Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
PythonとLLMで挑む、 4コマ漫画の構造化データ化 back
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
esuji
September 27, 2025
29
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
PythonとLLMで挑む、 4コマ漫画の構造化データ化 back
esuji
September 27, 2025
More Decks by esuji
See All by esuji
PythonとLLMで挑む、 4コマ漫画の構造化データ化
esuji5
2
350
Pythonで実現する4コマ漫画の分析・評論_2017
esuji5
0
23
Featured
See All Featured
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
We Are The Robots
honzajavorek
0
270
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
290
Believing is Seeing
oripsolob
1
170
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
180
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
63
55k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Product Roadmaps are Hard
iamctodd
55
12k
Transcript
PythonとLLMで挑む、 4コマ漫画の構造化データ化 2025.09.27 @esuji
最初にタイトルの内容を説明します 非構造化データをLLMでデータ化したいという例 ここでの非構造化データの定義は「表や画像に必要なデータが 含まれているがOCRだけでは項目と値を紐付けられないもの」とします 目的:買ったものをデータ化したい 非構造化データ:レシートを撮影したもの 構造化データ:{“商品”: “商品名”, “価格”: “◯◯円”}
やりかた:レシートの写真を取って Geminiに投げる。 プロンプト:「買ったものと価格を json形式で返して」→返ってくる ポイント:日本語OCR能力と表や画像の理解力
最初にタイトルの内容を説明します 実際のシステムで使うなら - 返すスキーマを詳細に定義: {“item”: item_name(str) , “price”: price(int)} -
例外を考慮したプロンプト作成:「商品情報が見つからないときは …」 - 帰ってきたデータの整形・検証:「円」を除去、正負判定、範囲判定 - 既存システム・DBへの統合:画面を作ってユーザーに紐付くデータにして … - 帰ってきたデータを受け入れるか判断する UI Pythonでやると良いところ - 入力する画像に事前画像処理:傾きや明るさ調整、トリミング、ノイズ除去 - 入力・出力のデータを機械学習・深層学習で処理:商品名からカテゴリ判定
自己紹介 - 名前:S治(@esuji) - プログラミング初心者向けの本は北川慎治名義で出してます(共著) - Pythonは2014年くらいから使ってます - 普段はWebやデータをあれこれするエンジニア -
最近は仕事で、とある非構造化データの LLMでのデータ化をやってました - 4コマ漫画とプログラミング関連で 10年くらいいろいろやってます - PyCon JPでの発表は4回目 - 2016年、2017年はトーク、2019年はポスター発表
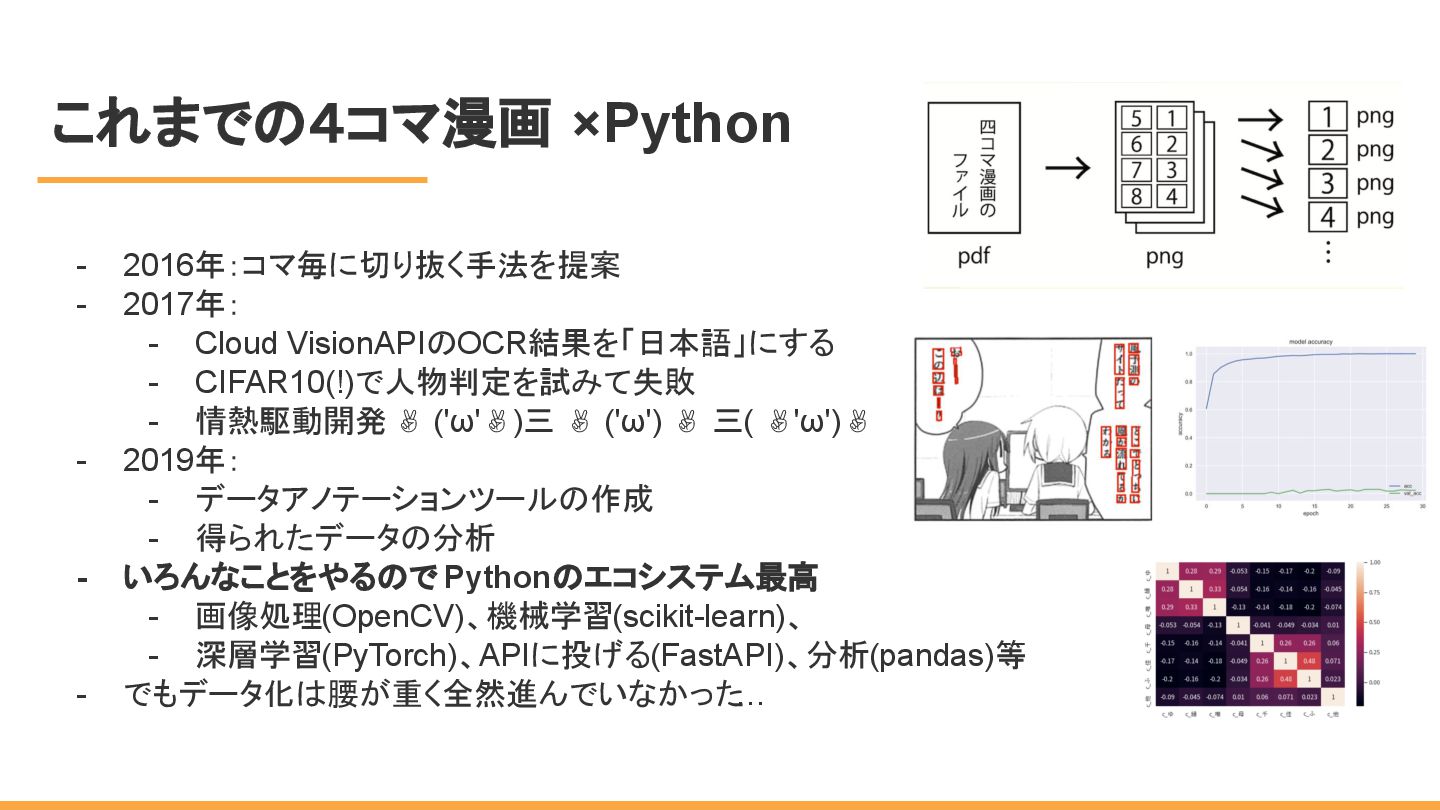
