Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DBとSQLについて
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
福岡情報ビジネスセンター
June 25, 2024
2.9k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DBとSQLについて
社内勉強会資料です。
この資料は、データベース(DB)とSQLの基本を学ぶためのものです。初心者の方でも分かりやすいように、基本的な考え方から実際の操作方法までを順番に説明しています。
福岡情報ビジネスセンター
June 25, 2024
More Decks by 福岡情報ビジネスセンター
See All by 福岡情報ビジネスセンター
GitHub Copilotハンズオン
fbei_ot
0
740
V0勉強会
fbei_ot
0
870
遅くならないSQLの書き方
fbei_ot
0
1.9k
ISMSってどんなもの?
fbei_ot
0
2.1k
ChatGPTをソフトウェア開発に活用する
fbei_ot
0
2.9k
Featured
See All Featured
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Odyssey Design
rkendrick25
PRO
2
730
A Tale of Four Properties
chriscoyier
163
24k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
360
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
Transcript
DBとSQLについて 株式会社福岡情報ビジネスセンター OT勉強会資料
DBについての基本的な知識
DB(データベース)とは? 検索や蓄積が容易にできるように整理された情報の集 まり。 通常はコンピュータによって実現されたものをさす。
DBの必要性 このようなことを防ぐ為、共有して使うデータは、 一元的に管理をする必要性がある。 ①顧客情報は支店ごとに管理している ②顧客は引越しをしたため、同じ会社の支店A⇒支店Bを利用しはじめる ③支店Bは顧客が支店Aでどのような取引をしたのか、支店Bに電話やメー ル、FAXで問い合わせる必要がある(契約内容、注文内容、クレーム対 応)
DB利用の利点 データの共有管理ができる データの取り出しが容易(並び変え等も) データとアプリケーションプログラムが分離しているため 特定の業務と切り離して管理できる データのアクセス制御やデータの矛盾が起きないように
管理する必要がある DBMS
DBMS(Database Management System) データベースを適切に使用するための管理を行ってくれるソフト ウェアが、「データベース管理システム」(Database Management System:DBMS)です。 ユーザーからのデータベースに対する要望は、必ずDBMSを介して
行われます。そのため、データを処理する前に、DBMSがユーザー のデータ利用の順番制御や権限確認を行ってくれます
DBモデルの種類 データベースモデルには大きく分けて 「階層型」 「ネットワーク型」 「リレーショナル型」
「NoSQL」 があります。 その中で、現在最も一般的に使用されているのは「リ レーショナルデータベース」(Relational Database:RDB) です。
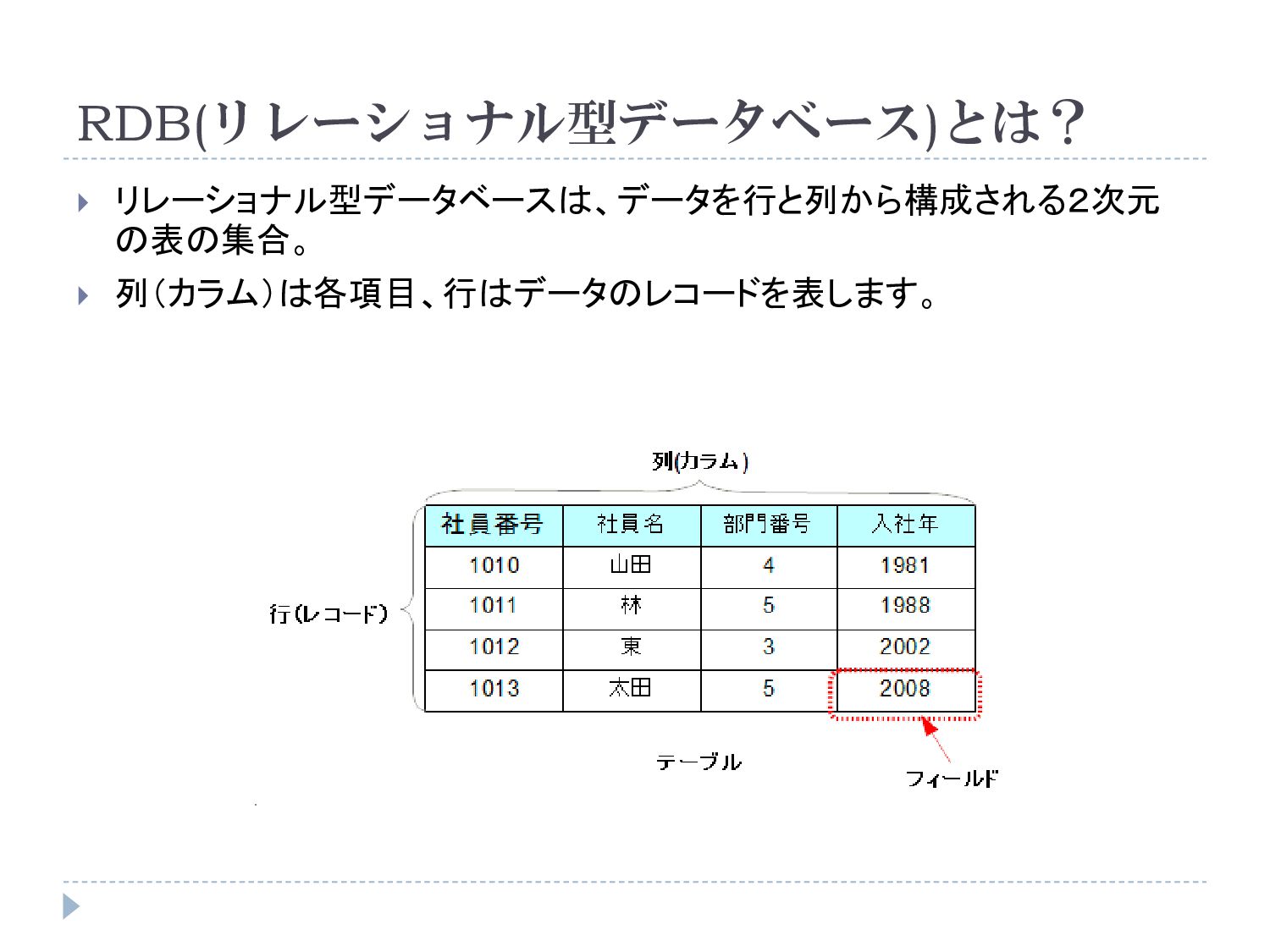
RDB(リレーショナル型データベース)とは? リレーショナル型データベースは、データを行と列から構成される2次元 の表の集合。 列(カラム)は各項目、行はデータのレコードを表します。
RDB(リレーショナルデータベース)の特徴 特徴 リレーションと二次元の表の集合 リレーショナルデータベースでは、すべてのデータを表形式で 表現します。表は列と行で構成され、列は必ず1つの意味を 持ちます ID 部門名
1 総務 2 経理 3 営業 ID 名前 生年月日 入社日 退職日 部門ID 1 佐藤 1994/03/03 2015/04/01 1 2 鈴木 1991/12/11 2012/04/01 1 3 田中 1979/01/01 2000/08/01 2010/07/31 2 リレーション(訳:関係、つながり) 部門 従業員
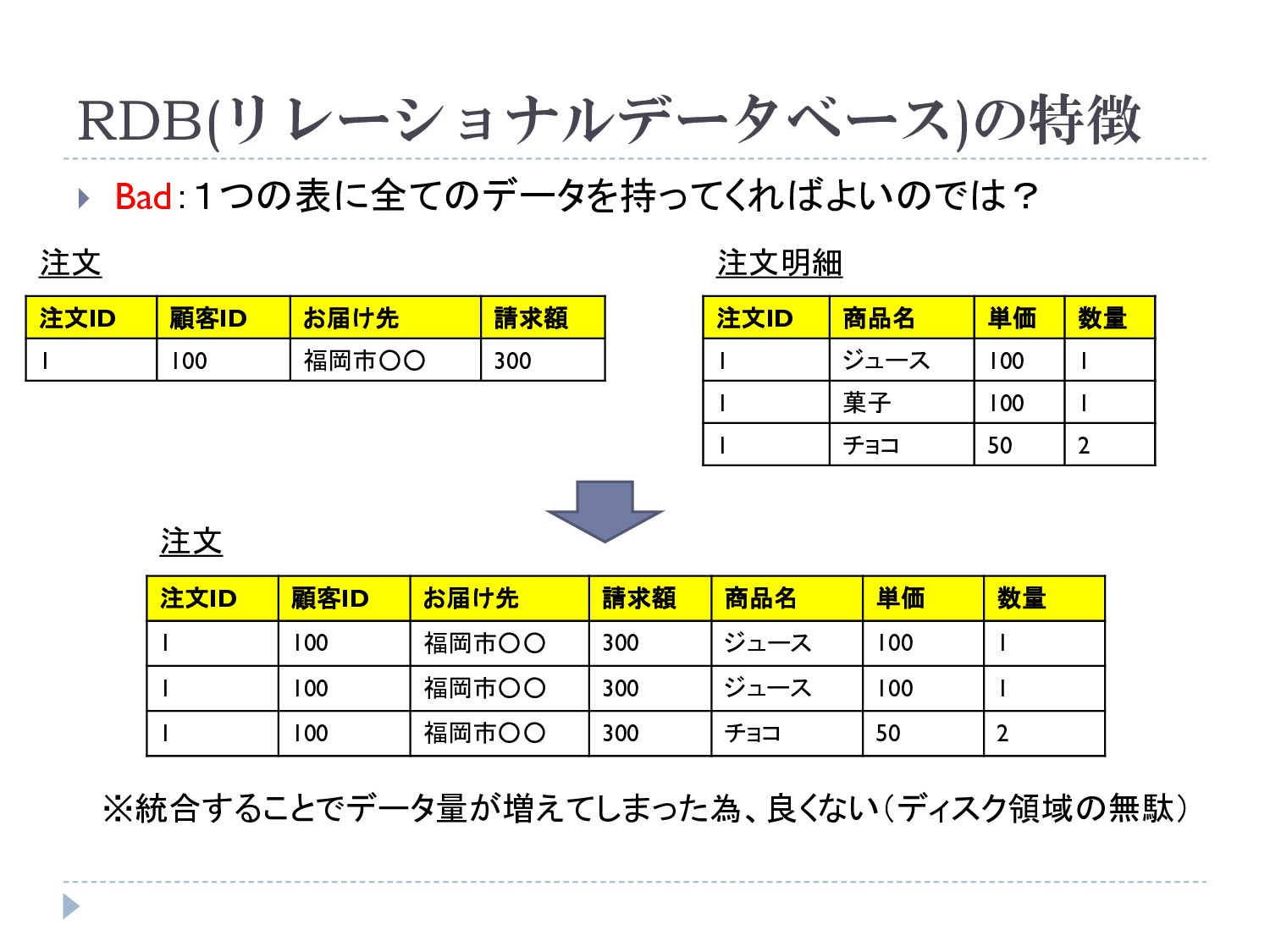
RDB(リレーショナルデータベース)の特徴 Bad:1つの表に全てのデータを持ってくればよいのでは? 注文ID 顧客ID お届け先 請求額 1 100 福岡市◦◦
300 注文ID 商品名 単価 数量 1 ジュース 100 1 1 菓子 100 1 1 チョコ 50 2 注文 注文明細 注文ID 顧客ID お届け先 請求額 商品名 単価 数量 1 100 福岡市◦◦ 300 ジュース 100 1 1 100 福岡市◦◦ 300 ジュース 100 1 1 100 福岡市◦◦ 300 チョコ 50 2 注文 ※統合することでデータ量が増えてしまった為、良くない(ディスク領域の無駄)
