CEDEC 2025 登壇資料です。本セッションでは、大規模イベントの配信を支えるために私たちが実施したクラウドアーキテクチャの強化施策と、更なる大規模イベントに向けた改善や社会インフラとしての進化について共有します。
従来の技術的負債を解消しながら、大規模トラフィック時のキャパシティ管理やオートスケール戦略、サービスメッシュ導入による通信制御・可観測性向上、モニタリングシステムの最適化など多角的なアプローチを実施しました。
過去のイベントを通じて得た学びを活かし、負荷試験やログ分析からクリティカルパスを抽出するとともに、障害時も小さく壊れるための耐障害設計を徹底。さらに、ピーキーなトラフィックや DDoS などのセキュリティリスクにも多層防御で対応し、社会インフラとしての信頼性をより強固にしました。
これらの取り組みは単なるイベント対応にとどまらず、次世代の大規模配信プラットフォームや社会インフラとしての進化に寄与するものです。本セッションを通じて、大規模ライブ配信の裏側でどのようなクラウドアーキテクチャが進化してきたのかを知り、今後のシステム設計・運用に役立つ具体的なノウハウをお伝えします。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
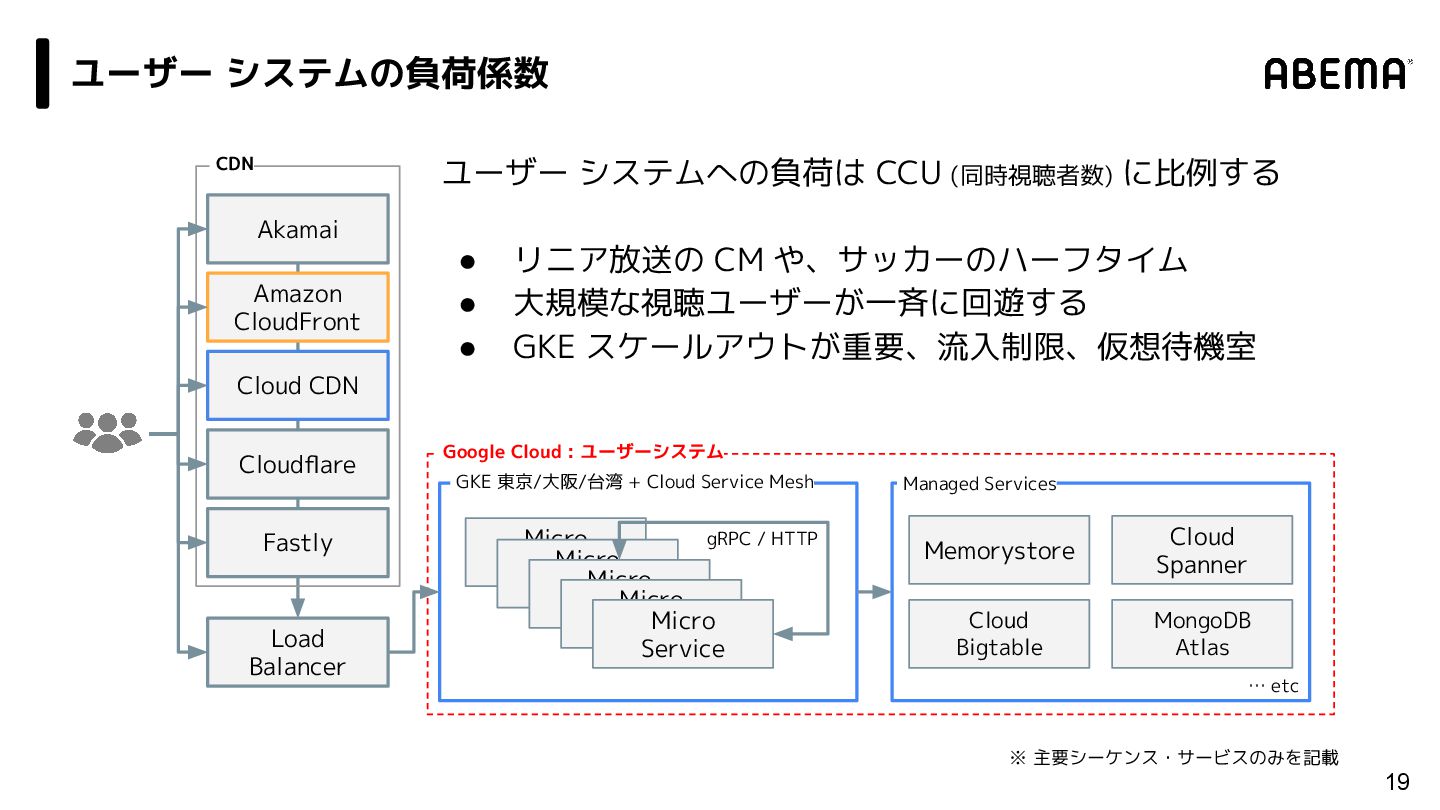{kind=link}