これまでの4コマ漫画 ×Python - 2016年:コマ毎に切り抜く手法を提案 - 2017年: - Cloud VisionAPIのOCR結果を「日本語」にする -
CIFAR10(!)で人物判定を試みて失敗 - 情熱駆動開発 ✌ ('ω'✌)三 ✌ ('ω') ✌ 三( ✌'ω')✌ - 2019年: - データアノテーションツールの作成 - 得られたデータの分析 - いろんなことをやるので Pythonのエコシステム最高 - 画像処理(OpenCV)、機械学習(scikit-learn)、 - 深層学習(PyTorch)、APIに投げる(FastAPI)、分析(pandas)等 - でもデータ化は腰が重く全然進んでいなかった …
LLMがやってきた - 2024年12月にGoogle Gemini 2.0が来てから日本語OCRや画像解釈能力が飛躍的に向上 - 日本語の表データもかなり取れるという実感 - 4コマ漫画にも応用できるという期待 -
人物と出てくる順番、発言の内容、発言の話者特定 をさせたい - ↓ - 結論:けっこういけそうでやっぱり無理 - プロンプトを頑張るのも事前情報を頑張るのもなんかむずい - 頑張ったプロンプト例: - 登場人物の特徴・口調・性格などを列挙 - 回答のスキーマを詳細に定義 - 具体例の画像とその画像に対する模範解答を付与
(寄り道)人物と出てくる順番、はなぜ重要なのか - 一般的な日本語の4コマ漫画は右上から読み始める - そのコマの最初のセリフは右にいる人物から始まるのが基本 - その人物が前のコマで左にいると、イマジナリーラインを超えてし まう可能性が高い - 絶対に超えてはいけないわけではないが、読者への違和感
をどれくらい許容するかに関わる - 詳しくは「イマジナリーライン 」で画像検索! - コマの流れと人物配置の置き方から作者のカメラワークへのこだ わりなどが見えてくる 『ひらめきはつめちゃん』 2巻 (大沖)より 大幅に超えていそうな例
