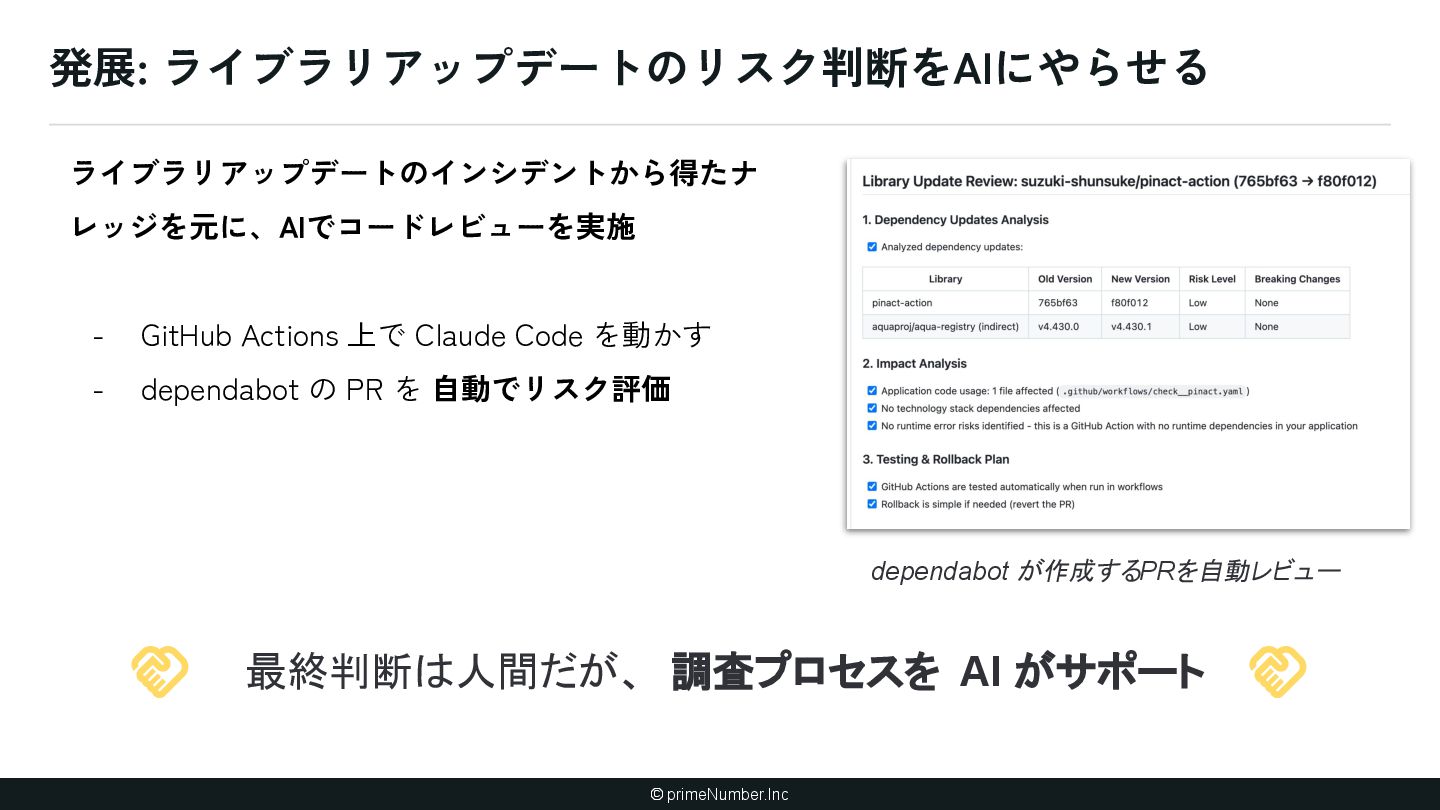
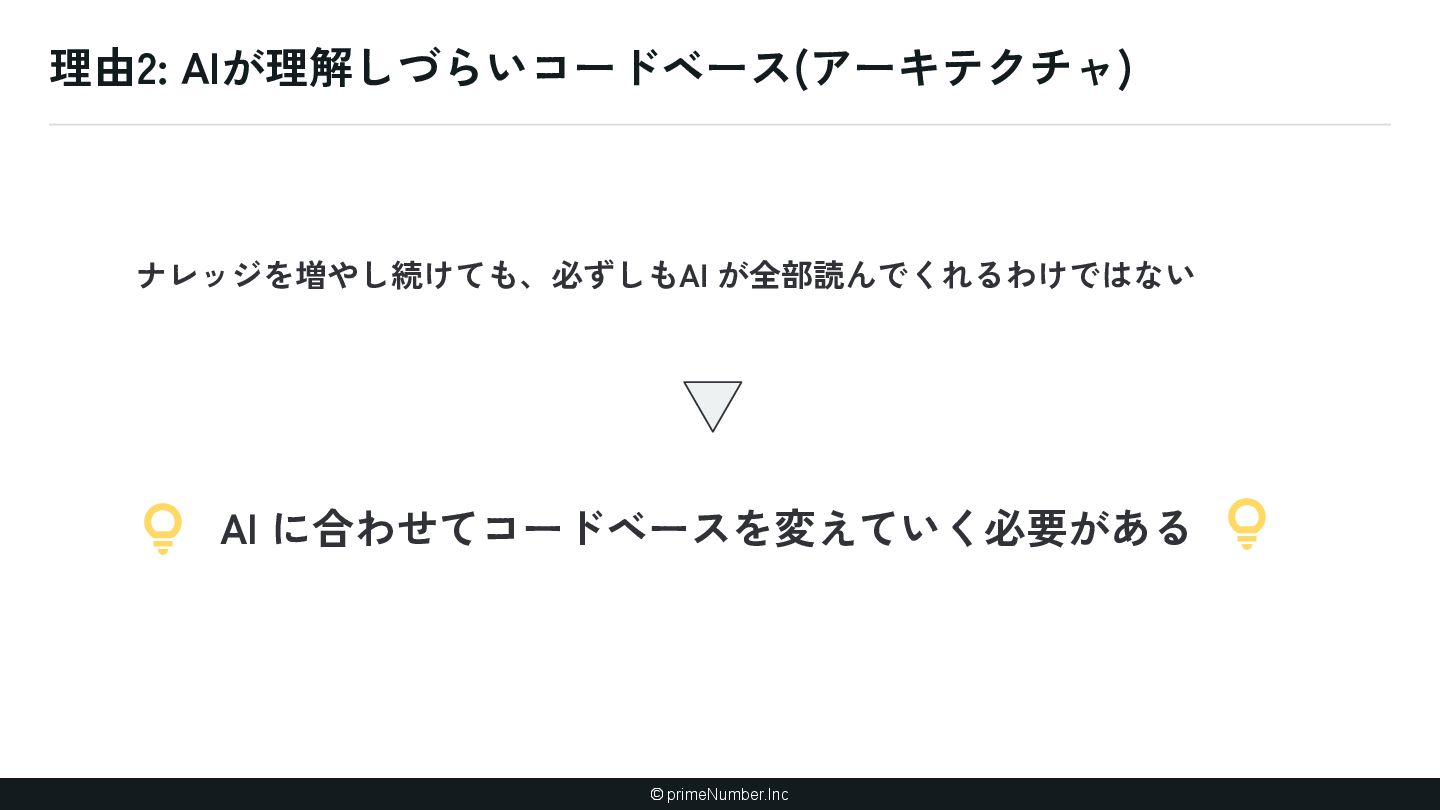
