usuário top_n = defaultdict(list) for uid, iid, true_r, est, _ in predictions: top_n[uid].append((iid, est)) # Ordena as predições para cada usuário baseado nos k maiores ratings for uid, user_ratings in top_n.items(): user_ratings.sort(key=lambda x: x[1], reverse=True) top_n[uid] = user_ratings[:n] return top_n Pegar top_n recomendações
![1 Criando sistemas de recomendação com scikit-surprise Guilmour Rossi [email protected]](https://files.speakerdeck.com/presentations/d8792b0293344378b42760524b33d0e2/slide_0.jpg){kind=link}
{kind=link}
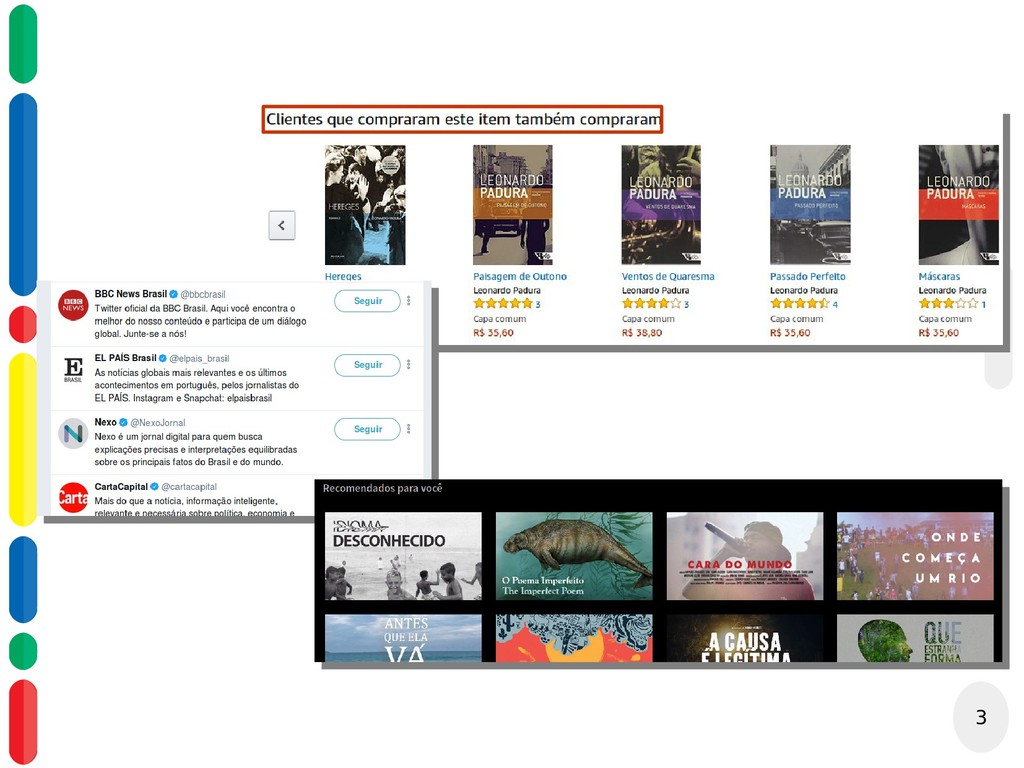{kind=link}
