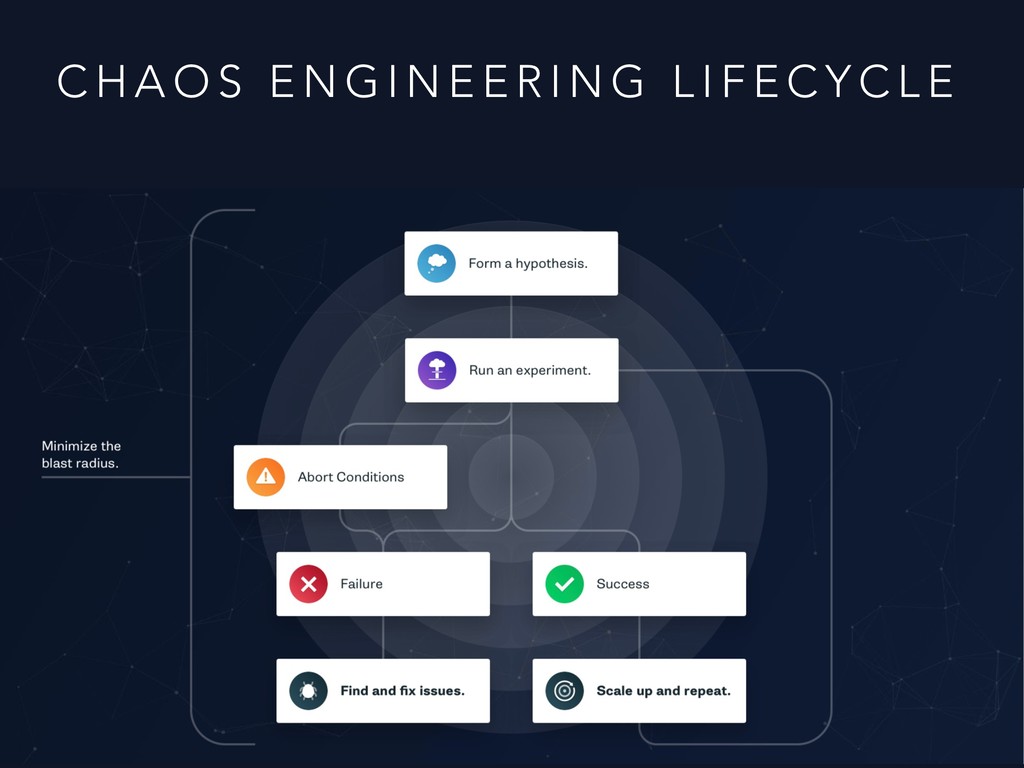
E E R I N G • “Thoughtful, planned experiments designed to reveal the weaknesses in our system” - Kolton Andrus • Like a vaccine, we inject harm into our system to help build immunity.
G I N E E R ? • The motivations are different depending on role: • Business case - avoiding costly downtime • On call case - avoiding 3am pages • Engineering - service availability
T E S F O R C H A O S • Have a High Severity Incident Management (SEV) Program • Have sufficient monitoring to observe effects • Alerts and paging, that notify a human during a SEV
Y ? • Everybody benefits from observing failure • Encourages cross-organization collaboration • Find your champions across the company • Encourages varied perspectives
E D AY • Gremlin holds Failure Fridays • Degradation of my features in the UI was less than desirable • Mapped out the critical failures, dropped tickets into tech debt, dealt with the tickets gradually as time allowed.
E E R I N G A N D U I • End-to-End testing of failure scenarios is not enough. • OSS Developer tooling around failure mitigation in UI is underdeveloped. • Tooling is regularly company specific.
E E R I N G A N D P R O D U C T • Mapping out potential alternative states (reroute, retry) • Product specs that include comprehensive failure scenarios are rare
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}