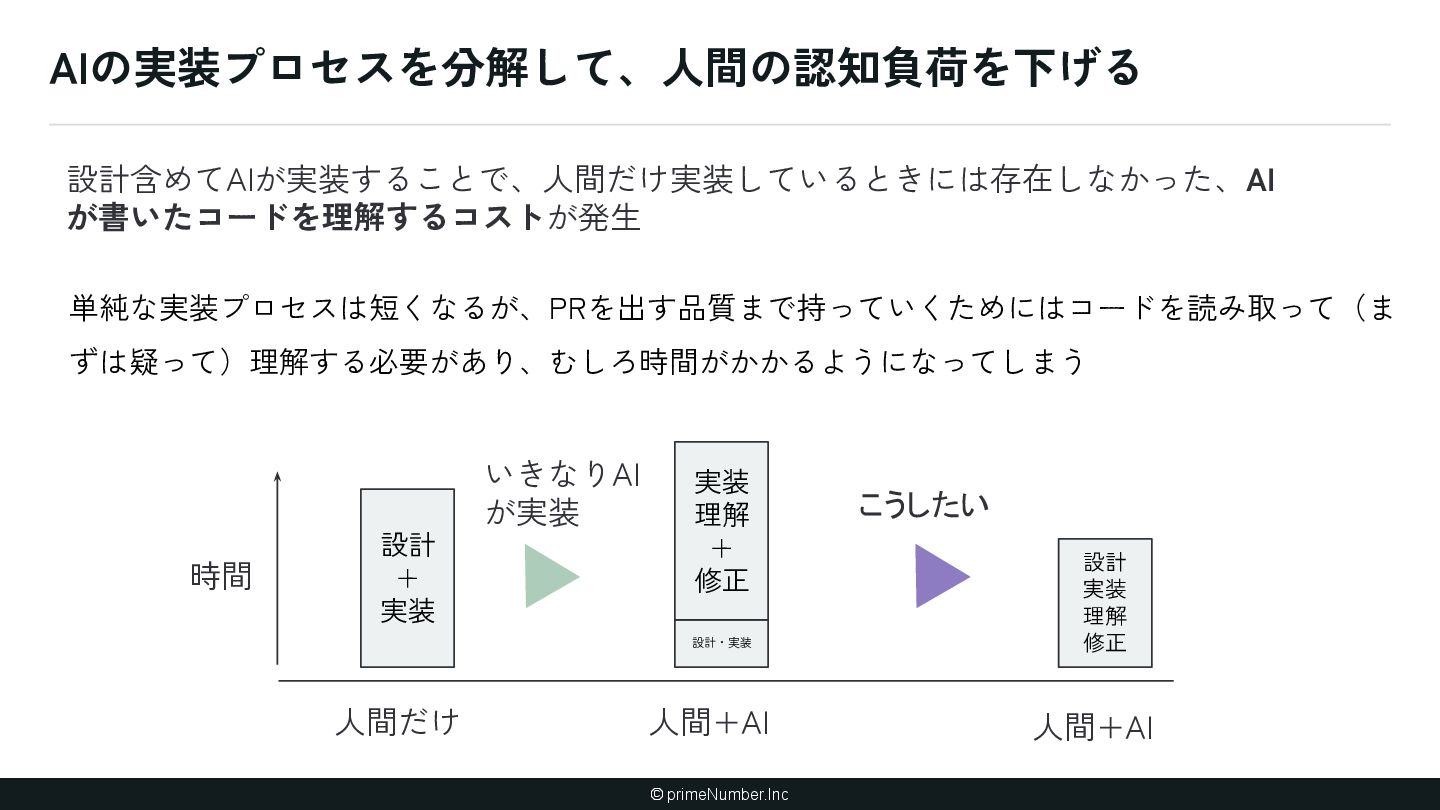
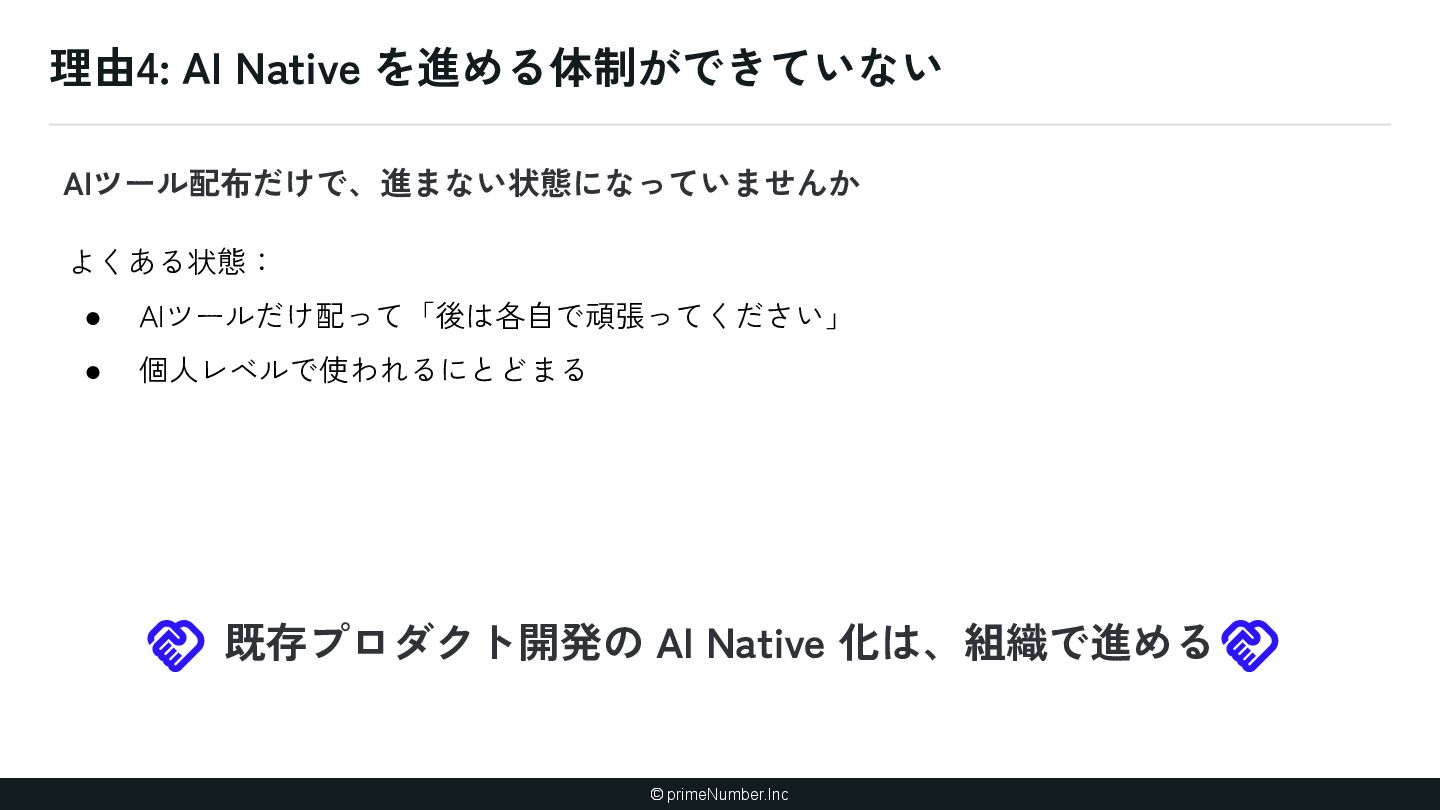
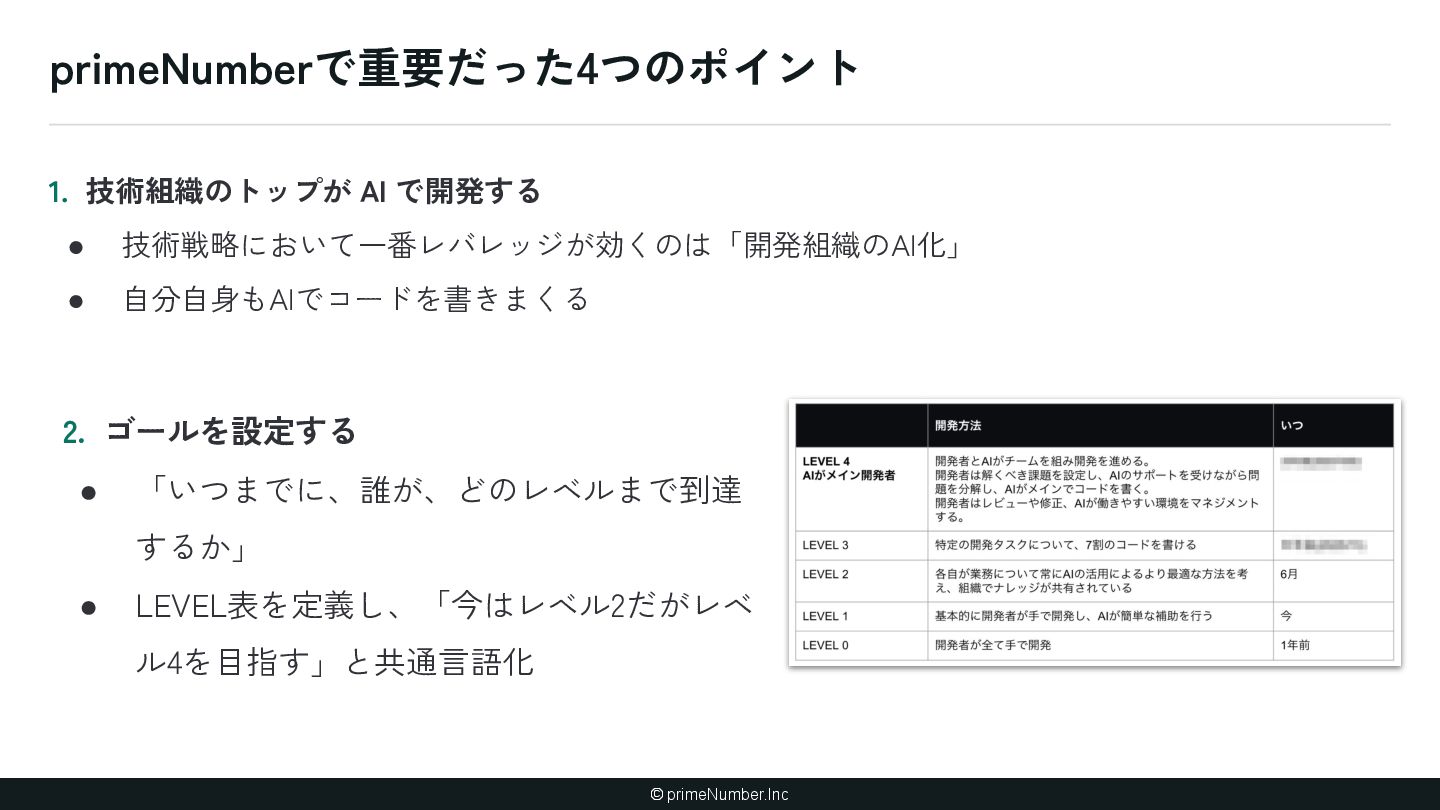