代表的なRDBMS リレーション型のDBのDBMSをRDBMSといいます。 代表的なRDBMSは以下のようなものがあります。 Oracle社のOracle Microsoft社のSQL Server IBM社のDB2 OSSのMySQL
PostgreSQL SQLite FBIでよく利用するのは、DB2、SQL Server、MySQLです。
代表的なRDBMS(Oracle) 商用のRDBとして初めてリリースされたデータベース 商用アプリケーション用データベースの中では、最大のシェア 値段が高いと言われているため、大手以外ではあまり見かけ ない サポート契約を途中からする場合、又は再開する場合にはそ
の空白期間にも料金が発生する
代表的なRDBMS(DB2) Oracle同様に長い歴史がある 大規模システムなどで使われている商用のRDBMS RDBを提唱したのはIBMだったが、商用としてリリースするの はOracleが先立った。 一昔前まではAS400などのオフコン上でしか動作しなかった
2015年にIBMCloudで利用出来るようになった(DB2 on cloud) ⇒通常のクラウドと一緒でハード面での心配もいらない。 ⇒IBMCloud上で構築するので導入も画一化できるはず ⇒使いどころがいまいち分からない
代表的なRDBMS(SQL Server) Windows Serverで構築している環境では高いシェアを有 している 環境がWINDOWSなので色々と扱いやすい(GUI) .Net系で構築された業務システムやWebシステムの
データベースとして利用されることが多い。
代表的なRDBMS(MySQL) OSSのDBの中では最も使われている代表的なRDBMS サンマイクロシステムズに買収される⇒サンマイクロシス テムズがOracleに買収される ライセンス元がOracle ライセンスが曖昧
⇒商用全てがアウトという人もいれば、受託開発はセーフで第三者に頒布し なければ大丈夫という人もいる よく似たMariadbというRDBMSも存在する(MySQLとあま り変わらない)
DBの選定方法 旧システムの有無 ⇒旧システムで何のDBを使用しているのか。 パッケージ化させるのか ⇒場合によっては商用のものを買う必要がある ⇒PostgreSQLは商用でも無料だが、MySQLなどはライセンスの 説明が書いてないので怪しい
使用する言語の指定 ⇒言語とDBの相性など(全く使用出来ないというわけではな い) (例)RPG-DB2、PHP-Mysql,PostgreSQL、.Net系-SQLServer
テーブル テーブルとは、表のことを表します。 行のことをレコード。列のことをフィールド(カラム)という。
DBの基本構造 データベースの中にスキーマという部屋があり、その中 にテーブル(表)が格納されているイメージ ※DBによって異なる(MySQLではスキーマ=データベース) データベース1 スキーマ1 テーブル1 テーブル2 テーブル3
テーブル4 スキーマ2 テーブル1 テーブル2 テーブル3 テーブル4 スキーマ3 テーブル1 テーブル2 テーブル3 テーブル4
テーブルのキー テーブルでは、レコードを一意に識別するためのフィールドとして、キーを 設定することができます。 【主キー】 ⇒レコードを一意に識別できるフィールドを主キーといいます。一意に表せる フィールドが複数ある場合は、1つのフィールドだけ主キーとして選びます。 他のキーは代替キー(代理キー)と呼ばれます。 主キーさえ指定すれば、 1つの行を特定できる
テーブルのキー 【複合キー】 ⇒1つのフィールドではなく、2つ以上のフィールドの組み合わせで1つのレ コードを識別できる場合、そのフィールドを組み合わせて主キーとして使 用できる。これを複合キーと呼ぶ。 社員名 生年月日 出身地 山田太郎 2000/4/15福岡
山田花子 2012/12/1福岡 山田太郎 2002/6/25福岡 山田次郎 2015/4/15福岡 複合キー 社員名だけの指定では、同姓 同名がいるため一意のレコード が識別できない。そのため、社 員名と生年月日を複合キーとし て定義している。
テーブルのキー 【外部キー】 ⇒あるテーブルに対して、他のテーブルの主キーをフィールドとしてもたせる。 そのもたせたフィールドを外部キーという。
フィールドの制約、データ型 フィールドには、格納されるデータの型の定義や制約をかけることができる 『代表的な型』 【数値型】 ⇒数値のためのデータ型。整数、浮動小数点、符号の有無などを設定 【文字列型】 ⇒アルファベット、記号、数字など任意の文字列のためのデータ型。 【日付・時刻型】 ⇒日付のみ、時刻のみ、日付と時刻、のように日付と時刻を入れる型。
【ブール値型】 ⇒真または偽のブール値を入れる型である。 【ビット型】 ⇒上記以外の、画像や音声、プログラムなどのデータを入れる型である。バイナリ型とも呼ばれ る。
フィールドの制約、データ型 フィールド制約 ⇒フィールドに設定できる値に制限を設ける。 制約 説明 NOT NULL NULLを設定できなくする UNIQUE 同じ値を設定できなくする
