*inbuf, float *filter, int tap) { for (i = 0; i < tap; i++) { sum.left += inbuf[i].left * filter[i]; sum.right += inbuf[i].right * filter[i]; } // FIR フィルタの出力データ1個を計算する関数 (fp32x2) SAMPLE calc_inner_product(const SAMPLE *inbuf, SAMPLE *filter, int tap) { for (i = 0; i < tap; i++) { sum.left += inbuf[i].left * filter[i].left; sum.right += inbuf[i].right * filter[i].right; } 最適化 さらに for ループ 1 回当たりの計算量を 2 倍に増やし たプログラムも作成してみました。(fp32x4_…)
{kind=link}
{kind=link}
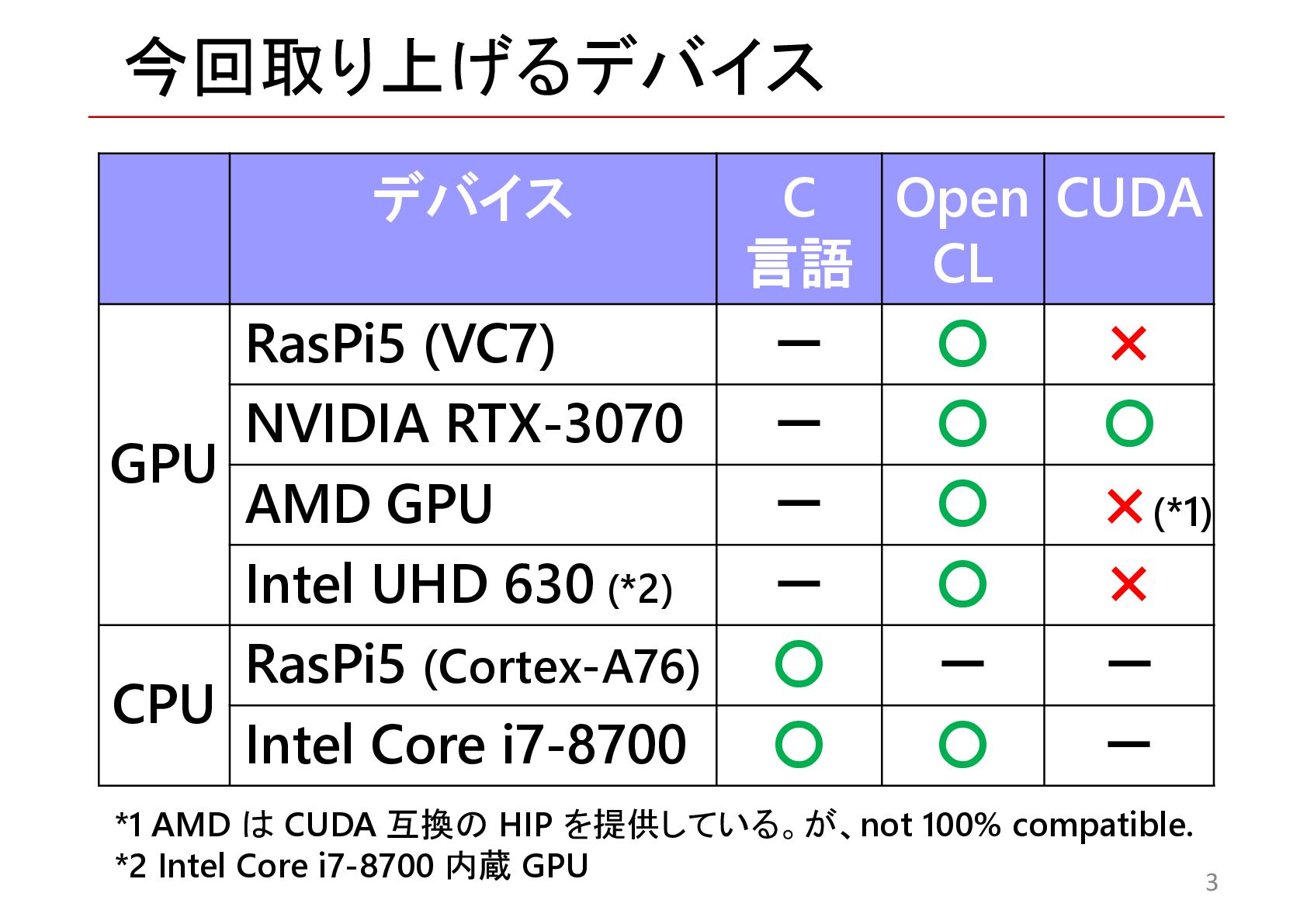{kind=link}
{kind=link}
{kind=link}
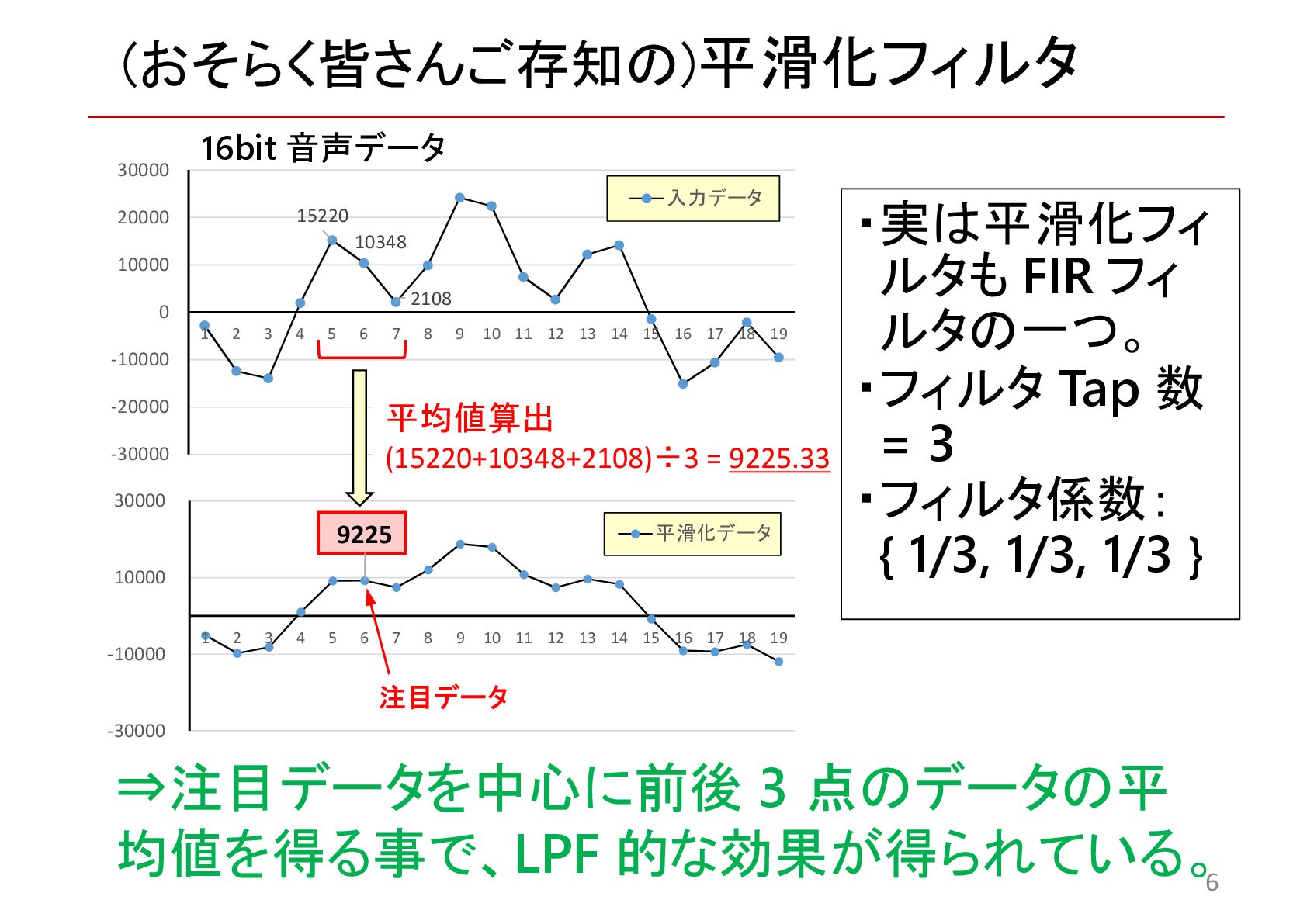