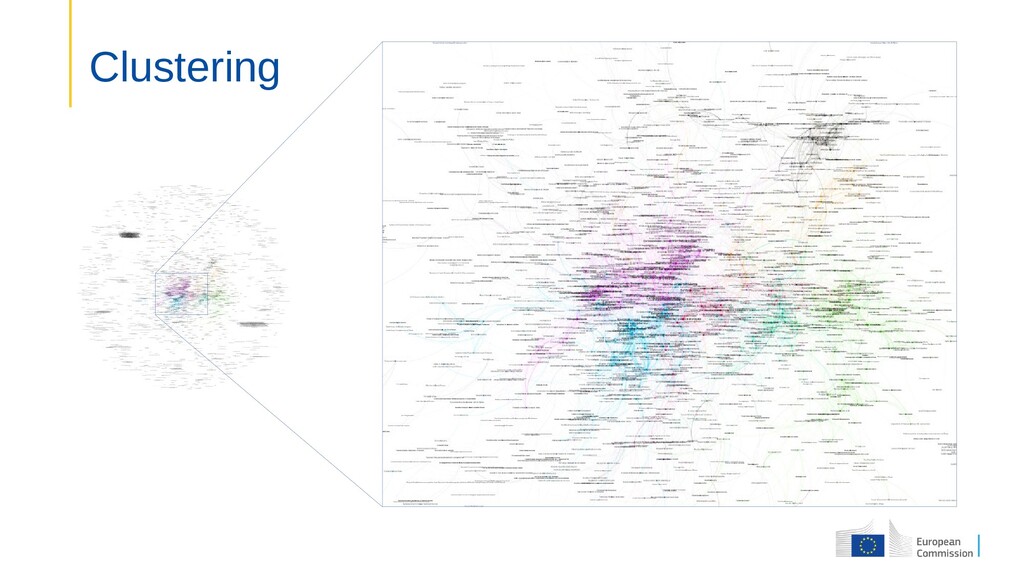
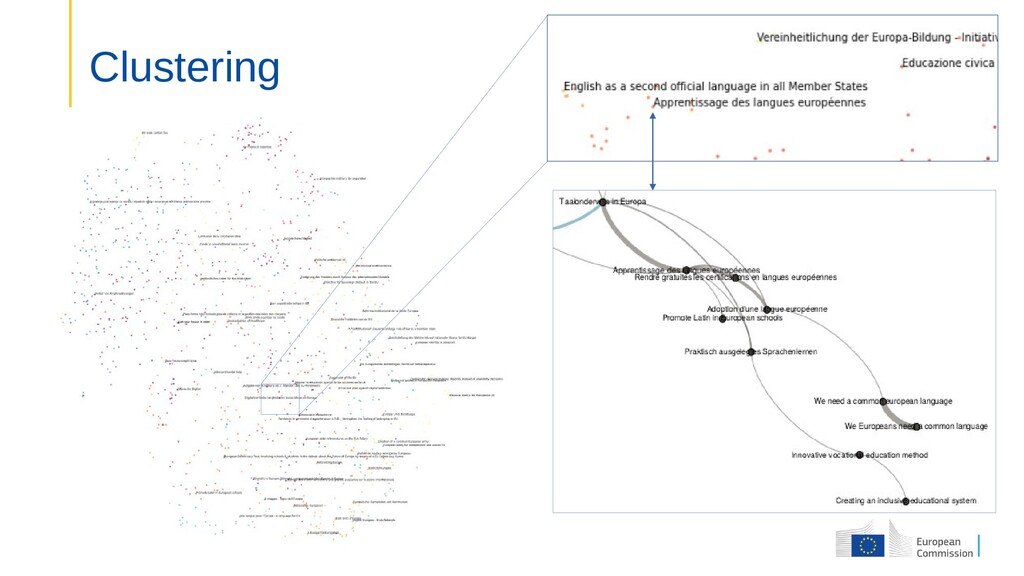
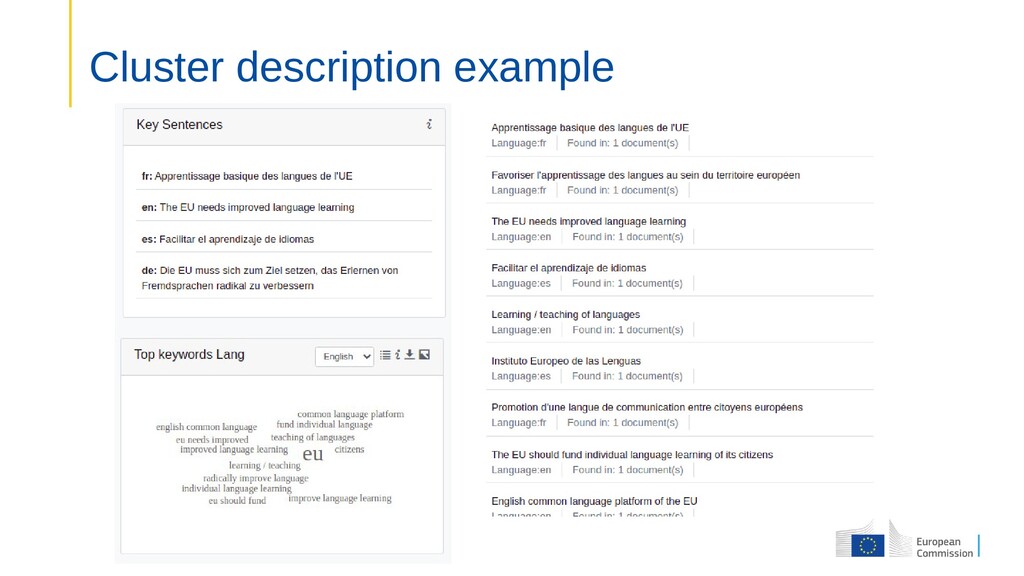
public consultation: 24+ languages 3.5 million uniq visitors 140 000 participants 26 000 contributions • Aim: Make sense of large number of multilingual contributions Identify clusters of linked ideas Find related ideas
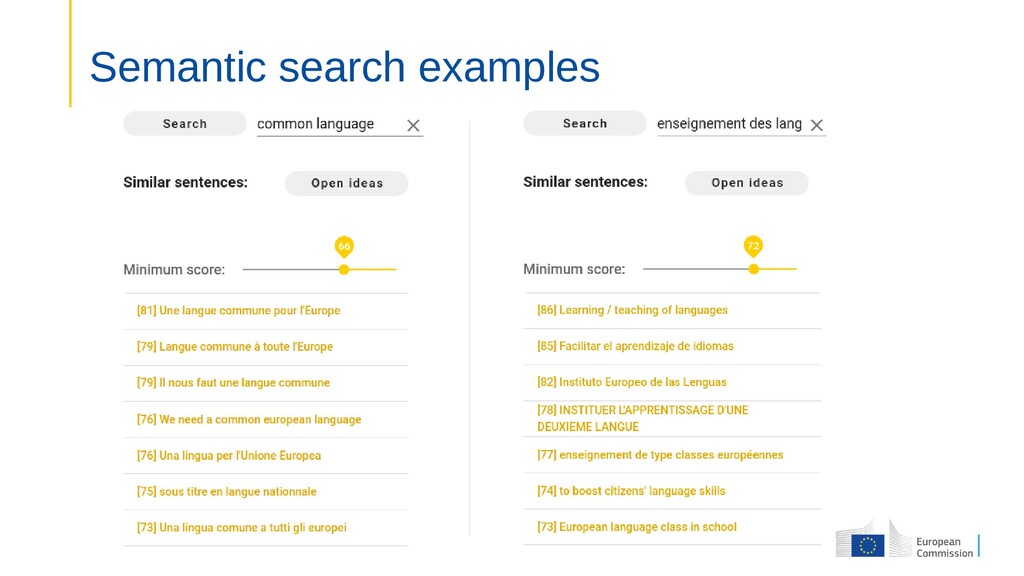
sentence embeddings (~ 100 languages) Ad-hoc: Search, Clustering and Visualisation algorithms • References: Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond A Survey Of Cross-lingual Word Embedding Models
• Information access and summarization in a highly multilingual environment • Supporting “Data for Policy” with Text Mining tools NLP as a key support in ‘Data For Policy’
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}