DEFAULT 値が設定されないときに、指定した値を初期値とする PRIMARY KEY 主キーとする(主キー制約) FOREIGN KEY 外部キーとする(外部キー制約) 主キー制約…一意である。NULLを許容しない。 外部キー制約…参照先のカラムにある値しか設定できなくなる。
テーブル設計時に気をつけるポイント ・基本的には正規化を行う。
非正規系⇒第1正規系 ・繰り返している項目の排除
第1正規系⇒第2正規系 ・主キー以外の項目が、主キーの一部の要素だけで決まるものを分 割する
第2正規系⇒第3正規系 ・主キー以外の項目で依存関係を持っているものも分割する
INDEX(索引) インデックス概要 ・目的のデータを取得する時間を短くすることが出来る ・インデックスを張っていない状態ではフルテーブルスキャンが行われている。 ・インデックスを使用することでデータベースの容量は増える。 インデックスの種類 ・複合インデックス ⇒1つのテーブルに複数のインデックスを張る。
・ユニークインデックス ⇒データの登録時にデータがユニークであるかを確認するためのインデック ス
トランザクション トランザクションとは、データベースにおいて「作業を完了する ための一連の作業単位」のことです。 トランザクションは、ユーザーが明示的にSQLのCOMMITコマ ンドを実行することで終了します。 COMMITコマンドを実行してトランザクションを終了すると、そ のトランザクションで行った変更内容が完全にデータベース
に確定されます。 逆にいうと、COMMIT前のトランザクションの変更内容は未 確定のため、ROLLBACKコマンドで取り消すことが可能です。
トランザクション 例) ある工場では、データベース内の在庫表と注文表を使用して、製品 の受発注を管理しています。 新たに、「2008年5月6日にD社から製品Aについて50個の注文があり販 売した」としたら、在庫表と注文表はSQLで以下のように変更します 処理の流れ 1.トランザクション開始(BeginTransaction)
2.注文表に行を追加(INSERT) 3.在庫表の行を変更(UPDATE) 4.トランザクションコミット(CommitTransaction) トランザクション処理の重要性 ・3.の在庫表をUPDATEしているときに停電してしまっ た。 ・このとき、データベースを再起動して、2.の注文表の INSERTだけDBに反映されてしまっていたらまずい。 (中途半端な状態だから) ・そのような状態にならないために、トランザクション 処理が必要になってくる (コミットしないとDBに反映されないため中途半端な DBのデータができない)
SQLについての基本的な知識
SQL(Structured Query Language)とは? RDBMSに対してのすべての処理は、SQLという言語を使 用します。 テーブルのデータの変更や、テーブルの作成などもSQL で行います。
DBを操作するための言語のこと
要素 説明 DML(データ操作) SELECT(データの検索)、INSERT(データの追加)、 UPDATE(データの更新)、DELETE(データの削除) DDL(データ定義) CREATE(表の作成)、ALTER(表の変更)、DROP(表の削除) トランザクション制御 COMMIT(データ変更の確定)、ROLLBACK(データ変更の取消) DCL(データ制御)
GRANT(ユーザ権限の追加)、REVOKE(ユーザ権限の削除) SQL(Structured Query Language)とは? SQLは処理の内容によって4つに分類されます。
CREATE(テーブル作成) テーブル作成するときは、CREATE文を使用します。 例) CREATE TABLE KT_EMP ( EMP_NO
VARCHAR(4) NOT NULL DEFAULT '' ,EMP_NM VARCHAR(40) NOT NULL DEFAULT ‘’ ,BIRTH_DT SMALLINT NOT NULL DEFAULT 0 ,SEX_FLG VARCHAR(6) NOT NULL DEFAULT '‘ ,ENTRY_DT INT NOT NULL DEFAULT 0 ,RETIRE_DT SMALLINT NOT NULL DEFAULT 0 , DELETE_FLG SMALLINT NOT NULL DEFAULT 0 ,PRIMARY KEY(EMP_NO) ); テーブル名 列名 データ型 制約 主キー定義
DROP(テーブル削除) テーブルを削除するときは、DROP文を使用します。 書き方) DROP TABLE テーブル名;
ALTER(テーブル列操作) テーブルの列の変更、削除、追加などを行うときは、ALTER文を使用します。 列 変更 書き方) ALTER TABLE テーブル名
ALTER COLUMN 列名 データ型 制約 列 削除 書き方) ALTER TABLE テーブル名 DROP COLUMN 列名 列 追加 書き方) ALTER TABLE テーブル名 ADD COLUMN 列名 データ型 制約
SELECT(テーブルデータ検索) テーブルのデータを検索するときは、SELECT文を使用し ます。 基本的な書き方) SELECT 列名 FROM テーブル名 WHERE
