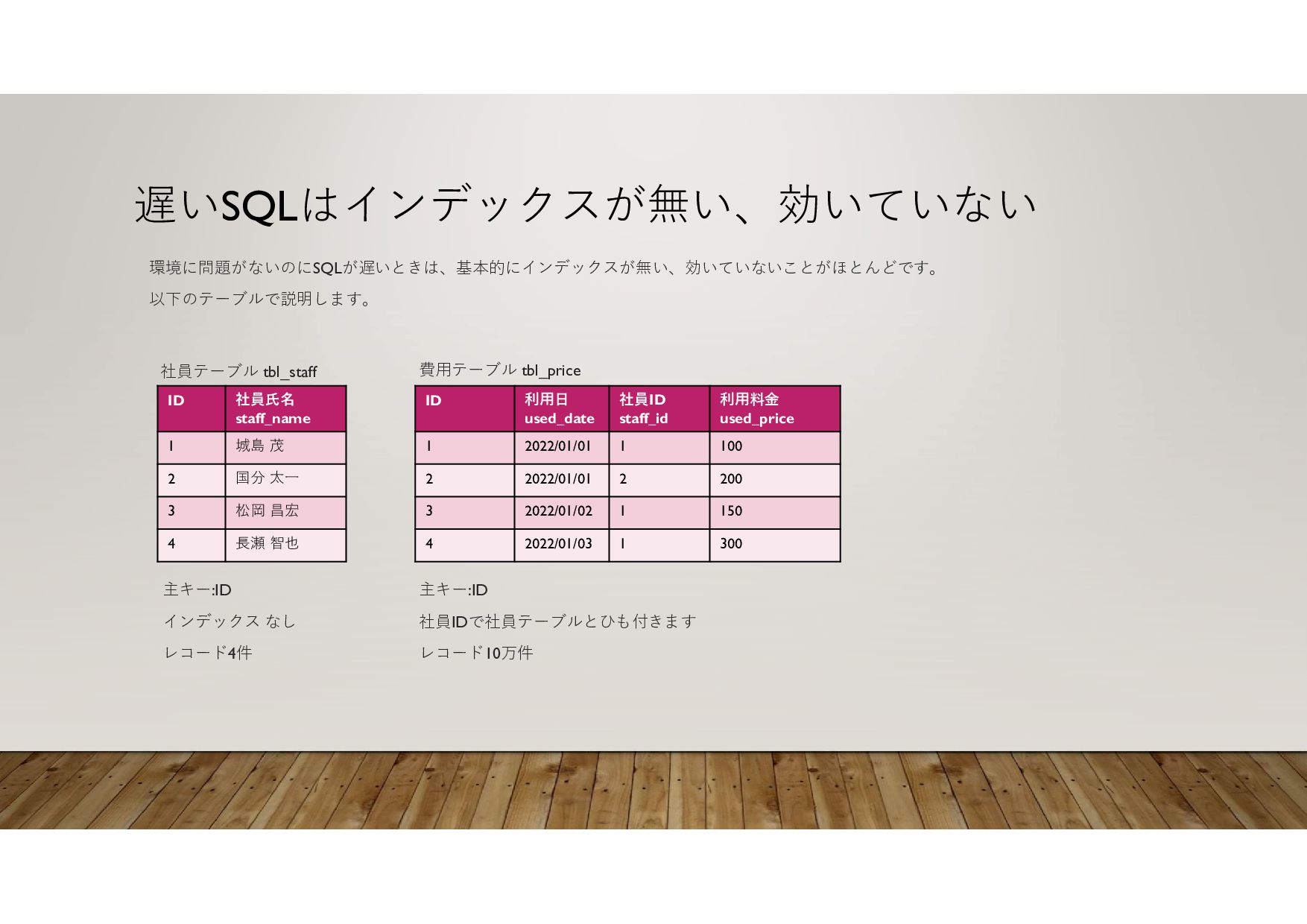
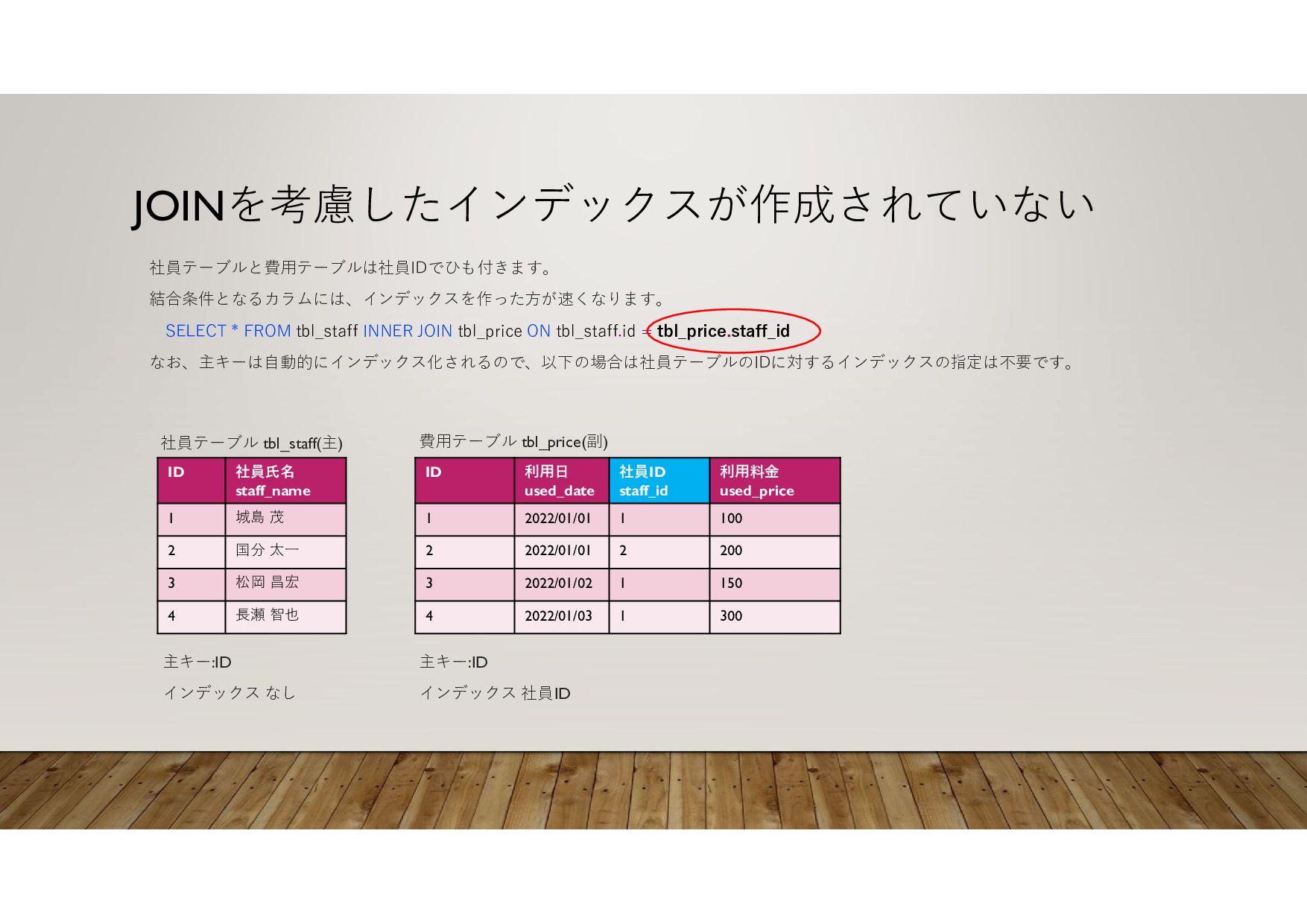
2022/01/01 1 200 B 2022/01/01 2 150 A 2022/01/02 3 300 A 2022/01/03 4 200 A 2022/12/31 99997 100 B 2022/12/31 99998 400 A 2023/01/01 99999 350 B 2023/01/01 100000 10万件のレコードがあるテーブルで、利用日、利用者で検索を行った場合 SELECT * FROM table WHERE 利用日 = ‘2022/12/31’ AND 利用者 =‘A’ インデックスがなければ1件目から10万件目までを全検索して該当データ を特定して抽出します。