LLMがダメなら深層学習でやればいいのでは with LLM 以前まではめんどくささがこれだけあった - モデル選定:最新の情報が追えてない、対象がモノクロ漫画という特殊性 - スクリプト準備:どのライブラリ使う?からパラメータやデータ水増しどうするかまで - アノテーション環境の用意:既存のアノテーションツールで賄えない部分は要自作
- アノテーションデータ変換:難しくはないけど、ただただ面倒 LLMを頼ればいいのでは - Claude Code (Maxプラン)にお願いしてみた - モデル選定→DINOv2(認識)とかYolo11(検出&認識)がいいんじゃない - スクリプト準備→Google Colabで学習させるNotebook作っておくね - アノテーション環境:Reactでさっとアノテーションツールを作っておいたよ - アノテーションデータ変換:変換用スクリプト書いておいたよ
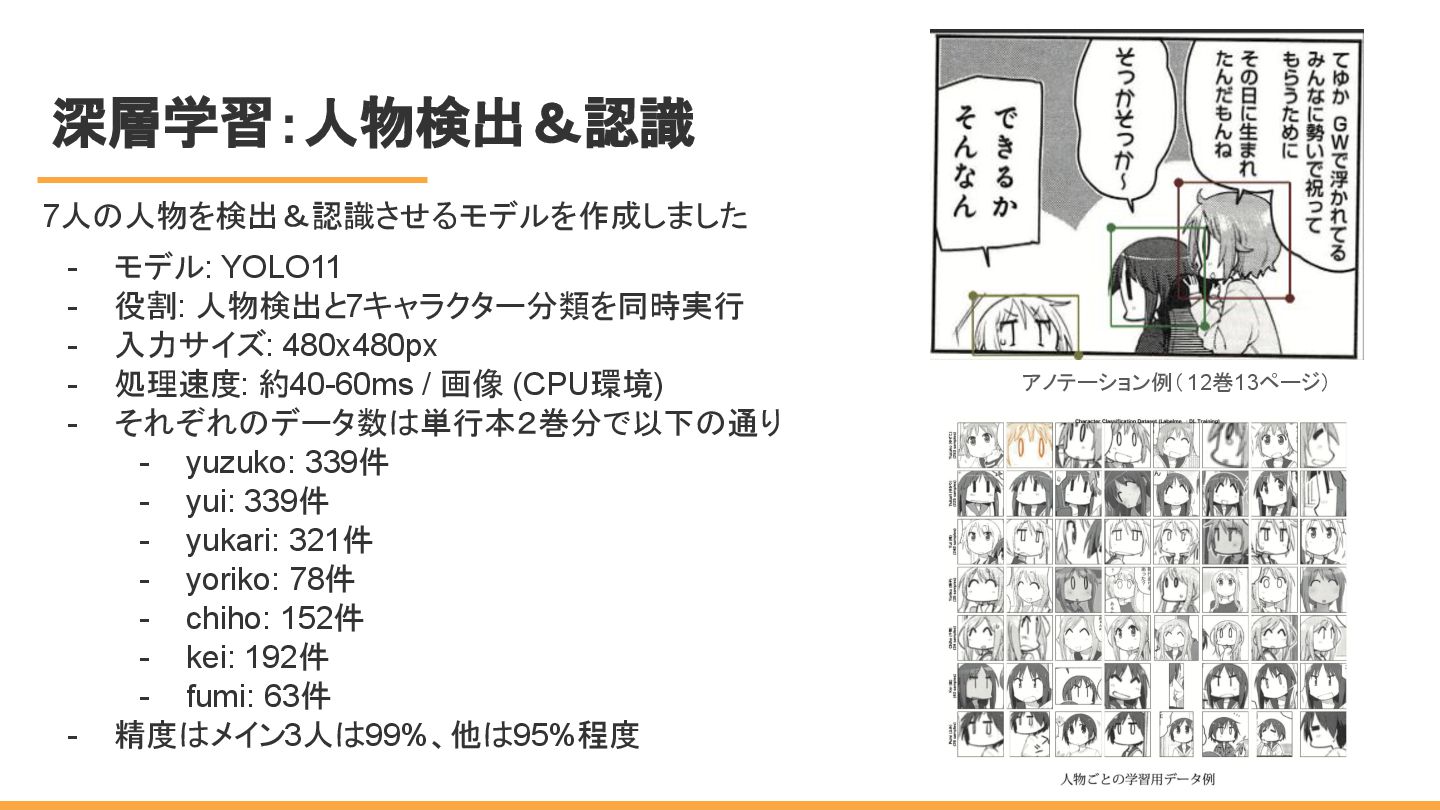
深層学習:人物検出&認識 7人の人物を検出&認識させるモデルを作成しました - モデル: YOLO11 - 役割: 人物検出と7キャラクター分類を同時実行 - 入力サイズ:
480x480px - 処理速度: 約40-60ms / 画像 (CPU環境) - それぞれのデータ数は単行本2巻分で以下の通り - yuzuko: 339件 - yui: 339件 - yukari: 321件 - yoriko: 78件 - chiho: 152件 - kei: 192件 - fumi: 63件 - 精度はメイン3人は99%、他は95%程度 アノテーション例( 12巻13ページ)
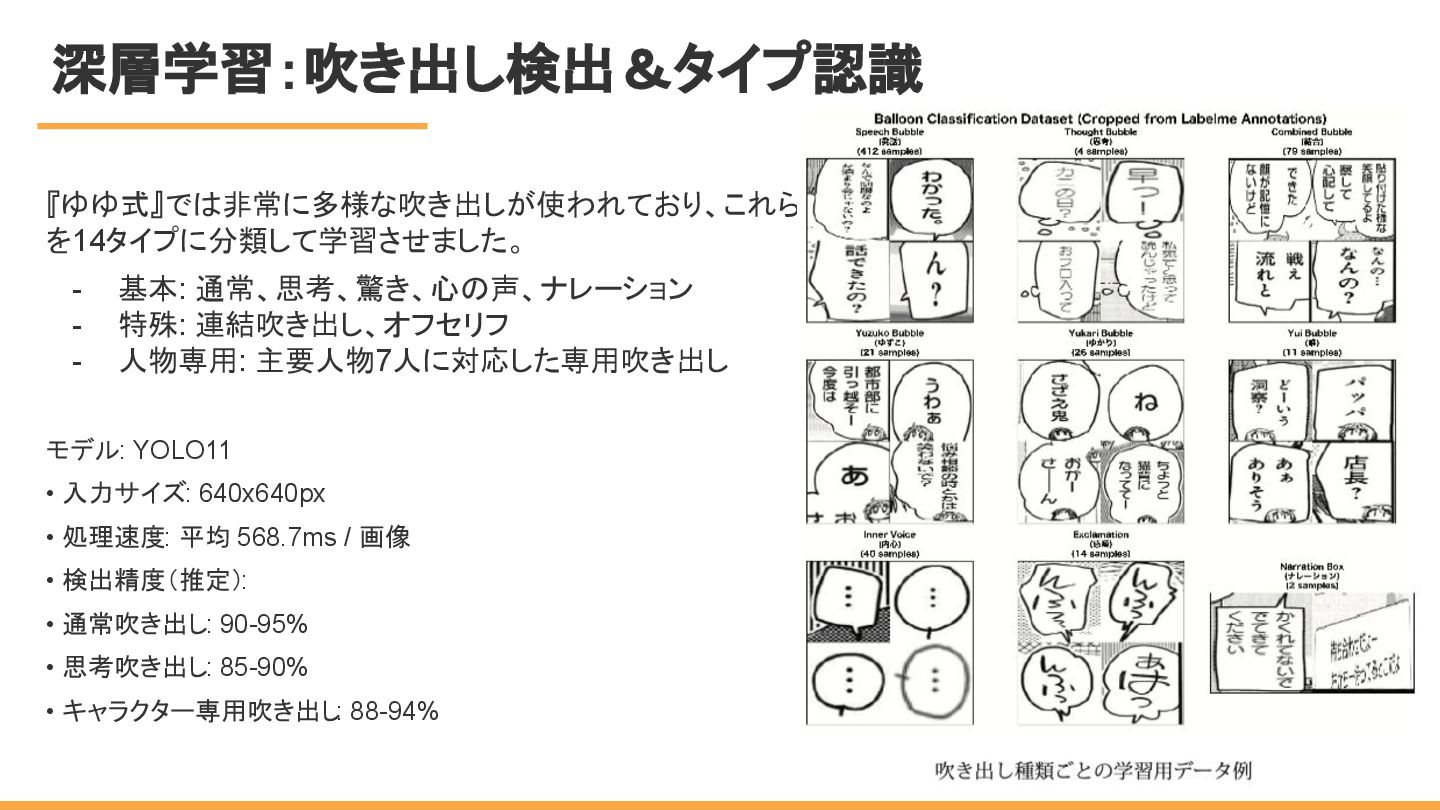
深層学習:吹き出し検出&タイプ認識 『ゆゆ式』では非常に多様な吹き出しが使われており、これら を14タイプに分類して学習させました。 - 基本: 通常、思考、驚き、心の声、ナレーション - 特殊: 連結吹き出し、オフセリフ -