条件 GROUP BY グループ化列 HAVING 条件 ORDER BY ソート列 ソート順
列と表の指定(SELECT FROM) 以下のような成績表テーブルがある。 学生番号 氏名 クラス 国語 数学 英語 11001山田
太郎 A組 65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作1.出席番号と氏名を取り出す SELECT 学生番号, 氏名 FROM 成績表 学生番号 氏名 11001山田 太郎 11002田中 次郎 11003中村 花子 11004村山 三郎 ・取得したい列名を書く ・複数ある場合は「,」区切りで書く ・テーブル名
列と表の指定(SELECT FROM) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎
A組 65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作2.すべての成績(すべてのデータ)を取り出す SELECT * FROM 成績表 ・テーブルのすべての列がほしい 場合は「*」を使用する 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎 A組 65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53
列と表の指定(SELECT FROM) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎
A組 65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作3.学籍番号と合計点(国語と数学と英語の和)を取り出す SELECT 学生番号,(国語 + 数学 + 英語) AS 合計点 FROM 成績表 学生番号 合計点 11001 179 11002 244 11003 218 11004 201 ・数値ならば「列名 + 列名」で和を出力することができる ・「AS 新列名」で、新列名としてデータを取得することができる
条件の指定(WHERE) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎 A組
65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作4.B組の学生の国語の点を取り出す SELECT 学生番号,氏名,国語 FROM 成績表 WHERE クラス = ‘B組’ ・WHERE句に条件を指定する ・文字列を指定する場合は、「’」で囲む 学生番号 氏名 国語 11004村山 三郎 60
条件の指定(WHERE) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎 A組
65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作5.国語と英語がともに70点以上を取り出す SELECT 学生番号,氏名 FROM 成績表 WHERE 国語 >= 70 AND 英語 >= 70 ・条件には、「=,>=,>,<=,<,!=,<>」を指定することができる ・複数の条件をANDまたはORで結びつけることができる 学生番号 氏名 11002田中 次郎 11003中村 花子
ソートの指定(ORDER BY) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎
A組 65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作6.A組の学生の国語の点が高い順に学生番号と氏名を取り出す SELECT 学生番号,氏名 FROM 成績表 WHERE クラス = ‘A組’ ORDER BY 国語 DESC ・ORDER BY句に並び替えに使用する列を書く。 ・複数の列を指定した場合は、先に指定した列から順に並び替えを判断する ・列の後ろに「ASC」で昇順、「DESC」で降順を指定できる(何も付けないと昇順) 学生番号 氏名 11003中村 花子 11002田中 次郎 11001山田 太郎
関数の指定(SUM,AVG,MAX,MIN,COUNT) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎 A組
65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作7.成績表の学生人数を取り出す SELECT COUNT(*) AS 人数 FROM 成績表 ・COUNT(*)で該当する行の件数を取得することができる 人数 4
関数の指定(SUM,AVG,MAX,MIN,COUNT) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎 A組
65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作8.国語の平均点を取り出す SELECT AVG(国語) AS 国語平均 FROM 成績表 ・AVG(列名)で列名の平均値を取得することができる ・他にもSUM(列名)で合計。MAX(列名)で最大値。MIN(列名)で最小値を取得す ることができる 国語平均 73.5