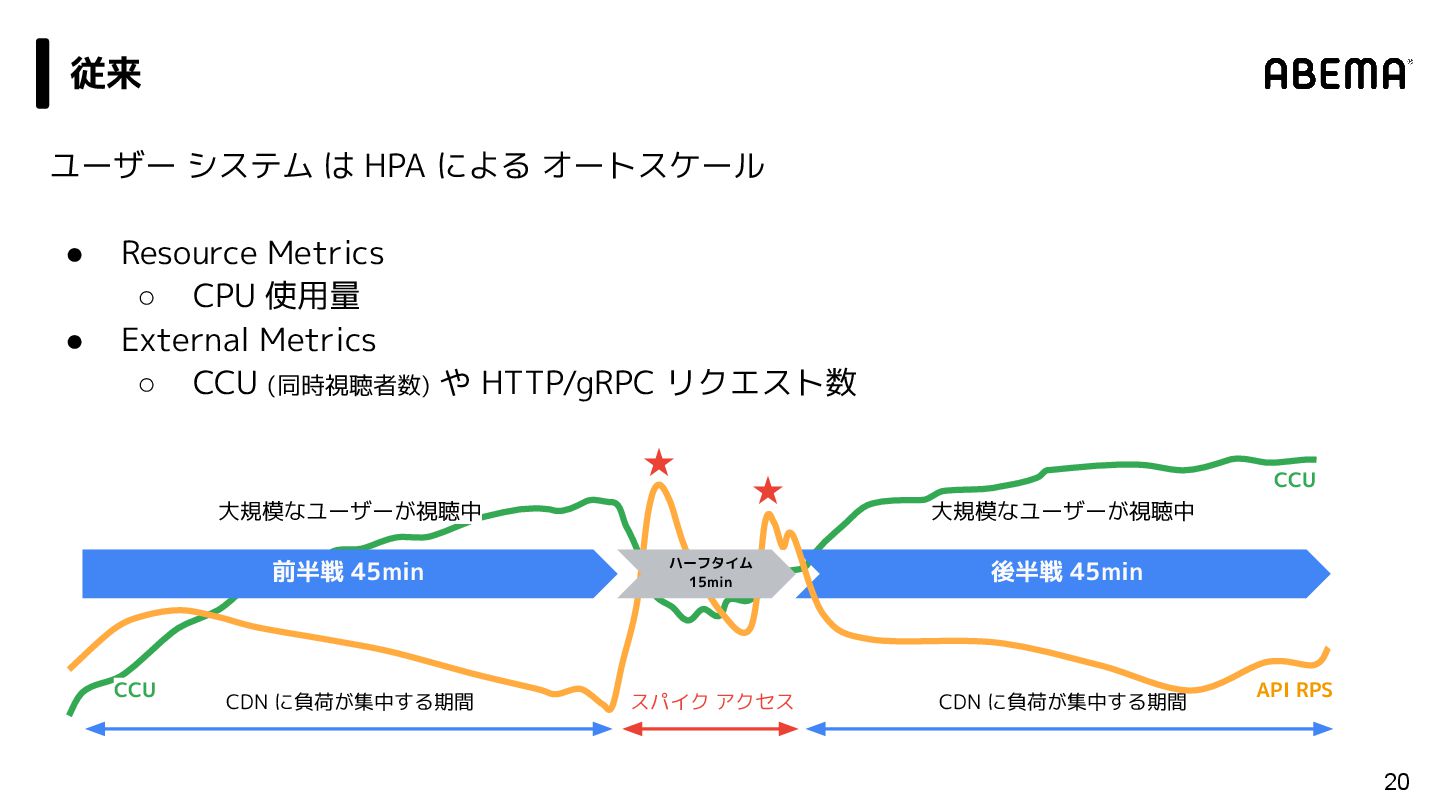{kind=link}
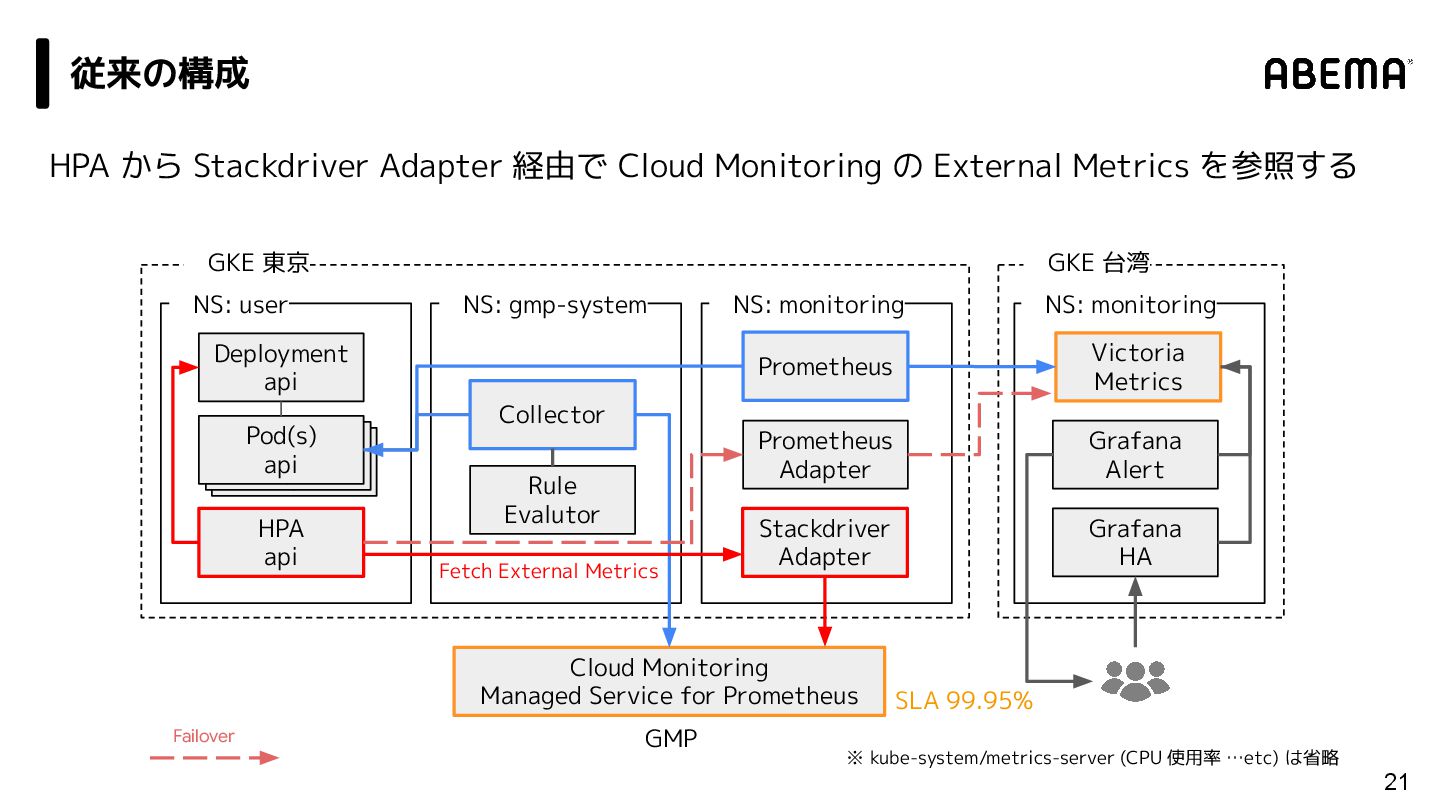{kind=link}
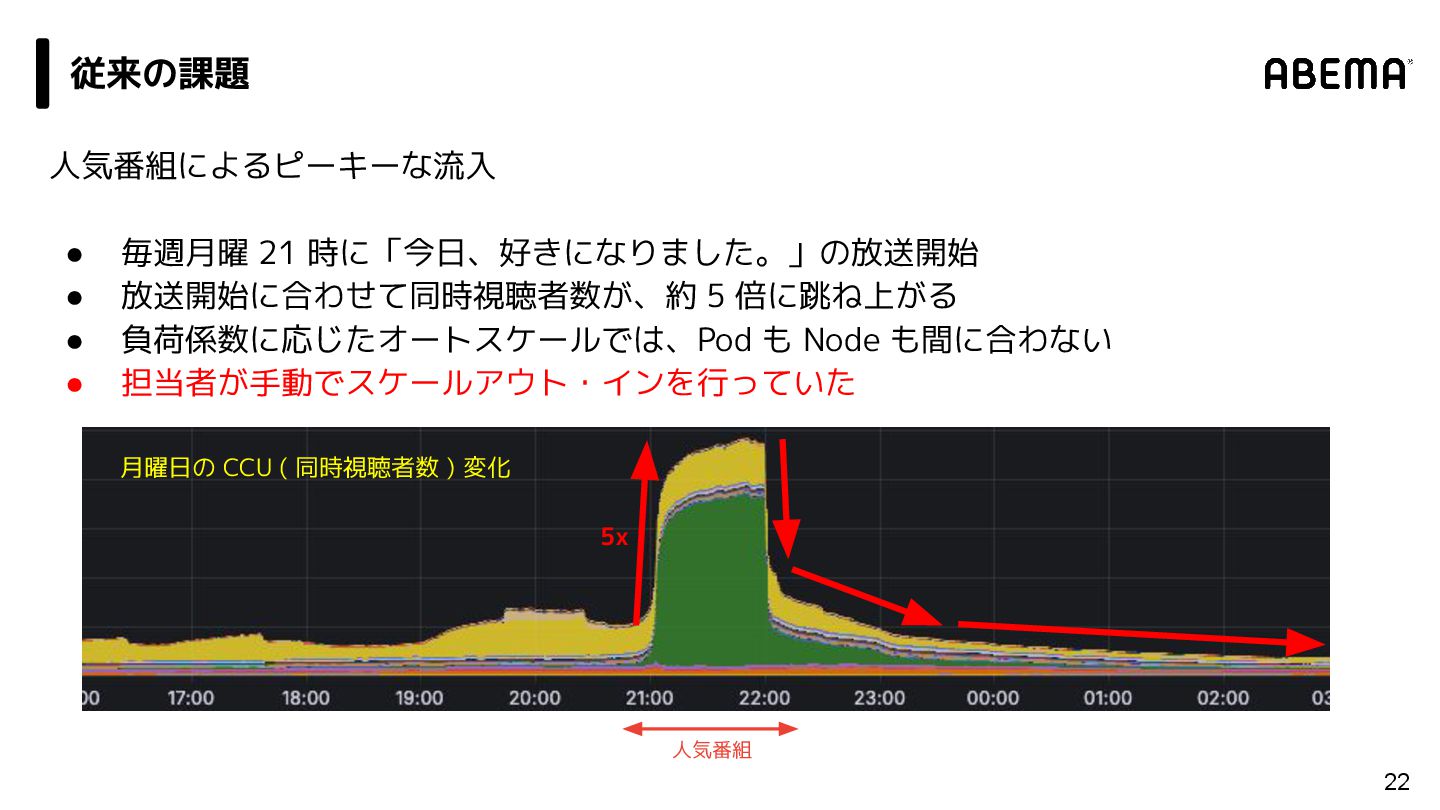{kind=link}
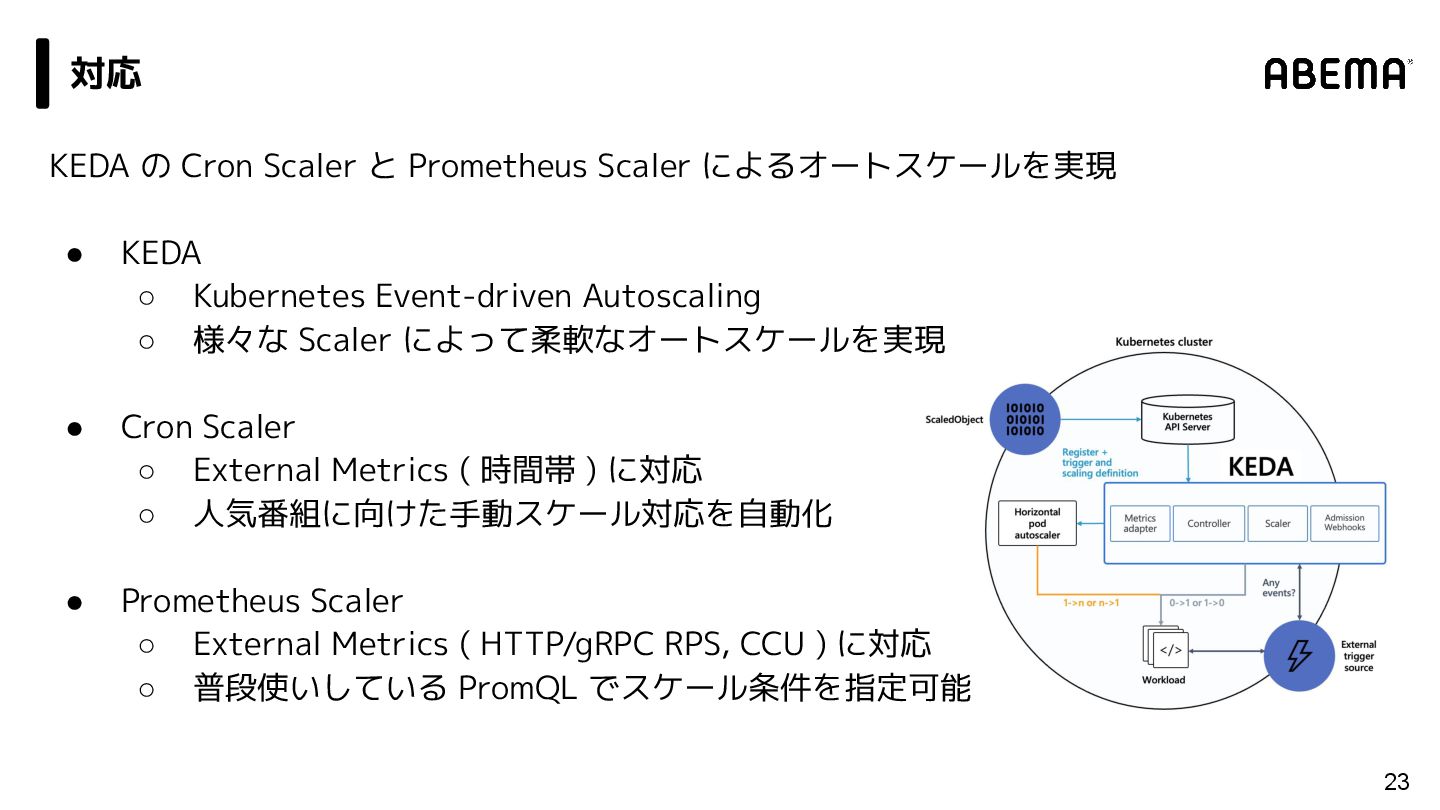{kind=link}
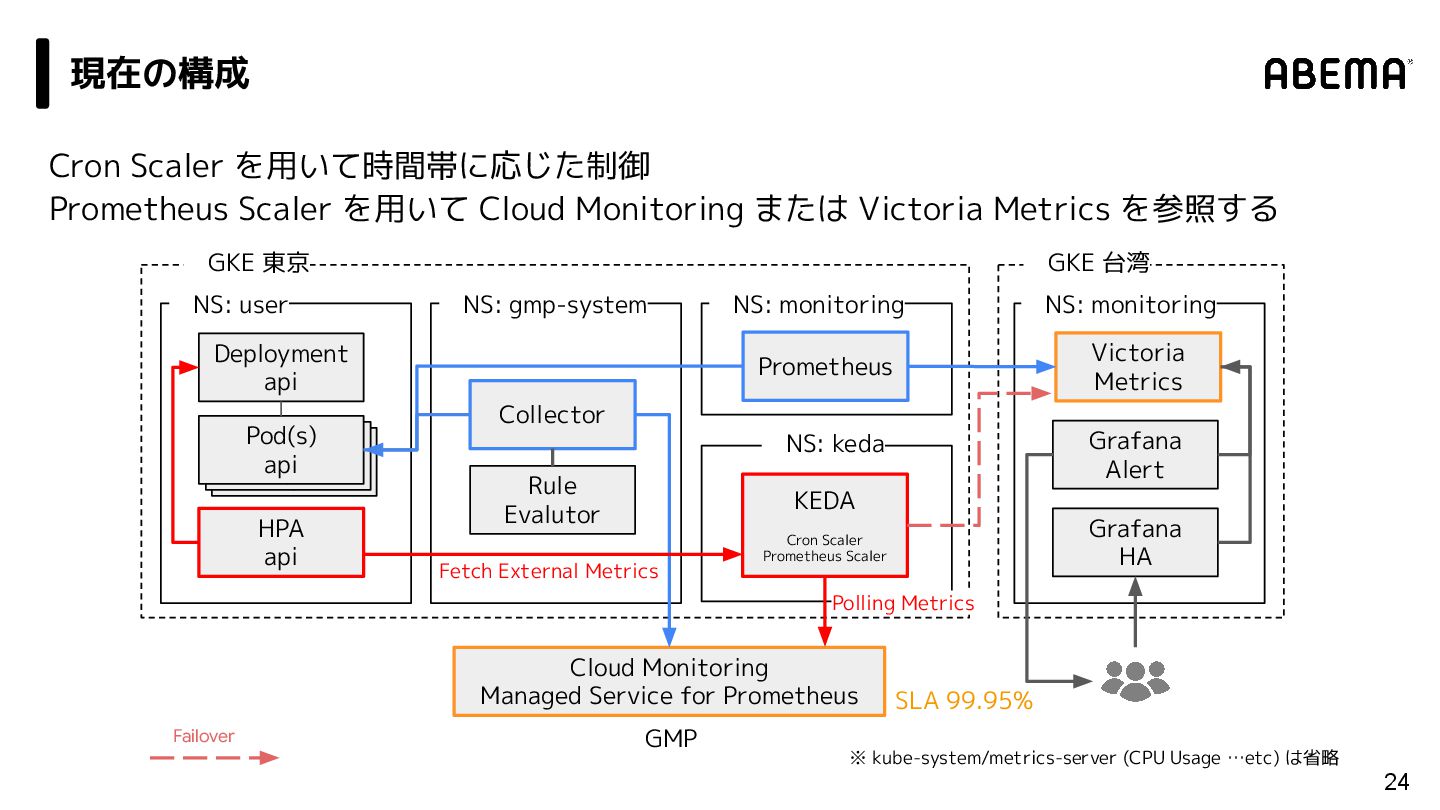{kind=link}
{kind=link}
{kind=link}