人物専用: 主要人物7人に対応した専用吹き出し モデル: YOLO11 • 入力サイズ: 640x640px • 処理速度: 平均 568.7ms / 画像 • 検出精度(推定): • 通常吹き出し: 90-95% • 思考吹き出し: 85-90% • キャラクター専用吹き出し : 88-94% 3
深層学習:吹き出しのしっぽ検出&方向認識 話者推定のために追加情報がほしい - 人物座標と吹き出し座標の近さをマッチングさせれ ば、多くの場合で話者と合っていそう - コマ内の人物全員が話していればそうなる場合が多 いが、増減すると別のマッチングが必要 - 通常の吹き出しにはしっぽが付いているのでそれを
使えばいいというシンプルな発想 - ただし、シンプルすぎるのかコミック工学の先行研究 には「やってみたが(4コマ漫画ではない通常のコマ割 り漫画では)精度が出ない」くらいの説明しかないので 実装してみることにした - 最初は画像処理のカーブ検出からしっぽのベクトルを 出してみたが、安定しなかったりトーンなどの背景が あると破滅した しっぽ利用が有効な例(10巻22ページ)
人物認識と吹き出しのしっぽ方向による話者推定 - 向きと角度で分類して画像を集めた - 精度はイマイチ… 70~80%程度 - 左右を間違えて判定 - 上方向データが極端に少ない
- 画像が小さすぎてうまく学習できていない? - しっぽのベクトルを伸ばして人物検出領域とぶつかったら、その人が話者という判定 - しっぽの座標が人物検出領域に埋もれていても、その人が話者という判定
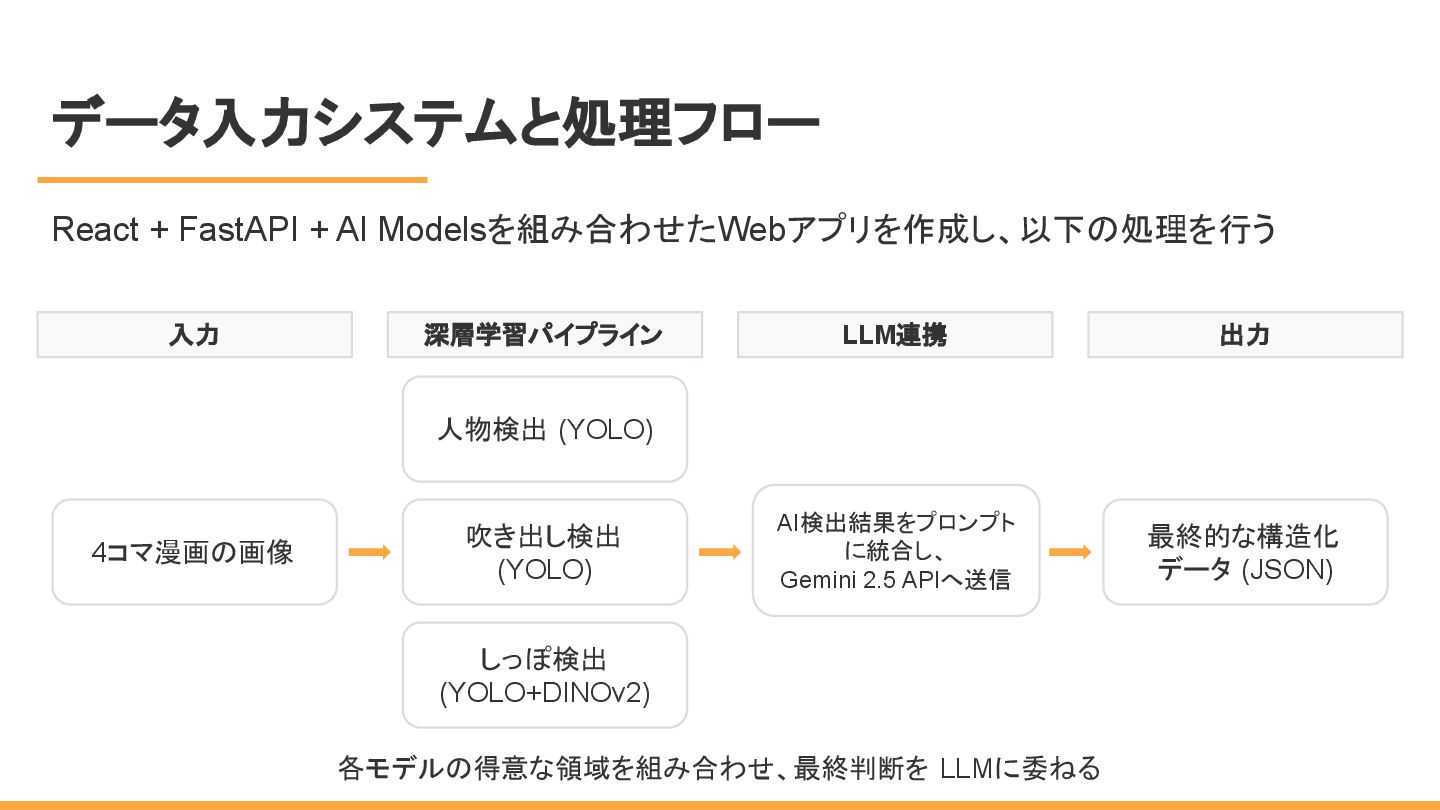
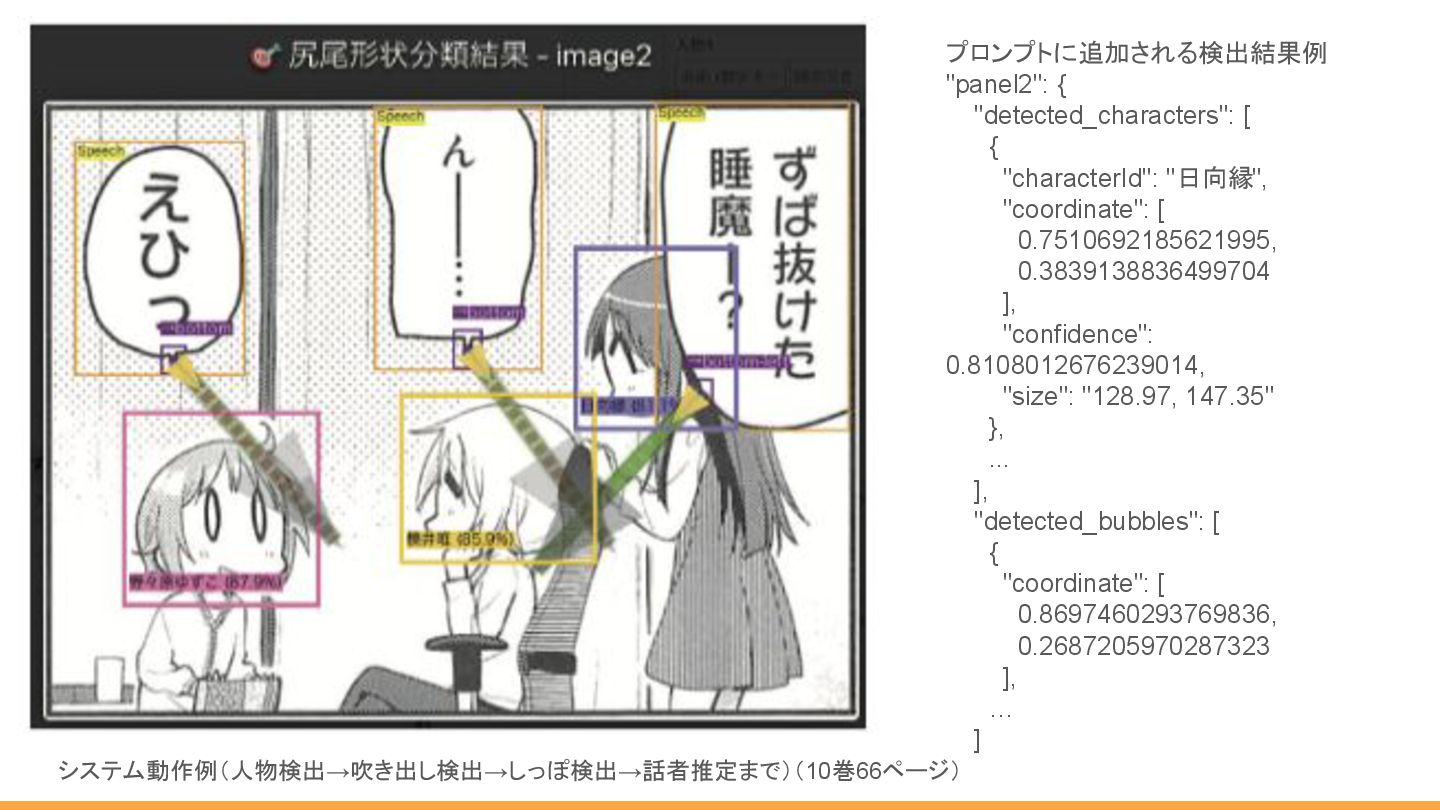
データ入力システムと処理フロー 各モデルの得意な領域を組み合わせ、最終判断を LLMに委ねる 入力 4コマ漫画の画像 深層学習パイプライン 人物検出 (YOLO) 吹き出し検出 (YOLO)