グループ化(GROUP BY) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎
A組 65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作9.成績表のクラス毎の学生人数を取り出す SELECT クラス, COUNT(*) AS 人数 FROM 成績表 GROUP BY クラス ・GROUP BY句に書いた列名で、同一の値を持つ行のグループができる。 ・グループ化した列と、関数以外の列はSELECT句で指定できない クラス 人数 A組 3 B組 1
グループ化(GROUP BY) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎
A組 65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作10.国語の平均点が70以下のクラスを取り出す SELECT クラス FROM 成績表 GROUP BY クラス HAVING AVG(国語) <= 70 ・グループを条件で絞り込むならば、HAVING句を使用する。 クラス B組
条件指定に関する応用(BETWEEN) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎 A組
65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作11.英語が70点以上80点未満の学生を取り出す SELECT 学籍番号, 氏名 FROM 成績表 WHERE 英語 BETWEEN 70 AND 79 ・BETWEEN 下限値 AND 上限値 という形式で下限値から上限値の範囲を指 定できる(下限値、上限値は範囲に含まれる) 学生番号 氏名 11001山田 太郎 11003中村 花子
条件指定に関する応用(LIKE) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎 A組
65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作12.名前に山を含む学生の氏名を取り出す SELECT 学籍番号, 氏名 FROM 成績表 WHERE 氏名 LIKE ‘%山%’ ・列名 LIKE ‘文字列パターン’で、特定の文字列を含むという条件にできる ・文字列パターンは、例えばABCという文字を含むという指定にしたい場合は、 %ABC%のように記述し、ABCから始まる文字列の場合には、ABC%にする 学生番号 氏名 11001山田 太郎 11004村山 三郎
その他の条件指定(IN,IS NULL) IN句 ⇒列名 IN (値1、値2、値3・・・)のように記述する。 ⇒値1、値2、値3のいずれかの値に一致するものを取得する。 ⇒列名 = 値1
OR 列名 = 値2 OR 列名 = 値3 と同じ意味 IS NULL ⇒列名 IS NULL のように記述する。 ⇒NULL値であるものを取得する。 ⇒NULL値でないものを取得するにはIS NOT NULLと記述する。
重複の削除(DISTINCT) 学生番号 氏名 クラス 国語 数学 英語 11001山田 太郎 A組
65 42 72 11002田中 次郎 A組 77 85 82 11003中村 花子 A組 92 48 78 11004村山 三郎 B組 60 88 53 成績表 操作13.クラスの一覧を取り出す SELECT DISTINCT クラス FROM 成績表 ・取り出した結果に重複がある場合に、重複を除き1つだけ取り出す場合には DISTINCTを使用する。 クラス A組 B組
テーブルの結合 複数のテーブルを結合するときには、JOINで結合するこ とができる。 JOINの種類として主に ・INNER JOIN ・LEFT (OUTER)
JOIN ・RIGHT (OUTER) JOIN の3つがある。 ※他(FULL JOIN,NATURAL JOIN,CROSS JOIN) ※DBによって異なる
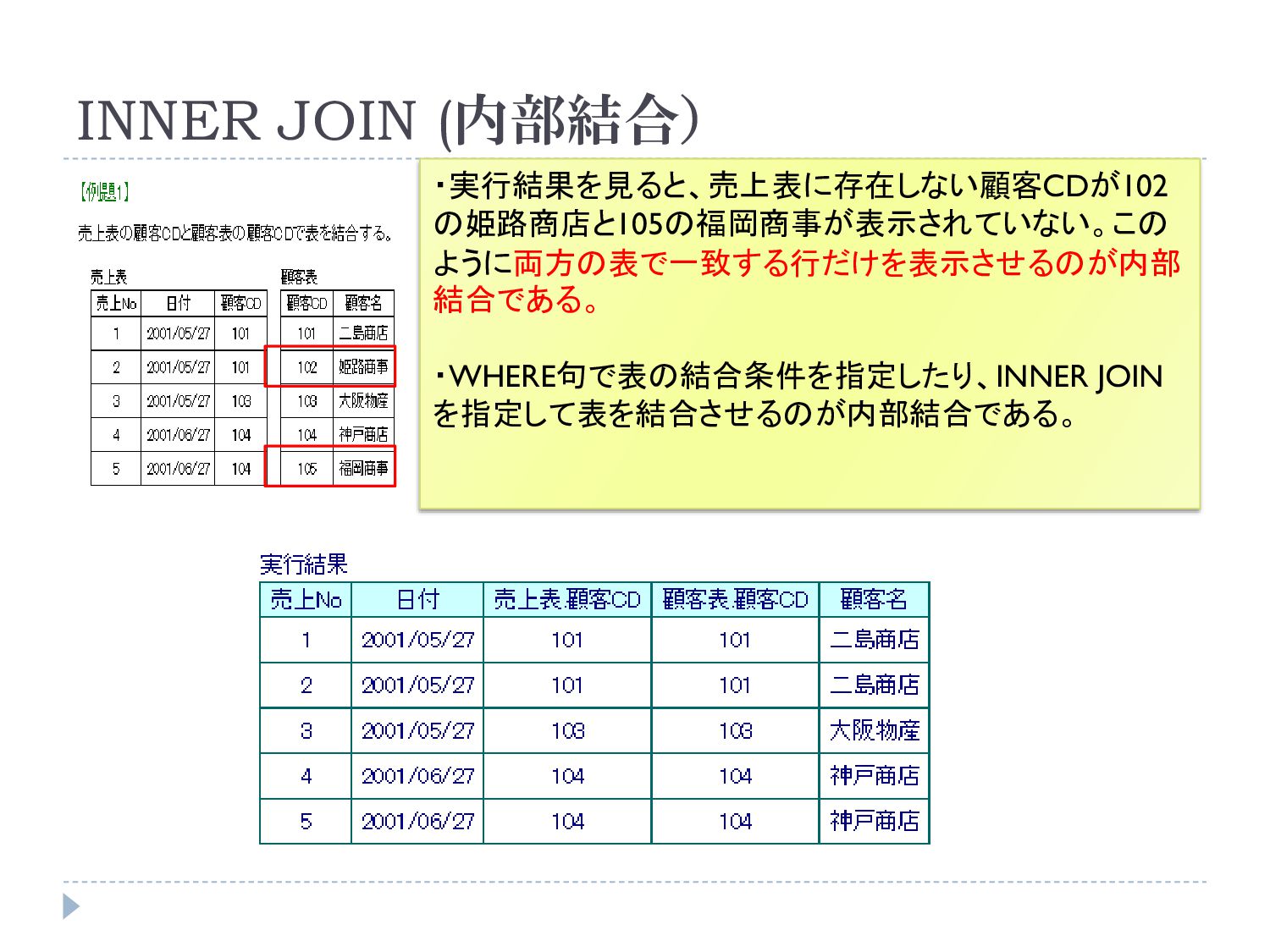
INNER JOIN (内部結合) INNER JOIN(内部結合)は、指定された両方のテーブル に存在するものだけが抽出される
INNER JOIN (内部結合) ・実行結果を見ると、売上表に存在しない顧客CDが102 の姫路商店と105の福岡商事が表示されていない。この ように両方の表で一致する行だけを表示させるのが内部 結合である。 ・WHERE句で表の結合条件を指定したり、INNER JOIN を指定して表を結合させるのが内部結合である。
LEFT JOINとRIGHT JOIN (外部結合) LEFT JOINとRIGHT JOINは、左右いずれかのテーブル を優先させたいときに指定する。
LEFT JOIN 左側に指定されたテーブルのすべての行が表示される RIGHT JOIN 右側に指定されたテーブルのすべての行が表示される