時間がかかります。 利用日と利用者でインデックスが作成されている場合は、該当データに 絞った抽出が可能です。速いです。 インデックスがあれば 範囲を絞った検索ができる インデックスがないと 最初から最後まで検索する
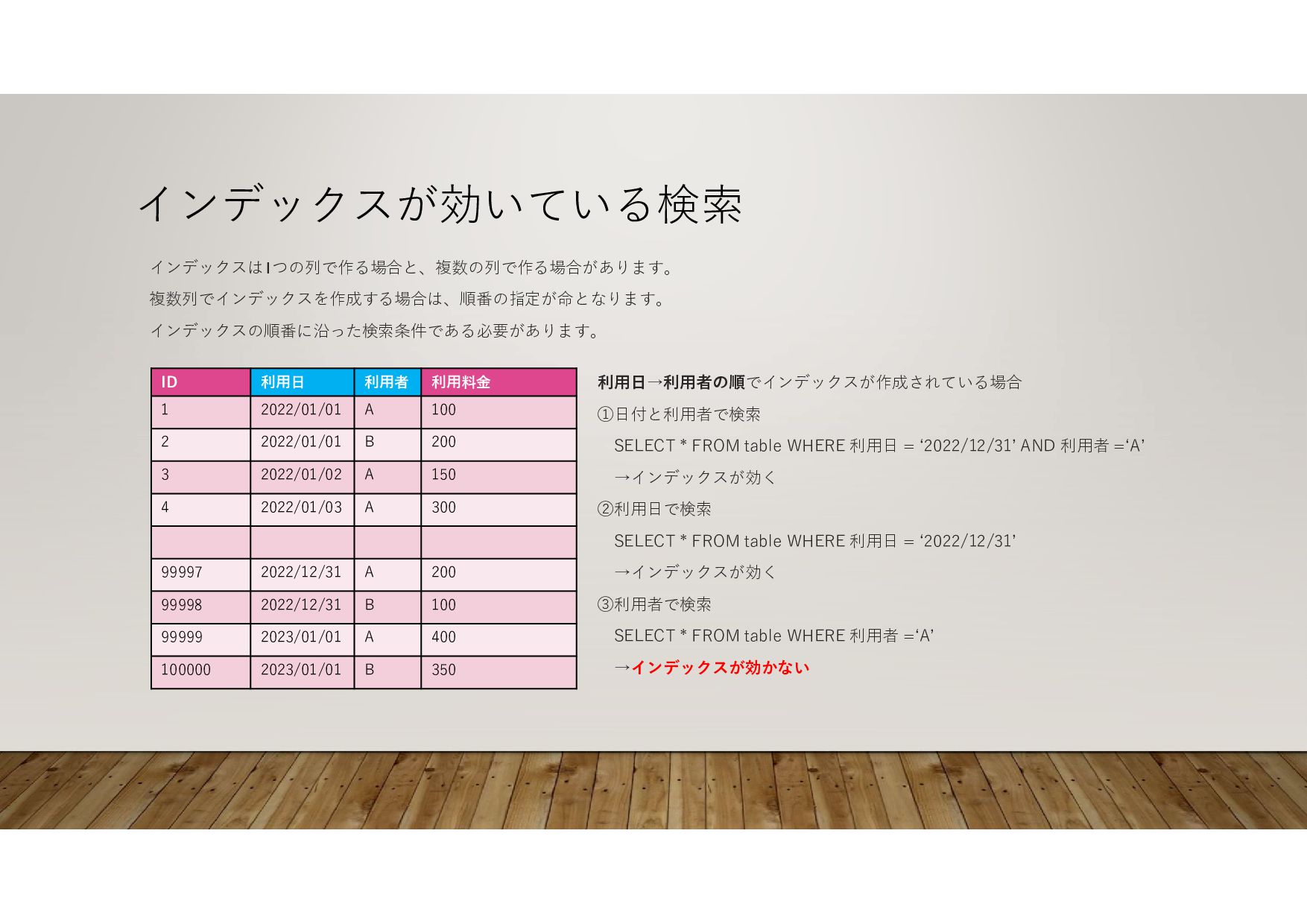
2022/01/01 2 150 A 2022/01/02 3 300 A 2022/01/03 4 200 A 2022/12/31 99997 100 B 2022/12/31 99998 400 A 2023/01/01 99999 350 B 2023/01/01 100000 インデックスが効いている検索 インデックスは1つの列で作る場合と、複数の列で作る場合があります。 複数列でインデックスを作成する場合は、順番の指定が命となります。 