しっぽ検出 (YOLO+DINOv2) LLM連携 AI検出結果をプロンプト に統合し、 Gemini 2.5 APIへ送信 出力 最終的な構造化 データ (JSON) React + FastAPI + AI Modelsを組み合わせたWebアプリを作成し、以下の処理を行う
システム動作例(人物検出→吹き出し検出→しっぽ検出→話者推定まで)(10巻66ページ) プロンプトに追加される検出結果例 "panel2": { "detected_characters": [ { "characterId": "日向縁", "coordinate":
[ 0.7510692185621995, 0.3839138836499704 ], "confidence": 0.8108012676239014, "size": "128.97, 147.35" }, ... ], "detected_bubbles": [ { "coordinate": [ 0.8697460293769836, 0.2687205970287323 ], … ]
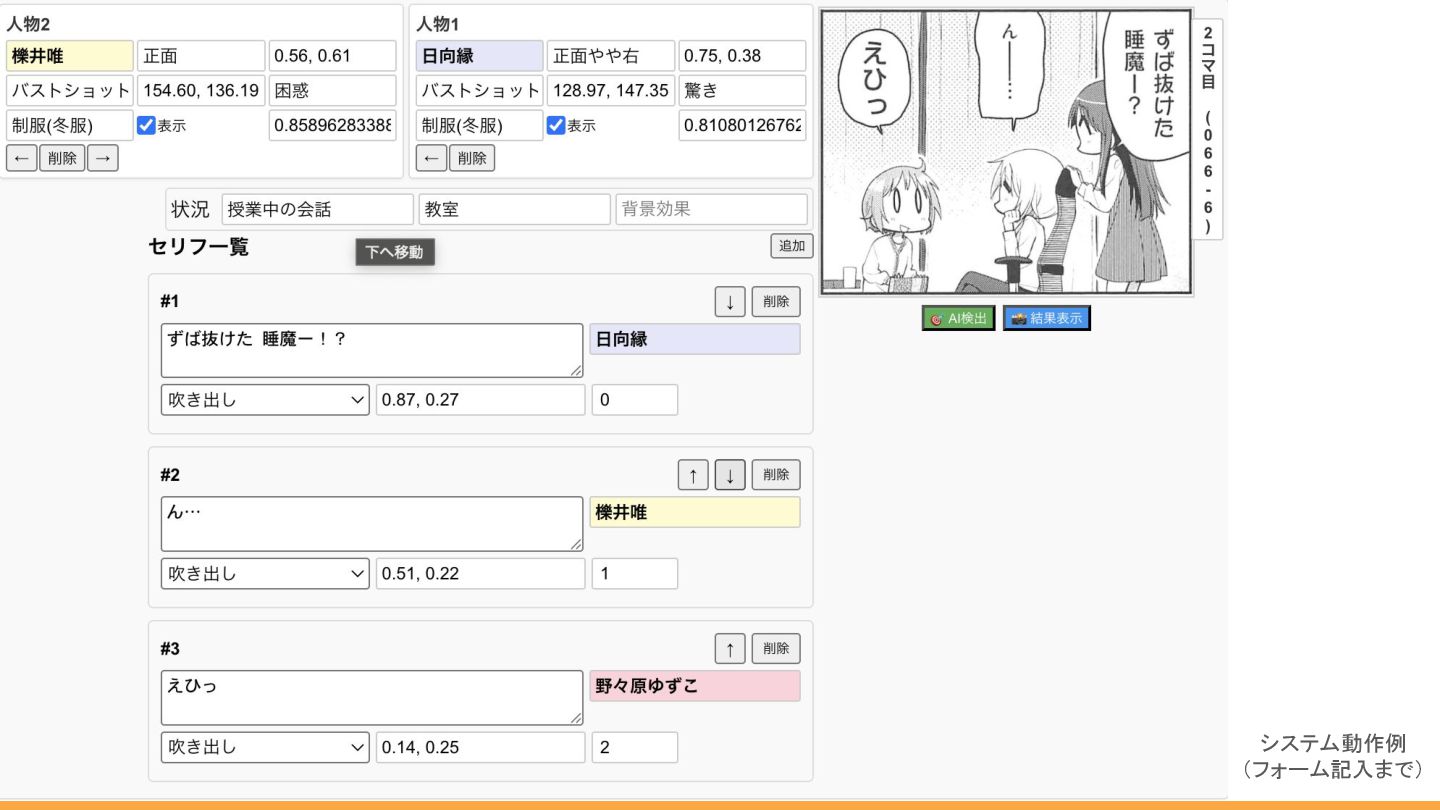
システム動作例 (フォーム記入まで)
システムの評価 実際の精度や時間を評価する 処理時間とコスト - 処理時間(4 コマ 1 セットあたり): 約 50~70
秒 - 深層学習モデルによる全検出・分類処理 : 約 3 秒 - Gemini API の応答時間:約 45~65 秒 - その他(画像読込・結果表示など) : 約 2 秒 - API コスト: 4 コマあたり約 0.8~1.2 円 (Gemini 2.5 Flash) - 単行本 1 冊(約 120 ページ)をすべて処理しても、約 200 円程度に収まる計算 - 作業効率: 手動でのアノテーション作業と比較して、約 75%の時間短縮を実現 - 従来手法:人物と話者の入力で3人・3つ ×4コマでの24入力の手直し - 今回の手法:4コマ分で平均4~6入力