LEFT JOINとRIGHT JOIN (外部結合) ・LEFT JOINを指定しているので、左 側の顧客表のすべての行が表示さ れている。 ・売上表において該当するデータが ない部分は、NULLが表示されてい
る。
JOINの書き方 INNER JOIN FROM テーブルA INNER JOIN テーブルB ON
テーブルA.カラム = テーブルB.カラム LEFT JOIN FROM テーブルA LEFT JOIN テーブルB ON テーブルA.カラム = テーブルB.カラム 結合条件 結合条件
SELECT(テーブルデータ検索) SELECTでデータ抽出するときの、SQL文の考え方(ナ カムラ的) 1.取得結果は、表形式として取得されることを意識する。 2.取得したい項目(カラム)を洗い出す。(取得したい表の形をはっきり させる) 3.取得したい項目をどのテーブルから取得するかを洗い出す。 (合計などの場合、どのテーブルのどの項目を合計するなど) 4.取得結果の件数と同じ件数になると思われるテーブルをメインテー
ブルと考える。 5.メインテーブルに対して、3で洗いだしたテーブルを結合する。 6.抽出条件を考える(WHERE句) 7.合計、最大件数などがある場合は、GROUP化などなど。。。
INSERT (行の追加) テーブルにデータを1行挿入するためのSQL文をINSERT文と呼ぶ。 一般形式) INSERT INTO テーブル名 VALUES(値リスト) ・値リストには、挿入するデータを列の順番にカンマで区切って指定する。
・値リストの値の数と、列の数は一致しなければならない 列指定形式) INSERT INTO テーブル名(列名リスト) VALUES(値リスト) ・列名リストには、値をセットしたい列名をカンマで区切って指定する。 ・値リストには、列名リストに列挙した列にセットする値を列名リストの順番にカンマで 区切って指定する。 ・値が指定されなかった列(列名リストにない列)は、列のデフォルト値が入る。
UPDATE (行の更新) テーブルにあるデータの、条件を満たす行の列を変更するた めのSQL文をUPDATE文と呼ぶ。 一般形式) UPDATE テーブル名 SET 列名
= 値 WHERE 検索条件 ・SET句に変更する列名と値を指定する ・複数項目変更する場合は、カンマ区切りで指定する ・検索条件を省略した場合、すべての行の値が変更される。 ・検索条件がある場合は、その検索条件に一致する行のみが 変更される
DELETE (行の削除) テーブルにあるデータの、条件を満たす行を削除するた めのSQL文をDELETE文と呼ぶ。 一般形式) DELETE FROM テーブル名 WHERE
検索条件 ・検索条件を満たす行をテーブルから削除する ・検索条件を省略した場合、テーブルのすべての行が削除 される
実践
前準備 A5:SQL Mk-2を導入 → 汎用SQL開発ツール DBの作成 DBのユーザー作成
テーブルの作成 データの作成 A5:SQL Mk-2からDBへアクセス確認 テーブル定義書確認
概要確認 テーブル定義書確認
実践問題 Q.1 全てのアカウントの一覧を取り出す 取得カラムは、ID,名前_姓,メールアドレスとする。 Q.2 全てのアカウントの一覧を取り出す 取得カラムは、全てとする。 Q.3 全ての注文の税込合計金額を取り出す 取得カラムは、ID,税込合計金額とする
実践問題 Q.4 名称が「メーカーD」のメーカーを取り出す 取得カラムは、全てとする。 Q.5 合計金額(税抜)が500000以上、600000以下の注文を取り出す。 取得カラムは、ID,合計金額(税抜)とする Q.6 名称が「メーカーD」または「メーカーG」のメーカーを取り出す 取得カラムは、全てとする。
実践問題 Q.7 名称が「メーカーD」または「メーカーG」または「メーカーI」 のメーカーを取り出す。取得カラムは、全てとする。 Q.8 名称が「メーカーD」以外のメーカーを取り出す 取得カラムは、全てとする。 Q.9 全ての商品を単価(税抜)が高い順に取り出す 取得カラムは、ID,名称,単価(税抜)とする
実践問題 Q.10 全ての商品を単価(税抜)が安い順に取り出す 取得カラムは、ID,名称,単価(税抜)とする Q.11 単価(税抜)が10000以下の商品を単価(税抜)が高い順に 取り出す。取得カラムは、ID,名称,単価(税抜)とする Q.12 顧客の人数を取り出す 取得カラムは、人数とする
実践問題 Q.13 顧客の平均年齢を取り出す 取得カラムは、平均年齢とする Q.14 全ての注文の総合計金額(税抜)を取り出す(全ての注文金 額を足した値)。取得カラムは、総合計金額(税抜)とする Q.15 商品の中で一番高い単価(税抜)を取り出す 取得カラムは、最高単価(税抜)とする
実践問題 Q.16 商品の中で一番安い単価(税抜)を取り出す 取得カラムは、最安単価(税抜)とする Q.17 注文が2018/1にされた注文の総合計金額(税抜)を取り出す(全 ての注文金額を足した値) 取得カラムは、総合計金額(税抜)とする Q.18 メーカー毎の商品数を取り出す
取得カラムは、メーカーID、商品数とする
