in mid 2013 - We started to use Spark mainly because of its usability and being a good match to our data set sizes allowing to take full advantage of all its speed - Mesos was the logical best way to run Spark and Hadoop jobs (and other kind of software) on the same nodes and have dynamic resources sharing
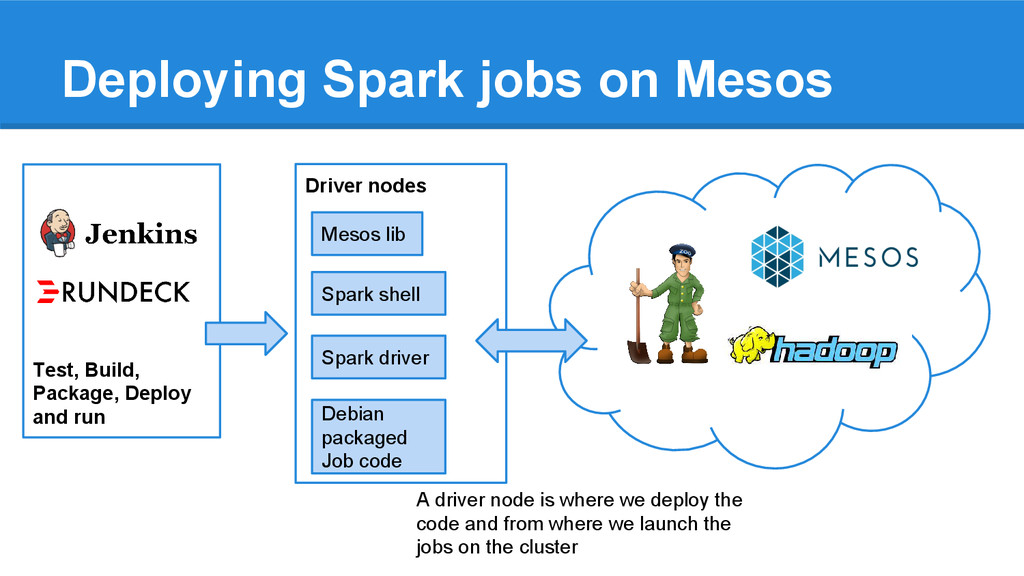
Mesos Driver nodes Mesos lib Spark shell Spark driver Debian packaged Job code A driver node is where we deploy the code and from where we launch the jobs on the cluster
customers that share common characteristics - Examples of segments: gender, industry, working in a big company… - Used to achieve fine grained targeting (ads, new products, understand the customer) - Send IBM Ads to all male customers older than 40 years and working in the IT
to combine them - The segmentation was computed through SQL queries on demand - The raw data needs to be preprocessed (cleaned and computed) - Many segments involve computations on the attributes they use, too expensive on MySQL - No way for non IT employees to have the segmentation
segments on complex data in reasonable time - Make them available to software components and humans (ex: Ad Targeting, AB Testing, BI team) - Expose a service that can answer to segmentation queries in real time * Get live counters & and all the members belonging to a combination of segments * A front-end allowing non IT people to combine segments and query it live
