Share
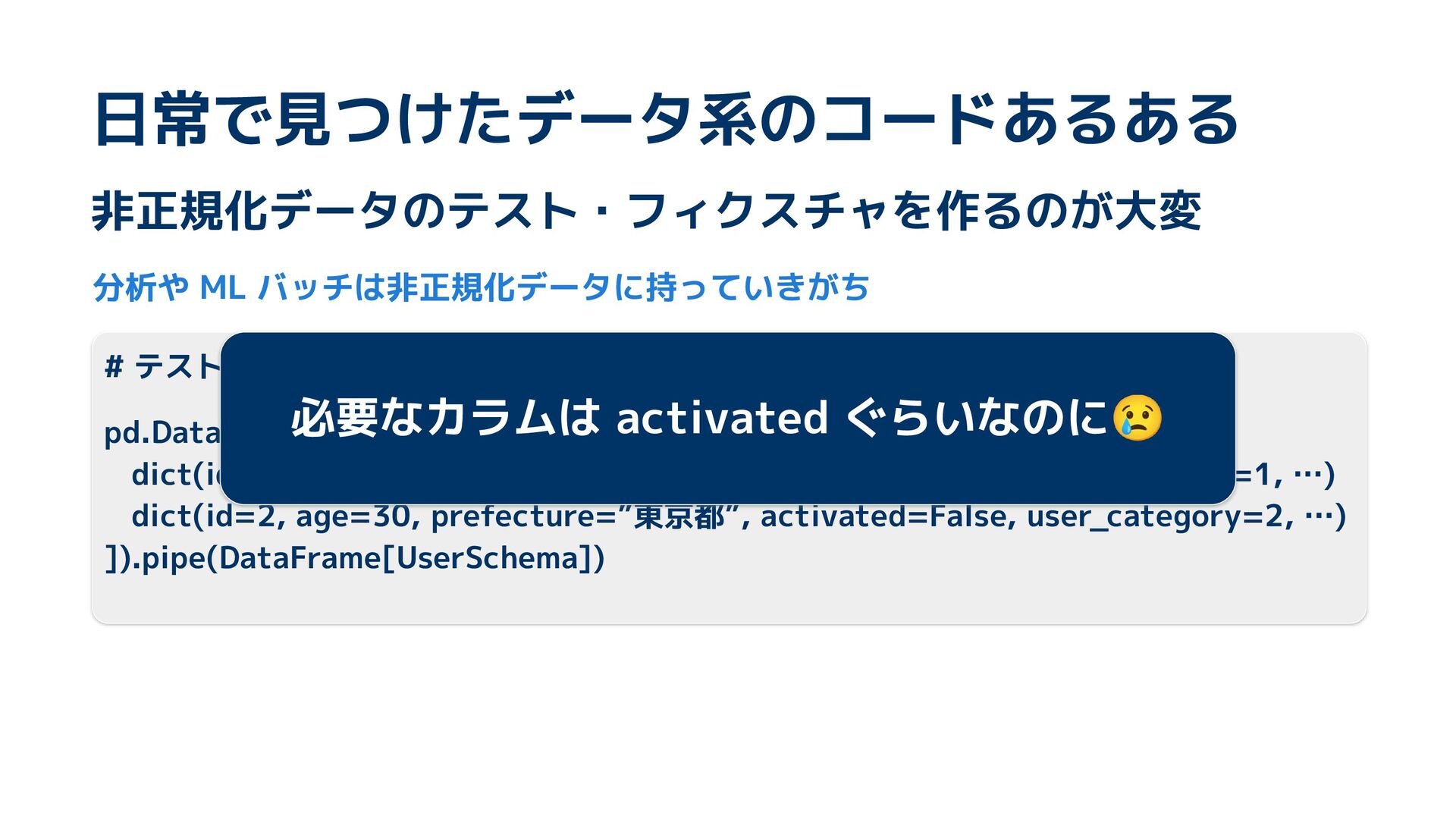
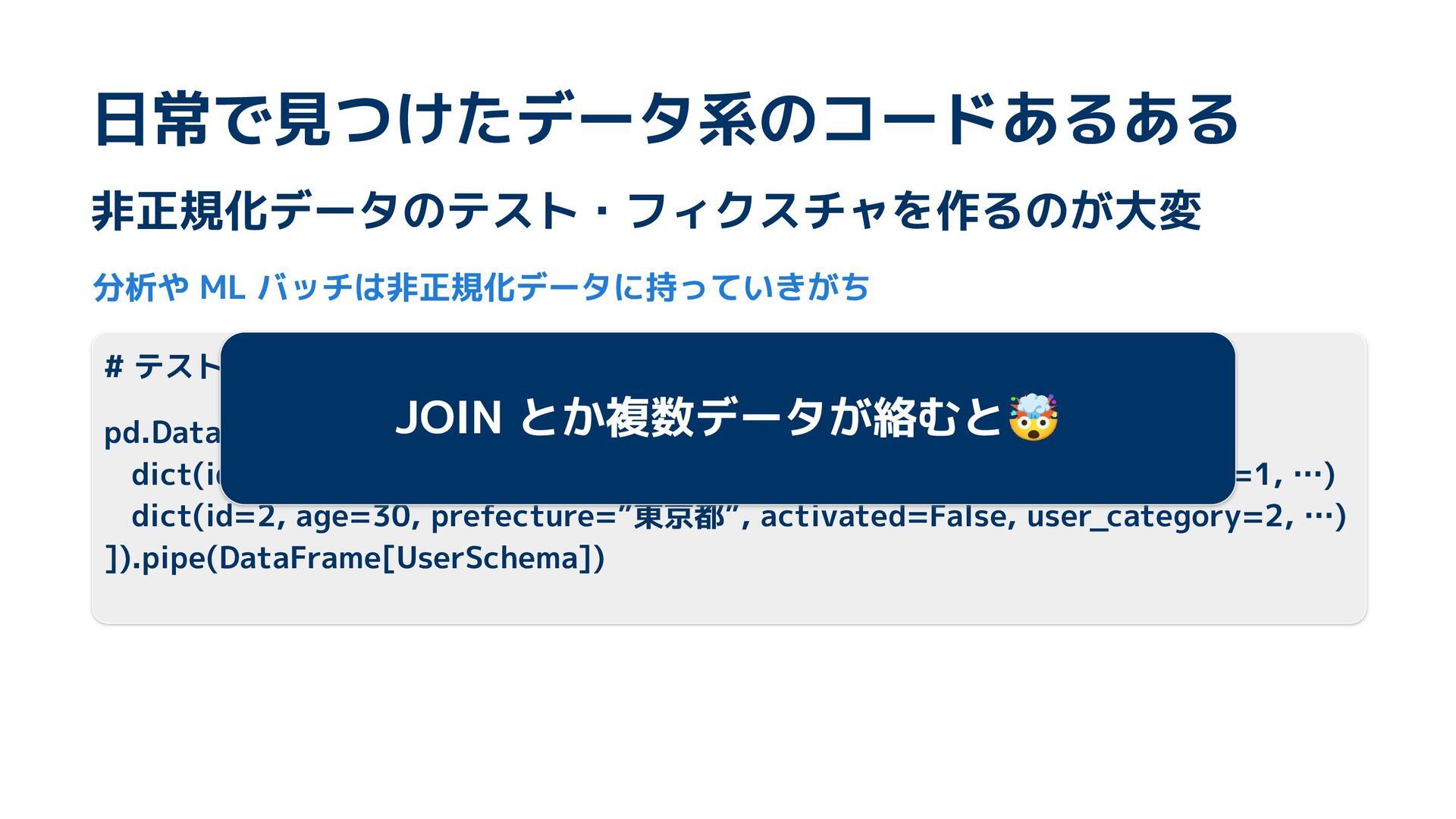
テーブルデータのテスト準備、その繰り返しの多さに「もっと楽にならないか?」と感じたことはありませんか?