{kind=link}
{kind=link}
{kind=link}
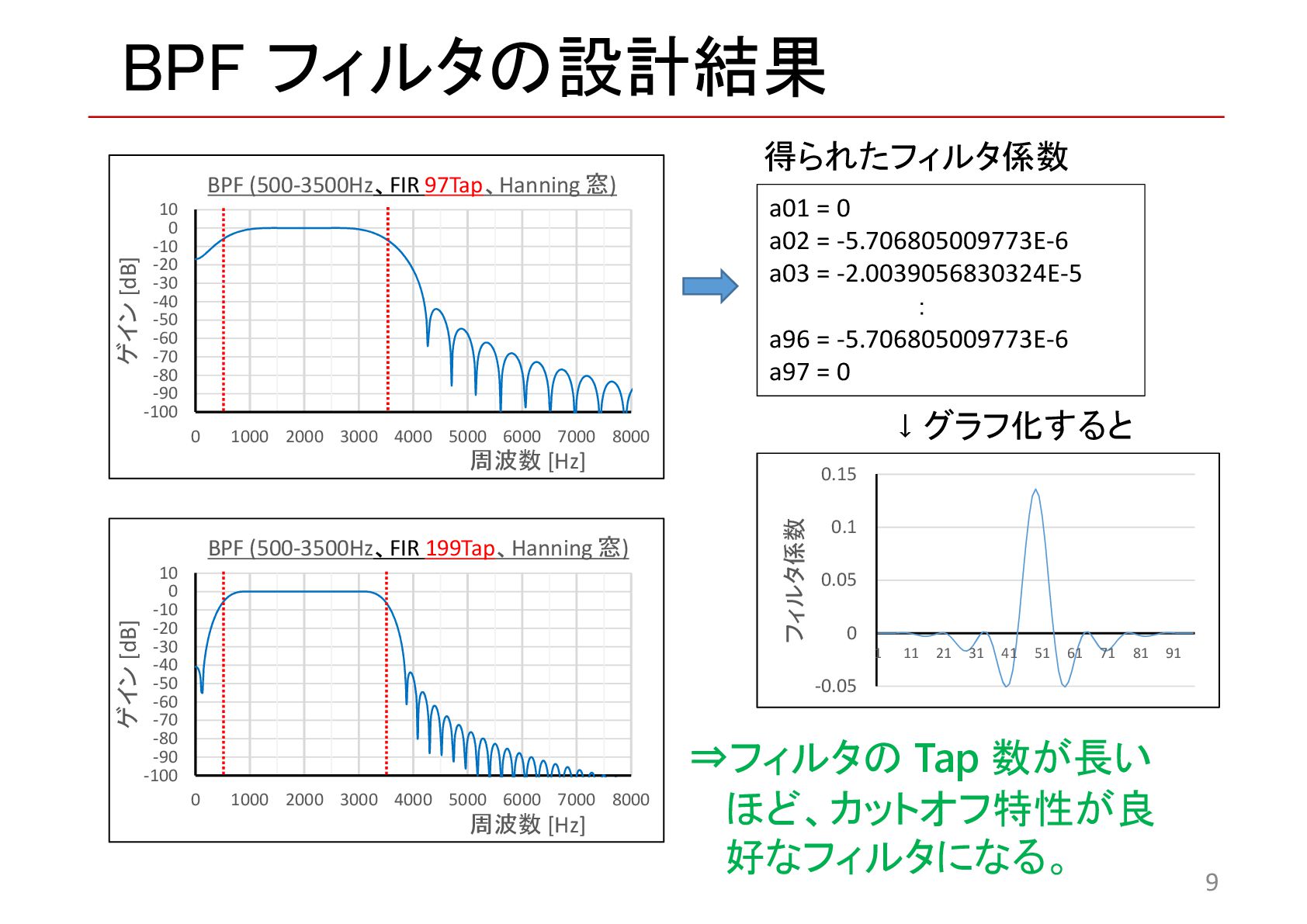{kind=link}
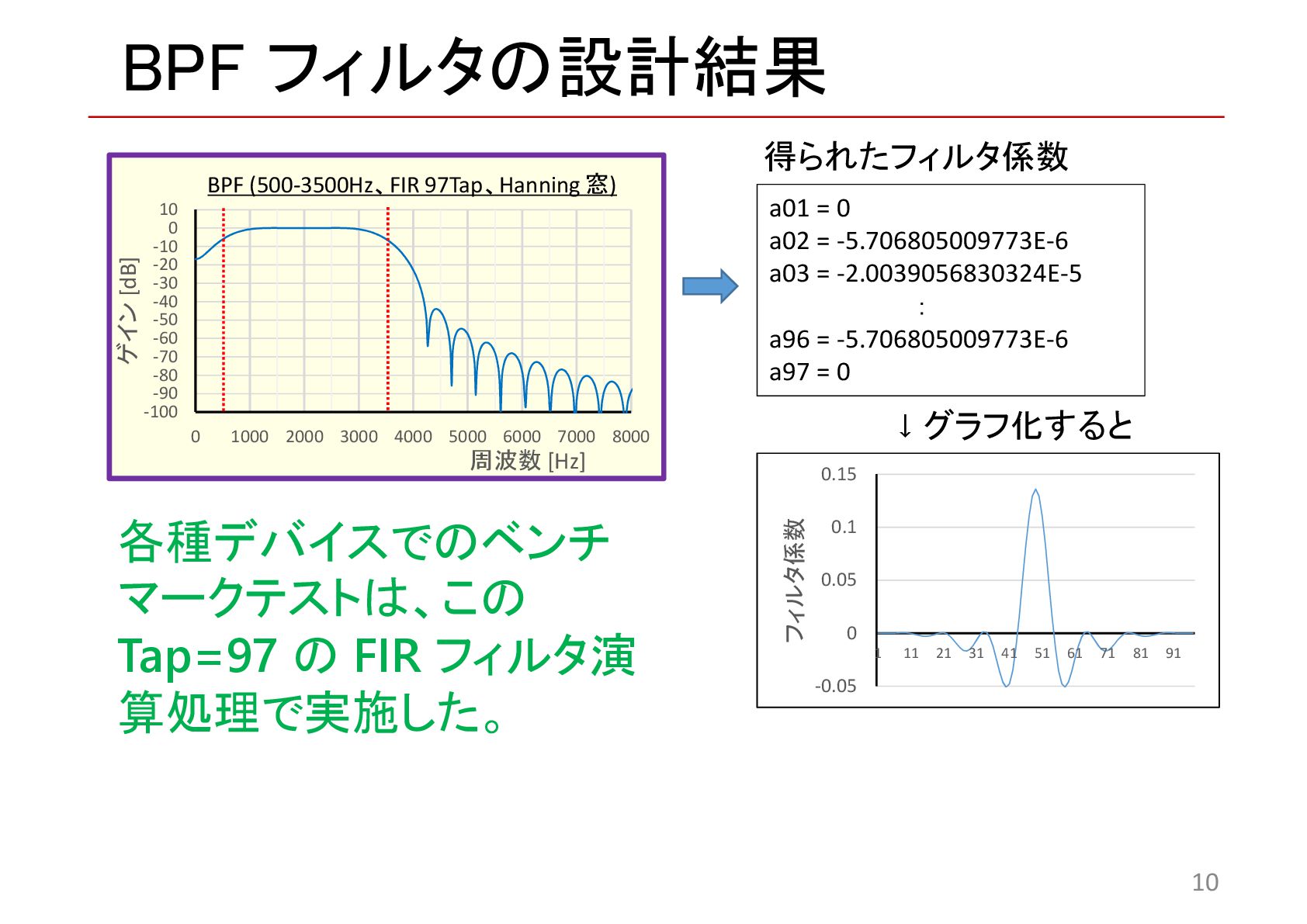{