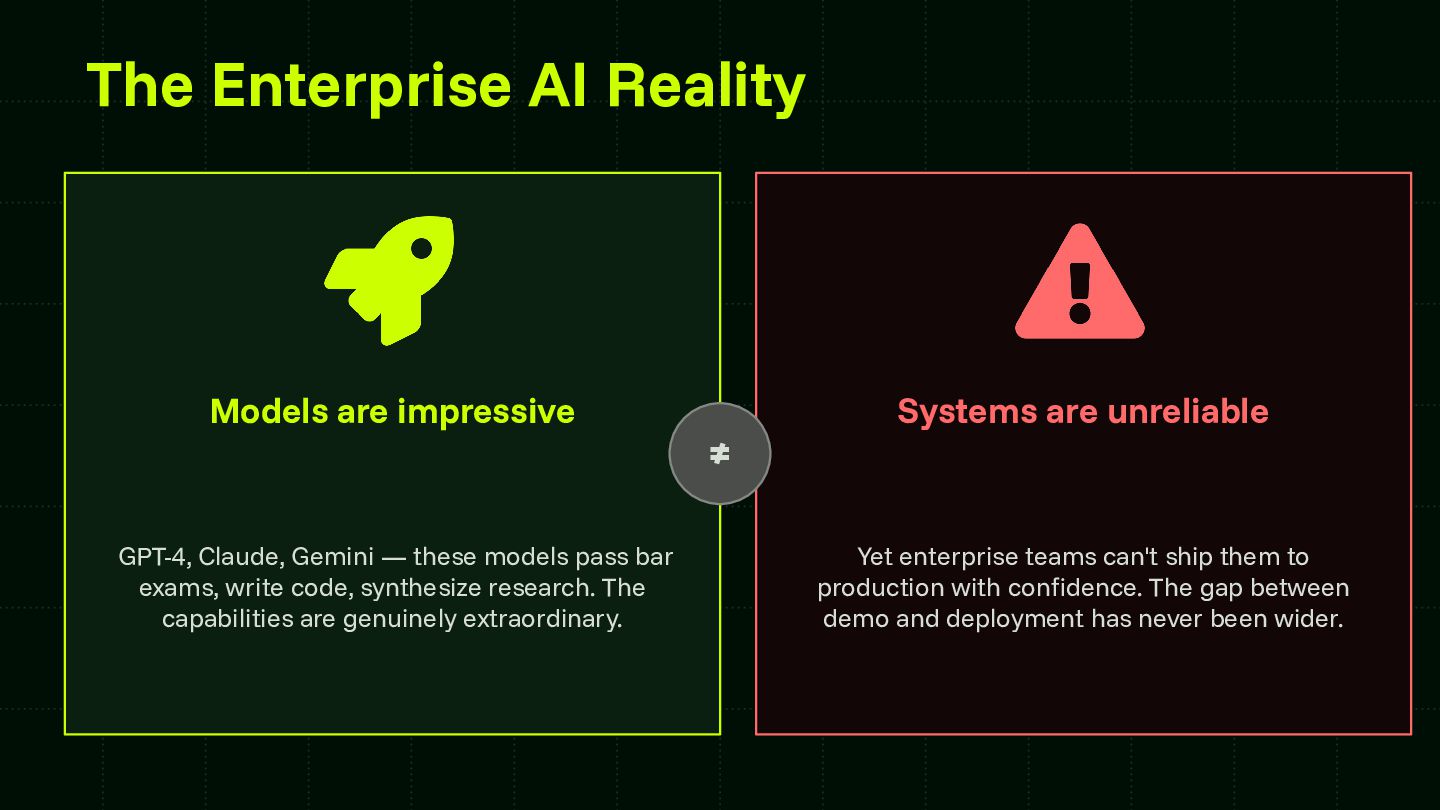
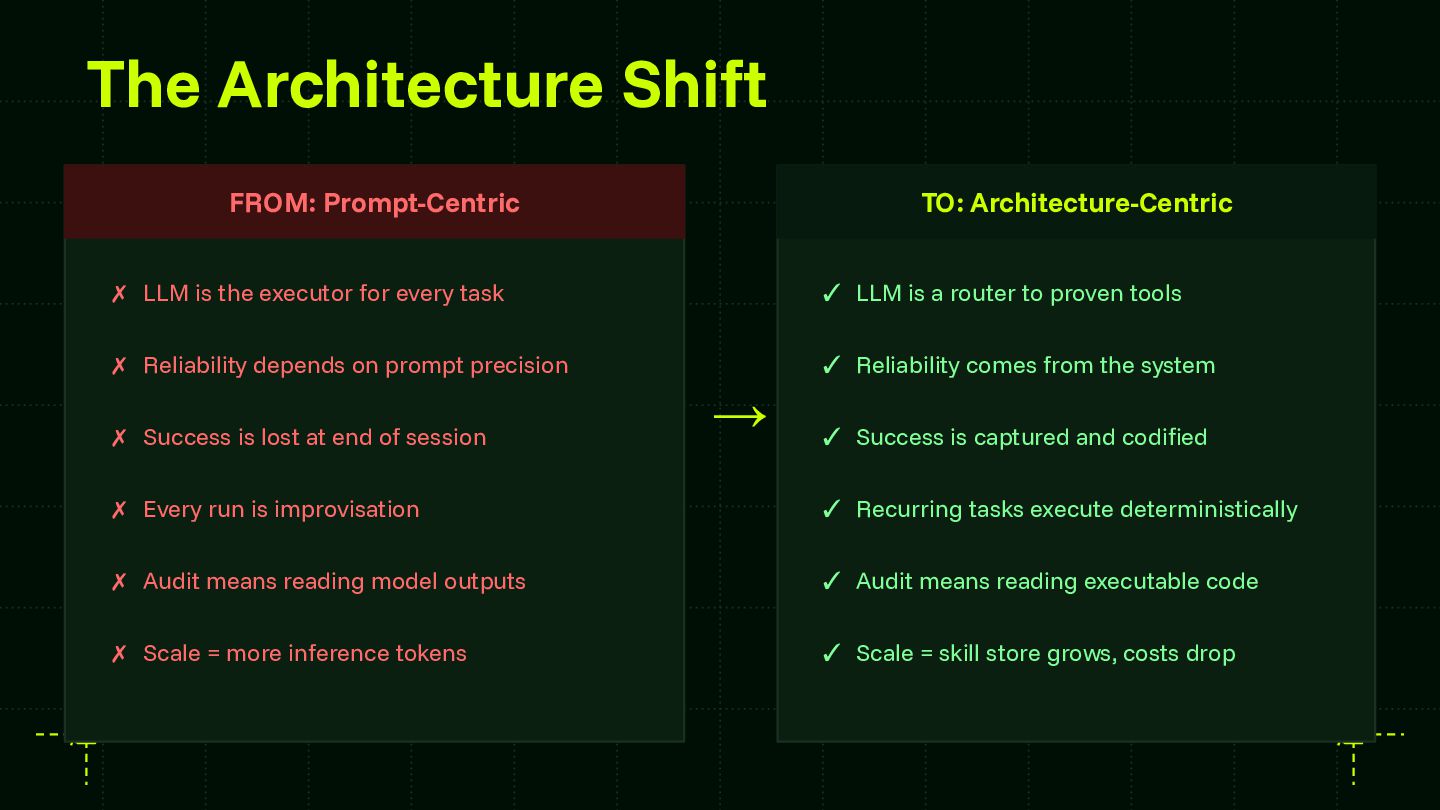
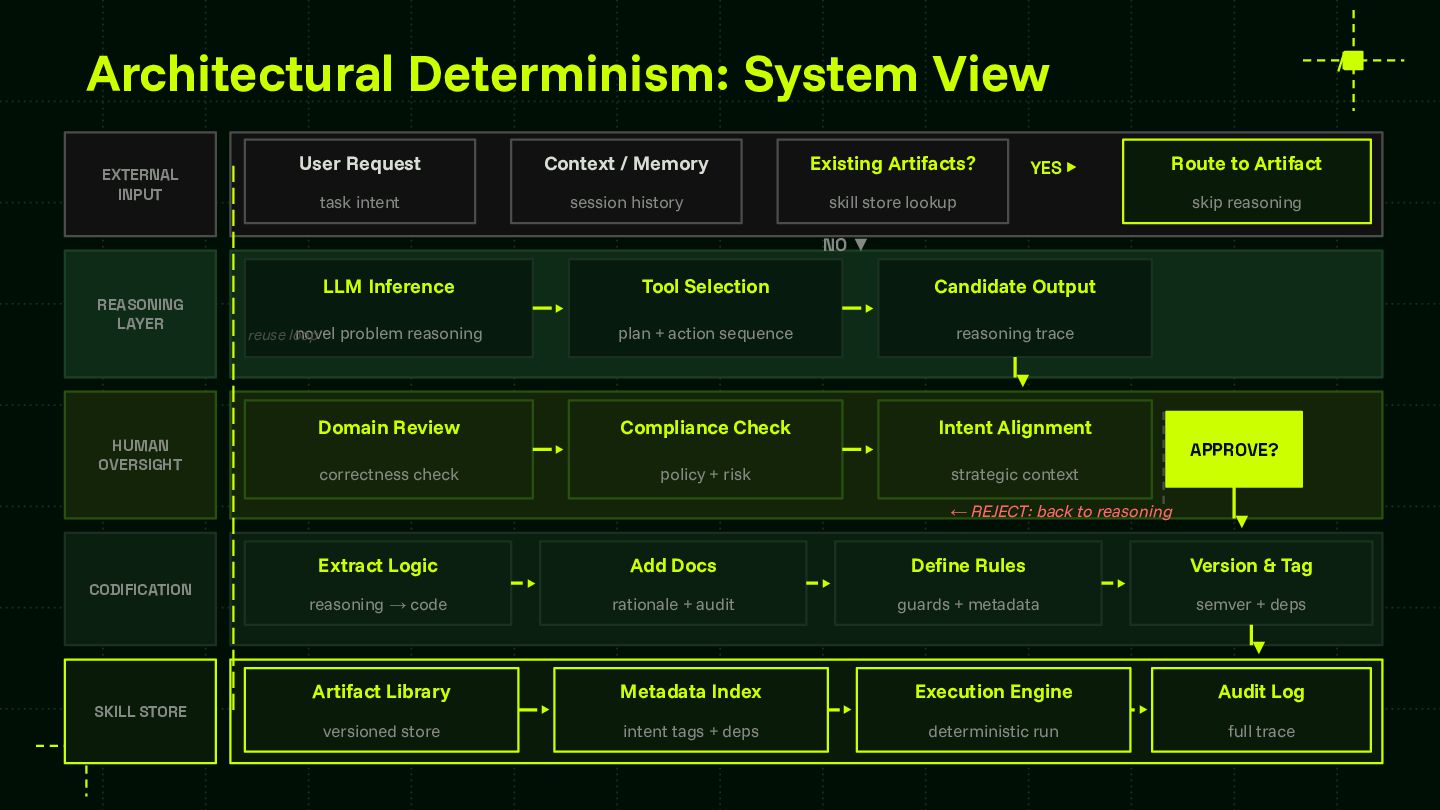