今回、そんなの日常的な悩みを解決するため、Rustで開発したパワフルなコード生成ツールを作成しました!RustでPythonのコードを解析するという、ちょっと不思議でギークなアプローチを通じて、型安全に退屈な作業を自動化するツールの開発方法についてお話します!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![完全に理解した、方針を立てよう 退屈なコードを自動生成できれば OK! class UserSchema(pa.DataFrameModel): id: Series[int] = Fields(...) activated:](https://files.speakerdeck.com/presentations/c4867480eaff4e65bc861f3434f2aca3/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
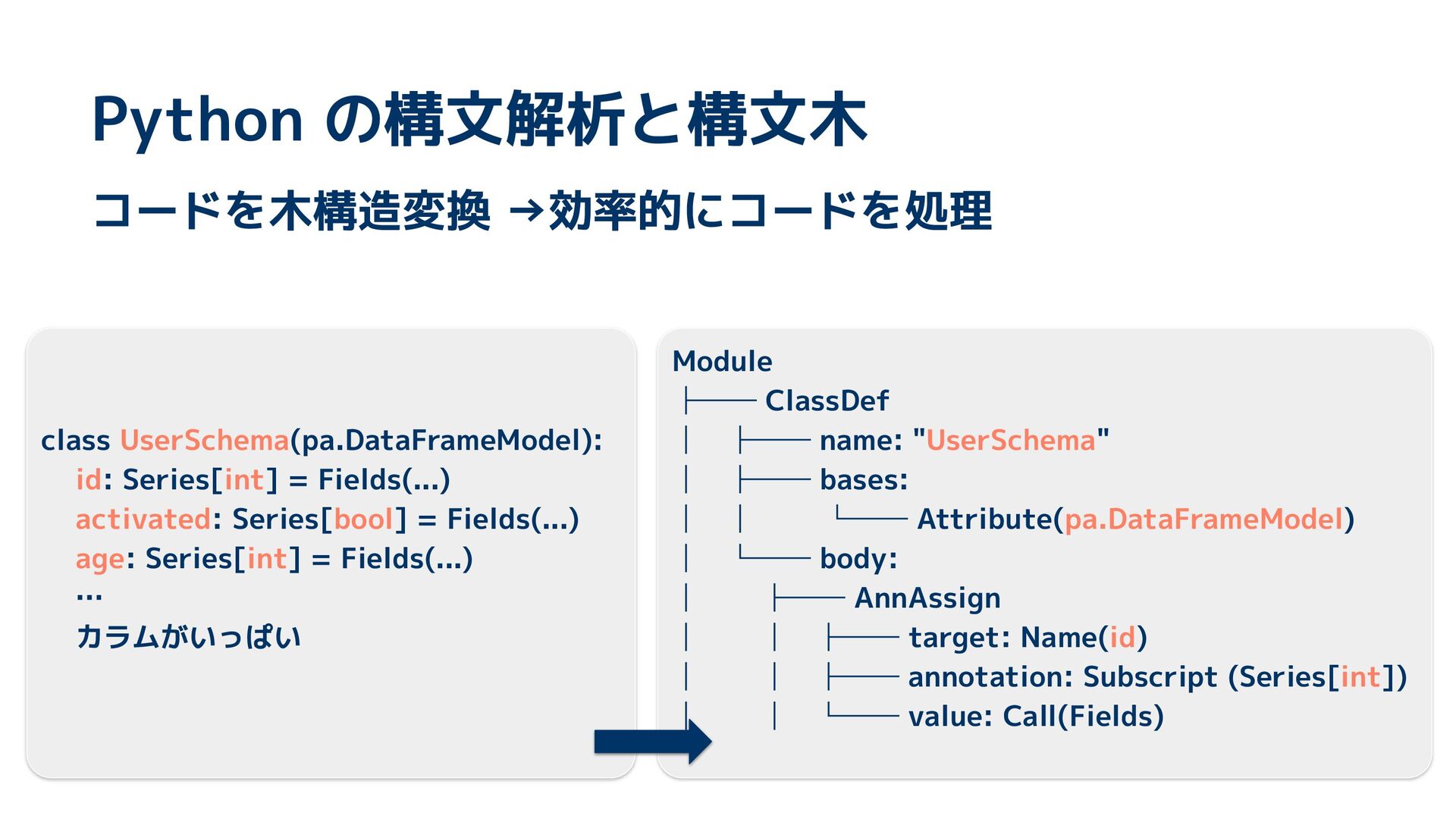{kind=link}
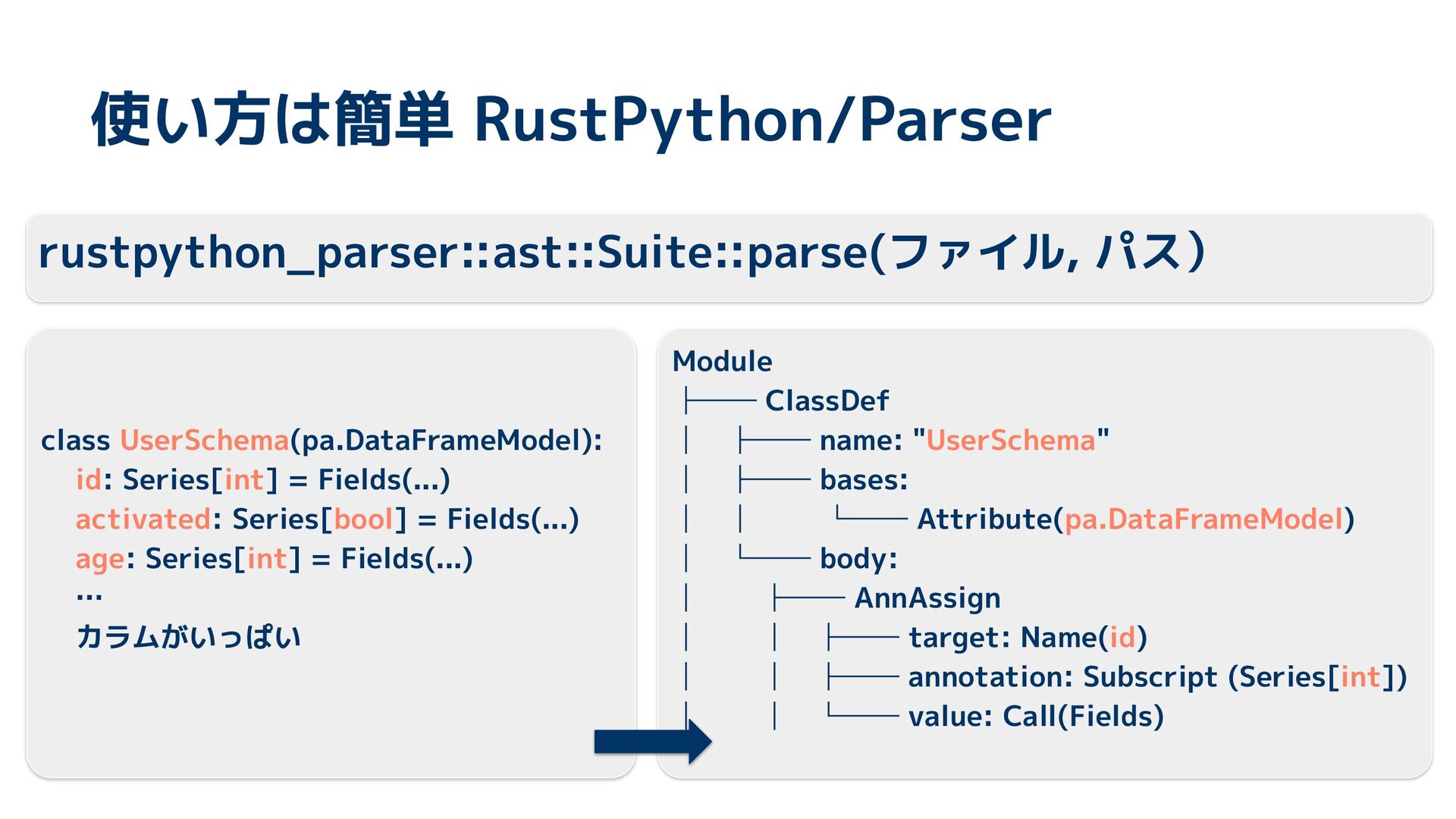{kind=link}
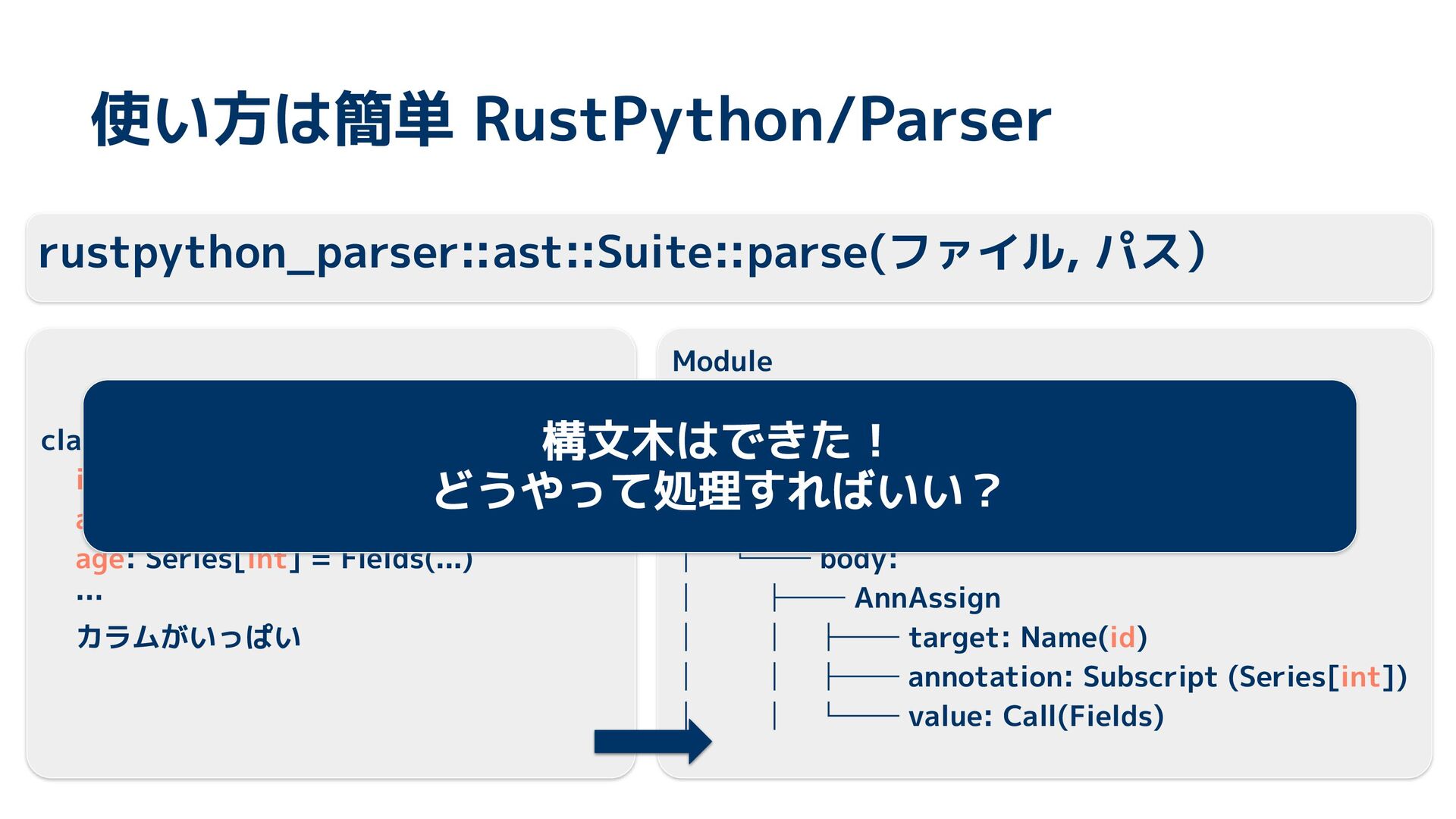