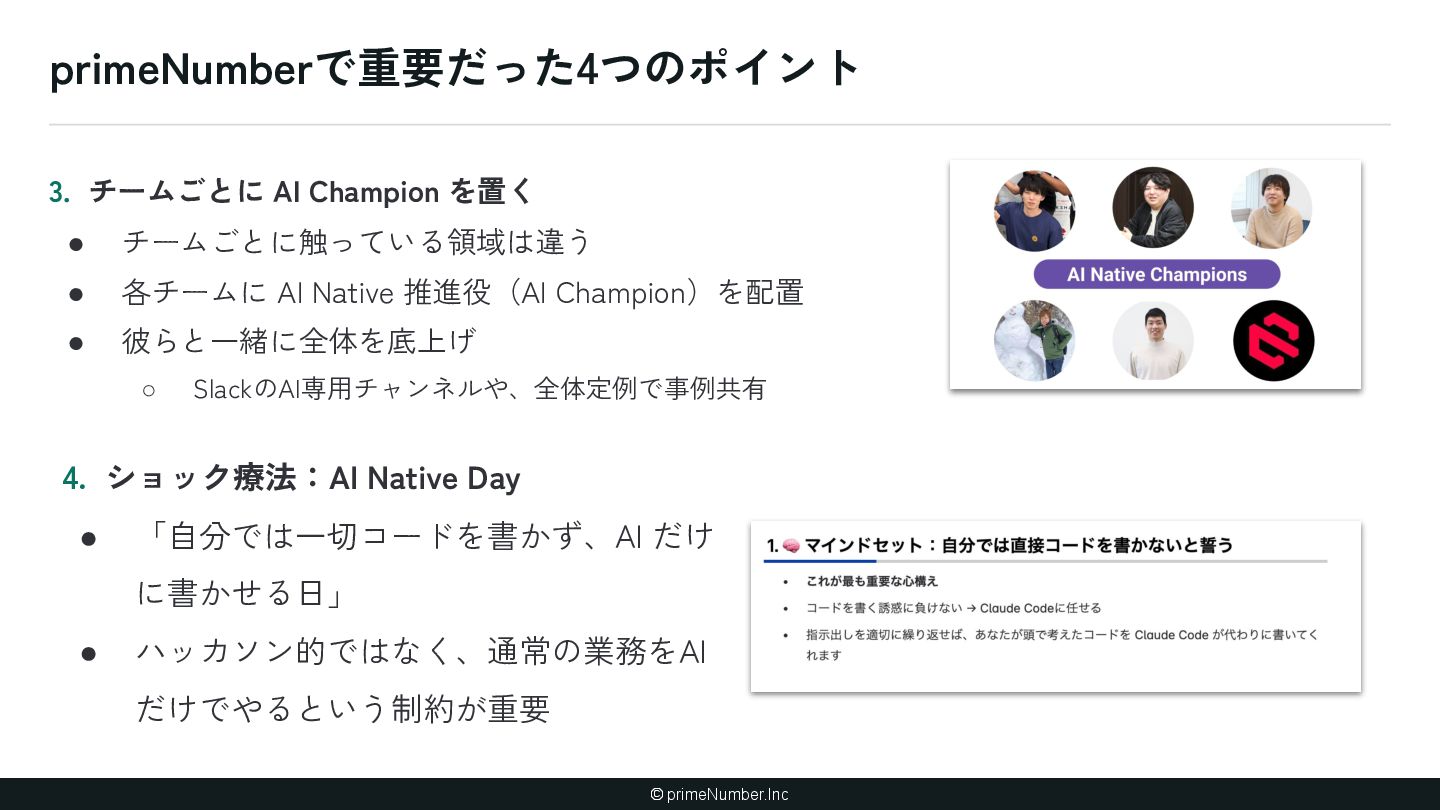
暗黙知が存在する(ナレッジ) ① 泥臭くナレッジ増やす ② AIにナレッジを書かせる 