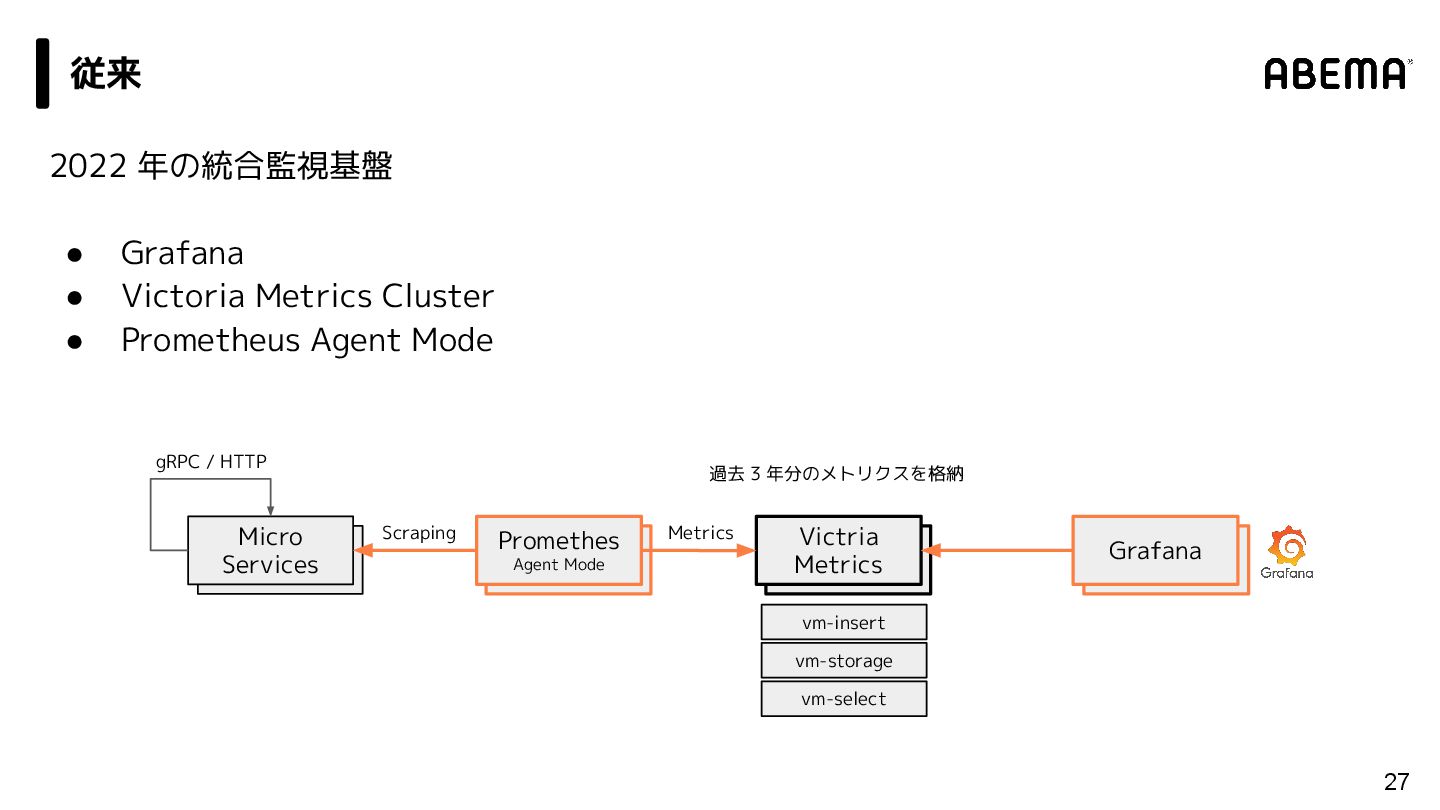{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
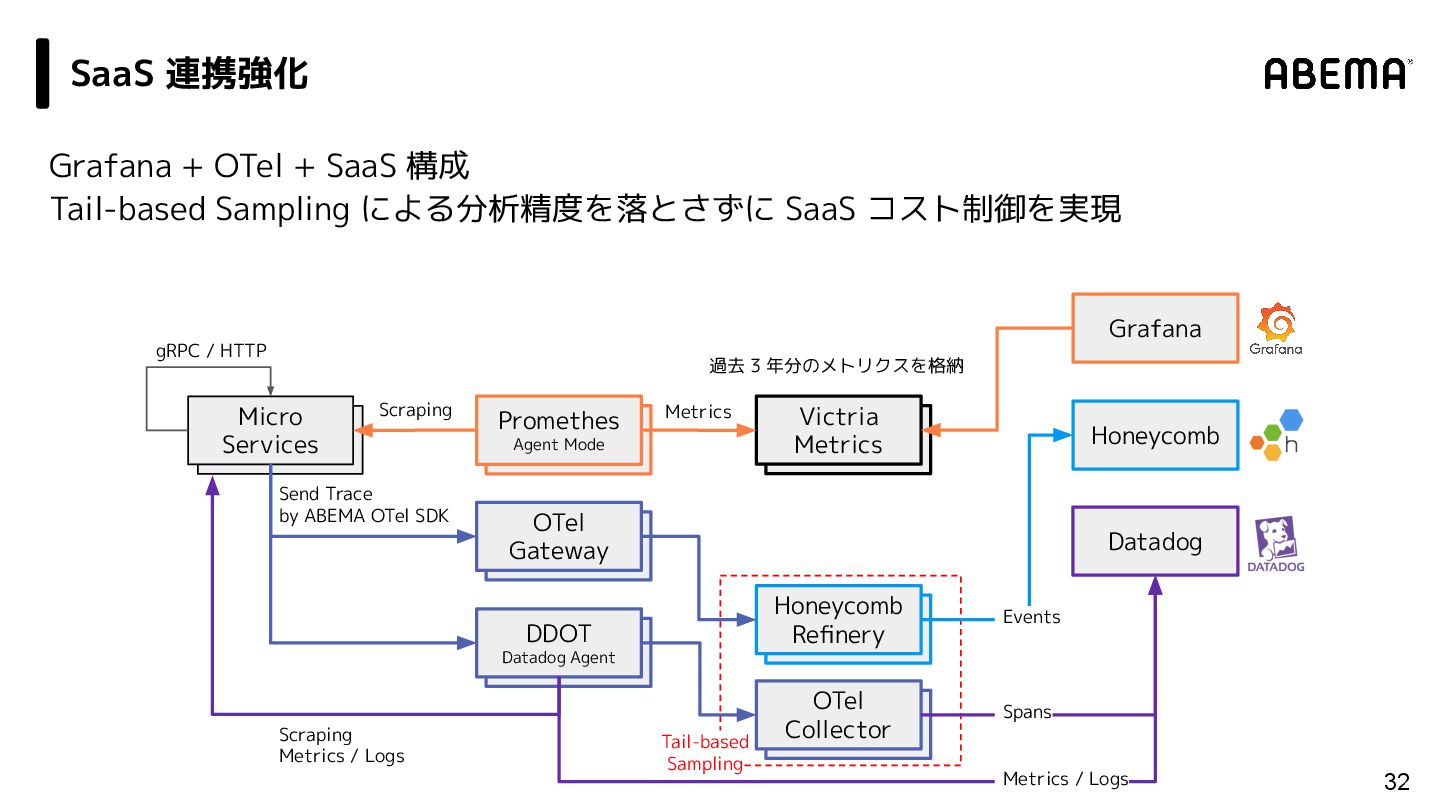{kind=link}
{kind=link}
{kind=link}
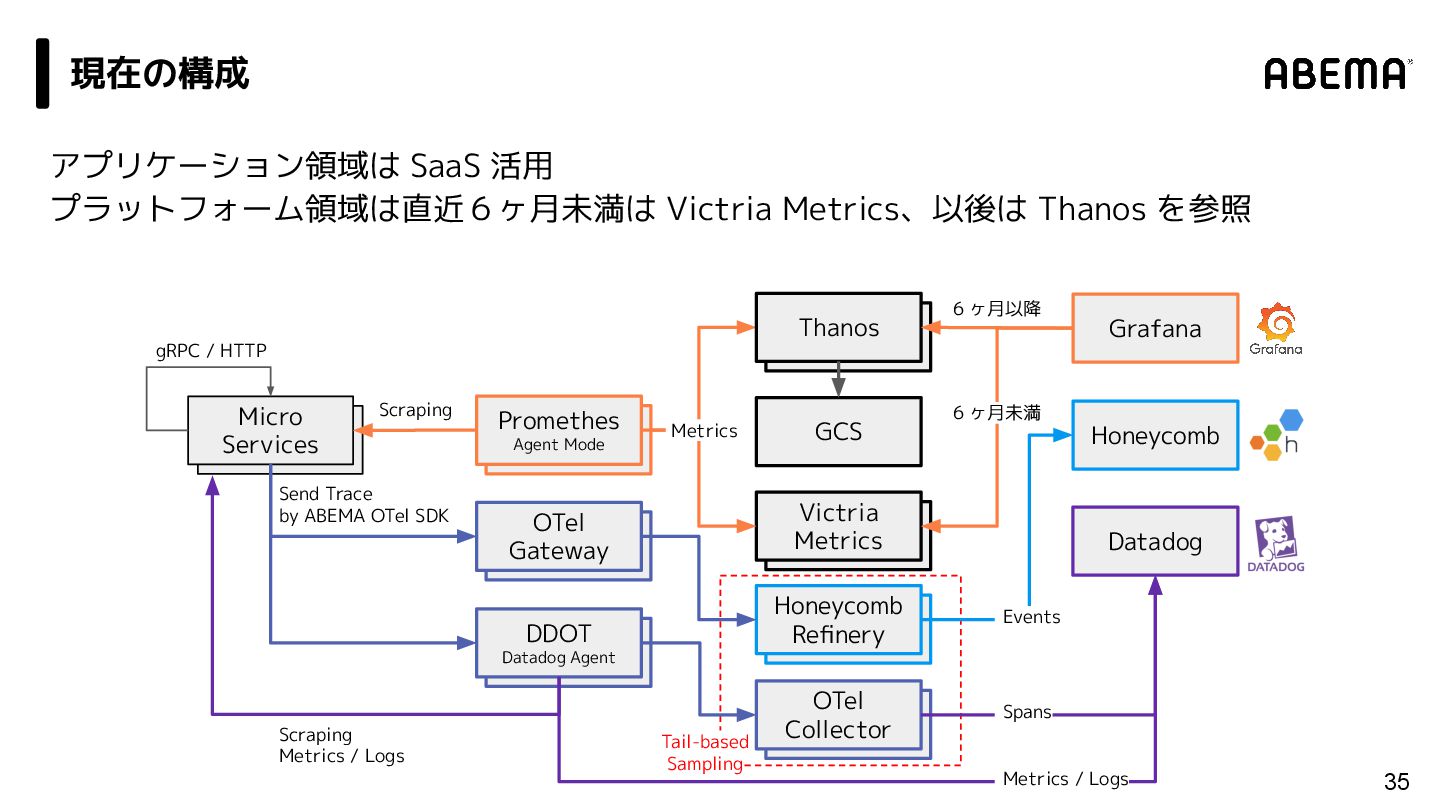{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
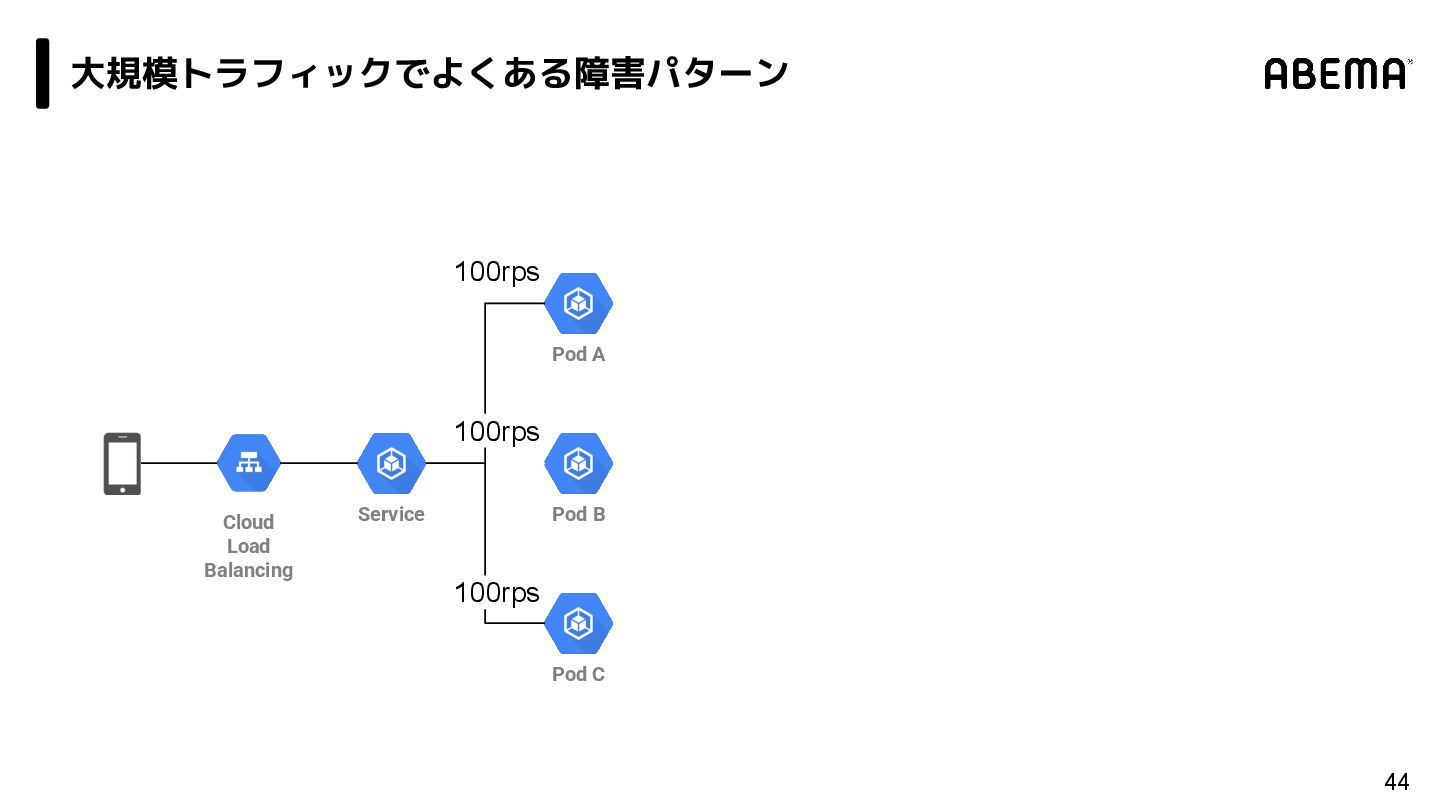{kind=link}
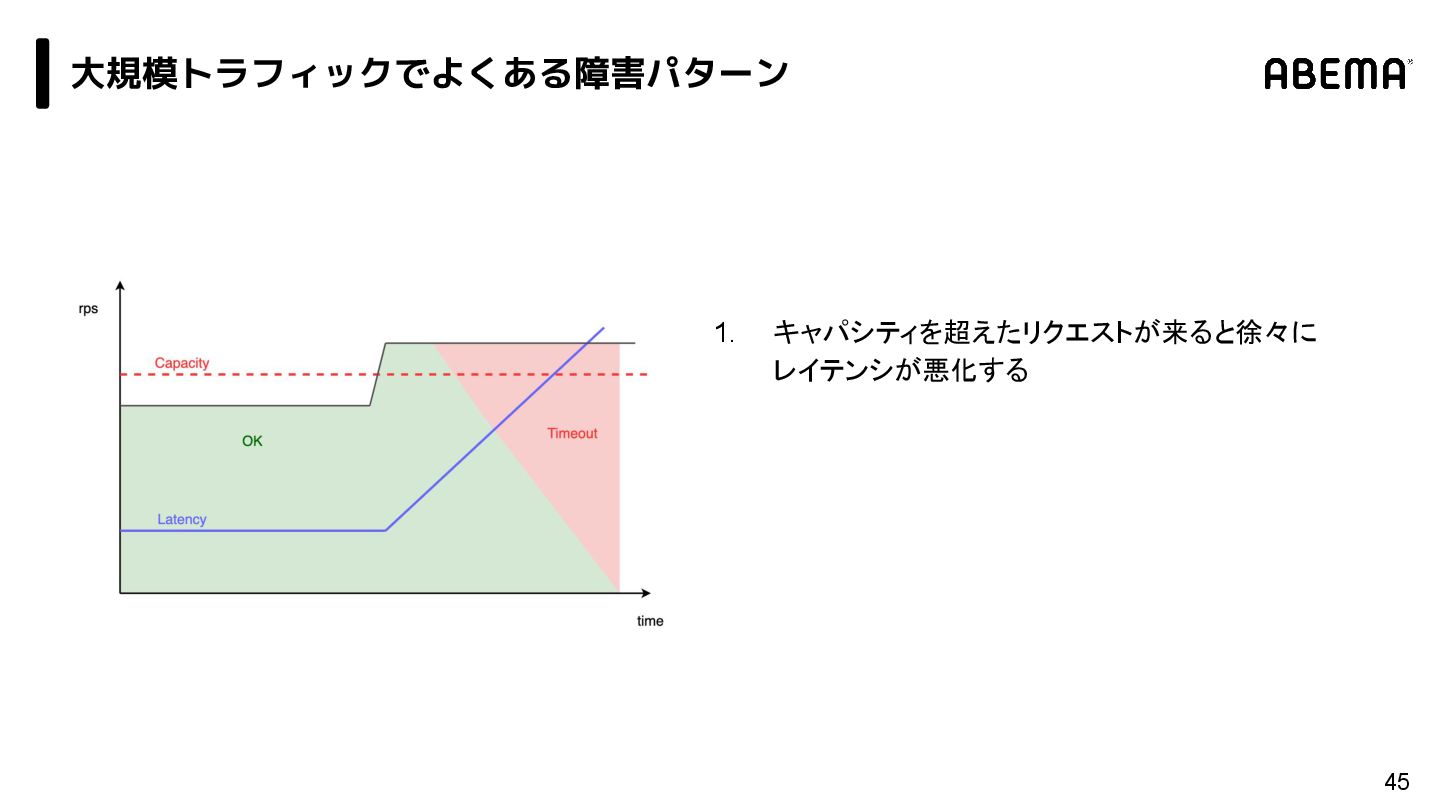{kind=link}
