Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Pythonで実現する4コマ漫画の分析・評論_2017
Search
esuji
September 27, 2025
23
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Pythonで実現する4コマ漫画の分析・評論_2017
esuji
September 27, 2025
More Decks by esuji
See All by esuji
PythonとLLMで挑む、 4コマ漫画の構造化データ化
esuji5
2
350
PythonとLLMで挑む、 4コマ漫画の構造化データ化 back
esuji5
0
29
Featured
See All Featured
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
How to Talk to Developers About Accessibility
jct
2
290
Crafting Experiences
bethany
1
210
Art, The Web, and Tiny UX
lynnandtonic
304
22k
YesSQL, Process and Tooling at Scale
rocio
174
15k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
800
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Design in an AI World
tapps
1
260
BBQ
matthewcrist
89
10k
Building the Perfect Custom Keyboard
takai
2
810
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Transcript
Pythonで実現する 4コマ漫画の分析・評論 2017 S 治∕@esuji repo. https://github.com/esuji5/yonkoma2data PyCon Jp 2017
09.09
3行で分かる概要 自分が面白い作品を読みたいので、4コマ漫画周辺の評論をやっ てます 作品を読んでデータをまとめる、分析するのが大変なのでPython でやってしまおう 情熱駆動開発 ✌ ('ω ' ✌
)三 ✌ ('ω ') ✌ 三( ✌ 'ω ') ✌ 2 / 32