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
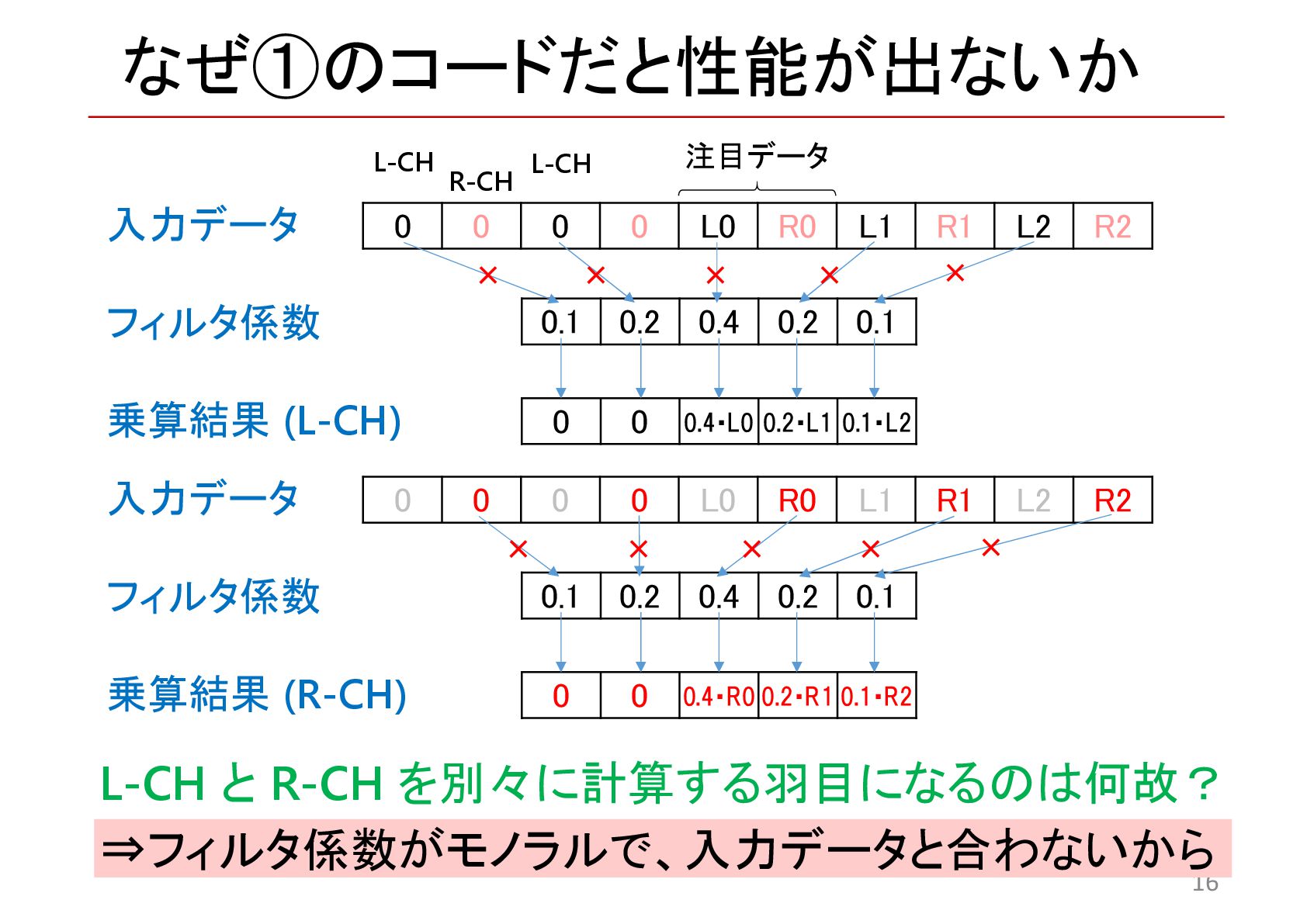{kind=link}
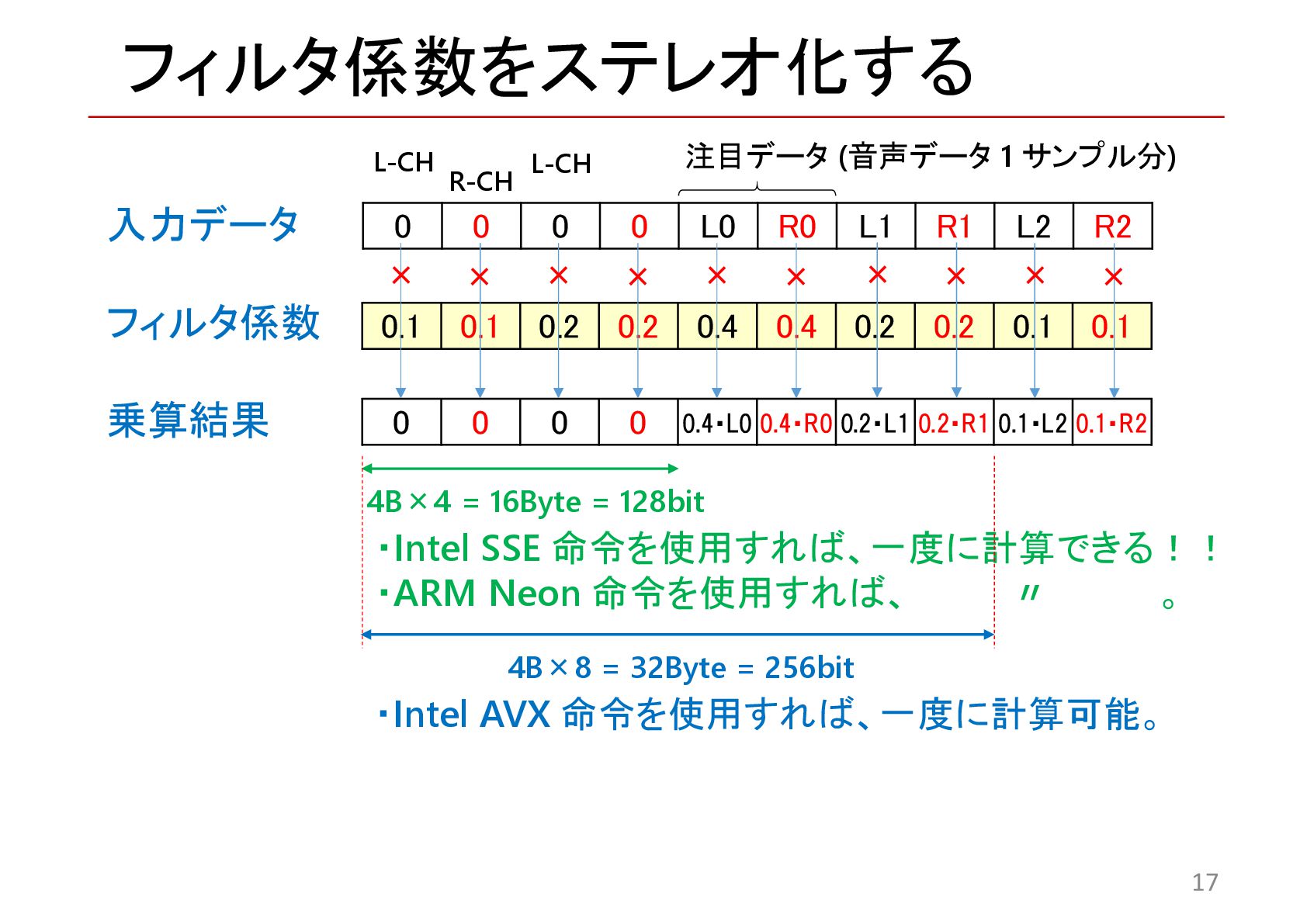