build a real data standardization layer - The business team doing ad-hoc segmentation has “cleaning rules” and knows the MySQL tables - We can’t spend time to change segments definitions - We have conventions The idea: Delegate - Implement the segments definitions as an SQL like DSL doing joins implicitly and taking advantage of the conventions - Let the business team create the segments definitions and define the cleaning rules inside the segment definition
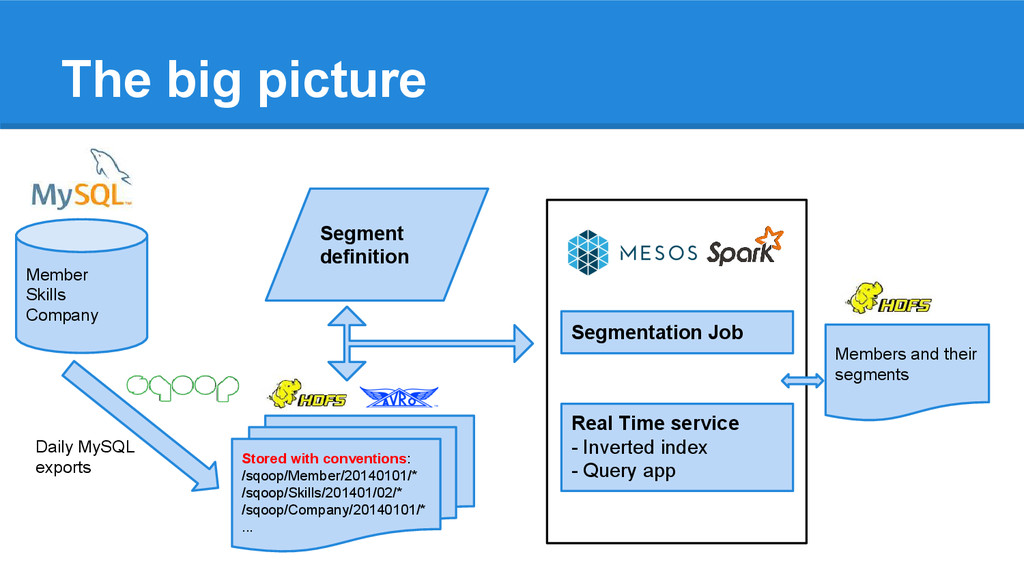
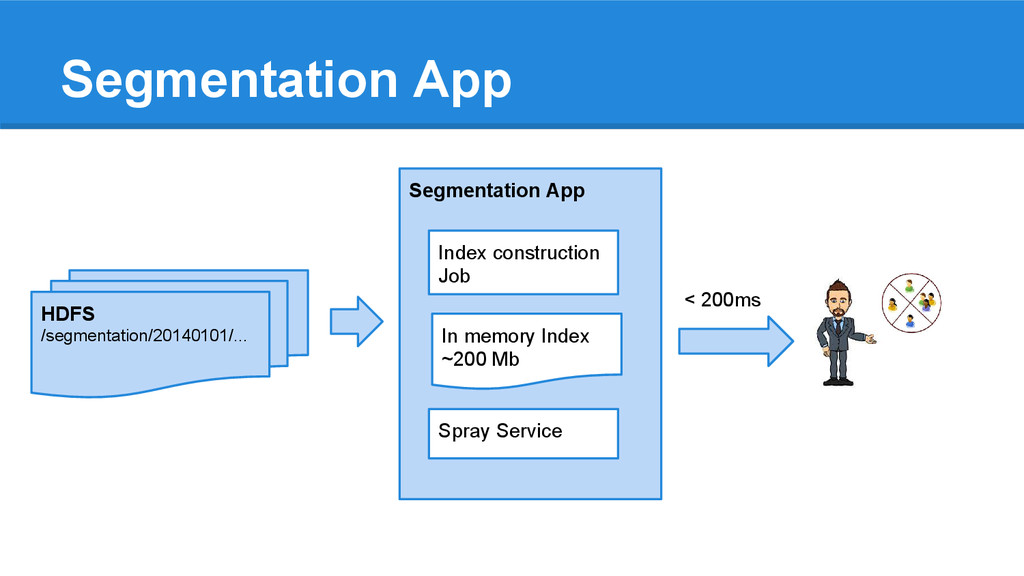
/sqoop/Member/20140101/* /sqoop/Skills/201401/02/* /sqoop/Company/20140101/* ... Members and their segments Real Time service - Inverted index - Query app Member Skills Company Daily MySQL exports
on the data - Doesn’t require the user to write JOINS, we imply it from the primary keys and the column names (remember, conventions) - A segment example: • Define some variables (for ex. patterns you want to see in the data) executiveKeywords: ["Dir.", "Resp.", Directeur, Directrice, Director, Dirigeant, Manager, Responsable, Chef, Chief, Head of] • The segment itself (and reuse available variables) Member.Headline = {executiveKeywords} or Position.StillInPosition=1 and Position.PositionTitle = {executiveKeywords} ...