自己紹介 名前:S治∕@esuji (北川慎治) 所属:株式会社ビープラウド 運営サービス: 近況:初心者向けのPython 本を共著で執筆 WEBサービス:subcatalog (
コミケに行く人のスペース探す) 3 / 32
4コマ漫画と評論 とPython 4 / 32
4コマ漫画とは 4つのコマによって短い物語を作る日本の漫画の形式の一つ 新聞や雑誌の一部に掲載されるなど古くから存在する 4コマ漫画の専門誌が存在し、ジャンルによって掲載されている 作品の傾向が違っている 5 / 32
現在刊行されている月刊4コマ漫画雑誌 まんがホーム、まんがタイム、まんがタイムジャン ボ、まんがタイムファミリー、まんがタイムスペシ ャル、まんがタイムオリジナル、まんがタイムきら ら、まんがタイムきららミラク、まんがタイムきら らMAX、まんがタイムきららキャラット、まんがタ ウン、まんがくらぶ、まんがライフオリジナル、ま んがライフ、まんがライフMOMO、まんが4コマぱ れっと、コミック電撃だいおうじ、コミックキュー ン
6 / 32
評論・批評とは 捉えられがちな意味 作品の悪口を言うことで自尊心を満たすもの 感情論で作品を貶める・レッテルを貼るもの 7 / 32
個人的に考える評論のあるべき姿 作品への新しい読み方を提示して、 作品と作家と読者に、新しい道を拓く (きづきあきら著『ヨイコノミライ』4巻より) 個人的な実績:アニメ『ゆゆ式』の監督インタビュー アニメの良い部分を探すブログを書き続けたことがきっかけ 8 / 32
4コマ漫画評論とPython 手作業でのデータ収集が大変なのでプログラムでガッとやりたい コマ毎の画像に変換 → 画像処理 セリフデータ抜き出し → OCR 、自然言語処理 誰がどこに映っているのか
→ 人物検出・認識 収集したデータの分析 pandas等を使っての分析 → 慣れればExcel より速くて楽 分析・可視化 → 慣れればExcel より( 以下略) やりたいことが多いので出来るだけライブラリ・APIに頼る方針 Pythonならどれもだいたい実現できるだろうという目論見 9 / 32
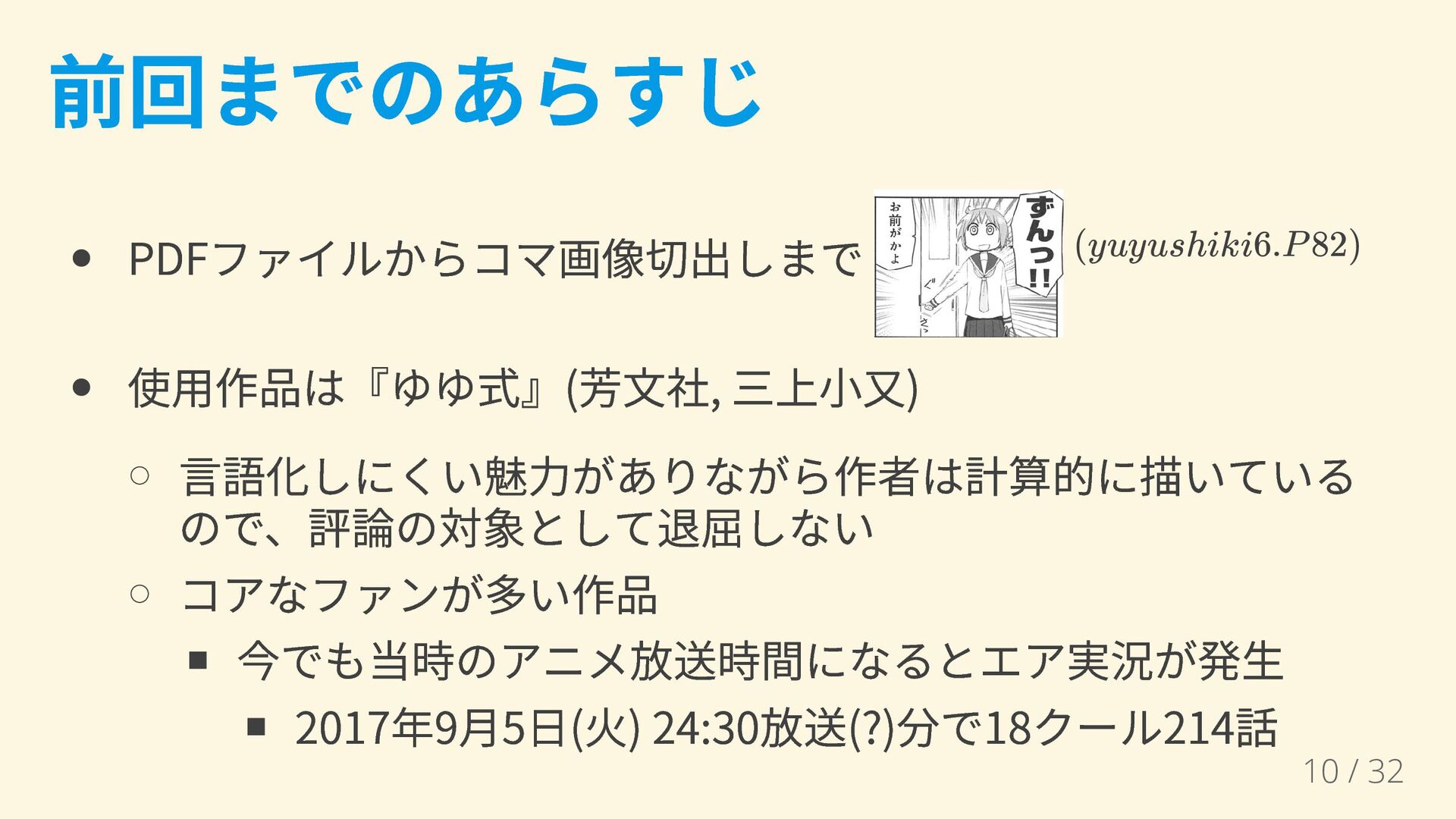
前回までのあらすじ PDFファイルからコマ画像切出しまで 使用作品は『ゆゆ式』(芳文社, 三上小又) 言語化しにくい魅力がありながら作者は計算的に描いている ので、評論の対象として退屈しない コアなファンが多い作品 今でも当時のアニメ放送時間になるとエア実況が発生 2017年9月5日(火) 24:30放送(?)分で18クール214話
