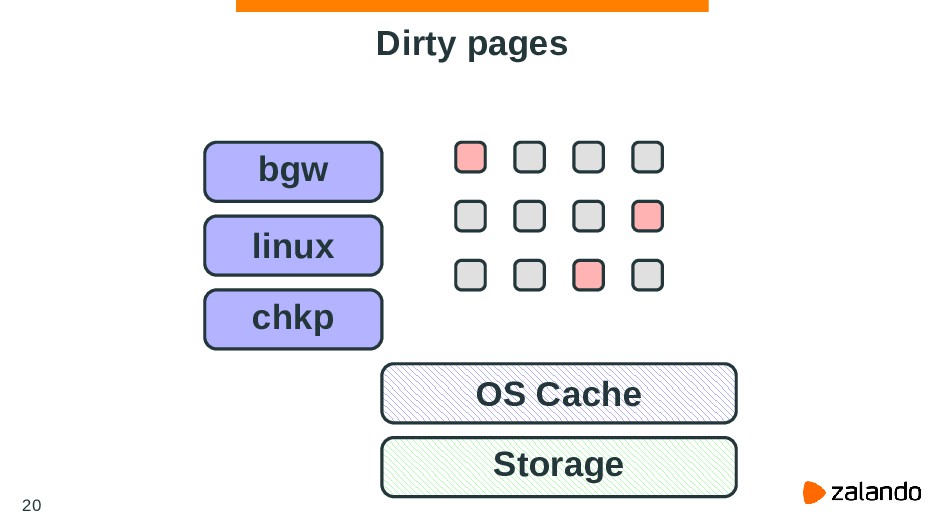
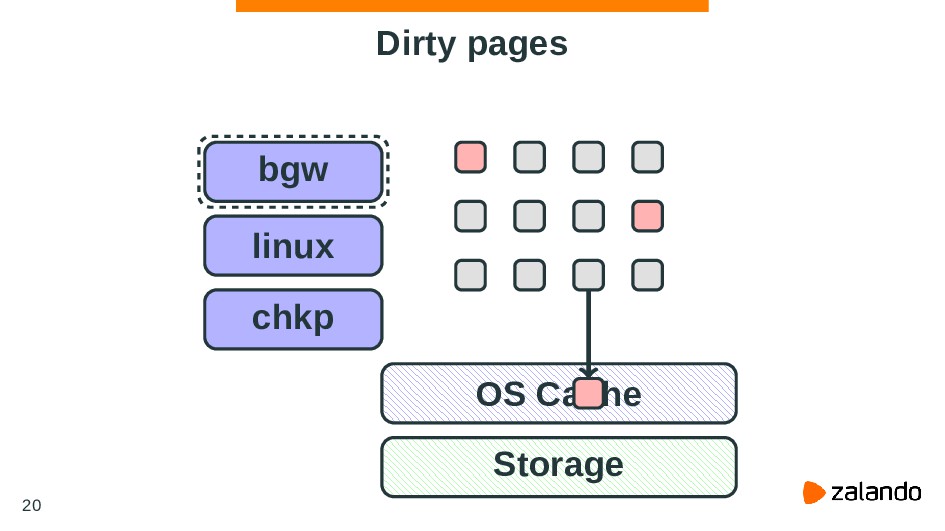
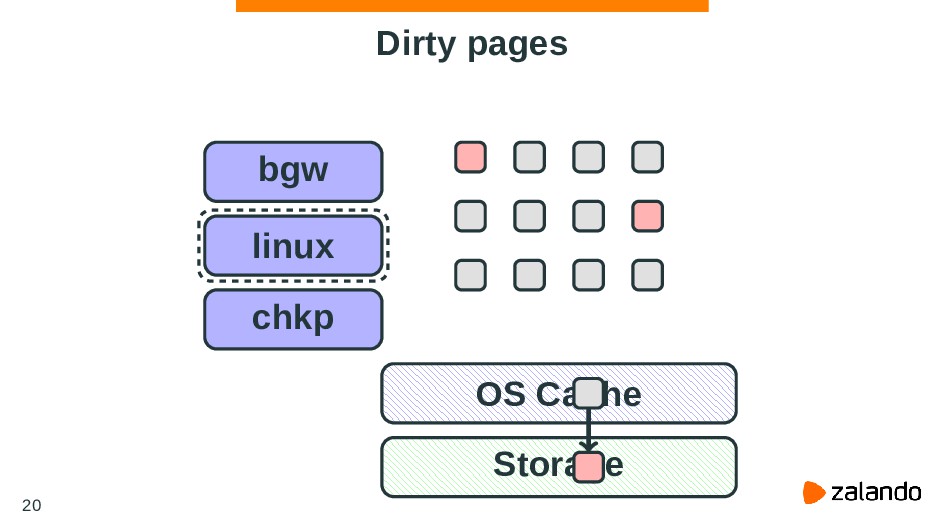
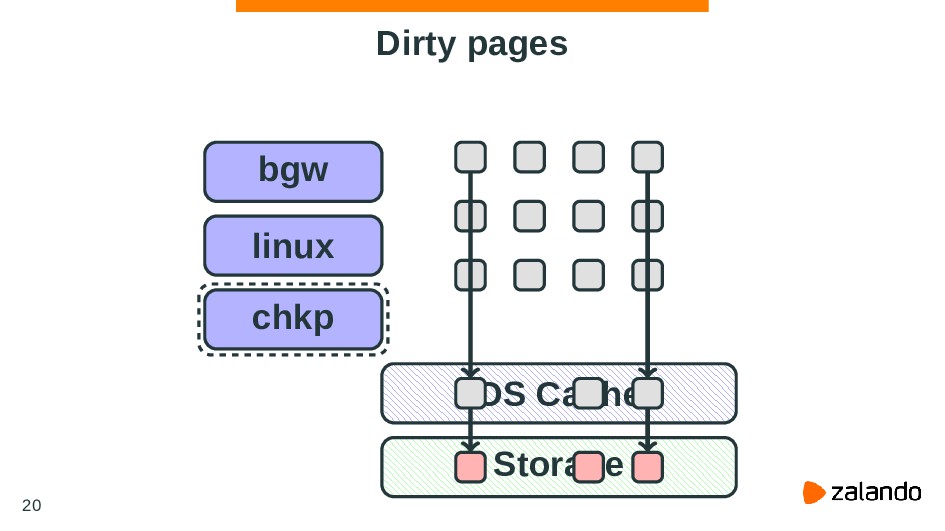
PostgreSQL is a database that heavily relies on functionality provided by an OS. This approach allows the reuse of some best practices and algorithms of utilizing machine resources like memory or CPU time. But on the other hand, it means PostgreSQL dependency