2. AIが理解しづらいコードベースになって いる(アーキテクチャ) ① AIに合わせてコードベースを変更する (できるとことか ら) 3. AIが扱える粒度に開発プロセスが分解さ れていない(プロセス設計) ① 開発プロセスを棚卸しする ② 人間の実装プロセスにAIをあわせる 4. AI Native を進める「体制」が整っていな い(組織) ① 技術のトップがちゃんとAI開発やる ② ゴールを設定 ③ AI Champion ④ ショック療法
{kind=link}
{kind=link}
{kind=link}
{kind=link}
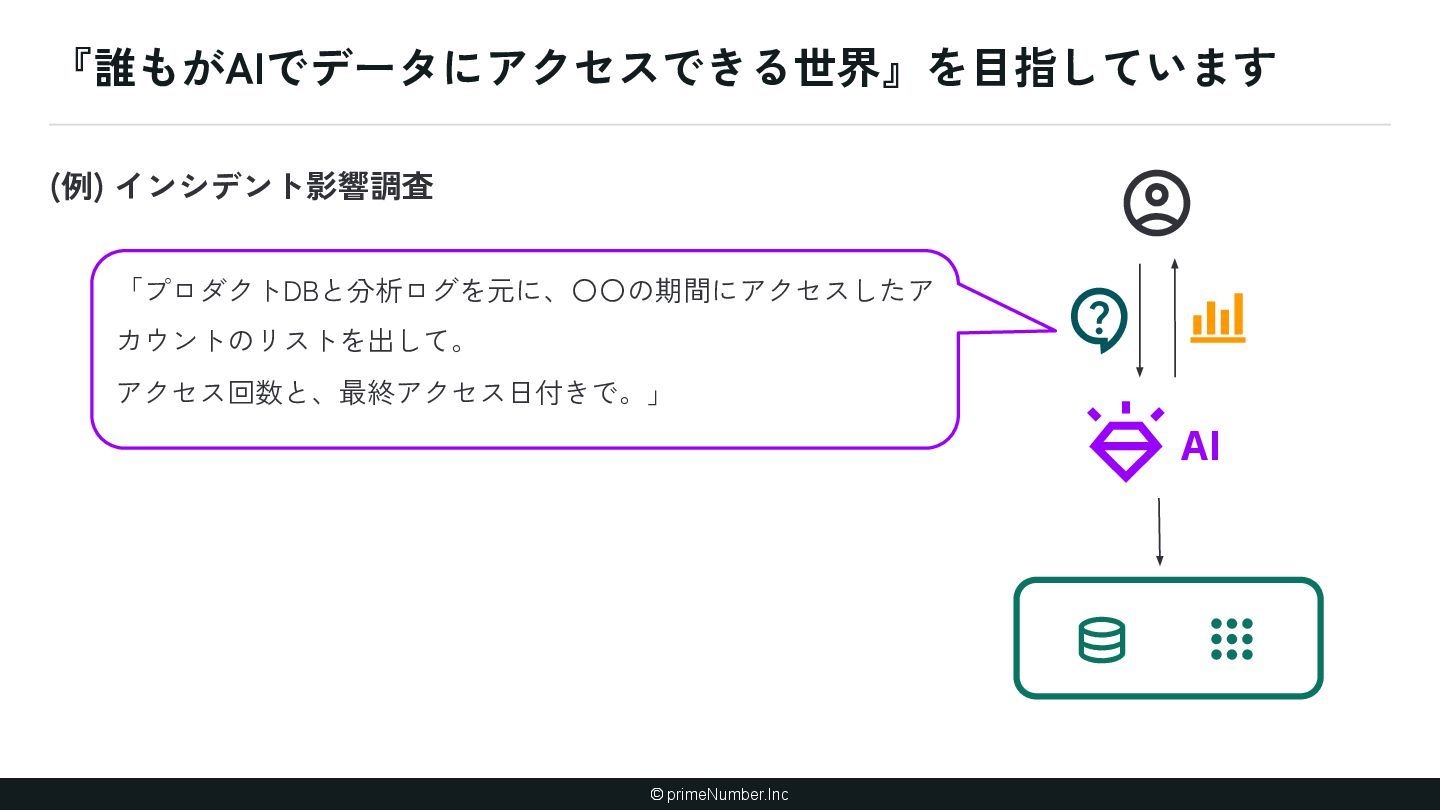