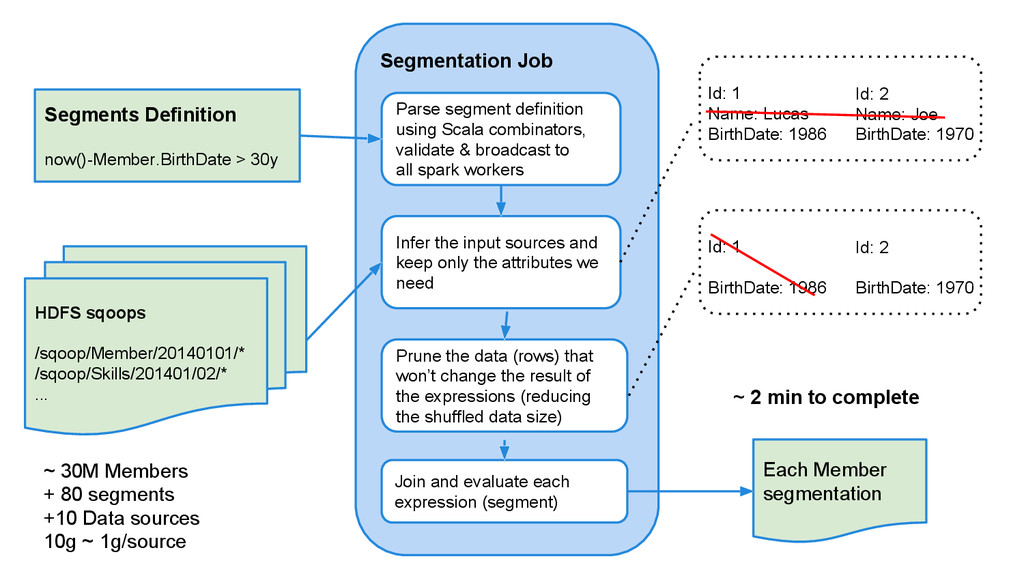
Segmentation Job Parse segment definition using Scala combinators, validate & broadcast to all spark workers Infer the input sources and keep only the attributes we need Prune the data (rows) that won’t change the result of the expressions (reducing the shuffled data size) Join and evaluate each expression (segment) ~ 30M Members + 80 segments +10 Data sources 10g ~ 1g/source Each Member segmentation ~ 2 min to complete Id: 1 Name: Lucas BirthDate: 1986 Id: 2 Name: Joe BirthDate: 1970 Id: 1 BirthDate: 1986 Id: 2 BirthDate: 1970
Elasticsearch and build an app to query it - The most natural one, but at that moment we wanted to test hypotheses and didn’t want to pollute our production Elasticsearch
long running spark job as a service (popular in the Spark community) • In a Spray app launch a spark job and load the data in memory • Submit HTTP requests to the Spray app that will query the in memory RDD - Increases possibility of problems/failures as the service would run 24/24 and would have its data spread across N nodes - Experienced blocking of offered resources by Mesos when running 2+ passive spark shells
using an in memory inverted index + a short spark job • At startup, launch a job that will build the index • Collect it on the driver node & stop the job • Submit HTTP requests to the Spray app that will query the in memory index - The quickest solution (for us) to get something running and collect feedback
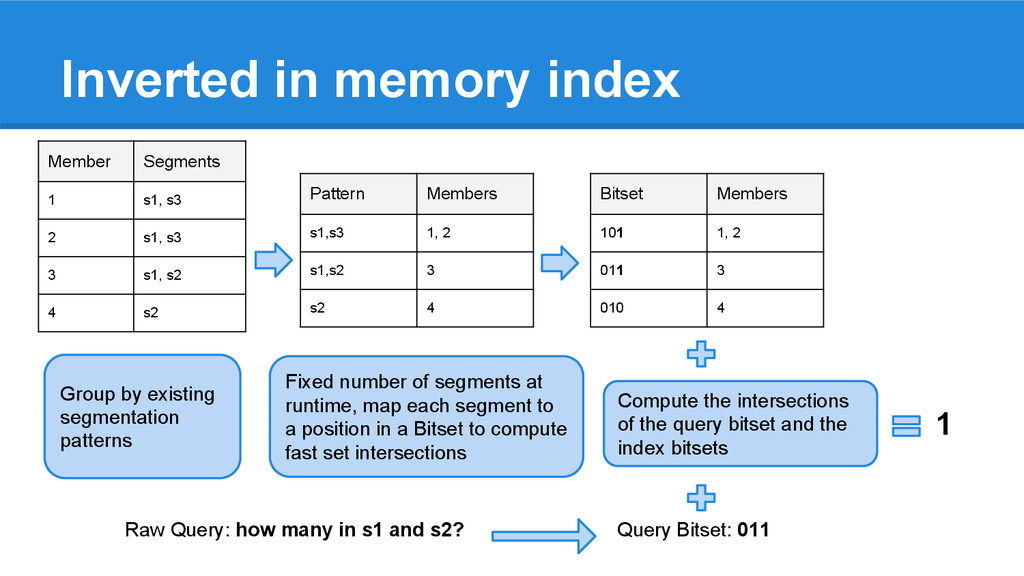
by existing segmentation patterns Member Segments 1 s1, s3 2 s1, s3 3 s1, s2 4 s2 Fixed number of segments at runtime, map each segment to a position in a Bitset to compute fast set intersections Raw Query: how many in s1 and s2? Query Bitset: 011 Compute the intersections of the query bitset and the index bitsets 1 Inverted in memory index Bitset Members 101 1, 2 011 3 010 4
in production for 6 and 3 months, running every day without any trouble, nor requiring an intervention - The computed segmentation is used to display targeted Ads in email campaigns - The Segmentation App, runs 24/24 7/7 and is mainly being used by the sales
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}