(yuyushiki6.P82) 10 / 32
今日のアジェンダ OCR結果を「日本語」にする 人物を検出する(detection) 人物を分類する(classi cation) 今後の展望 情熱駆動開発について まとめ 11 /
32
OCR結果を「日本語」にする セリフをデータ化するためにGoogle Cloud Vision APIでOCR 縦書き日本語に対応したOCRとしてはとてもよい結果を出す ただし、そのまま日本語として扱えるかは別の話 返ってきたOCR結果:' 野々原家\n 独特の\n(
ヘ\n なんか?\n あつや だ\n 恥ずかしい!) e®\n し!\n 家の事\n 恥ずかしい\n し!\n' (APIresult, yuyushiki7.P46) 12 / 32
OCR結果の問題点 文字ではない部分が余計な文字として認識される 言語を指定しなくても日本語縦書きを認識するが、逆に横書きと して認識される場合もあって煩わしい 吹き出し外の手書き文字の検出精度が悪い 上下で2つの吹き出しに分かれている場合、右上から下に向かっ て走査されるため、順番がおかしくなる 特殊なフォントでは文字列の誤検出になる確率が高い 傍線やリーダー点のような記号の区別精度が悪い 13
/ 32
日本語化への頑張り ルールベースでとにかく余分なものを排除していく 無効な文字の設定(例:英数記号のみ) 横長の検出部を排除 細すぎる検出部は除外文字(例:1, へ, ー等)以外なら排除 吹き出し外の文字を判定して除外 吹き出しの結合 吹き出し判定を行い、真ならそのエリア内の文字列を結合
縦に吹き出しが分かれている場合も頑張る 14 / 32
頑張りの結果 1: 野々原家独特のヘなんか? 2: あつやだ恥ずかしい! 家の事恥ずかしい! (APIresult, yuyushiki7.P46) 15 /
32
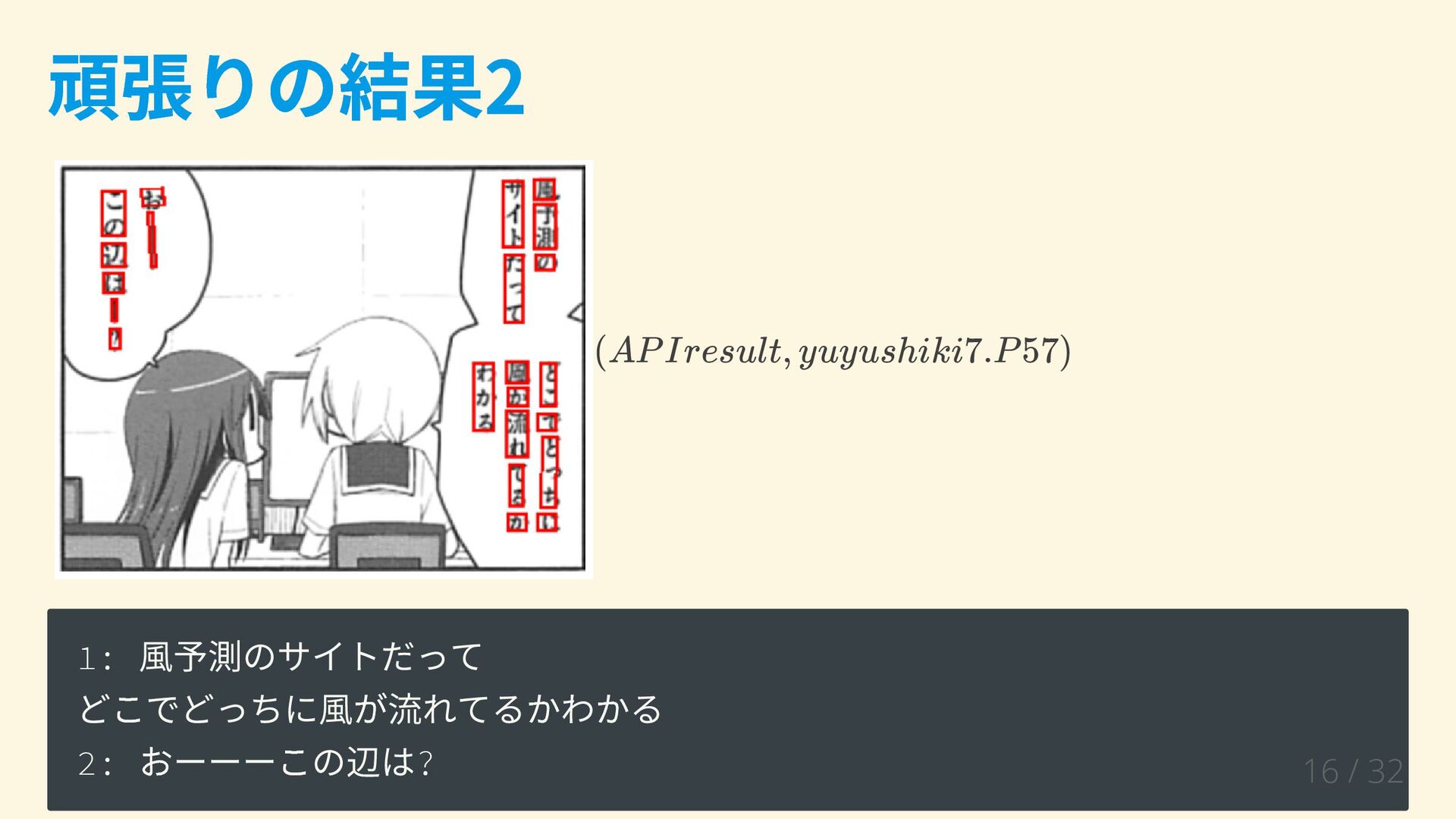
頑張りの結果2 1: 風予測のサイトだって どこでどっちに風が流れてるかわかる 2: おーーーこの辺は? (APIresult, yuyushiki7.P57) 16 /
32
人物を検出する(detection) 検出:人物らしきものが映っている座標を特定する 計算量が多すぎない方法としてdlib の物体検出器を利用する 既存のアニメ顔検出器の結果をdlibで使えるxmlとして吐き出す 等のテクニックも使える ゆゆ式では横向き・後ろ向き・顔の重なりが表現として頻出する が、それでも検出できるかを試す yuyushiki5.P11, P92