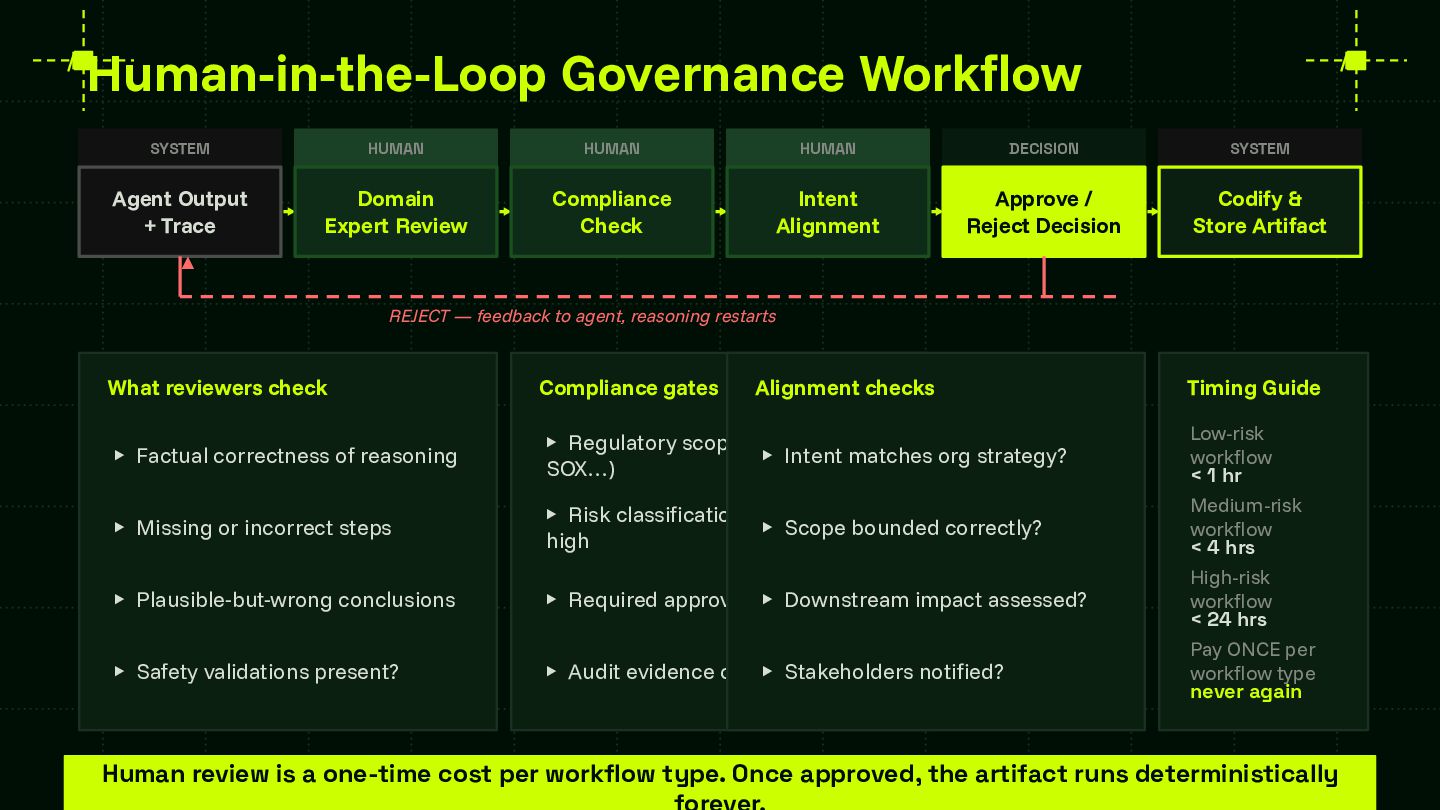
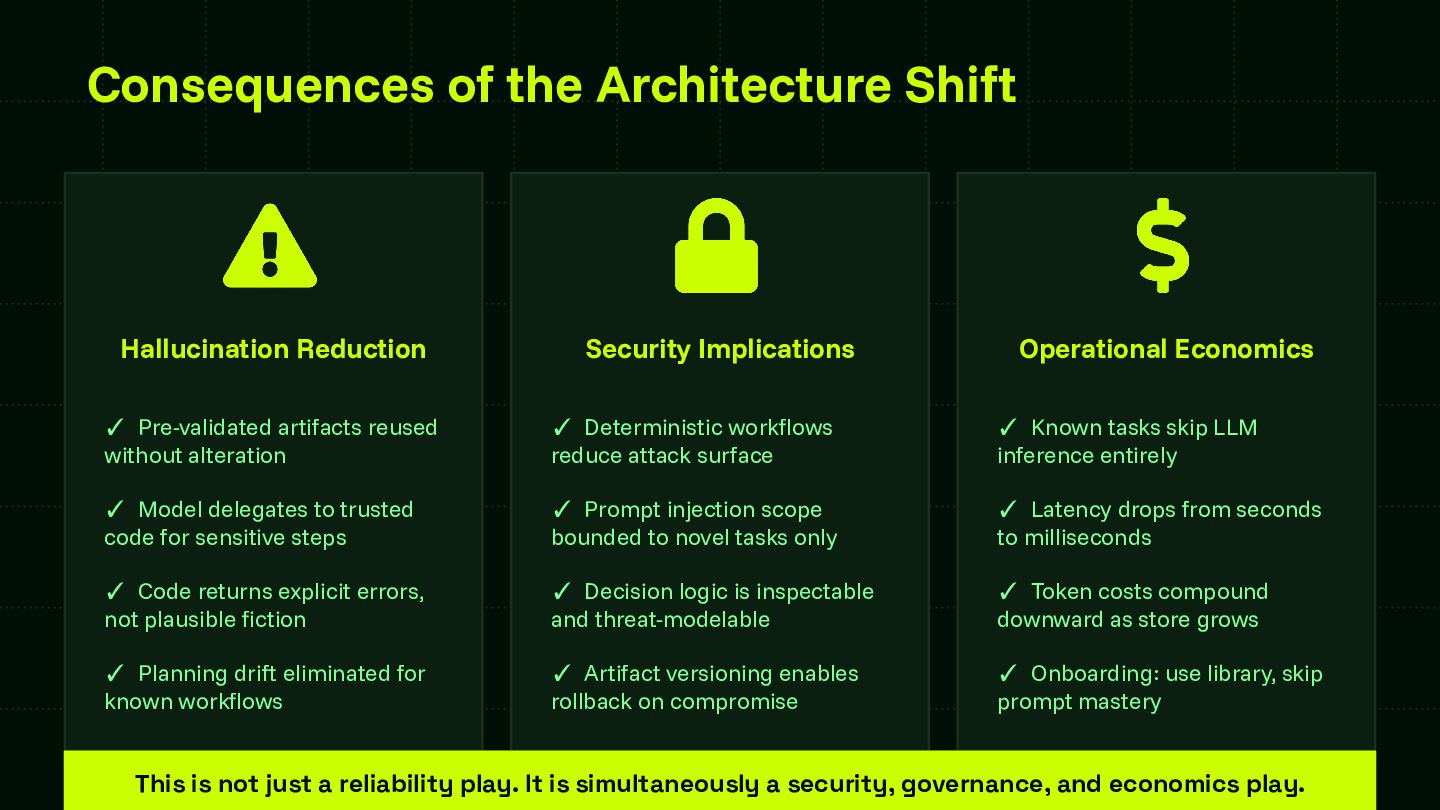