今後の展望 - 発言内容や登場人物、自然言語で、どのコマかを検索できるシステム - DB検索+RAG的なイメージ - 4コマ漫画のネーム制作を支援するツール - 他の作品への展開 -
MLOps大変なのでいい感じのライブラリで解決したい - MLOpsの「あるある」課題の解決と、そのためのライブラリ gokart
まとめ この発表について - 非構造化データをデータ化するなら LLMとPythonの組み合わせは試す価値あり - LLMは開発の準備工程を劇的に短縮してくれる最高のパートナー - 深層学習は座標特定やキャラクター識別、その作品に特化したタスクで高い精度 -
1ヶ月ちょっとくらいでLLMを使い倒してこれを作った、という話でもある ついでにお伝えしたいこと - なにかテーマを持ってみよう アンテナを立てよう - ✨Solve a problem✨
参考文献・ URL 本プロジェクトのGitHub:https://github.com/esuji5/four-panel-forge 同人誌の宣伝:https://esuji.booth.pm/ にて販売中 論文・研究 - The Manga Whisperer:
Automatically Generating Transcriptions for Comics - Ragav Sachdeva, Andrew Zisserman (2024) - Manga109Dialog: A Large-scale Dialogue Dataset for Comics Speaker Detection - Yingxuan Li et al. (2024) - Manga109: http://www.manga109.org/ - 漫画研究の標準データセット
参考文献・ URL AI/LLMサービス - Claude: https://www.anthropic.com/claude - Gemini: https://ai.google.dev/ -