17 / 32
imglabでGUIアノテーション dlib付属のimglabを使ってGUIで顔部分をアノテーション 1~7巻まで各50コマをランダムに抜き出し、学習させる 学習させる量が多すぎるとメモリ不足で動かなくなる 学習後のdetectorで5巻から顔を切り出す…… だが、しかし 目を顔と誤検出 吹き出しやセリフ文字を顔と誤検出 顔を検出しても範囲が広すぎるか狭すぎて切り取れない 期待した精度は出なかった。
18 / 32
人物を分類する(classi cation) 検出した人物画像を切り抜いて分類することで誰がどこに映って いるのかをデータ化する 画像分類に定評のあるCNN(Convolutional Neural Network) keras でのCIFAR10 のサンプルコードをベースにした
モデル:( 畳込み層+ プーリング層)×2 入力画像サイズは32×32px 既存のアニメ顔検出器を用いて正面向きの顔を切り出す 19 / 32
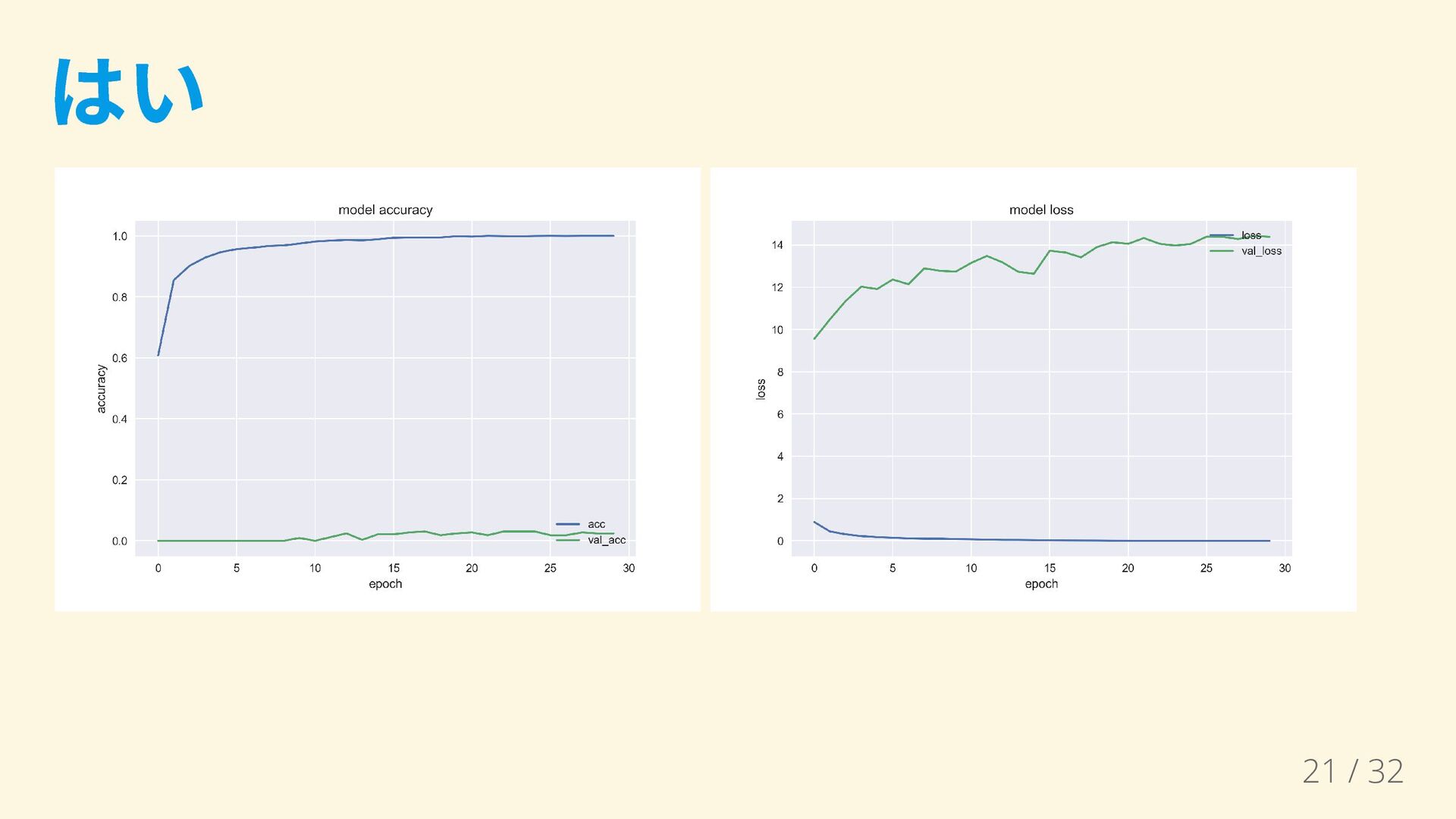
1~7巻分から切り出した顔の数 野々原ゆずこ:1368 日向縁:1109 櫟井唯:1152 松本頼子:127 相川千穂:130 岡野佳:102 長谷川ふみ:77 問:このサンプルで学習は上手くいくでしょうか? 20
/ 32
はい 21 / 32
答:だめみたいですね…… precision recall f1-score support 0 0.86 0.99 0.92 121
1 0.84 0.99 0.91 95 2 0.97 0.97 0.97 106 3 0.50 0.25 0.33 12 4 0.00 0.00 0.00 13 5 0.00 0.00 0.00 10 6 0.00 0.00 0.00 7 avg / total 0.80 0.88 0.84 364 22 / 32
人物の検出・分類手法の敗北 検出と分類の精度からデータ入力支援として使えるかは微妙 吹き出し等の漫画表現 横向き・後ろ向き・重なりの構図が頻出 主要人物の登場数に大きな偏りがある 比較的、前向きや横向きが多いような作品では上手くいく可能性 は十分にある cf. 『NEW GAME!』(芳文社,
得能正太郎) 23 / 32
今後の展望 データにまとめる 処理毎に画像パスを持つCSV形式にまとめていく セリフデータと画像パスの対 人物データと画像パスの対 and more... データを分析する データが集まったら知りたいことを好きなだけ分析する 24