実践問題 Q.19 平均商品単価が30000以上のメーカーを取り出す 取得カラムは、メーカーIDとする Q.20 単価(税抜)が50000以上100000未満の商品を取り出す 取得カラムは、全てとする 条件指定に、BETWEENを使用すること Q.21 名前の姓に「中」を含む顧客を取り出す
取得カラムは、全てとする
実践問題 Q.22 名前の姓が「中」からはじまる顧客を取り出す 取得カラムは、全てとする Q.23 名前の姓が「本」でおわる顧客を取り出す 取得カラムは、全てとする Q.24 名前の姓が「中村」「田中」の顧客を取り出す 取得カラムは、全てとする
条件指定にINを使用すること
実践問題 Q.25 備考がNULLの注文を取り出す 取得カラムは、全てとする Q.26 備考がNULLではない注文を取り出す 取得カラムは、全てとする Q.27 アカウントの名前の姓の一覧を取り出す 取得カラムは、名前_姓とする
SQLにDISTINCTを使用すること
実践問題 Q.28 商品の名称、商品区分名の一覧を取り出す 取得カラムは、商品の名称、商品区分名とする Q.29 商品の名称、商品区分名、メーカー名の一覧を取り出す 取得カラムは、商品の名称、商品区分名、メーカー名とす る
実践問題 Q.30 一度でも注文されたことがある商品の一覧を取り出す 取得カラムは、商品の名称とする 取得結果に重複はなしとする(同じ商品が複数存在しない ように) メインテーブルは、商品とする Q.31 一度も注文されたことがない商品の一覧を取り出す 取得カラムは、商品の名称とする
実践問題 Q.32 顧客毎の注文回数を取り出す 取得カラムは、顧客のID,顧客の名前_姓,注文回数とする 一度も注文したことがない顧客は取り出さなくてよい Q.33 性別毎の今までの注文回数を取り出す 取得カラムは、性別ID,性別の名称、注文回数とする 一度も注文したことがない性別は取り出さなくてよい Q.34
2018/1にされた注文で、1回の注文の明細が5件以上ある注文を取り 出す 取得カラムは、注文のID、注文日、明細件数とする
実践問題 Q.35 2018/1~2019/4に注文されており、支払方法がクレジットの注文で、 以下の情報が乗っている注文明細一覧を取り出す 注文ヘッダID 注文日 顧客名前_姓 性別名 商品名 商品区分名
メーカー名 単価(税抜) 数量 税込本体価格 取り出すデータの順序として、顧客名前_姓の昇順、注文日の昇順、商品名の昇順とする
サブクエリ クエリ内のクエリのこと SELECT文の中にSELECT文を書くこと SELECT句、FROM句、WHERE句で使用することができる
サブクエリ(SELECT句) SELECTで取得するラカムの一つとして、SELECT文を使う 例)顧客の一覧を取得。取得カラムは、ID、名前_姓、年齢、 平均年齢とする SELECT 顧客.ID, 顧客.名前_姓, 顧客.年齢, (SELECT
avg(年齢) FROM 顧客) as avg_age FROM 顧客;
サブクエリ(FROM句) SELECTした結果をFROM句で使用する 例)メーカー毎の商品数を取得する。取得カラムは、メー カーID、商品数 SELECT 商品.メーカーID, 商品.商品数 FROM (
SELECT メーカーID, count(*) as 商品数 FROM 商品 GROUP BY メーカーID ) as 商品;
サブクエリ(WHERE句) WHERE句の条件の値にSELECT文を使用する 例)メーカーIDが1の商品を注文している注文の一覧を取 得。取得カラムは、注文ID SELECT DISTINCT 注文ID FROM 注文明細
WHERE 商品ID IN( SELECT ID FROM 商品 WHERE メーカーID = 1 );
実践問題 Q.36 注文の一覧を取得する。 取得カラムは、ID、顧客ID、注文日、注文商品平均単価(すべ ての注文商品の平均単価) SELECT句でサブクエリを使用すること Q.37 注文の一覧を取得する。 取得カラムは、ID、顧客ID、注文日、注文商品数(注文毎の商 品数)
FROM句でサブクエリを使用すること ※JOIN使います
実践問題 Q.38 20代の顧客が注文した一覧を取得。 取得カラムは、ID、顧客ID、注文日 WHERE句でサブクエリを使用すること Q.39 顧客毎の注文回数を取得する。 取得カラムは、ID(顧客)、名前_姓、注文回数 ※1回も注文がない顧客も表示すること ※1回も注文がない場合、0と表示すること(ググってよし)
実践問題 Q.40 2018/2に注文したことがあり、メーカーA(メーカーID:1) の商品を注文したことがあり、今までの注文で1000000円 以上(税抜)の注文をしたことがある顧客を取得。 取得カラムは、ID(顧客)、名前_姓、総合計注文金額(税 抜) ※2重以上のサブクエリ使ってもよい ※ググってよい
こぼれ話
Q.良いSQL文を書くコツ 短いSQL文というよりは、見た人がわかりやすい(可読性が 高い)SQL文を目指そう。 可読性が高くなるための工夫 1.コメント多用(抽出結果、サブクエリの説明) 2.あまりにも複雑になる場合、アプリケーション側の処理で結 果を求めるという選択もあり。(速度とのかねあい) 3.
