On kernel-target alignment”. In: Advances in Neural Information Processing Systems 14. 2001. [Duchi2008] John Duchi et al. “Efficient projections onto the l1-ball for learning in high dimensions”. In: Proceedings of the 25th International Conference on Machine Learning. 2008. [Gönen2011] Mehmet Gönen et al. “Multiple Kernel Learning Algorithms”. In: Journal of Machine Learning Research 12 (2011), pp. 2211–2268. 24 / 24
{kind=link}
![Overview Random Fourier Features(RFF) [Rahimi2007]: Fast Kernel Method • Approximate](https://files.speakerdeck.com/presentations/58ad3c5fb91e4940b6e679ed24379706/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![History of RFF Proposed: [Rahimi2007] • Generalization: [Rahimi2008] • Acceleration](https://files.speakerdeck.com/presentations/58ad3c5fb91e4940b6e679ed24379706/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Benchmark Datasets: Scalability • vs joint optimizaiton[Gönen2011] (n=5000) ∗The tables](https://files.speakerdeck.com/presentations/58ad3c5fb91e4940b6e679ed24379706/slide_19.jpg){kind=link}
{kind=link}
![Reference I • Lelated to random Fourier features: [Le2013] Quoc](https://files.speakerdeck.com/presentations/58ad3c5fb91e4940b6e679ed24379706/slide_21.jpg){kind=link}
![Reference II [Yang2012] Tianbao Yang et al. “Nystrom Method vs](https://files.speakerdeck.com/presentations/58ad3c5fb91e4940b6e679ed24379706/slide_22.jpg){kind=link}
![Reference III • Other [Cortes2010] Corinna Cortes et al. “Generalization](https://files.speakerdeck.com/presentations/58ad3c5fb91e4940b6e679ed24379706/slide_23.jpg){kind=link}