/ 32
やりたいこと-1 背景の種類を判断する 場所 教室、唯ちゃんの部屋、外 スクリーントーンのパターン 無背景 OCRの自前実装 セリフ、人物、状況から該当コマを検索するシステム 25 /
32
やりたいこと-2 人物配置・カメラワークの分析 人物配置のパターン イマジナリーライン超えの率 同ポジション率 他、どんなパターンがあるのか 26 / 32
やりたいこと-3 会話内容の分析 頻出語を調べる 会話遷移のパターン 話を振る、話を広げる、ツッコむ ギャグを言う、受けない、ディスコミュニケーション 27 / 32
よくある質問 最終的にAIとかに活かせないの? 創作として面白いかは別の問題として 「ゆゆ式らしい」人物配置、会話を生成し無限に楽しむ 二次創作のネームとして人物配置を利用 人物配置の何が重要なの? 漫画は右から読んでいくため、コマ上の人物配置とセリフの 順番が概ね一致する ただしイマジナリーライン超え等の制約を考えると、読みや すい人物配置はバリエーションに限りがある
28 / 32
情熱駆動開発 自分が欲しいものを誰かが作ってくれることはないと気付く やりたいことがプログラムで解決できそうか当たりを付ける Pythonなら様々な分野のライブラリが存在する やりたいことの情報に色々触れる 勉強会に行く 界隈の情報を流してくれる人をSNSでフォローする 論文を読む 勉強する 実現する
→ ✌ ('ω ' ✌ )三 ✌ ('ω ') ✌ 三( ✌ 'ω ') ✌ 29 / 32
まとめ 4コマ評論をプログラミングで加速させるにはPythonが最適 画像処理、機械学習、深層学習、APIに投げる、分析等 実際、さっさとデータを手入力した方が速いのは内緒 ルールベースを敷いていくのはとても辛い 人物検出・分類をするには作品の難易度が高い 情熱駆動開発はやっぱり ✌ ('ω '
✌ )三 ✌ ('ω ') ✌ 三( ✌ 'ω ') ✌ 30 / 32
ご清聴ありがとうございました and... 原作『ゆゆ式』 1 〜9 巻発売中 アニメBD-BOX 好評発売中 新作OVA 好評発売中
31 / 32
発表後に寄せられた提案 人物の検出 ネガティブサンプルを集めるようにする 頭の一部のみをアノテーションして検出・分類に使う 人物の分類 illustration2vecを用いた特徴抽出&機械学習で精度向上 セリフの内容から言ってる人を推定し、人物の認識につなげる 32 / 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}