on an OS - if you configure your OS it may significantly affect database performance.
In this talk we’ll talk about common techniques of configuring the Linux kernel to work efficiently with PostgreSQL. We’re going to discuss PostgreSQL and kernel internals, some important questions about how they work, and how different options or features of the Linux kernel can help you to manage the high load with PostgreSQL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
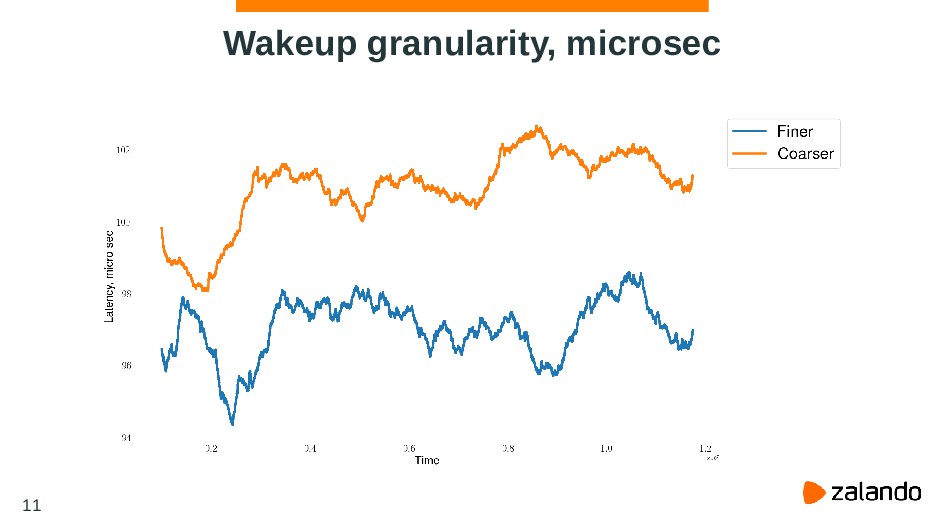{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
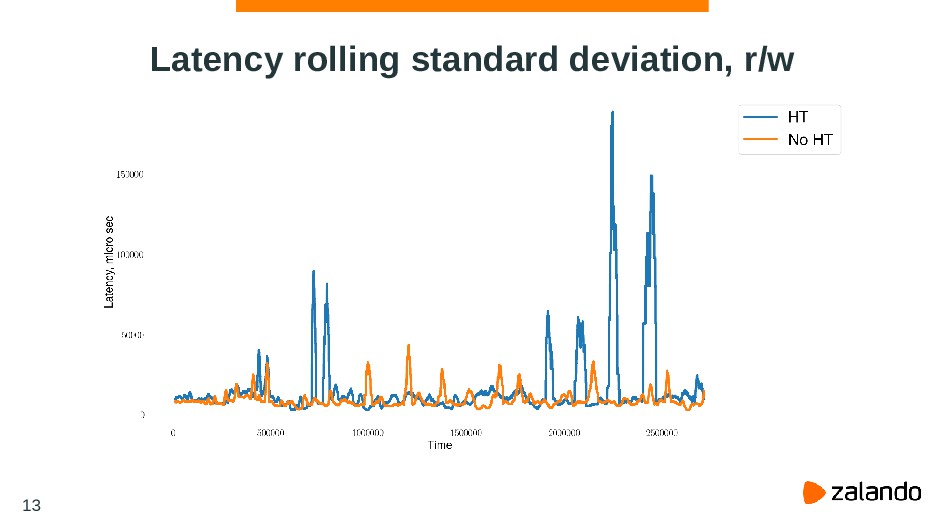{kind=link}
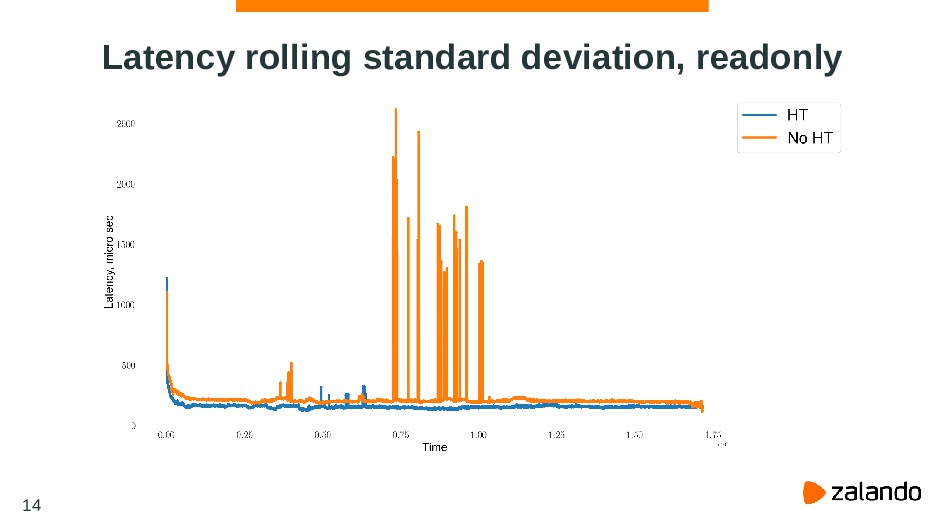{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
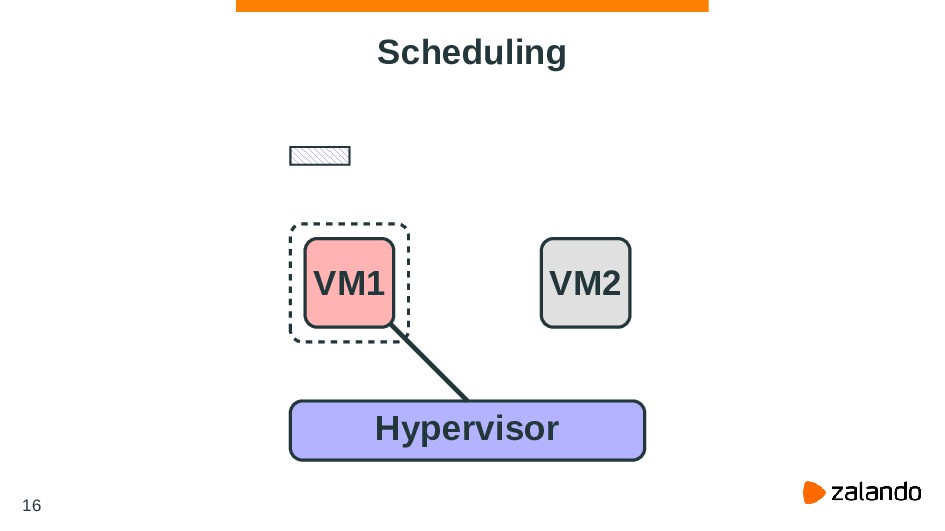{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
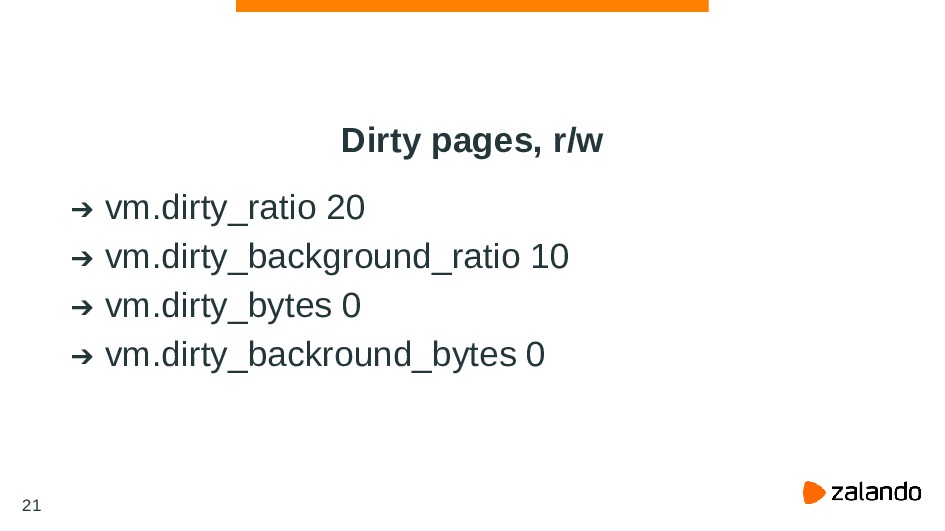{kind=link}