{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
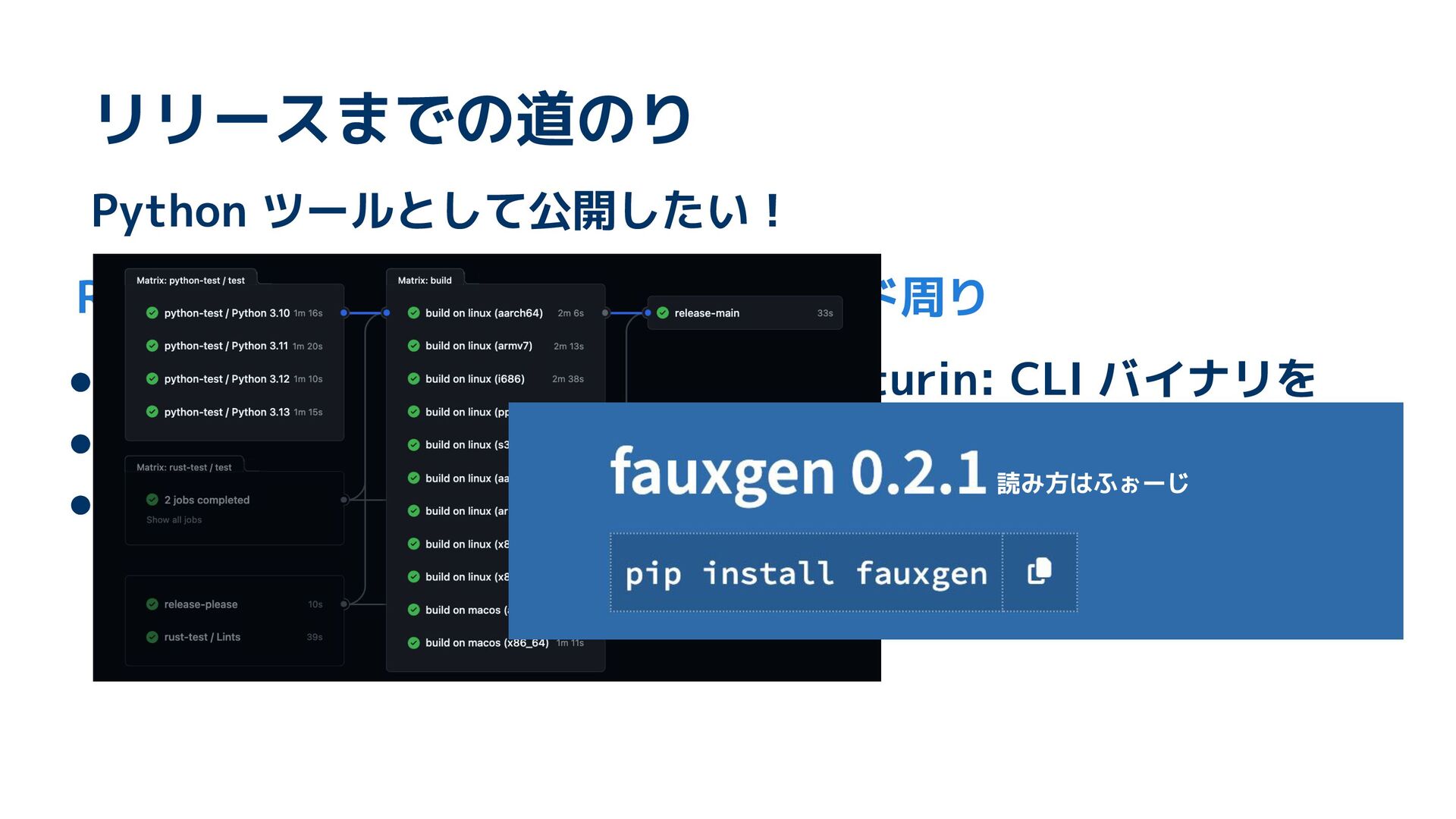{kind=link}
{kind=link}
{kind=link}