{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
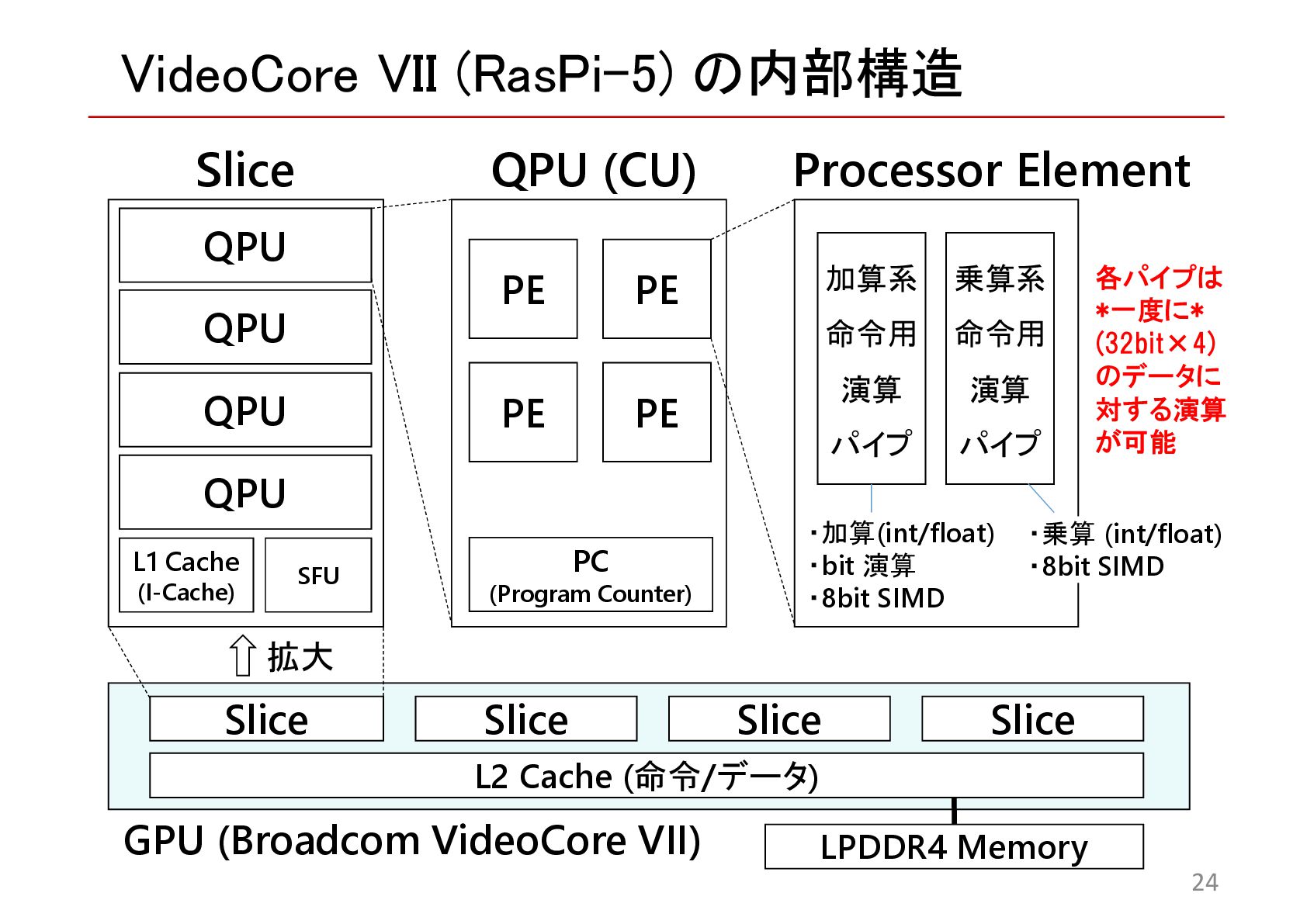{kind=link}
{kind=link}