{kind=link}
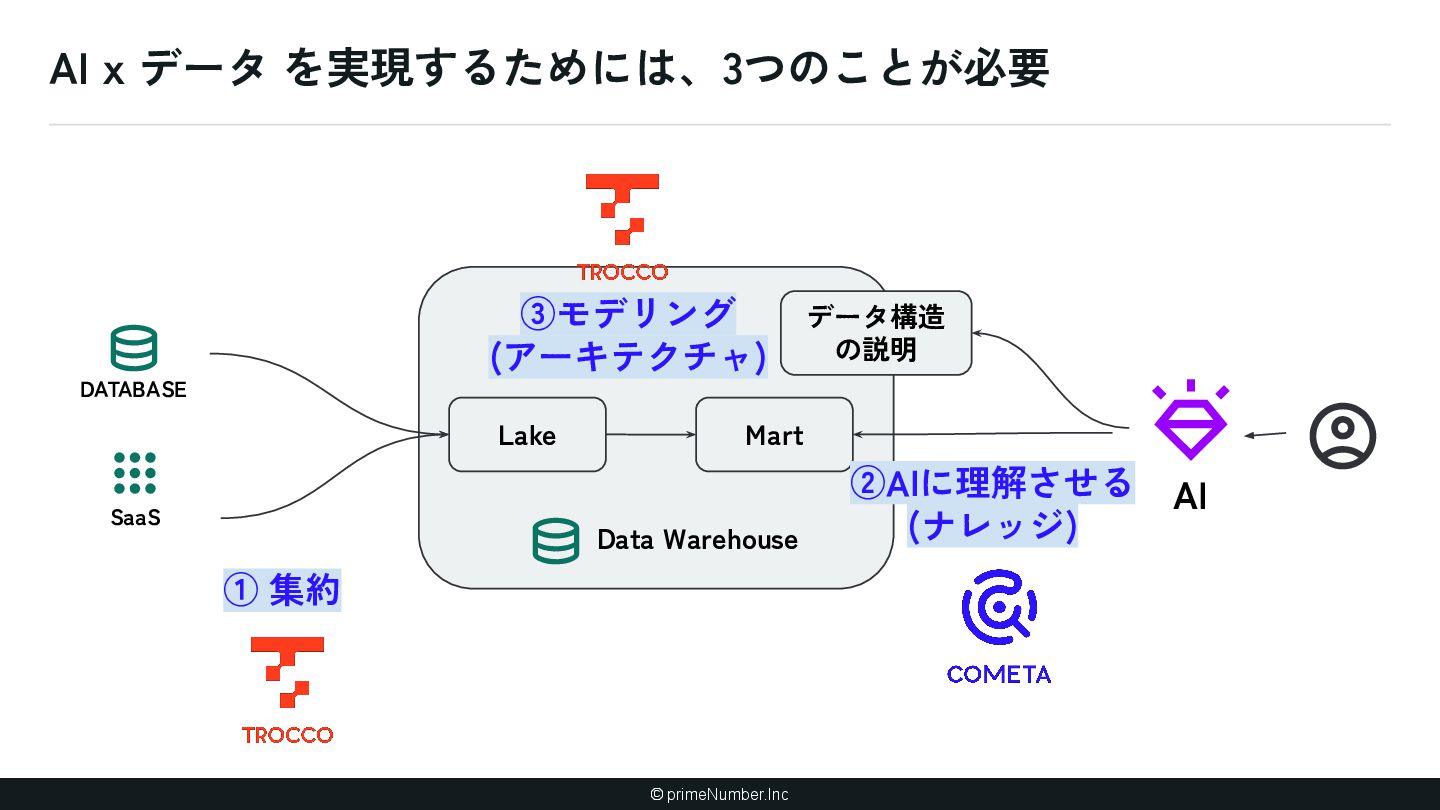{kind=link}
{kind=link}
{kind=link}
{kind=link}