{kind=link}
{kind=link}
{kind=link}
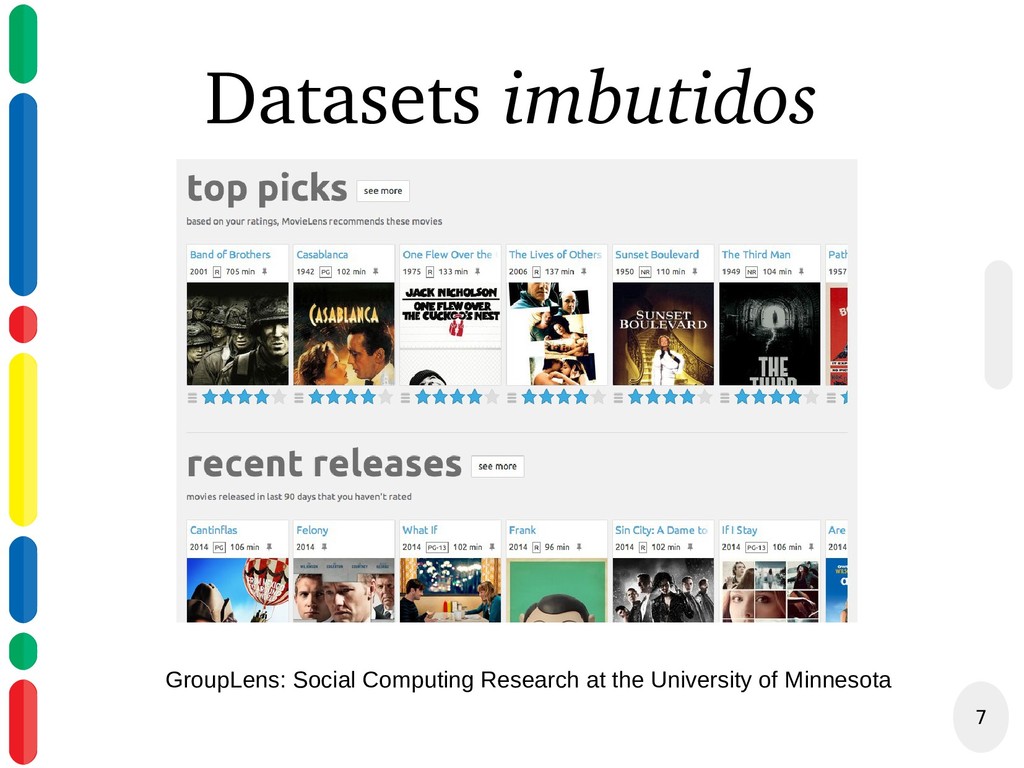{kind=link}
{kind=link}
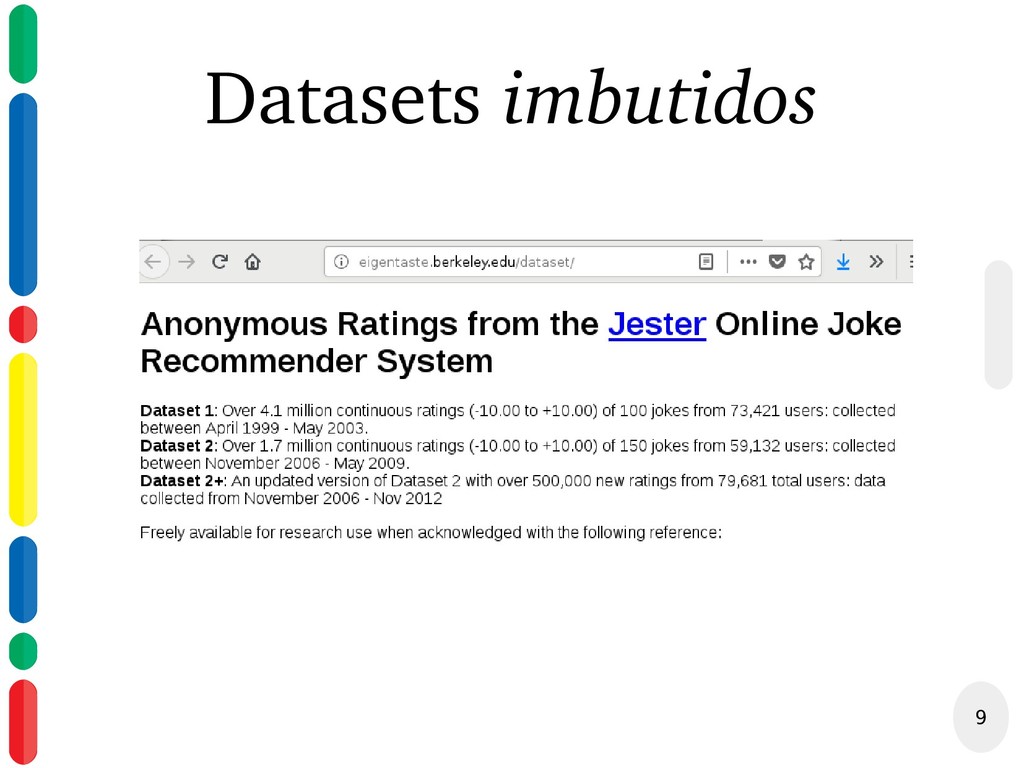{kind=link}
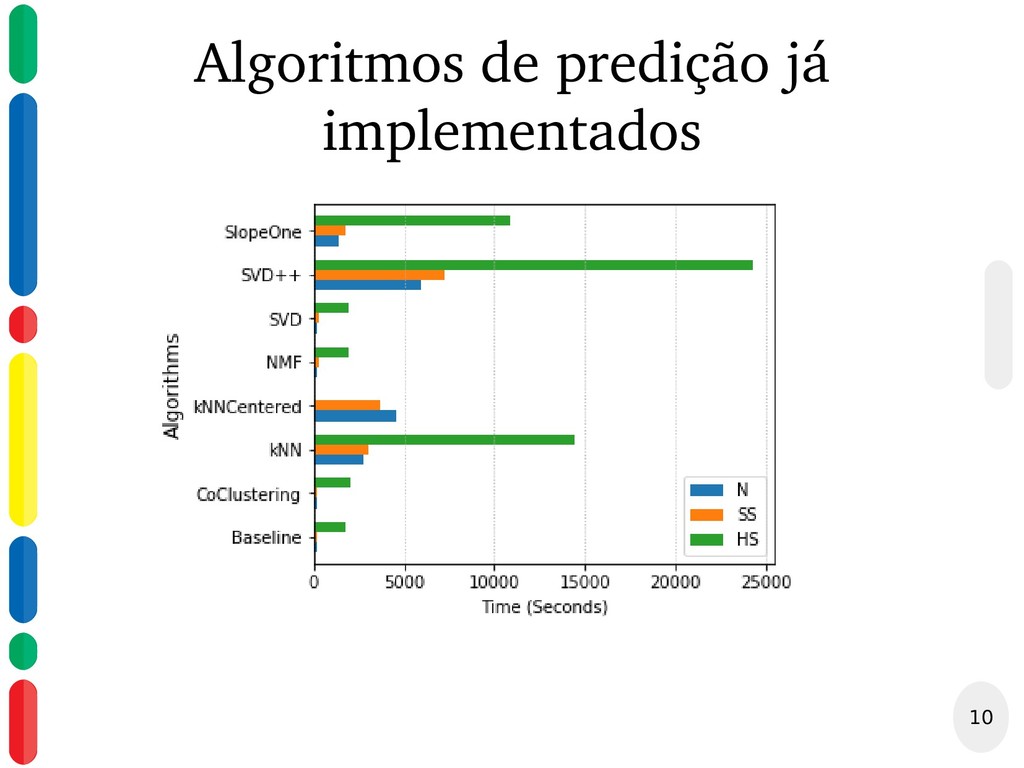{kind=link}
{kind=link}
{kind=link}
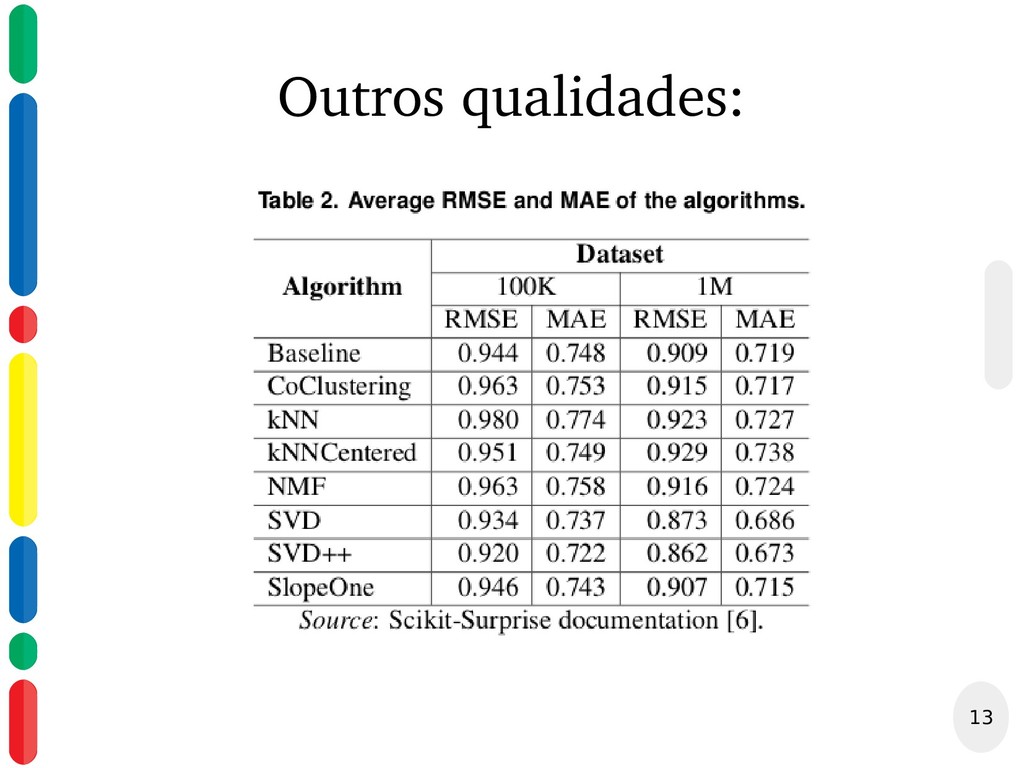{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