インデックスの順番に沿った検索条件である必要があります。 利用日→利用者の順でインデックスが作成されている場合 ①日付と利用者で検索 SELECT * FROM table WHERE 利用日 = ‘2022/12/31’ AND 利用者 =‘A’ →インデックスが効く ②利用日で検索 SELECT * FROM table WHERE 利用日 = ‘2022/12/31’ →インデックスが効く ③利用者で検索 SELECT * FROM table WHERE 利用者 =‘A’ →インデックスが効かない
‘2022/12/31’ OR 利用料金 = 250 ← 利用料金はインデックス化されていない ・LIKE検索、ただし書き方による 先頭一致 LIKE ‘ABC%’ →インデックスが効く、ただし文字ABCの該当範囲までをフェッチして、フェッチした中を全検索 含む LIKE ‘%ABC%’ 、後方一致 LIKE ‘%ABC’ →インデックスが効かない ・カラムで演算、関数を行って検索した場合(ただし右辺での演算はOK) SELECT * FROM table WHERE 利用料金 * 1.1 >= 220 ← 効かない SELECT * FROM table WHERE 利用料金 >= 220 / 1.1 ← 効く SELECT * FROM table WHERE DATE_FORMAT(利用日, ‘%Y%m’) = ‘202201‘ ← 効かない SELECT * FROM table WHERE 利用日 BETWEEN ‘2022/01/01’ AND ‘2022/01/31’ ← 効く ・否定形検索 日付 <> ‘2022/12/31’ ・IS NULL検索、IS NOT NULL検索 (DBによってはインデックスが効かないそうです。MySQLは効くそうです。) TRIM なども注意