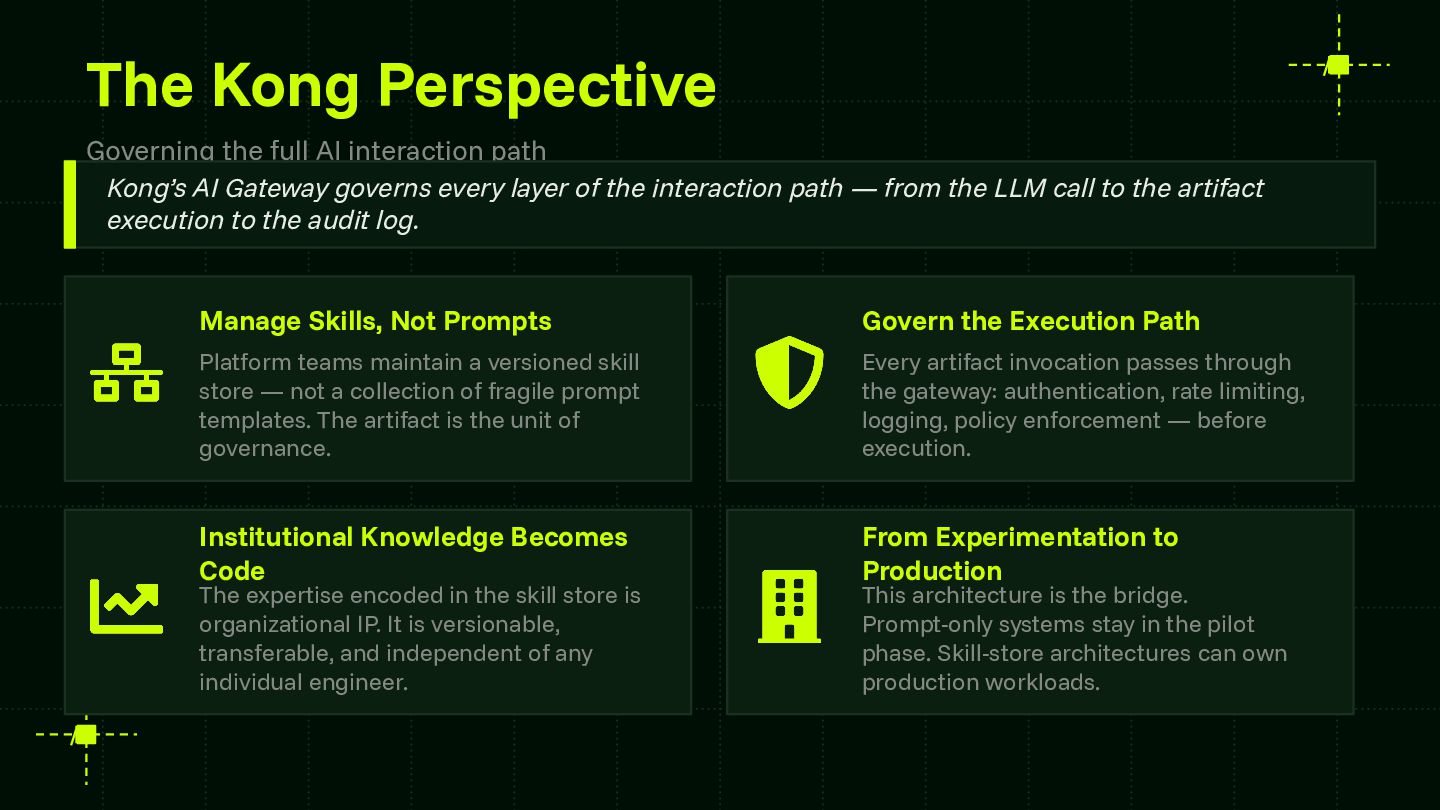
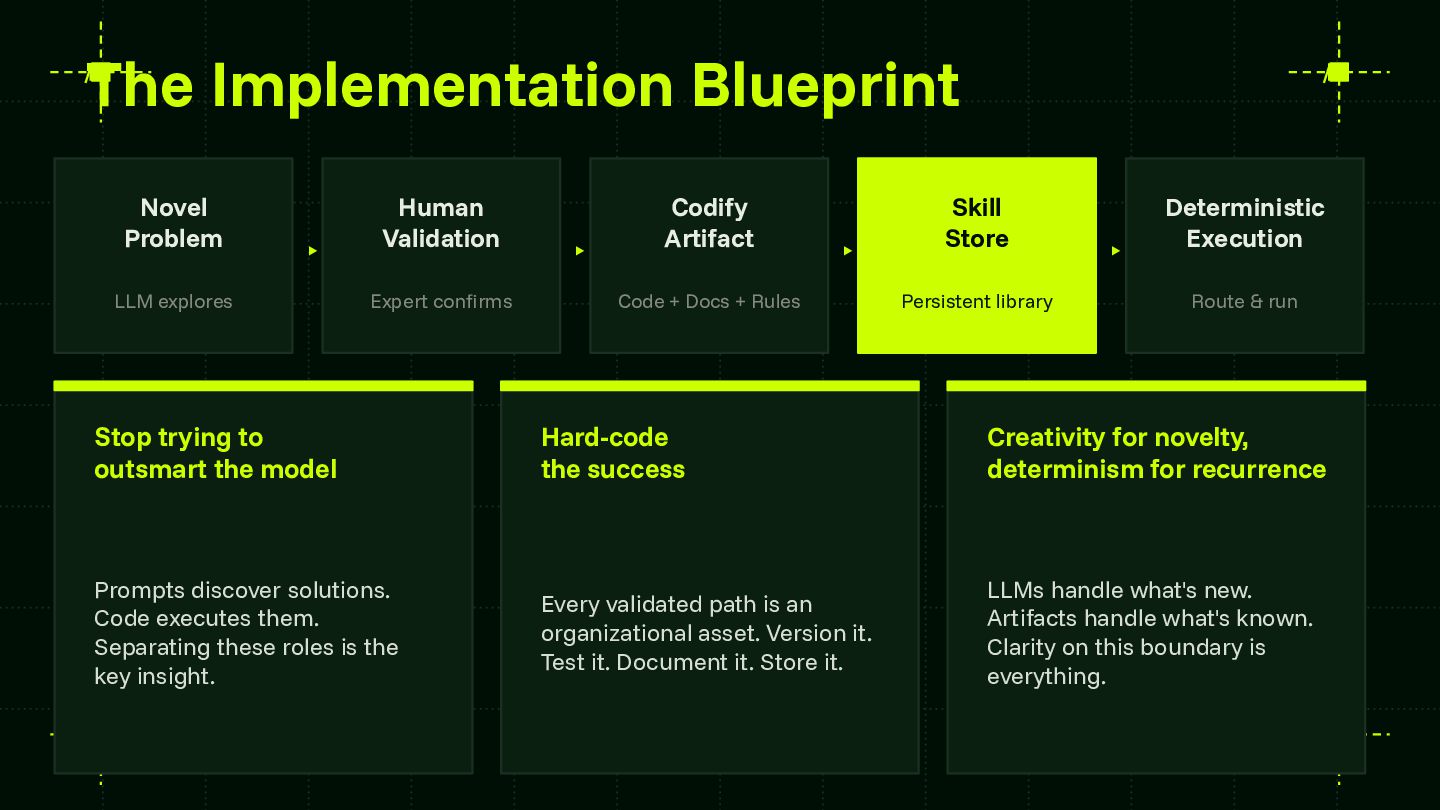
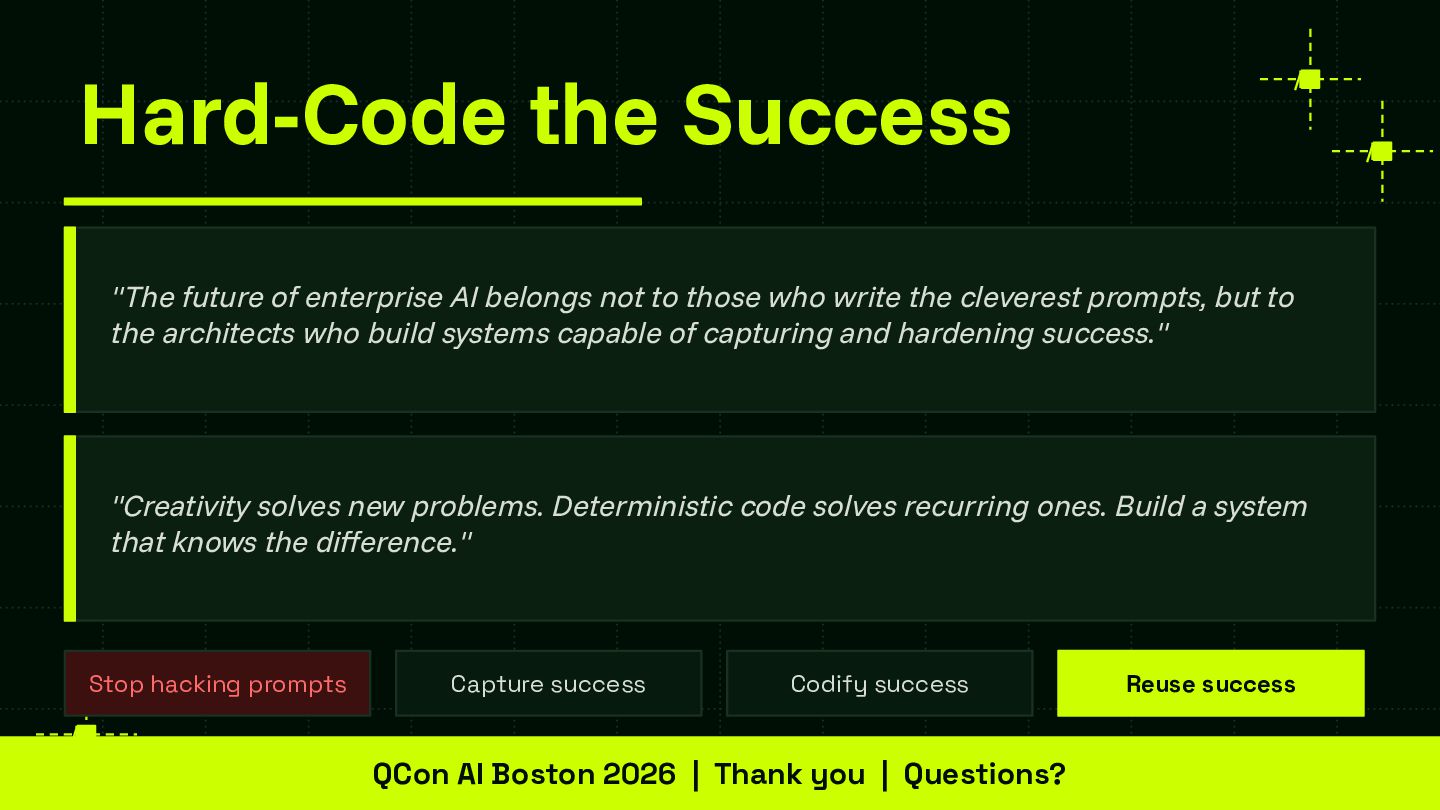