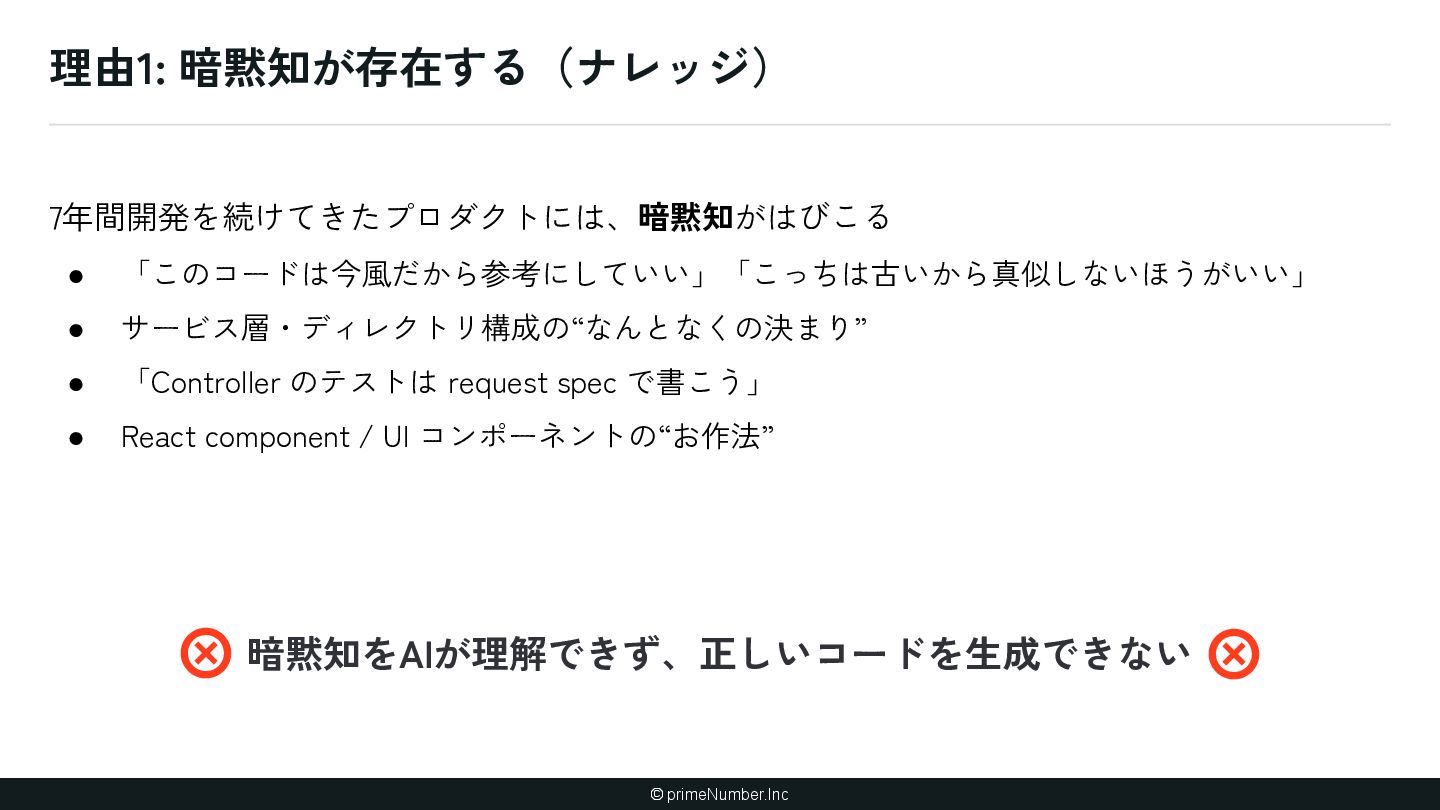{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}