Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
GPT_LangChain_LlamaIndexを活用しDB作業の生産性10倍を考える
Search
神谷築
June 12, 2023
Programming
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
GPT_LangChain_LlamaIndexを活用しDB作業の生産性10倍を考える
LangChainとLhamaIndexの簡易解説
ツールを利用しているpythonプログラムの解説
デモ(いい感じに完成していたら紹介します。。。w)
神谷築
June 12, 2023
More Decks by 神谷築
See All by 神谷築
Backlogで開発プロセスを可視化した話
eg_kamiya
0
180
GPTを使って行ったプレスリリースまでのプロセス
eg_kamiya
0
150
Other Decks in Programming
See All in Programming
Skillsは効率化、Agentsは"自分の拡張"——Builder時代のエージェント編成(CC Night 2026)
wemra
1
170
不変条件と整合性境界—ビジネスが決める設計判断と実現パターン / Invariants and Consistency Boundaries
nrslib
14
5.9k
Vite+ Unified Toolchain for the Web
naokihaba
0
370
作って学ぶ、 JSX (TSX) ランタイムの基本
syumai
7
1.7k
AIキャラアプリkaiwaの低遅延音声通話基盤をどう作ったか - AWS Gravitonで支える低遅延・低コストAI Agent基盤
mogamit
0
120
OSもどきOS
arkw
0
600