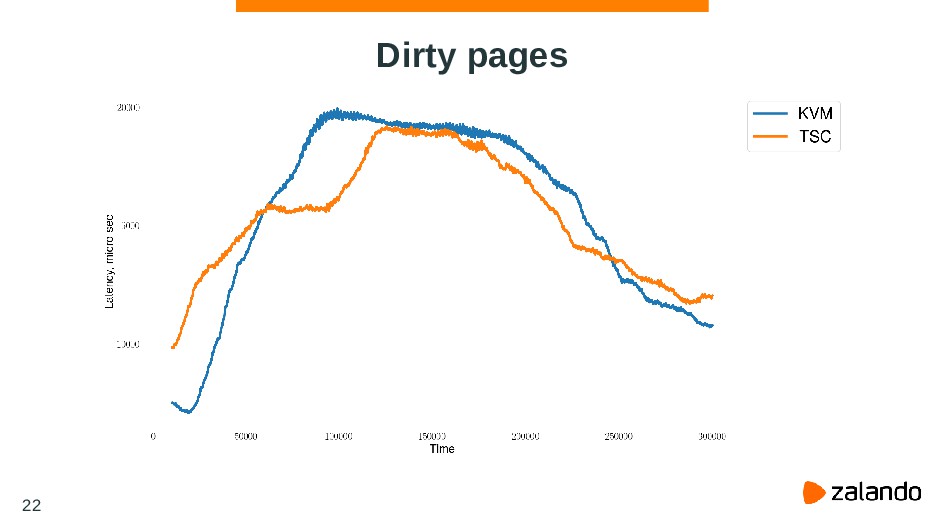{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
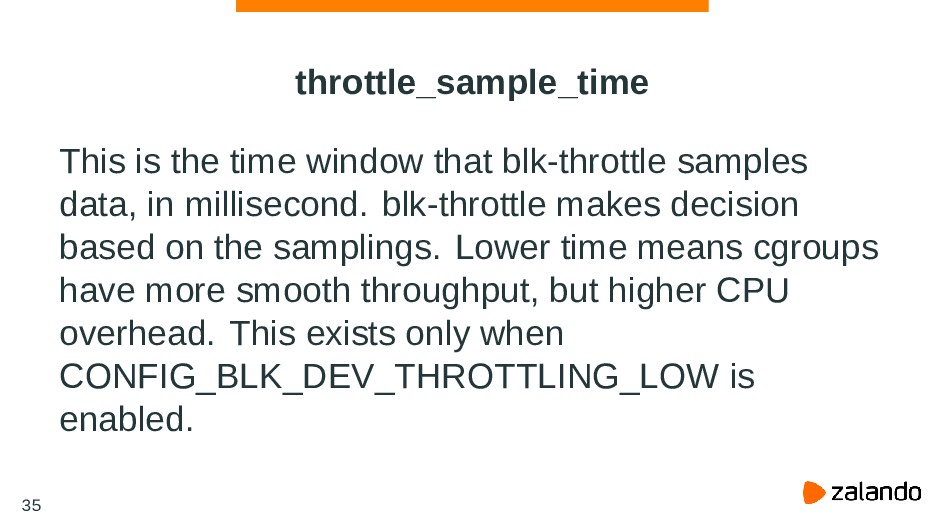
![8388 8388 postgres blk_throtl_bio blk_throtl_bio+0x1 [kernel] dm_make_request+0x80 [kernel] generic_make_request+0xf6 [kernel]](https://files.speakerdeck.com/presentations/8a0668038e6644f0a85c3d0b3d0c0cba/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}