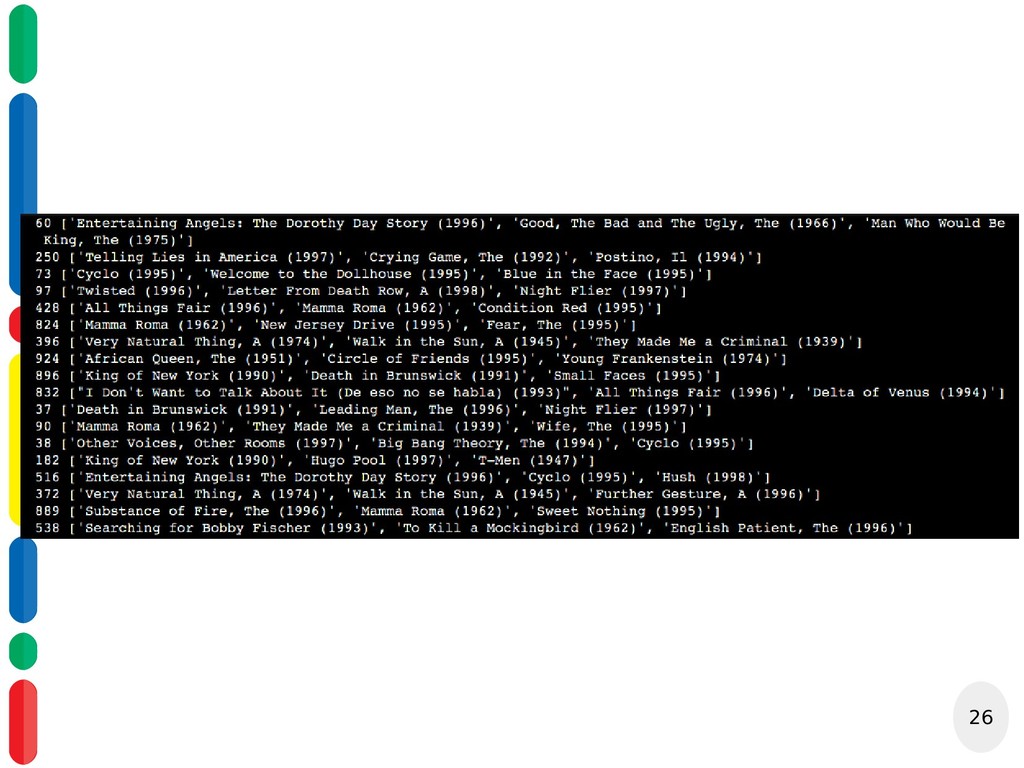{kind=link}
![27 [email protected] | @guilmour | guilmour.org Obrigado! Guilmour Rossi [email protected]](https://files.speakerdeck.com/presentations/d8792b0293344378b42760524b33d0e2/slide_26.jpg){kind=link}
{kind=link}