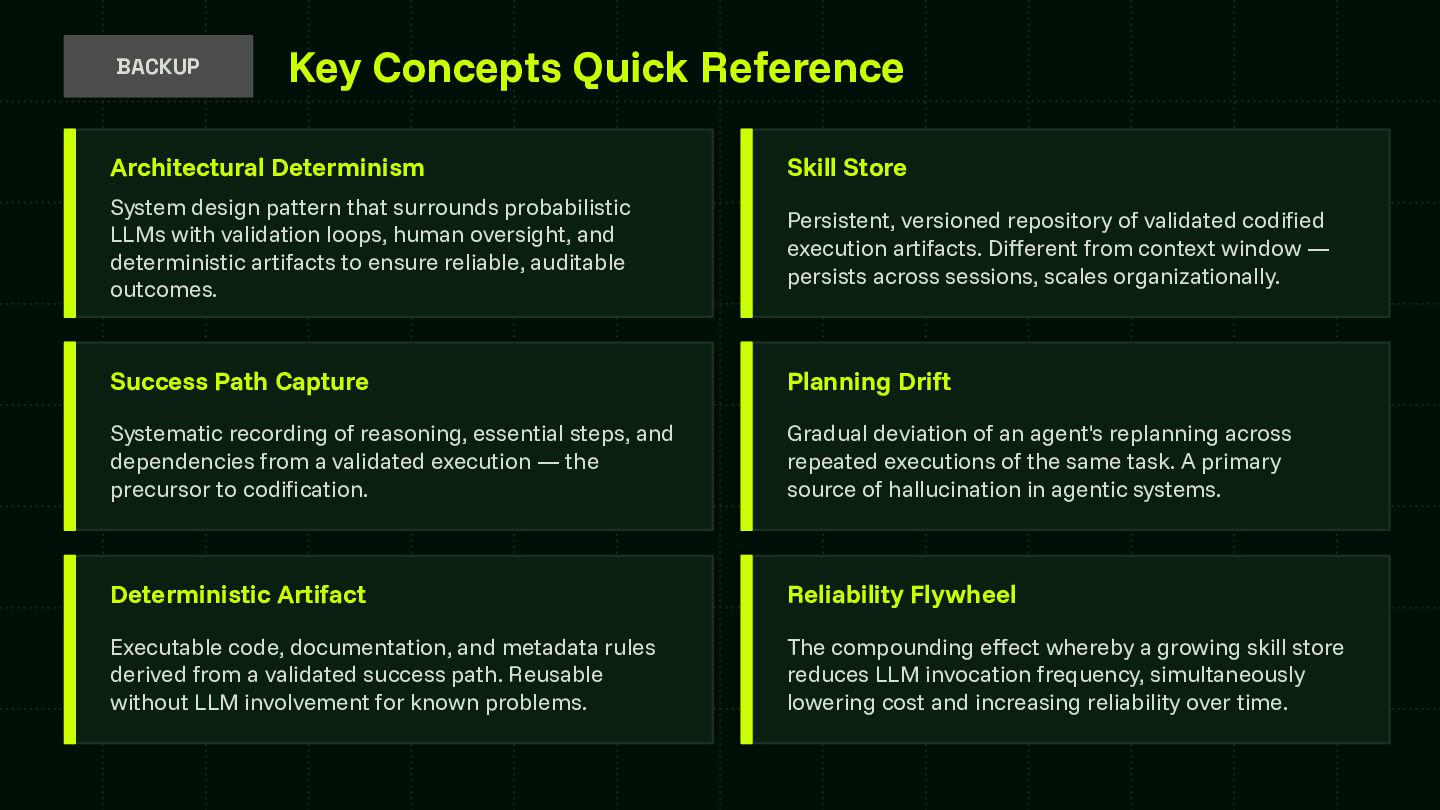
Reliability is the central challenge blocking enterprise AI adoption at scale. This session provides a framework that teams can apply regardless of model provider or agent runtime — advancing the community's shared understanding of how to systematically capture and codify agent behavior. The skill store pattern is directly applicable to any organization building multi-agent systems and contributes a concrete architectural model for the ecosystem to build on and extend.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}