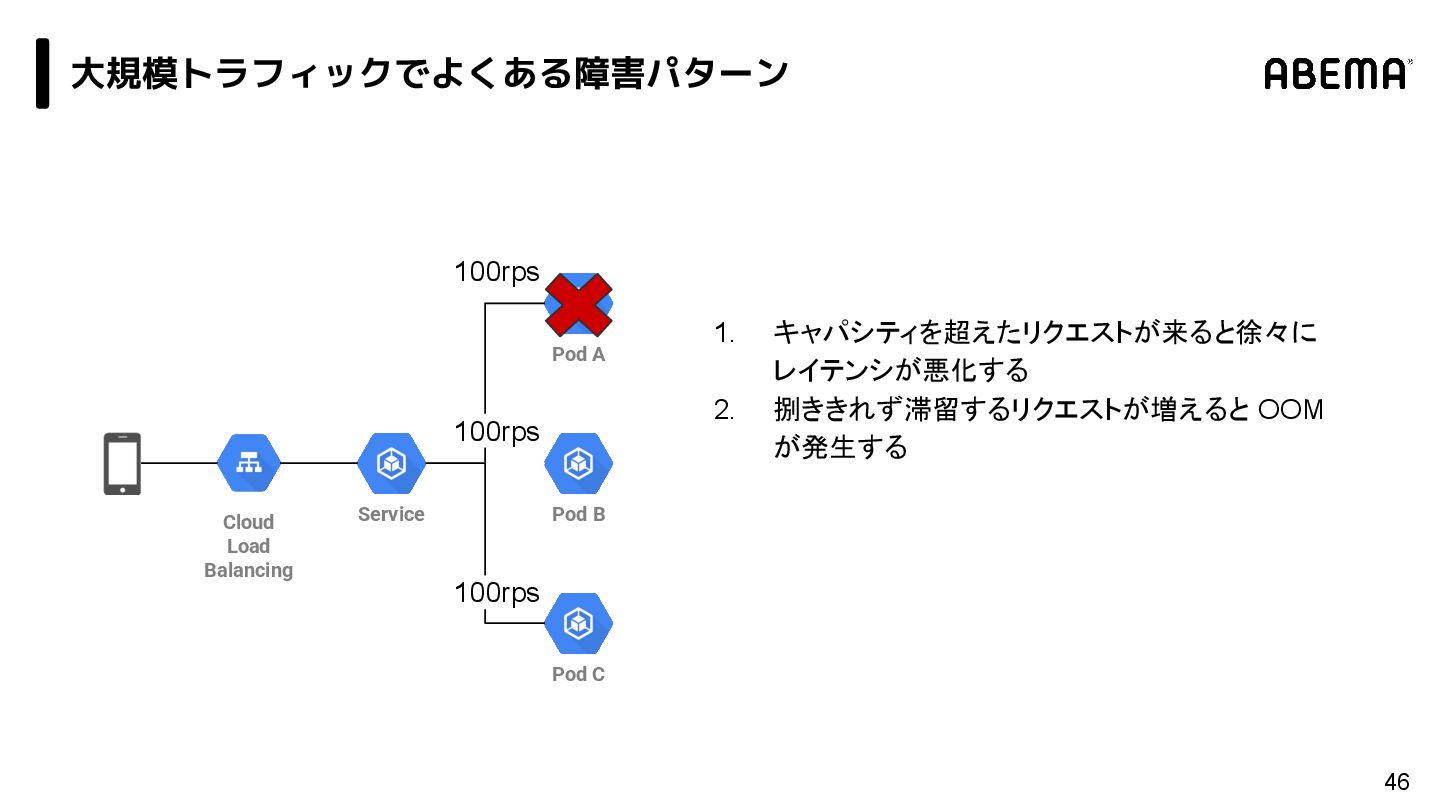{kind=link}
{kind=link}
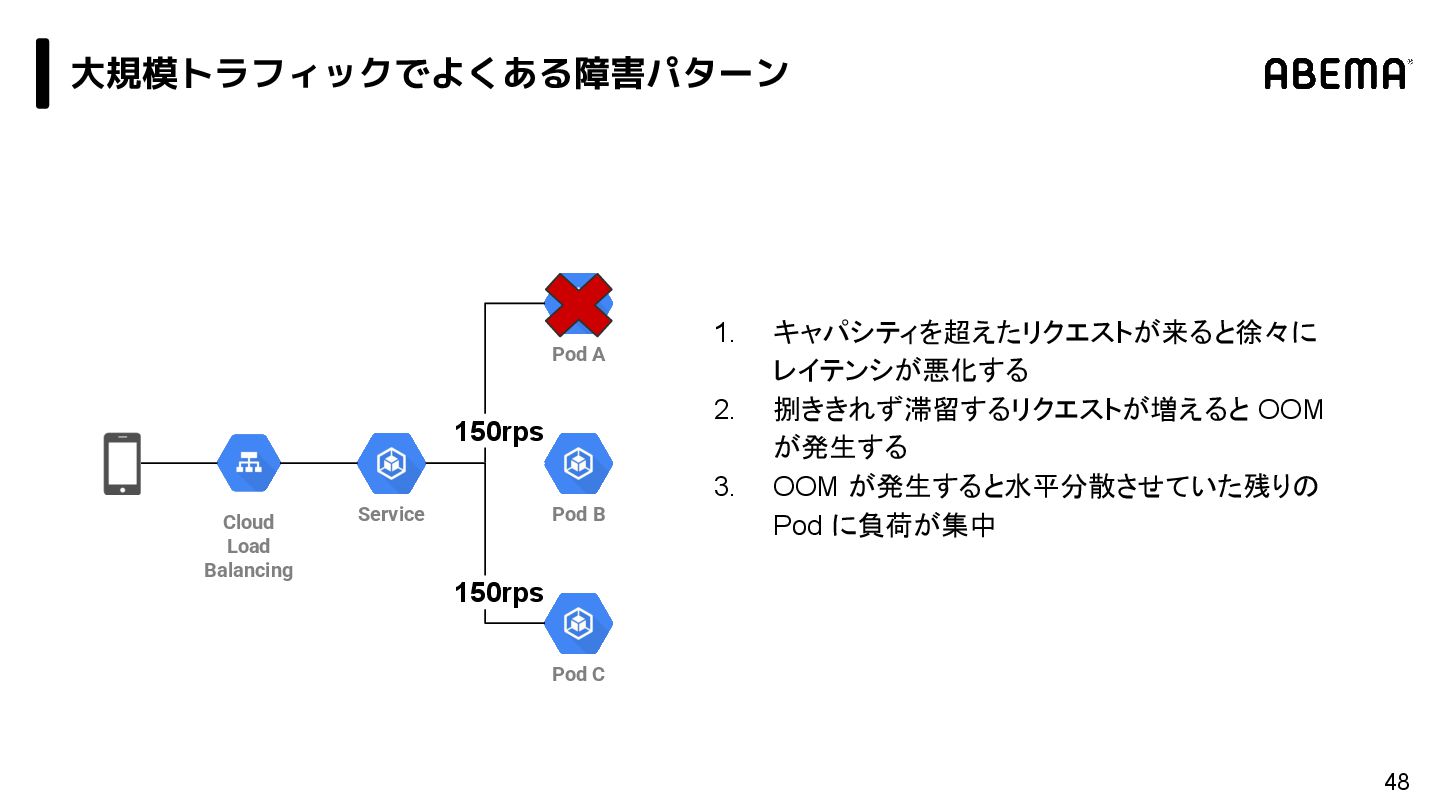{kind=link}
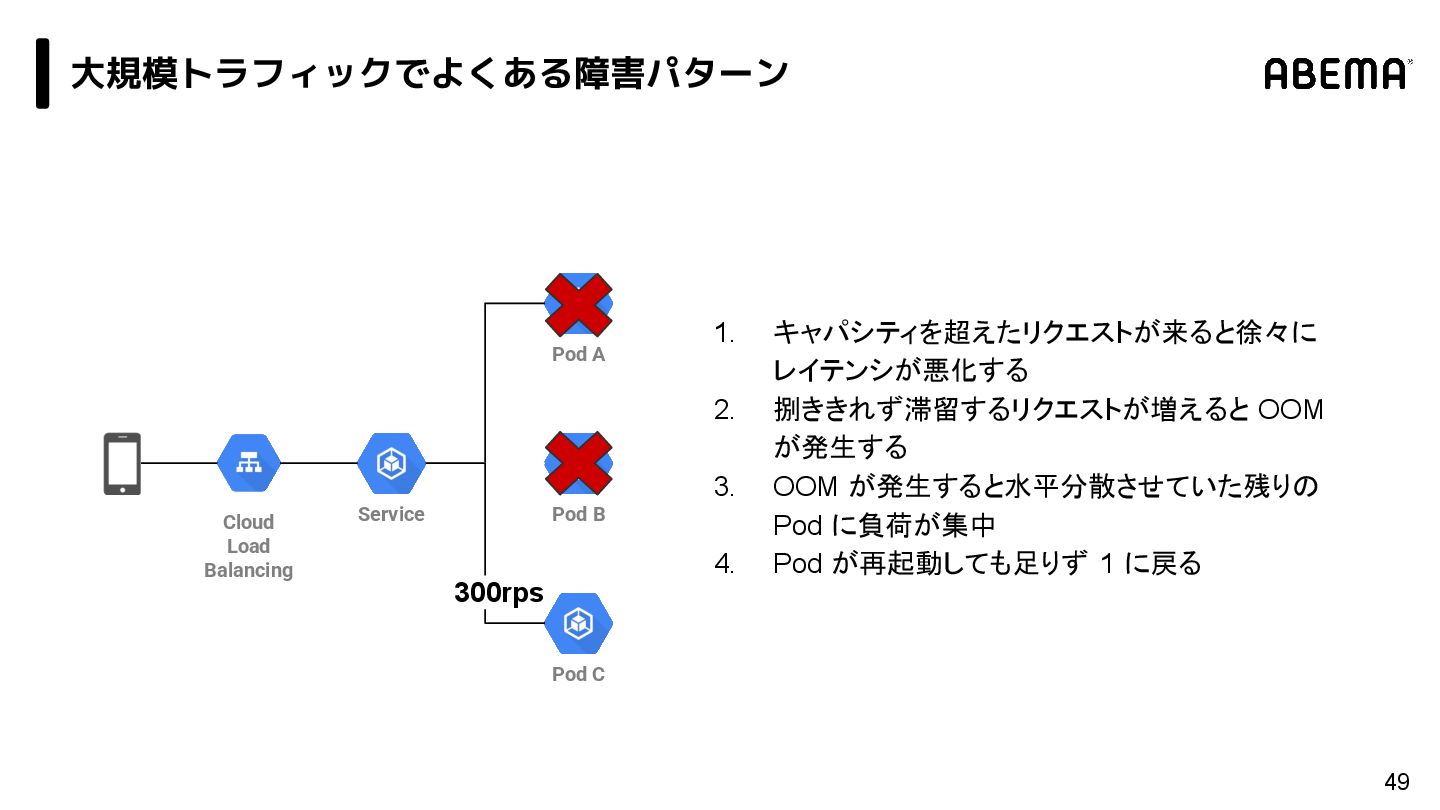{kind=link}
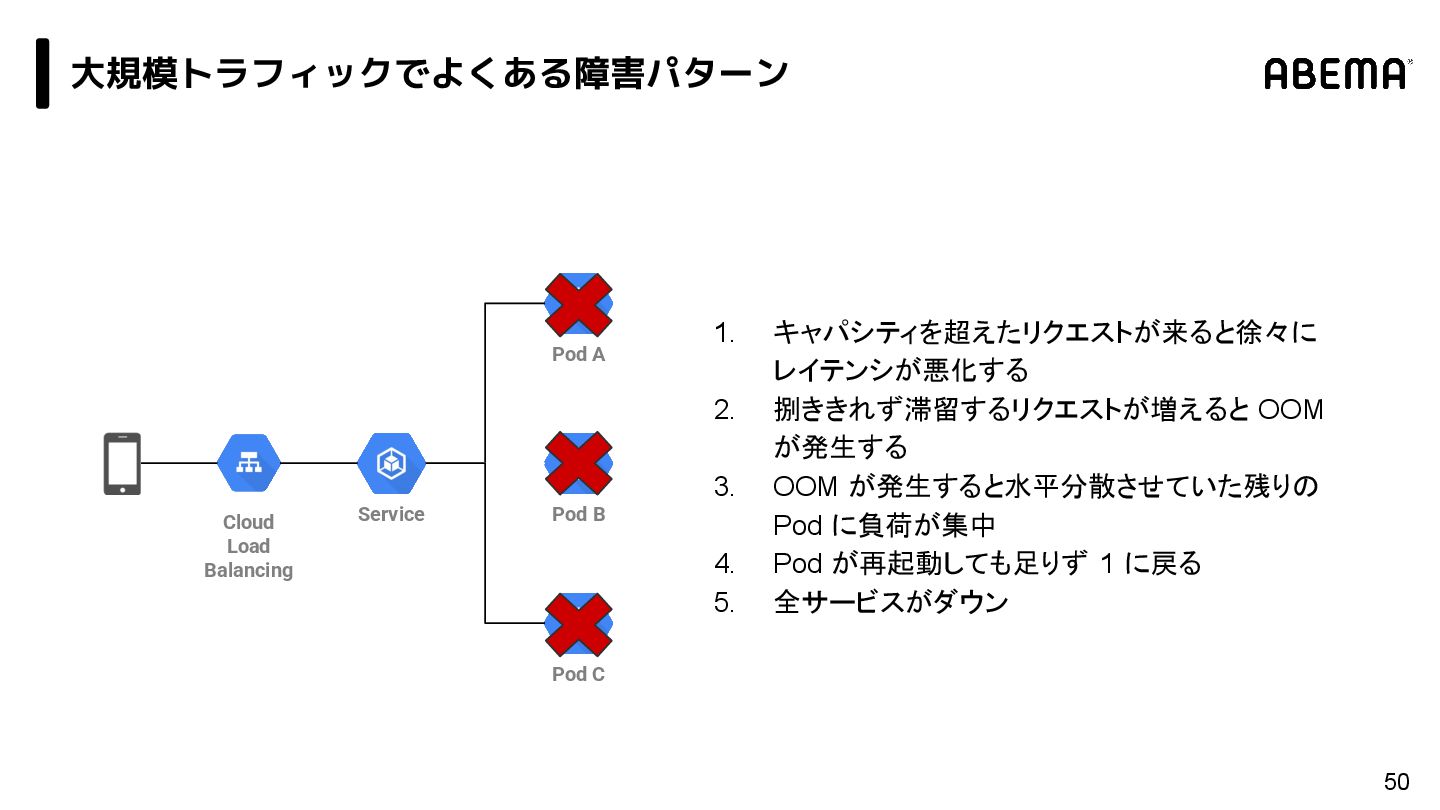{kind=link}
{kind=link}
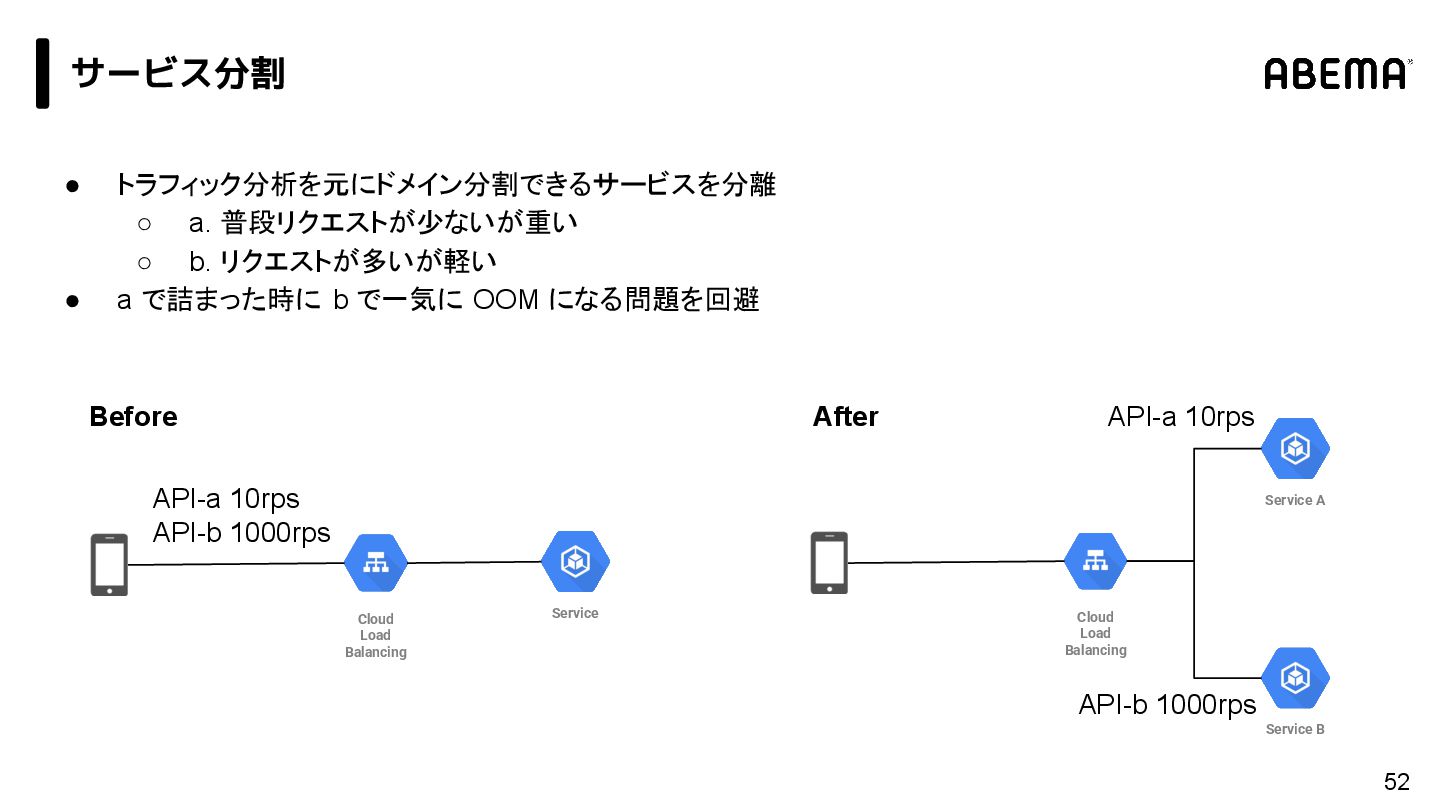{kind=link}