SQLが整形されている 4. ANDやORを使用する時に括弧で囲む 5. INDEXの恩恵を受けれないSQLを使用しない(IN句等) 6.NOTや<>などの否定形を多用しない。
Q.SQLやりがちなミス 1.VARCHAR型とCHAR型の値の違い VARCHAR型 = 可変長 CHAR型 = 固定長 CHAR型は固定長のため、例えばCHAR(10)のカラムに、 ‘12345’という値を入れると’12345
’という風に10バイト になるように半角スペースが入る。そのため、SELECTで取得 した値には、半角スペースが入っていることに注意。 ※WHERE句で検索するときは、半角スペースは考慮する 必要はない
Q. DBの種類ごとに注意点があれば知りたいで す。 いくつか種類ごとに違うところをご紹介 ・連番を振るフィールド制約 MySQL :AUTO_INCREMENT SQLServer :IDENTITY Oracle
:存在しない。SEQUENCE,TRIGERを利用 ※Oracle 12 cからIDENTITYが使用できるようになった ・SELECTでのAS句 Oracleでは、テーブルのリネームにAS句は使用できない ・VIEW MySQLでは、VIEWにサブクエリが使用できない
Q. DBの種類ごとに注意点があれば知りたいで す。 ・VARCHARの定義 VARCHAR(n) MySQL :nには文字数を指定する SQLServer :nにはバイト数を指定する Oracle
: nにはバイト数を指定する ・NULLと空文字(‘’)の扱い MySQL :違うものとして扱う SQLServer :違うものとして扱う Oracle :どちらもNULLとして扱う などなど違いは、まだまだたくさんある。
Q. 知ってたら得するかも ◦例をパワポ内に書けないので参考記事。 ◦バッチ処理や保守運用時のリカバリー対応で役に立つ ①SELECTした結果をINSERT https://qiita.com/ques0942/items/acfdd5382c638580ce0b ②Joinした結果をUPDATE https://qiita.com/atwata/items/8ccb240ca450de4a6651 ③Joinした結果をDELETE https://qiita.com/atwata/items/cb2ca951db7852a48d22
Q. SQLでデータ取得が遅いときの対処方法の考 え方。 対処方法 ①SQL文をチューニングする ②INDEXを張る ③スペックを上げる ④テーブル構成自体を変える 他の部分への影響や、修正範囲を考えた場合、 番号順に対処方法をためしたほうがいい。
Q. SQLでデータ取得が遅いときの対処方法の考 え方。 ①SQL文をチューニングする 1.複雑なSQLの場合は、ボトルネックになっている箇所を特定する。 ⇒SQLの一部のみ実行していって、この部分を追加したら遅くなるというところを 特定 2.INNER JOIN と
LEFT JOIN どちらでもいい結合の場合は、LEFT JOINに変更 ⇒絶対ではない 3.結合前にデータを絞りこむ ⇒結合後にWHERE句で絞り込んでいる場合、結合するときに無駄なデータに結 合していることになる(取得不要のデータにまで結合をしている)ので、無駄な 時間が掛ってしまう。そのため、サブクエリで結合前に絞り込んで、結合する と早くなることがある。
Q. SQLでデータ取得が遅いときの対処方法の考 え方。 4.INDEXが使用されないようなSQLを多用しない ⇒IN、NOT IN 少量なら問題ないが、IN句で指定しすぎると遅くなる 引数は左から順番に評価するので、ヒットしやすそうなキーを一番左に 持ってくると多少マシになる。 EXISTS句でも代用可能ならIN句ではなくEXISTS句を使用する
⇒中間一致、後方一致の条件指定(LIKE検索) LIKE ‘%AAA%’、 LIKE ‘%AAA’ ⇒INDEXが張られている列に対しての関数使用やIS NULLの使用
Q. SQLでデータ取得が遅いときの対処方法の考 え方。 ②INDEXを張る 1.ボトルネックになっているテーブルに対して、INDEXを張る。検索キーになっている 項目に対して張る。 ⇒抽出条件の指定の仕方によっては、インデックスが利かないので注意 ・抽出項目にTRIMなどの命令を使ったあとに条件指定 ・インデックスに登録した項目の順番どおりに条件指定しないなど ③DBのスペックを上げる(かなりの効果が期待できる)
1.サーバ自体のスペックを上げる ⇒月額料金が変わる場合があるので最終手段(顧客に要相談) 2.DBサーバが使用するメモリの使用量の限界を引き上げる ⇒他の箇所に影響が出ないように気をつける(DBサーバとWebサーバが同一サー バ上にいる場合などは特に気を使うこと) ④テーブル構成自体を変える 1.設計からダメだったってことで、テーブル構成を変える。 ⇒プロジェクト序盤ぐらいでしか出来ない。基本的には①~③で解決させる。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}