決定論的オーケストレーションの設計と実装 / Design and Implementation of Deterministic Orchestration
nrslib
4
1.5k
Oxcを導入して開発体験が向上した話
yug1224
4
350
ランチタイムLT会3周年!ランチタイムLT会を3年間続けられたお話
y0hgi
1
120
TypeScript+Orvalで実現する型安全かつ堅牢でスケーラブルなマルチチャネル通知基盤 / TSKaigi Night talks ~after conference~
d0riven
0
370
IBM Bobを活用したレガシーアプリの最新化
oniak3ibm
PRO
1
220
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
0
170
Featured
See All Featured
Writing Fast Ruby
sferik
630
63k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Documentation Writing (for coders)
carmenintech
77
5.4k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Balancing Empowerment & Direction
lara
6
1.2k
My Coaching Mixtape
mlcsv
0
160
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
180
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
190
The SEO Collaboration Effect
kristinabergwall1
1
490
We Are The Robots
honzajavorek
0
260
Being A Developer After 40
akosma
91
590k
Transcript
GPT/LangChain/LlamaIndexを活用しDB 作業の生産性10倍を考える GPT Okinawa
自己紹介 • 〜2011:飲食業 • 2012年:株式会社プロトソリューション • 2018年:株式会社EC-GAIN • 2020年:CTO就任 •
現在 :開発組織構築奮闘中 神谷 築(カミヤ キズク) 1991年:31歳 4人の子持ち お酒/ラーメン大好き
GPT Okinawa Mission GPTを使って開発生産性を10倍にしたい
Slack
今日の流れ - LangChain/LhamaIndex解説 - LT - ディスカッション
GPT の課題 最新情報や独自の情報を持っていない
GPT の課題に対するアプローチ - Fine -tuning - In-Context Learning
Fine-tuning モデル自体にデータを与えて再学習させる方法
In-Context Learning 情報を先に与えておいて、GPTにアプローチする方法
今回の話 In-Context Learning
使うツール LangChain LhamaIndex
LangChainとは LangChainは、GPT-3のような大規模言語モデル( Large Language Model: LLM)を利用してサービスの開発 をしたいときに便利に使えるライブラリです。 例えば、ChatGPT のような AI
とチャットできるサービスを開発する場合を考えます。 OpenAI が提供する GPT-3 の API だけでも非常にシンプルで使いやすいので、 GPT-3 のみを使用した AI チャットサービスを開発 するには LangChain は不要かもしれません。 