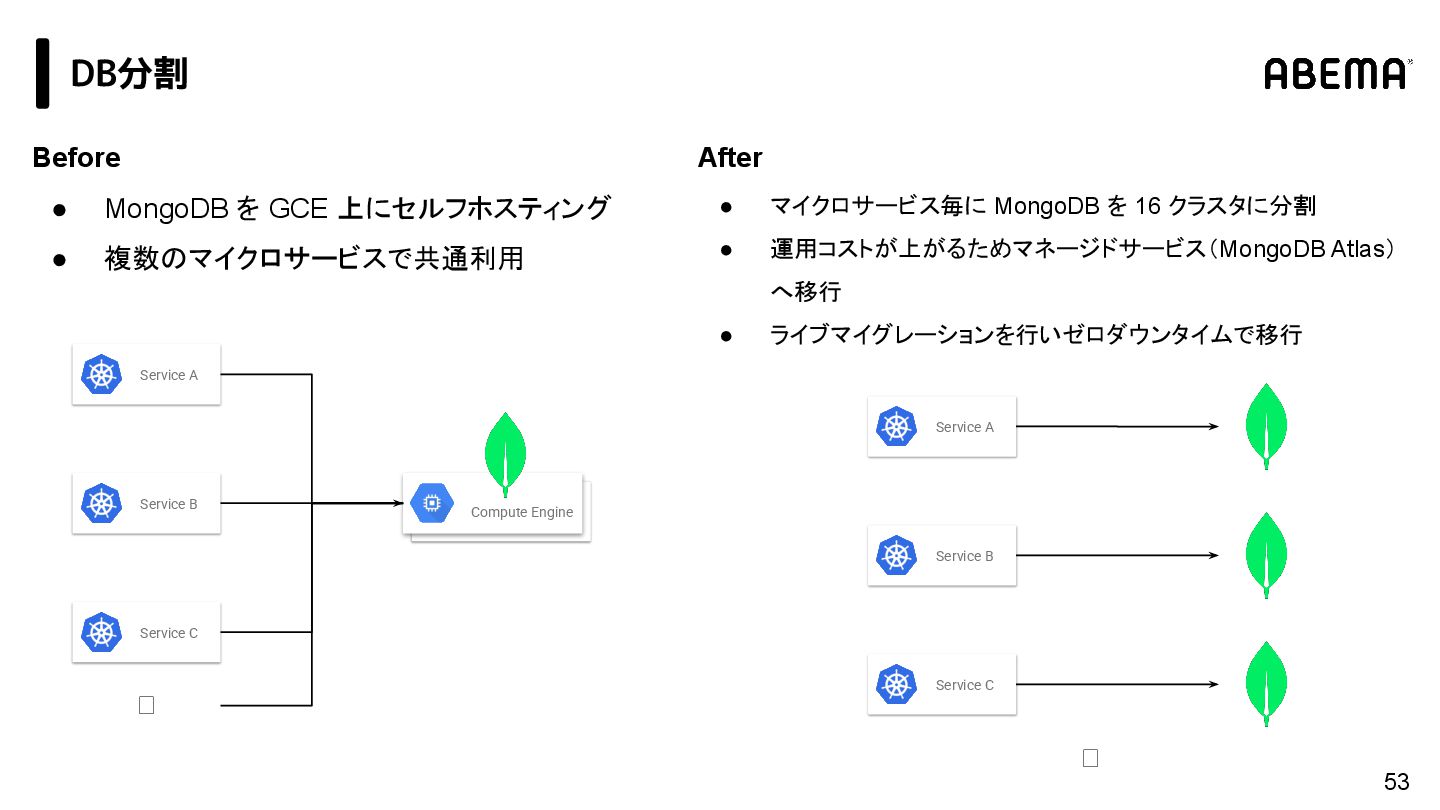{kind=link}
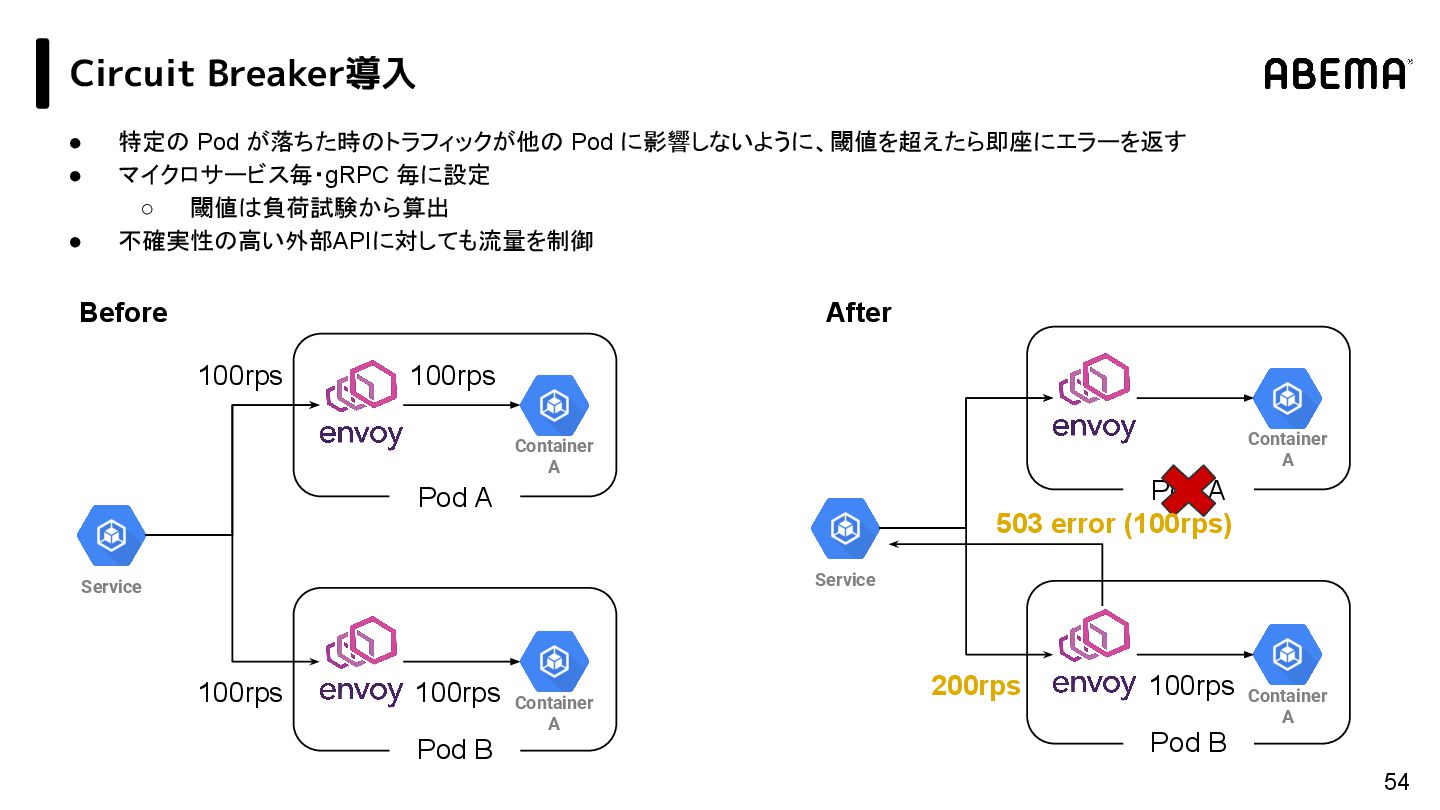{kind=link}
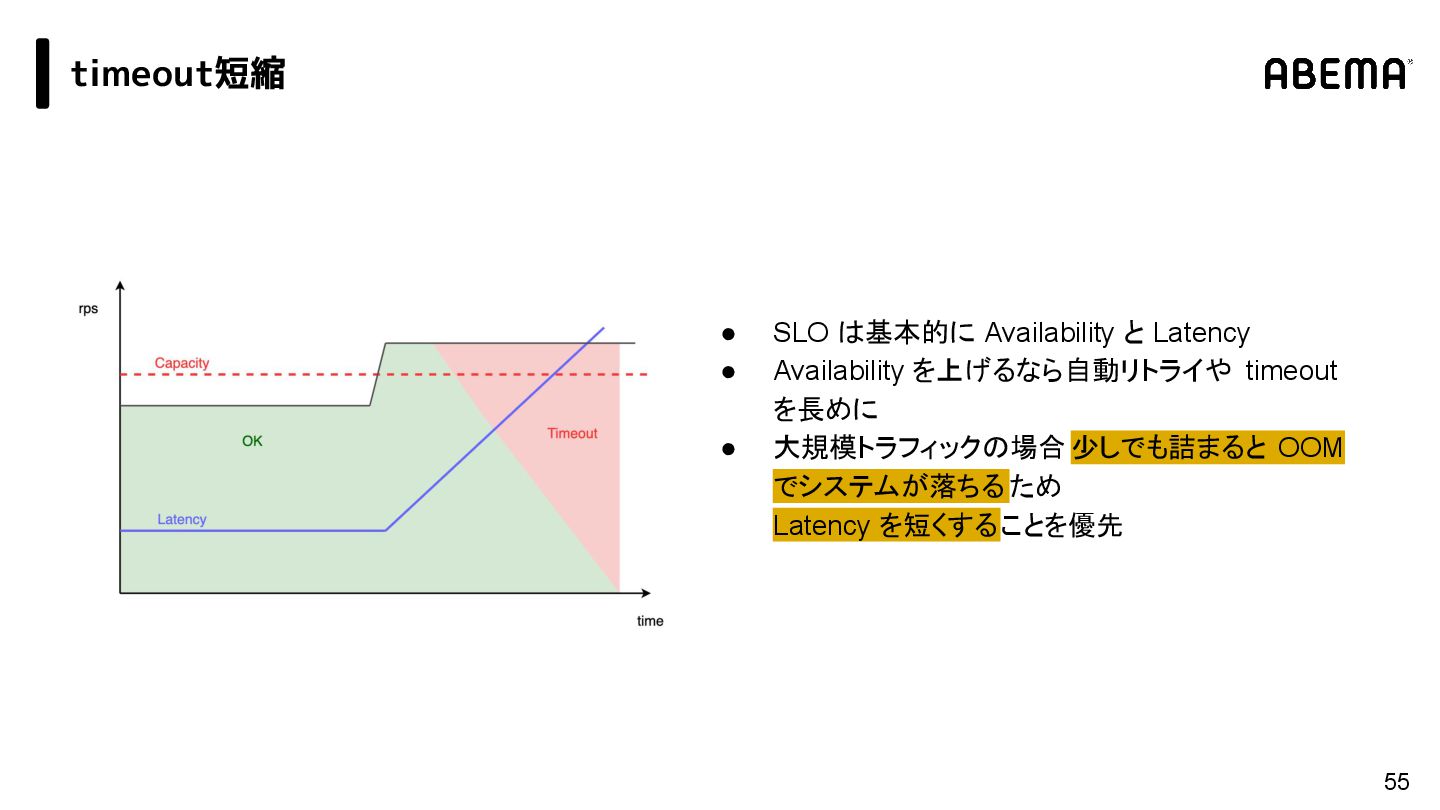{kind=link}
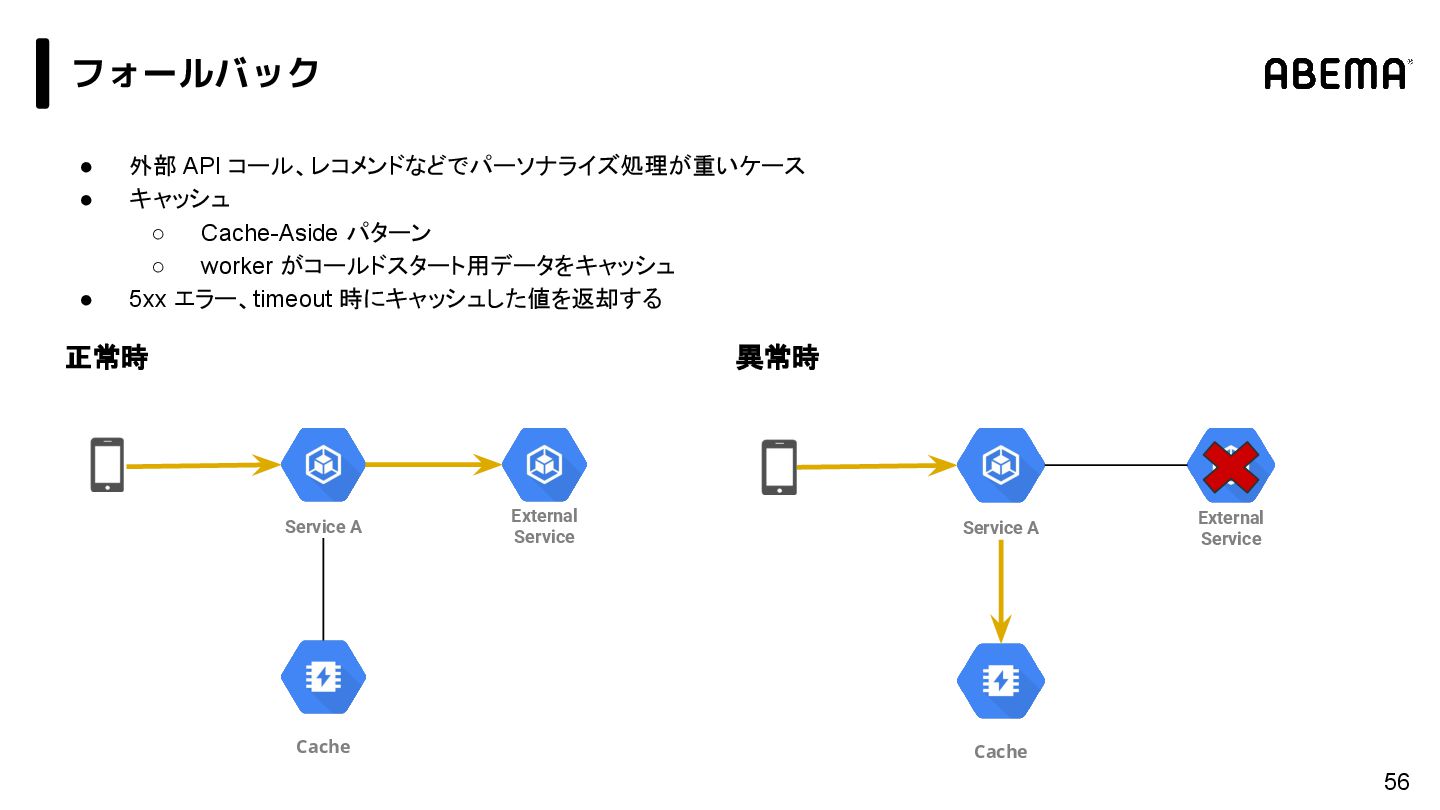{kind=link}
{kind=link}
{kind=link}
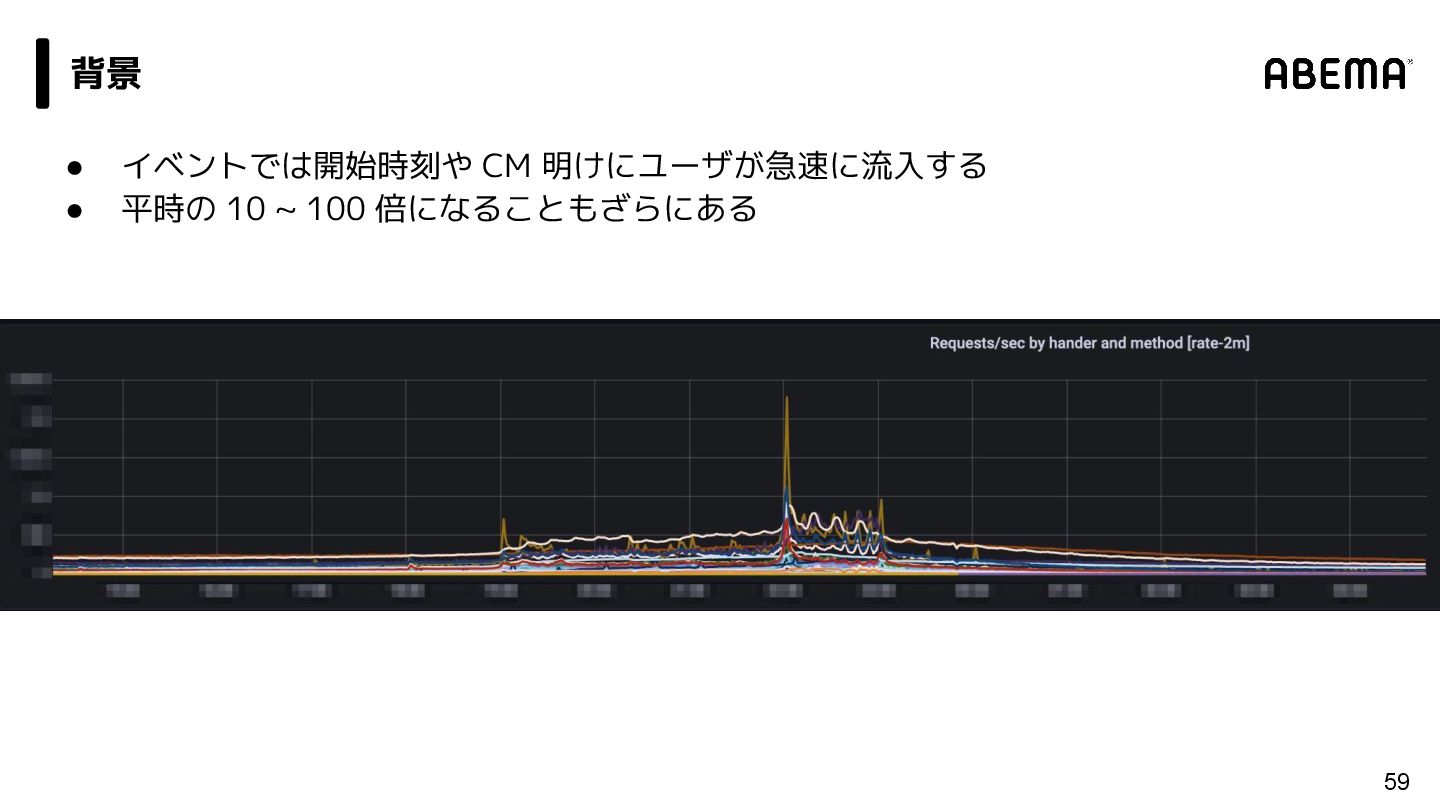{kind=link}
{kind=link}
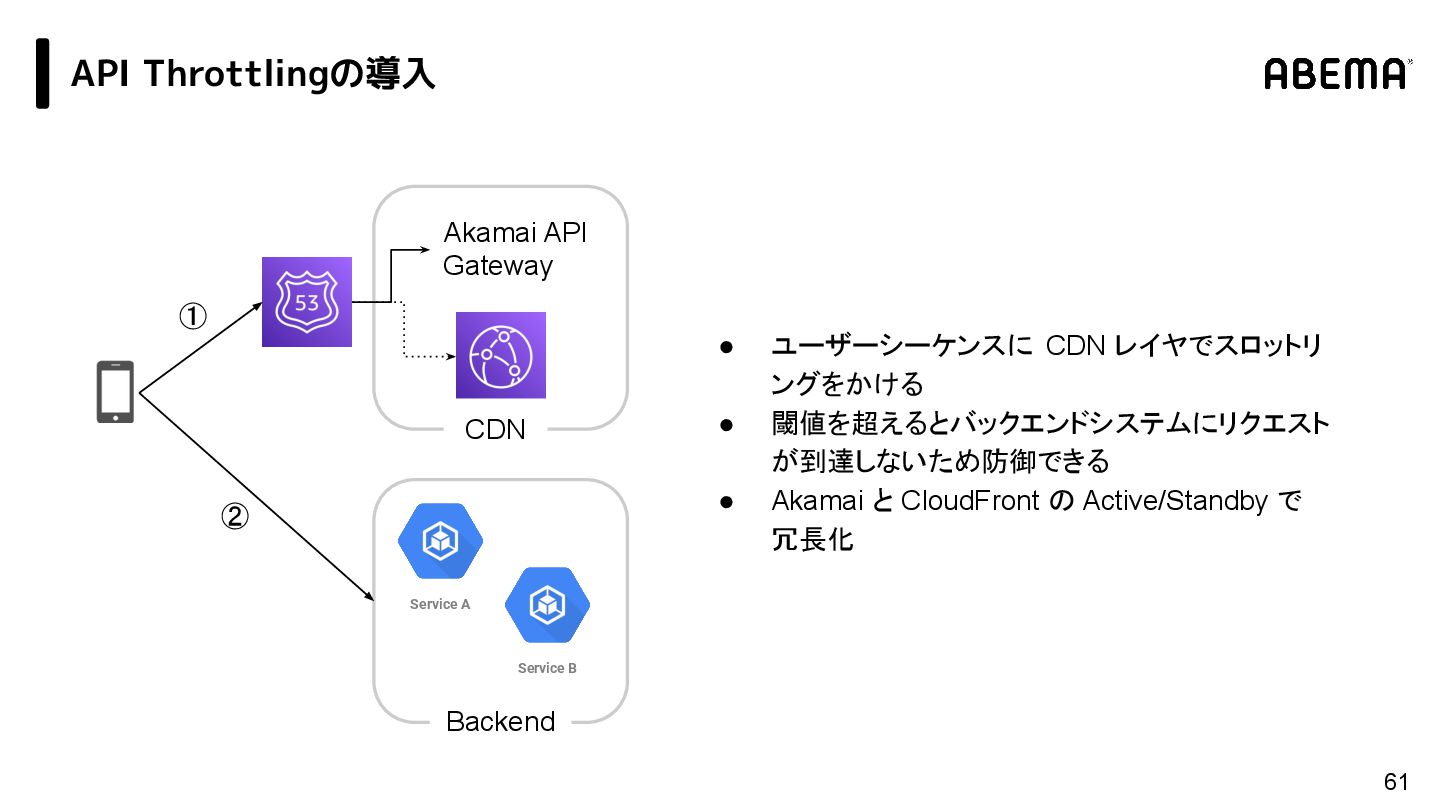{kind=link}