Google Colab: https://colab.research.google.com/ 深層学習ライブラリ・モデル - PyTorch: https://pytorch.org/ - Transformers (Hugging Face): https://huggingface.co/docs/transformers - OpenCV: https://opencv.org/ - Ultralytics YOLO: https://github.com/ultralytics/ultralytics - Segment Anything (SAM): https://segment-anything.com/ - CLIP (OpenAI): https://github.com/openai/CLIP
(寄り道)対象となる作品 「4コマ漫画」といいつつ対象になる作品はほとんど 1つです - 『ゆゆ式』(芳文社,三上小又) - 15巻が今日9/27発売! - 野々原ゆずこ役の大久保瑠美さんも本日がお誕生日! -
2008年、まんがタイムきららで連載開始 - COMIC FUZでも無料分あり - 2013年、アニメ化 - 2017年、OVA発売 - この資料内で説明用に表示されるのは基本的にこの作品のコマ です
- なんでこんなことをやっているか - ゆゆ式という漫画にハマる( 2010年) - 何が面白いのかを考える - よくわからないので評論活動をする( 2012年)
- アニメ監督にインタビューする (2013年) - やることなくなる - プログラミングでなんかやるかとなる( 2015年) - 評論とは - 作品への新しい読み方を提示して、作品と作家と読者に、新しい道を拓く - (きづきあきら著『ヨイコノミライ』 4巻より) 3 (寄り道) 評論活動へのモチベーション
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}