しかし、例えば、開発したいチャットアプリの要件に、「最新の検 索結果の内容も踏まえて AIに返答をさせたい」といった条件が追加された場合には LangChain が有効です。 LangChain には、「検索エンジンでの検索結果を API で返してくれるサービス」である SerpApi と LLM を組み 合わせる機能があります。 この機能を使うことで、よくある「最新の検索結果の内容も踏まえて AI に返答をさせ たい」という要望を数行のコードで実装できます。 このように、LangChain は LLM を使ってサービスを開発したいときのよくある機能をまとめて提供してくれてい るライブラリです。 引用:https://book.st-hakky.com/docs/langcain-intro/
LangChain要約 GPTを簡単に扱えるようにする 便利なやつ
LhamaIndexとは GPTのようなLLMにプライベートなデータを補強するために、in-context learningという 枠組みがあり、これを行うには データの取り込み インデックス化が必要 ということです。そこで、このデータの取り込み、インデックス化、またそのインデックスを 利用して質問(クエリ)に回答するところまでの機能を一気通貫で提供してくれるのが LlamaIndex、となります。 引用:https://dev.classmethod.jp/articles/llamaindex-overview/
LhamaIndex要約 in-context learning を簡単にできるやつ
プログラムのステップ - テキストを分割 - embeddingとretrieverの作成 - gptの実行
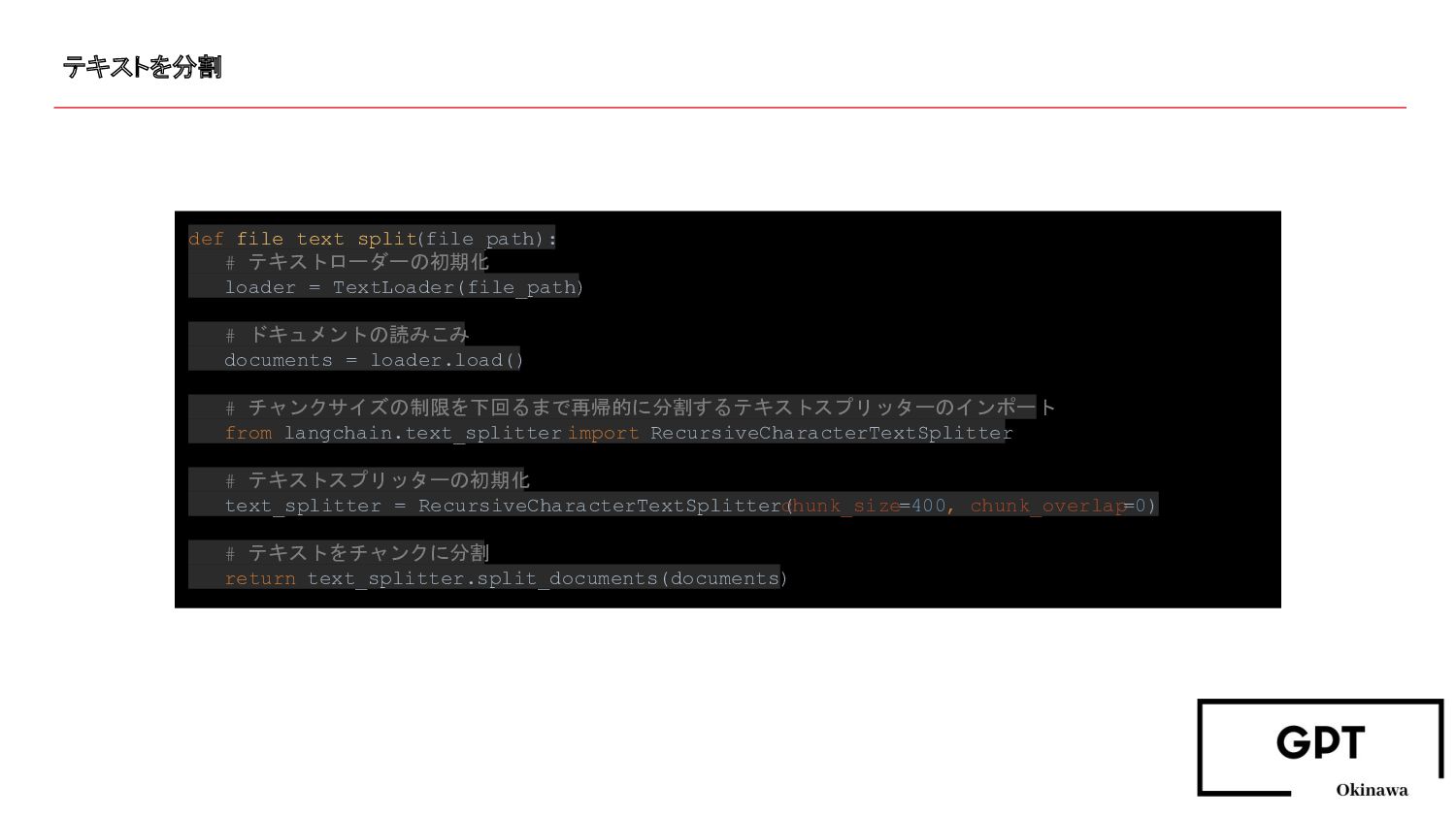
テキストを分割 def file_text_split (file_path): # テキストローダーの初期化 loader = TextLoader(file_path) #