{kind=link}
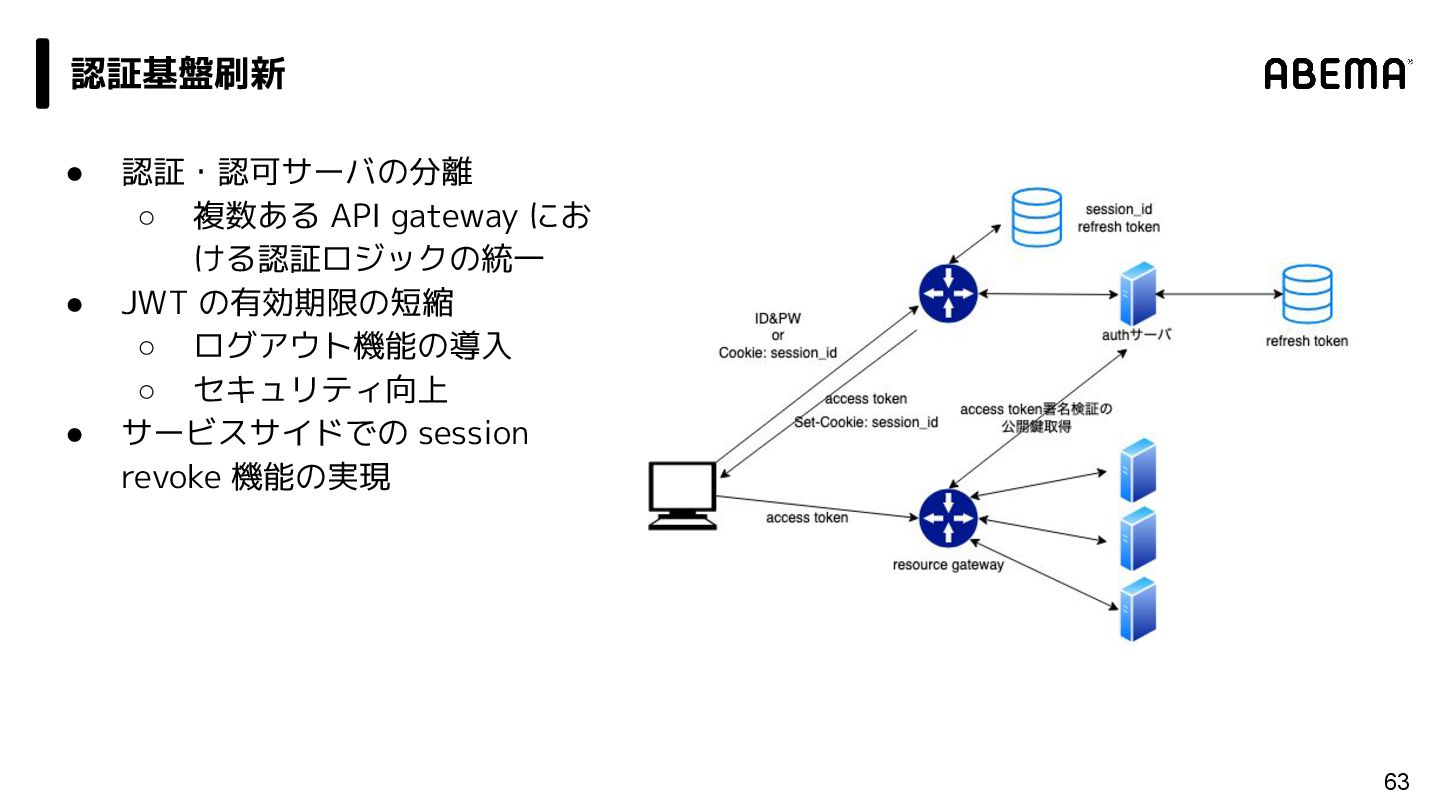{kind=link}
{kind=link}
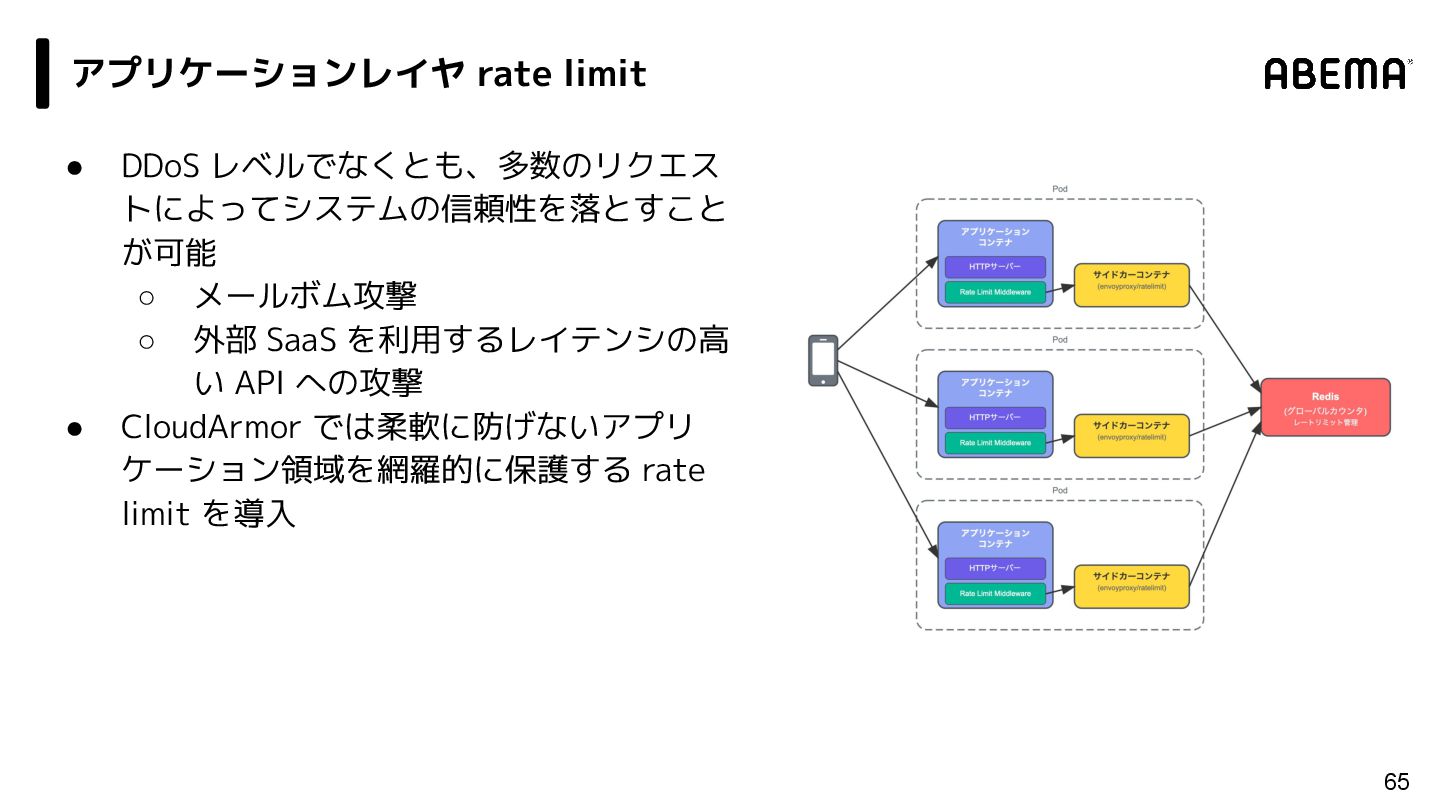{kind=link}
{kind=link}
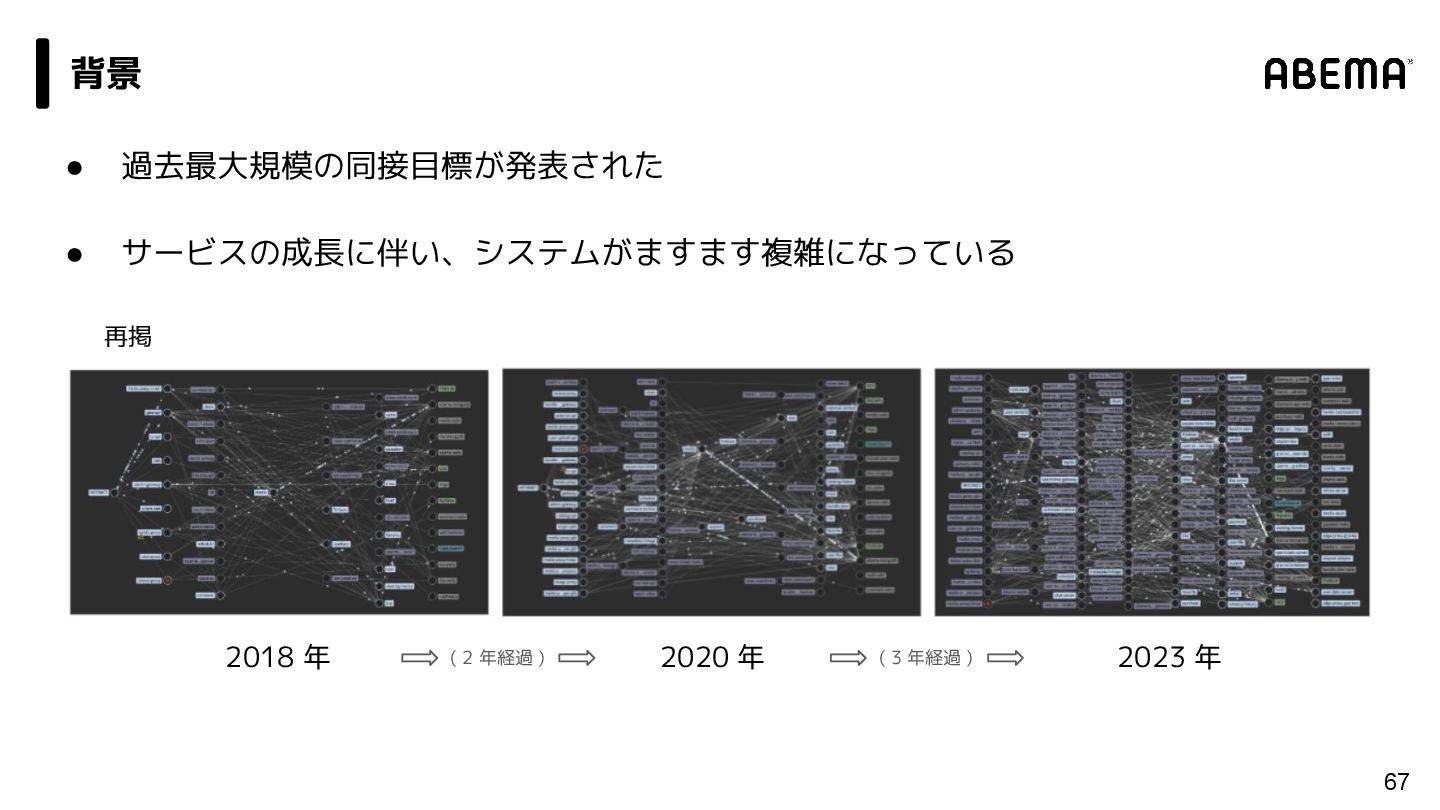{kind=link}
{kind=link}
{kind=link}
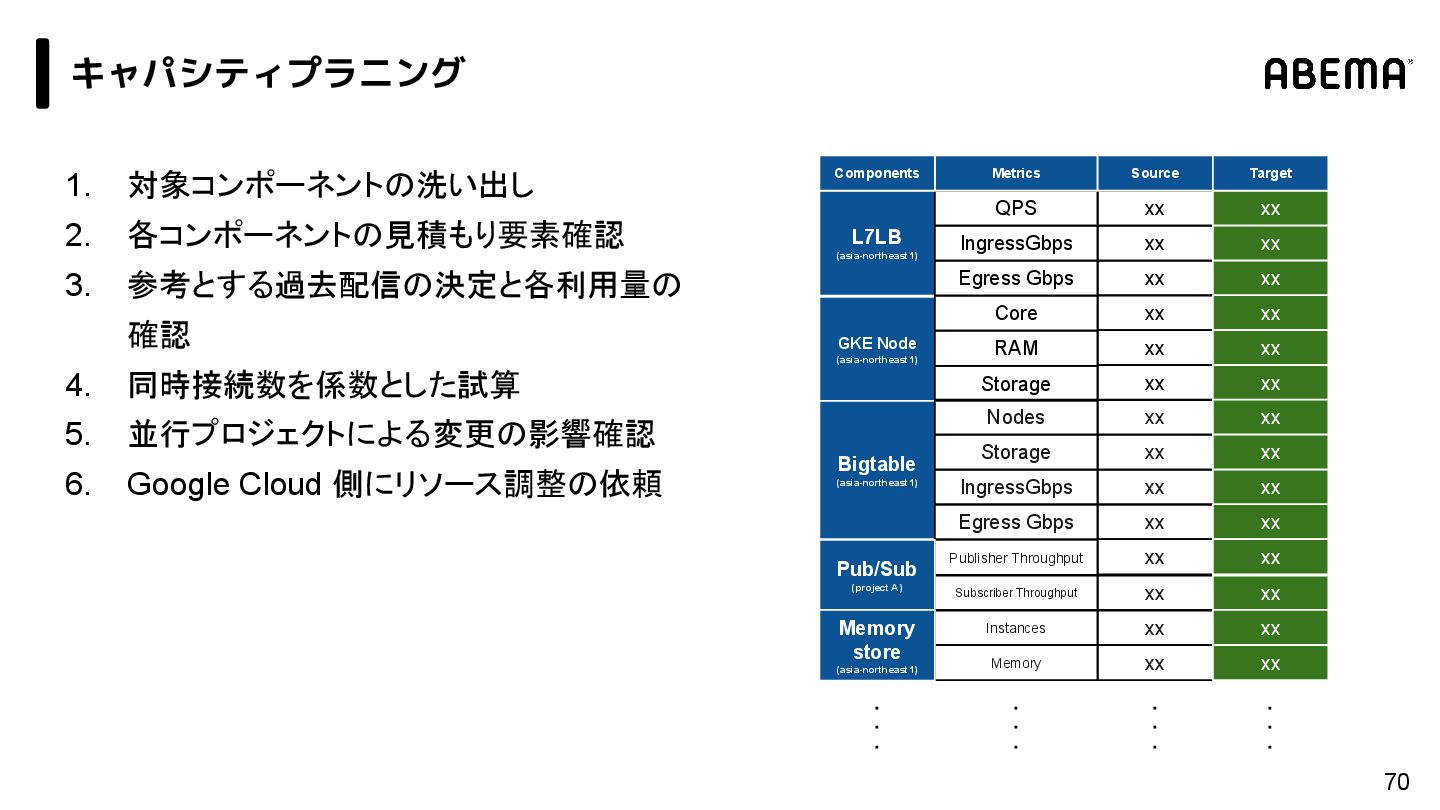{kind=link}