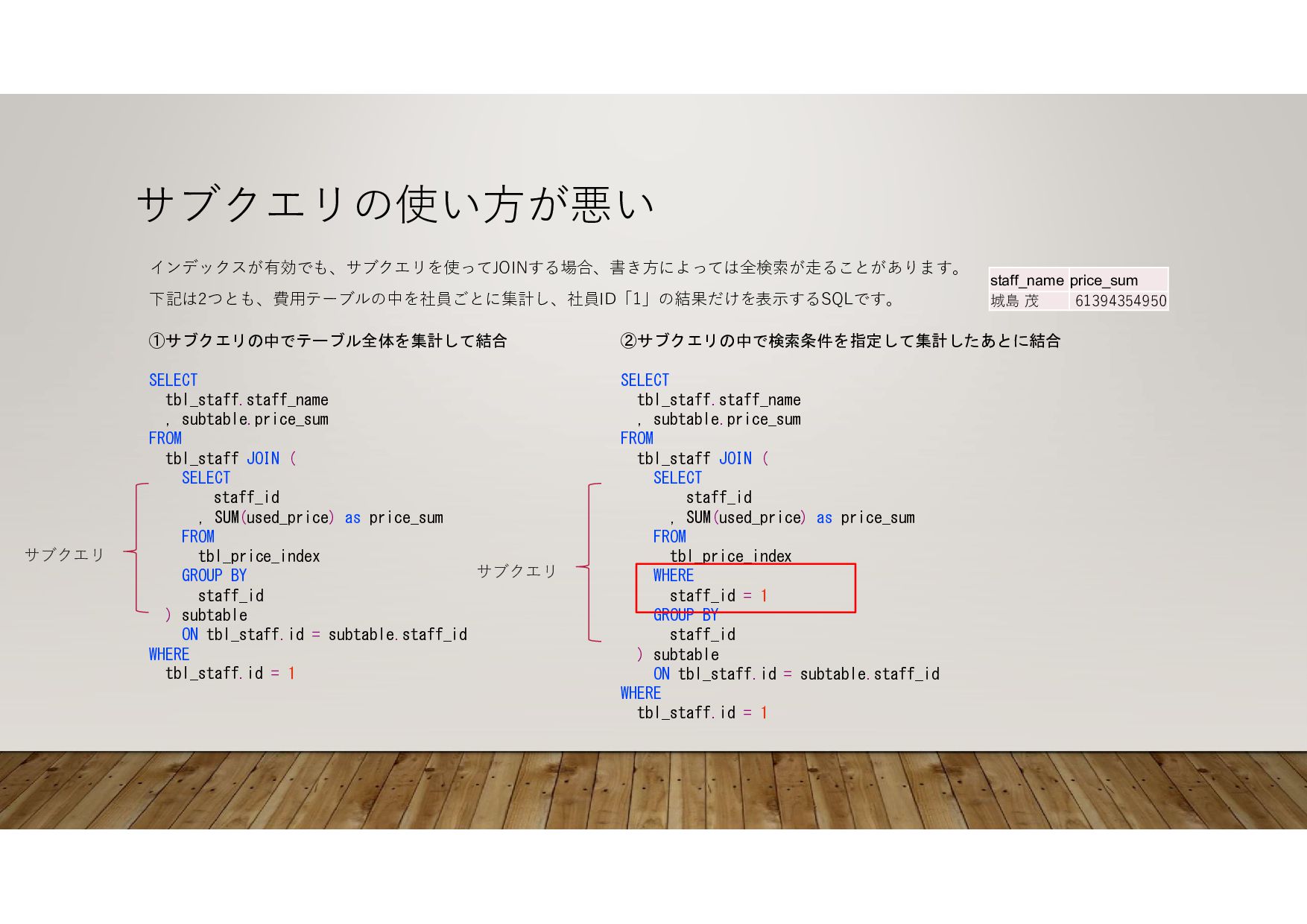
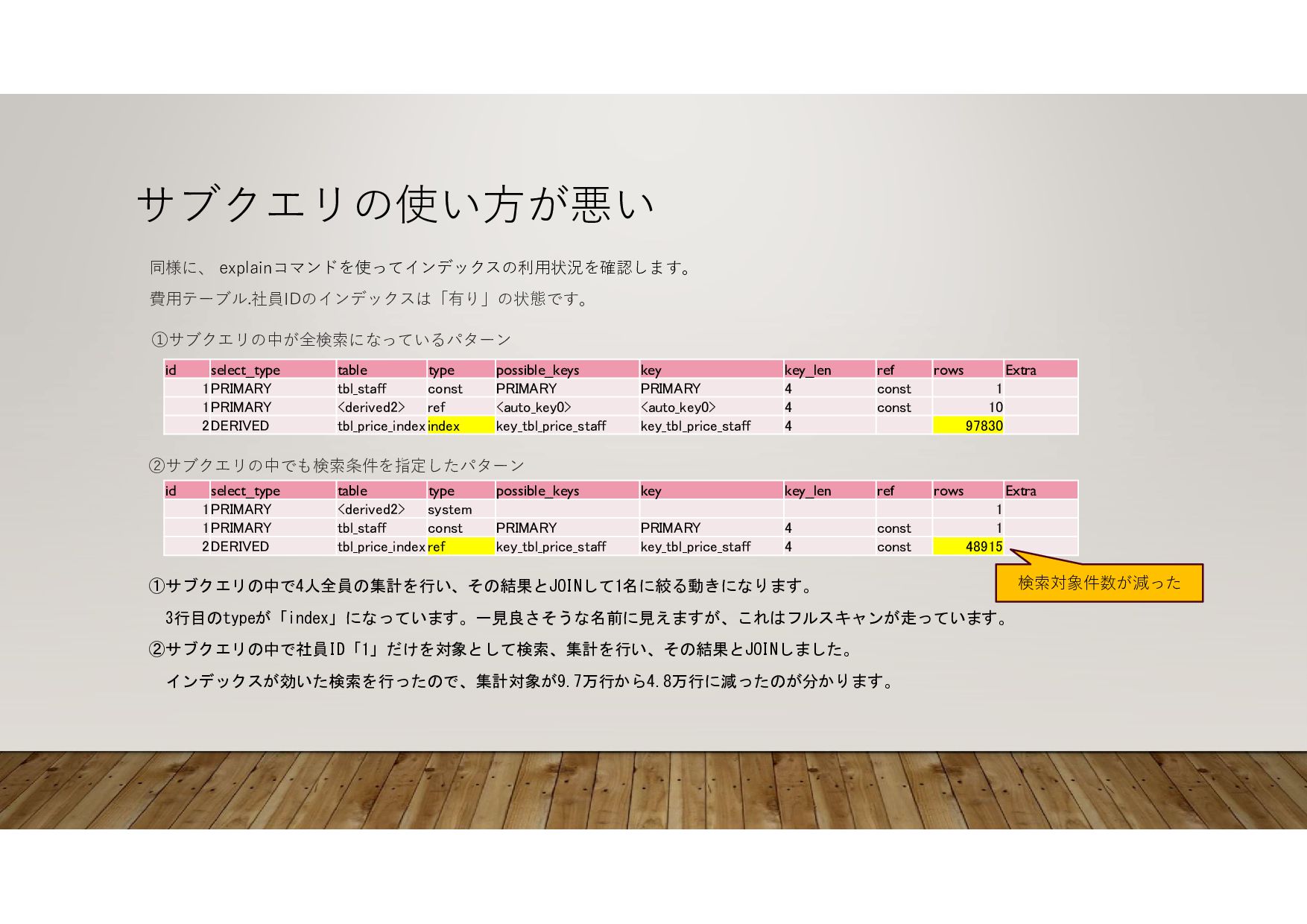
SELECT staff_id , SUM(used_price) as price_sum FROM tbl_price_index GROUP BY staff_id ) subtable ON tbl_staff.id = subtable.staff_id WHERE tbl_staff.id = 1 ②サブクエリの中で検索条件を指定して集計したあとに結合 SELECT tbl_staff.staff_name , subtable.price_sum FROM tbl_staff JOIN ( SELECT staff_id , SUM(used_price) as price_sum FROM tbl_price_index WHERE staff_id = 1 GROUP BY staff_id ) subtable ON tbl_staff.id = subtable.staff_id WHERE tbl_staff.id = 1 インデックスが有効でも、サブクエリを使ってJOINする場合、書き方によっては全検索が走ることがあります。 下記は2つとも、費用テーブルの中を社員ごとに集計し、社員ID「1」の結果だけを表示するSQLです。 結果 → サブクエリ price_sum staff_name 61394354950 城島 茂 サブクエリ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}