ドキュメントの読みこみ documents = loader.load() # チャンクサイズの制限を下回るまで再帰的に分割するテキストスプリッターのインポート from langchain.text_splitter import RecursiveCharacterTextSplitter # テキストスプリッターの初期化 text_splitter = RecursiveCharacterTextSplitter( chunk_size=400, chunk_overlap=0) # テキストをチャンクに分割 return text_splitter.split_documents(documents)
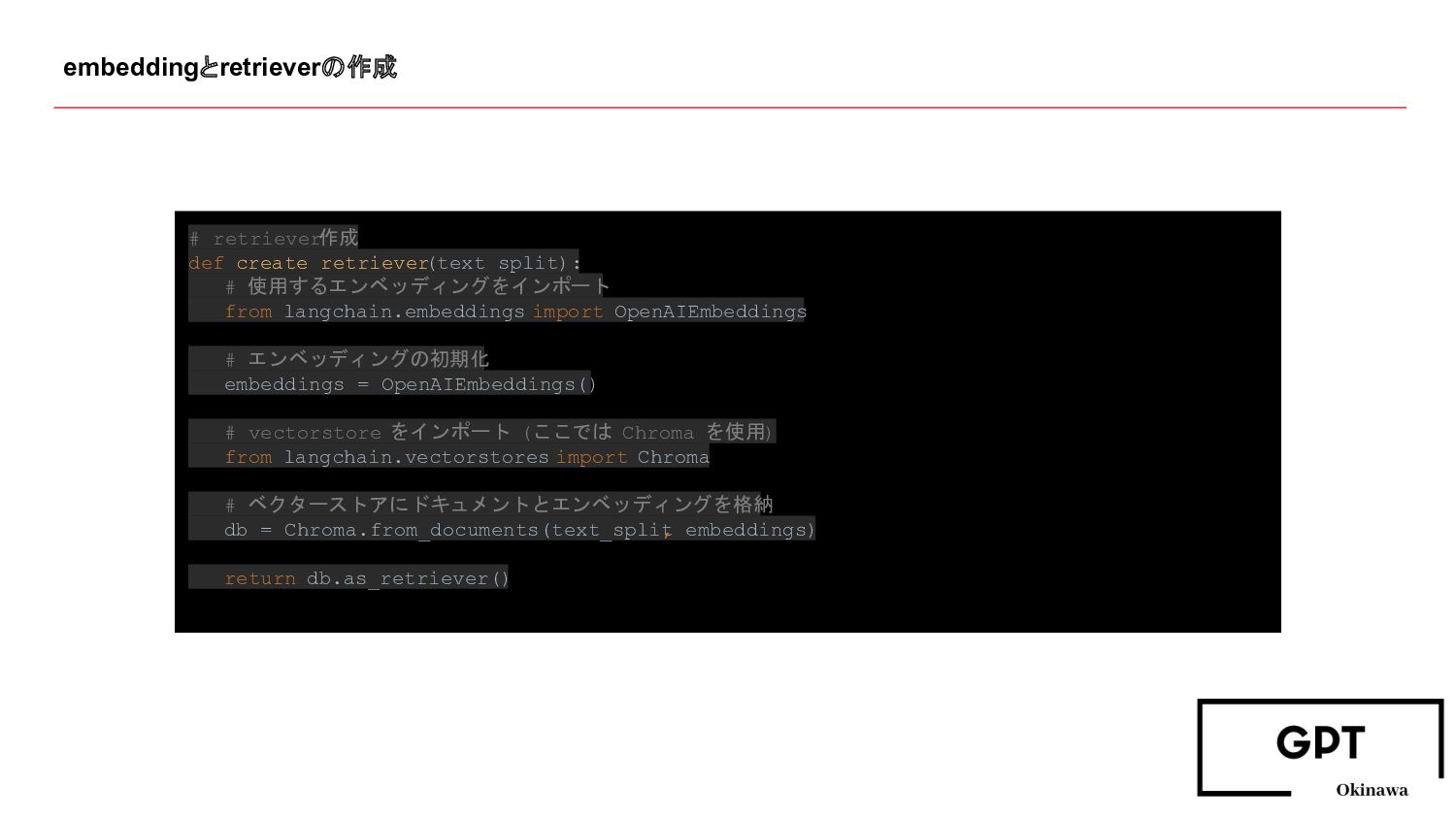
embeddingとretrieverの作成 # retriever作成 def create_retriever (text_split): # 使用するエンベッディングをインポート from langchain.embeddings
import OpenAIEmbeddings # エンベッディングの初期化 embeddings = OpenAIEmbeddings() # vectorstore をインポート (ここでは Chroma を使用) from langchain.vectorstores import Chroma # ベクターストアにドキュメントとエンベッディングを格納 db = Chroma.from_documents(text_split , embeddings) return db.as_retriever()
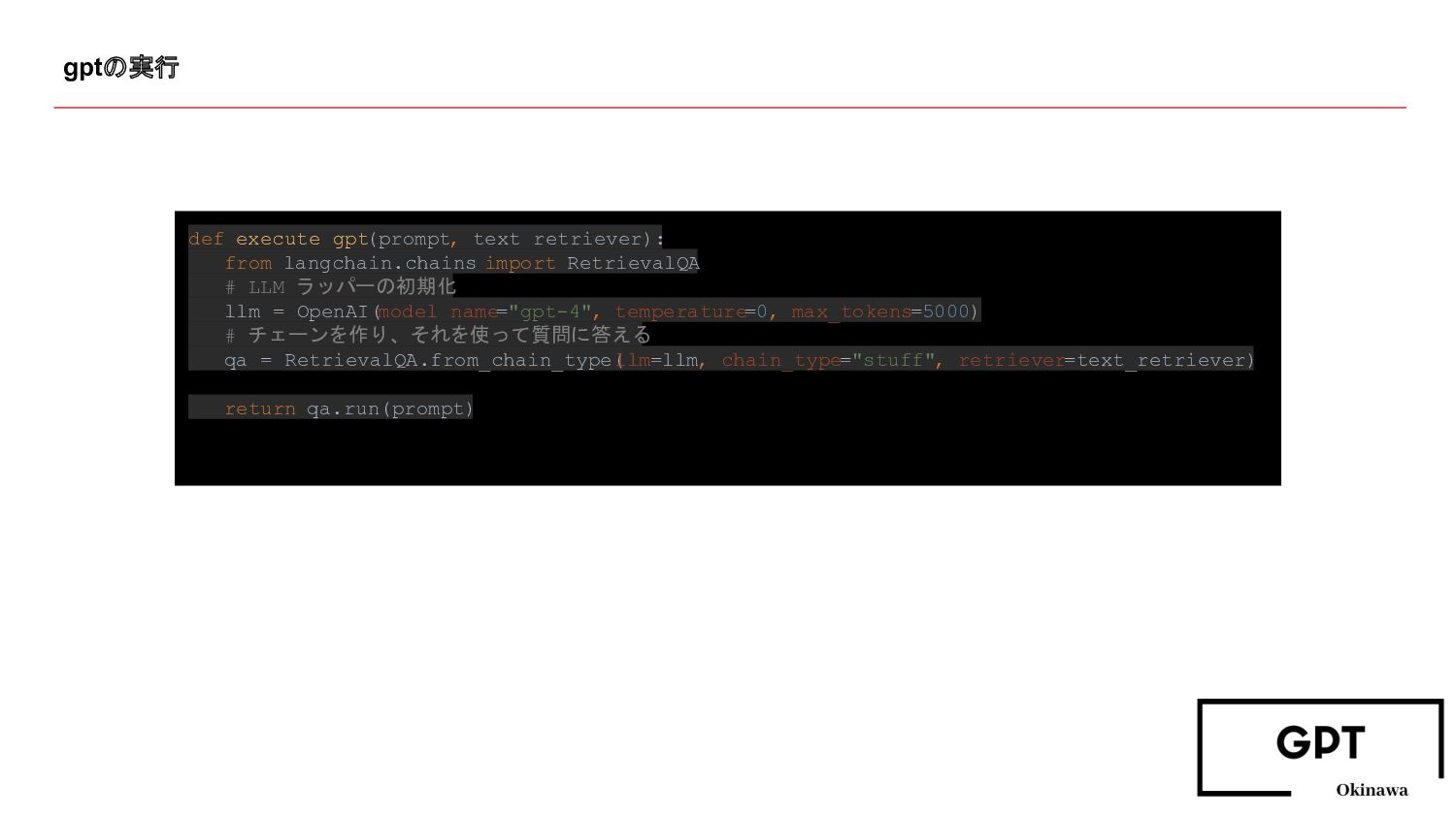