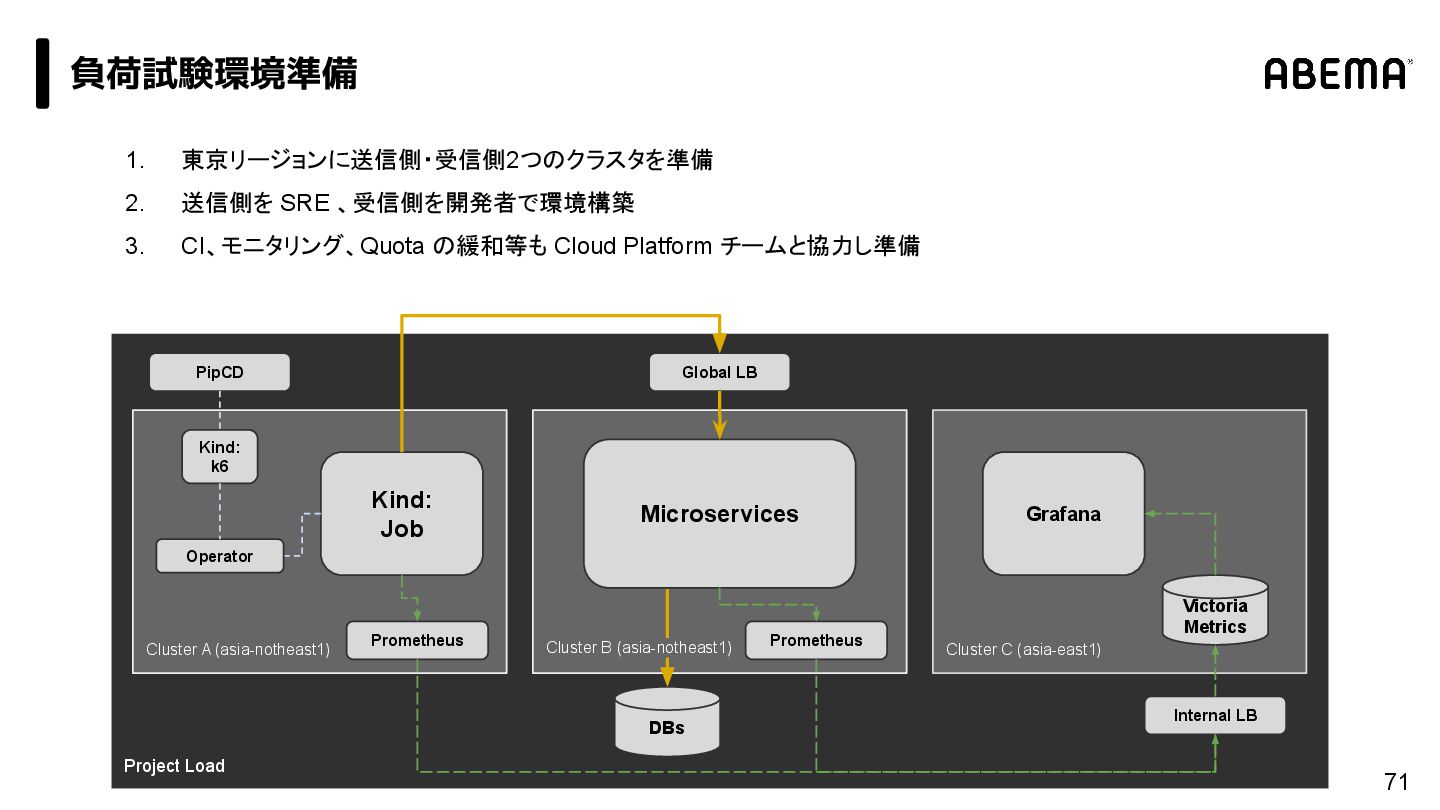{kind=link}
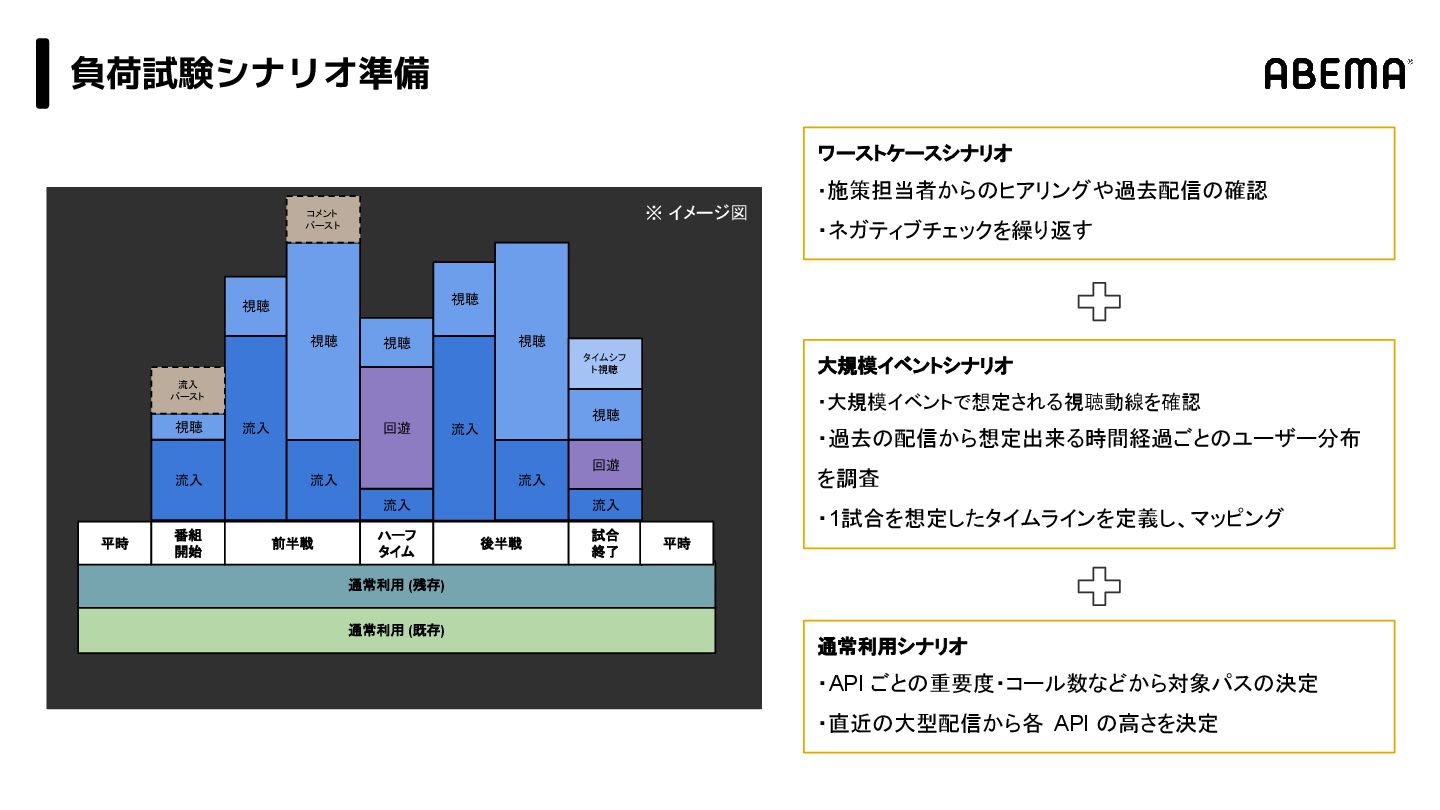{kind=link}
{kind=link}
{kind=link}
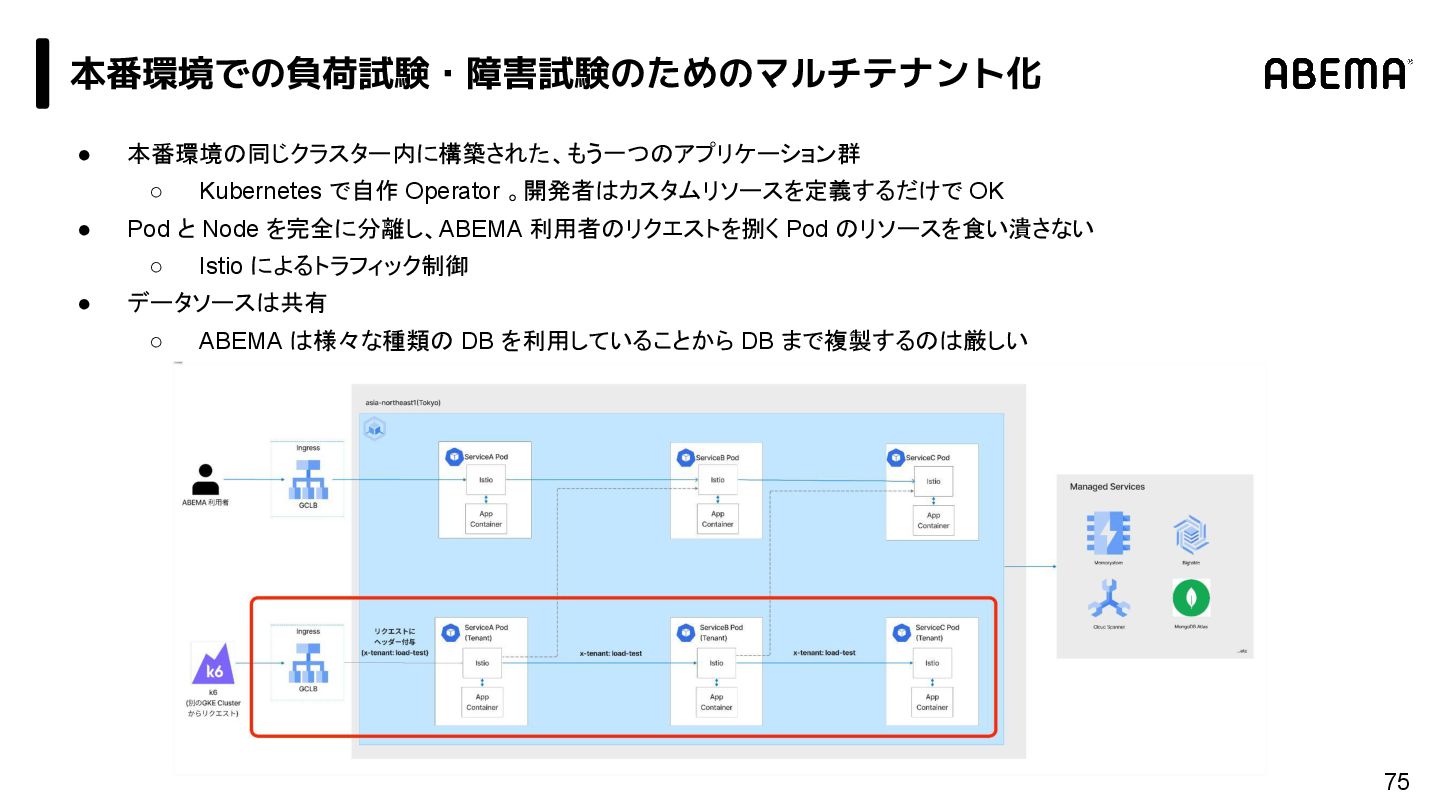{kind=link}
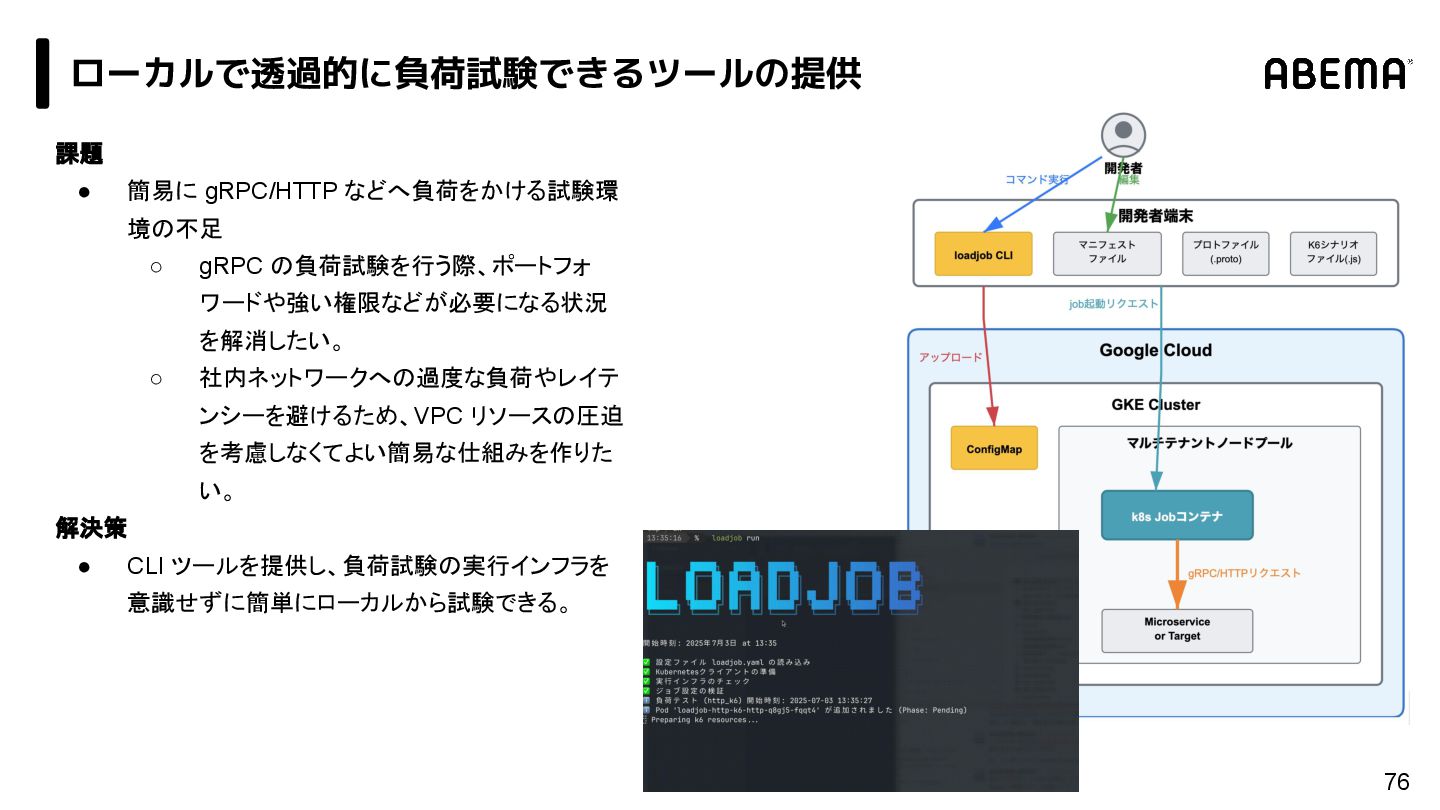{kind=link}
{kind=link}
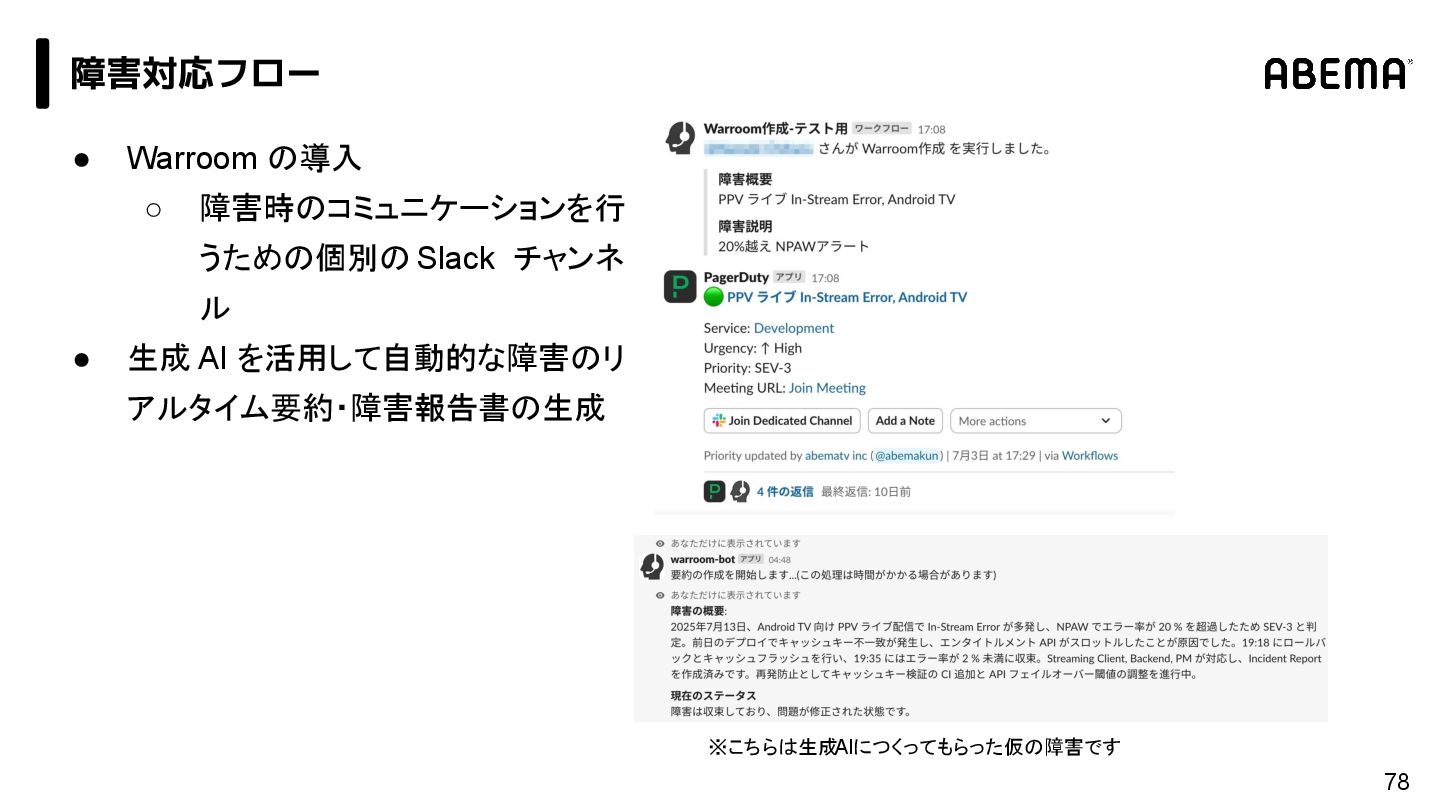{kind=link}
{kind=link}
{kind=link}
{kind=link}