gptの実行 def execute_gpt(prompt, text_retriever): from langchain.chains import RetrievalQA # LLM
ラッパーの初期化 llm = OpenAI(model_name="gpt-4", temperature=0, max_tokens=5000) # チェーンを作り、それを使って質問に答える qa = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=text_retriever) return qa.run(prompt)
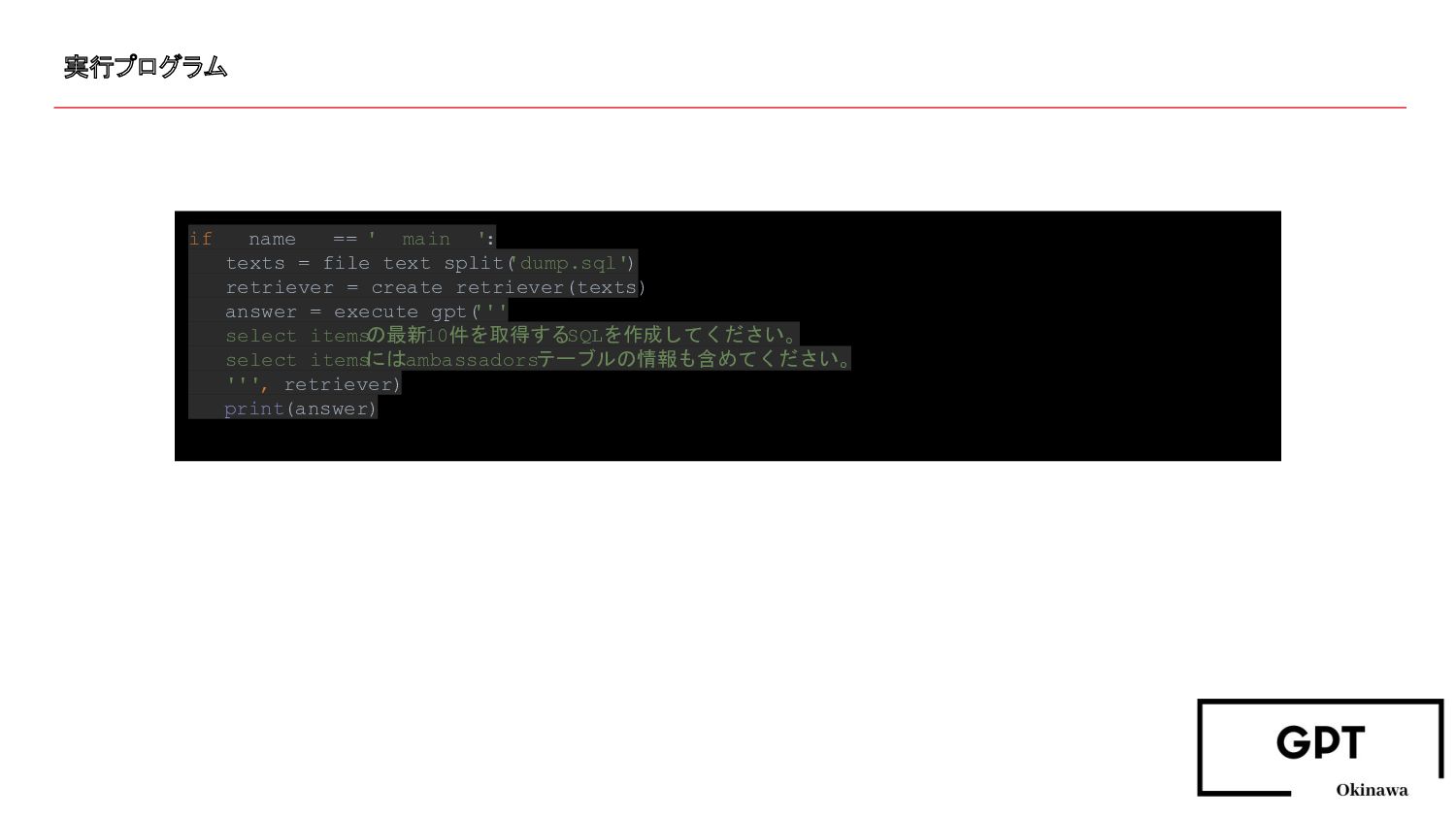
実行プログラム if __name__ == '__main__': texts = file_text_split( 'dump.sql') retriever
= create_retriever(texts) answer = execute_gpt( ''' select_items の最新10件を取得するSQLを作成してください。 select_items にはambassadorsテーブルの情報も含めてください。 ''', retriever) print(answer)
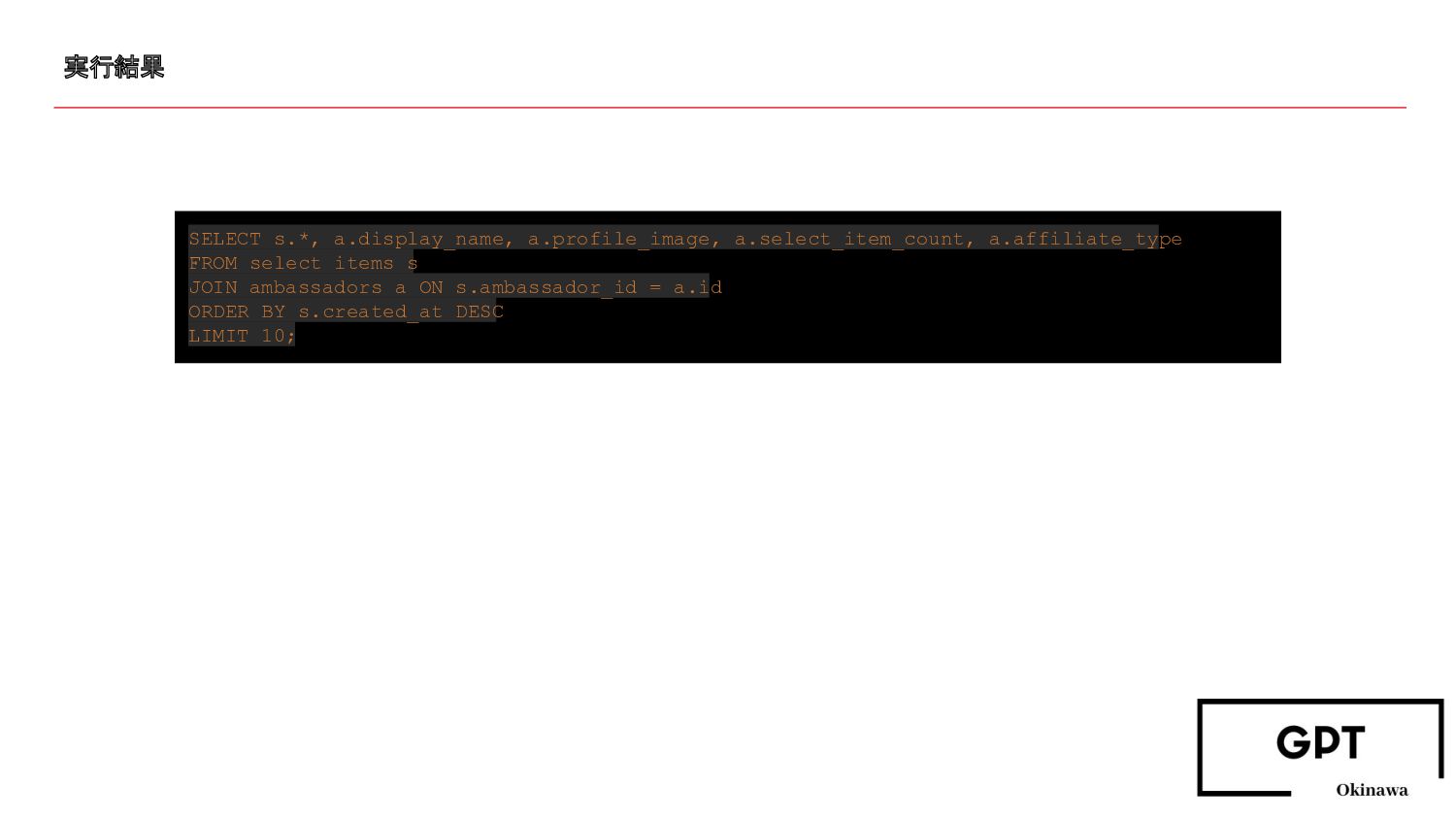
実行結果 SELECT s.*, a.display_name, a.profile_image, a.select_item_count, a.affiliate_type FROM select_items s
JOIN ambassadors a ON s.ambassador_id = a.id ORDER BY s.created_at DESC LIMIT 10;
感想 おおお!
読み込ませたdump.sql データベースのdumpデータを食わせた。 185,426文字のデータ
テキスト分割について 全てのテキストを一回で処理する事が制限されておりできない。 意味のある単位で、テキストをある程度分割する必要がある。 今回は適当に分割してみた。
embeddingとretrieverについて embeddingとは文字をベクトル表現に変換すること 雑に言うと文字が下記のようにマシンが処理しやすい形で管理されるようになる [0.002369190799072385, -0.004423773847520351] retrieverとは、情報を検索して言語モデルに情報を渡せるやつ。 今回だと、GPTの言語モデルにsql dumpのデータを検索して渡している。 正直、内部の詳細はわかっていない。
まとめ - In-Context Learningの実装は難しくない(テキストデータが必要) - ChatGPTには投げられない量のデータを扱える
最後に でかい独自のテキストデータと GPTを簡単に組み合わせる事ができる 色々な活用方法がありますよね!
以上!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![embeddingとretrieverについて embeddingとは文字をベクトル表現に変換すること 雑に言うと文字が下記のようにマシンが処理しやすい形で管理されるようになる [0.002369190799072385, -0.004423773847520351] retrieverとは、情報を検索して言語モデルに情報を渡せるやつ。 今回だと、GPTの言語モデルにsql dumpのデータを検索して渡している。 正直、内部の詳細はわかっていない。](https://files.speakerdeck.com/presentations/9841af2e07fa407dbc6b1e12a1c5c61b/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}