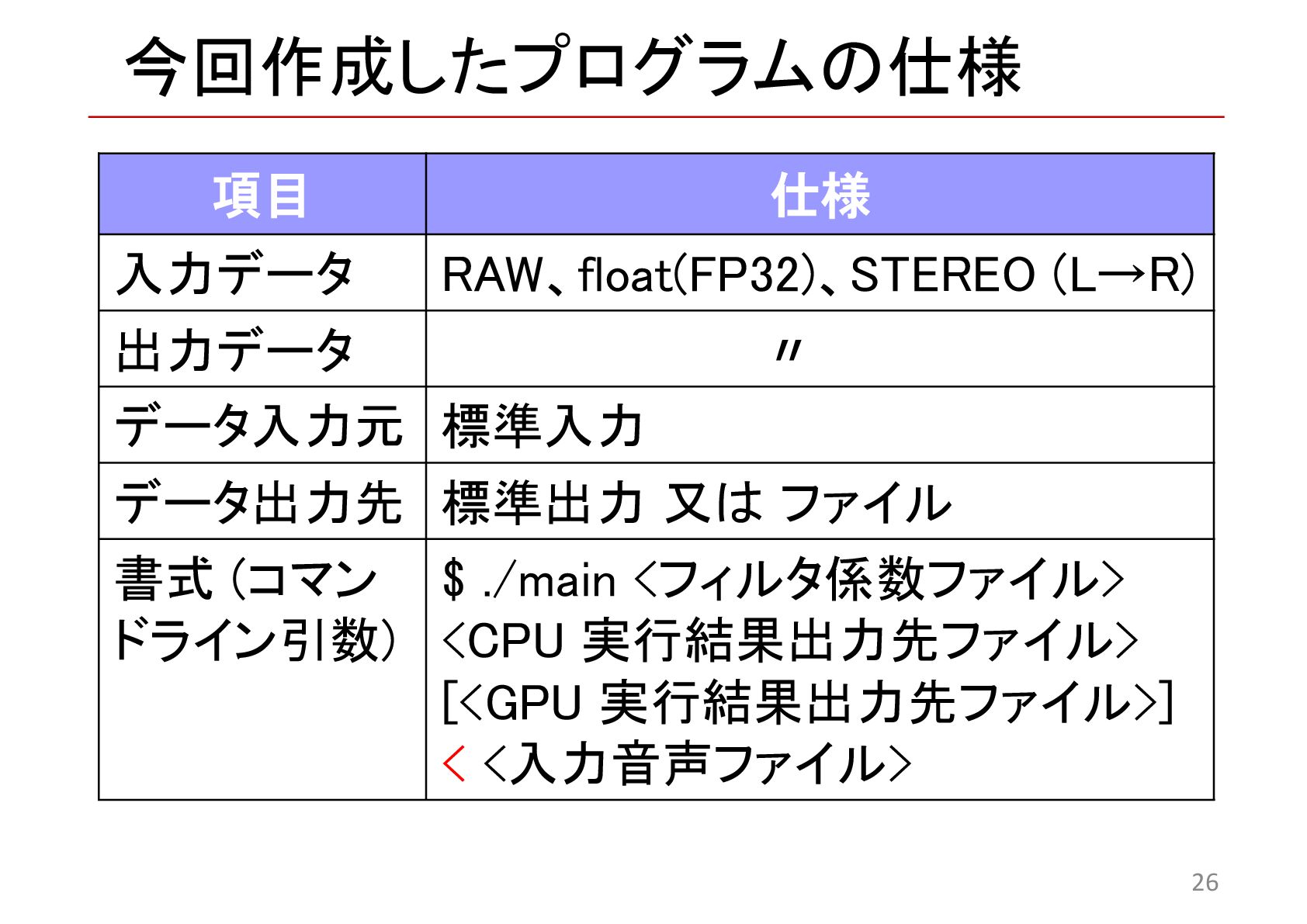{kind=link}
{kind=link}
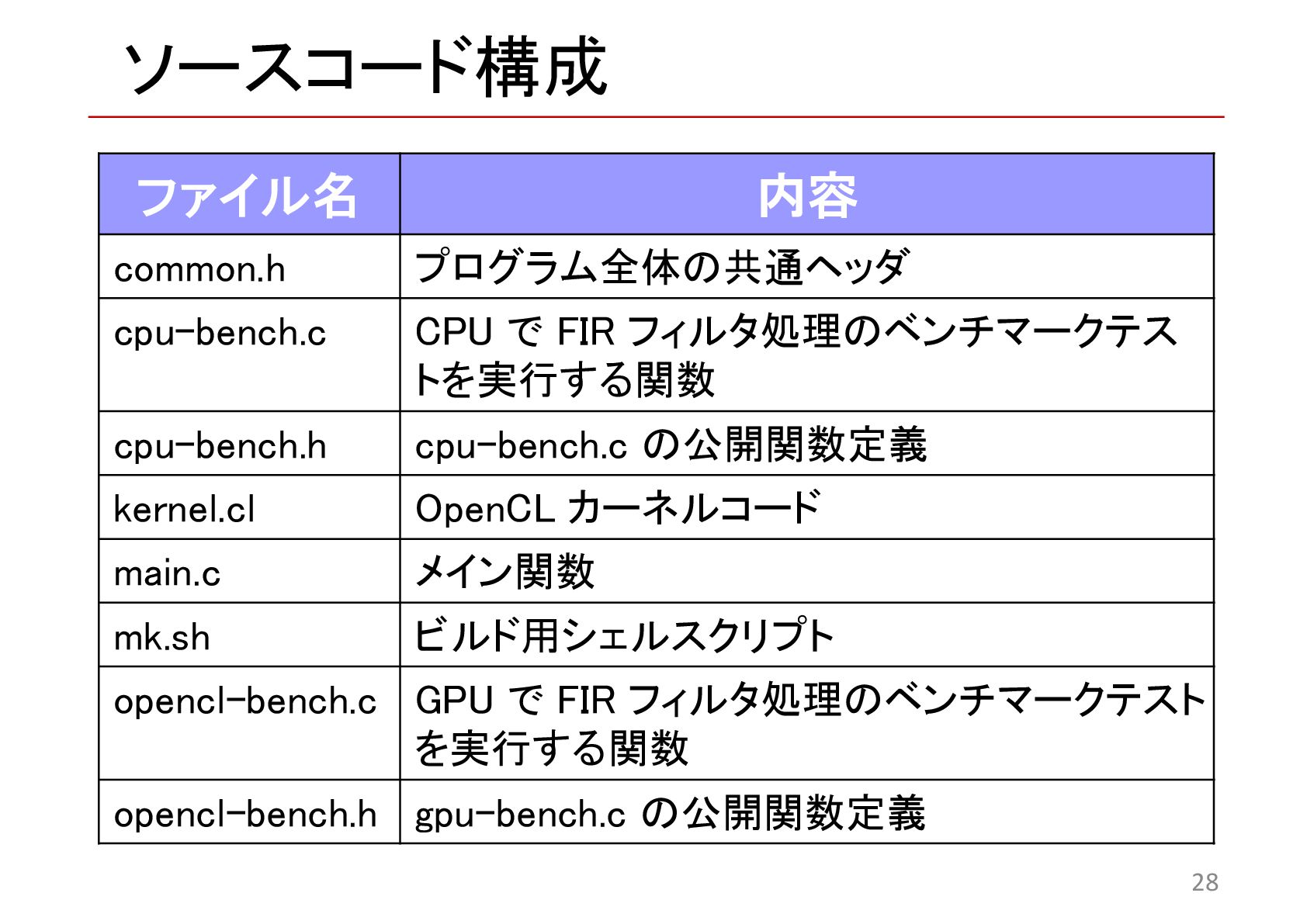{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
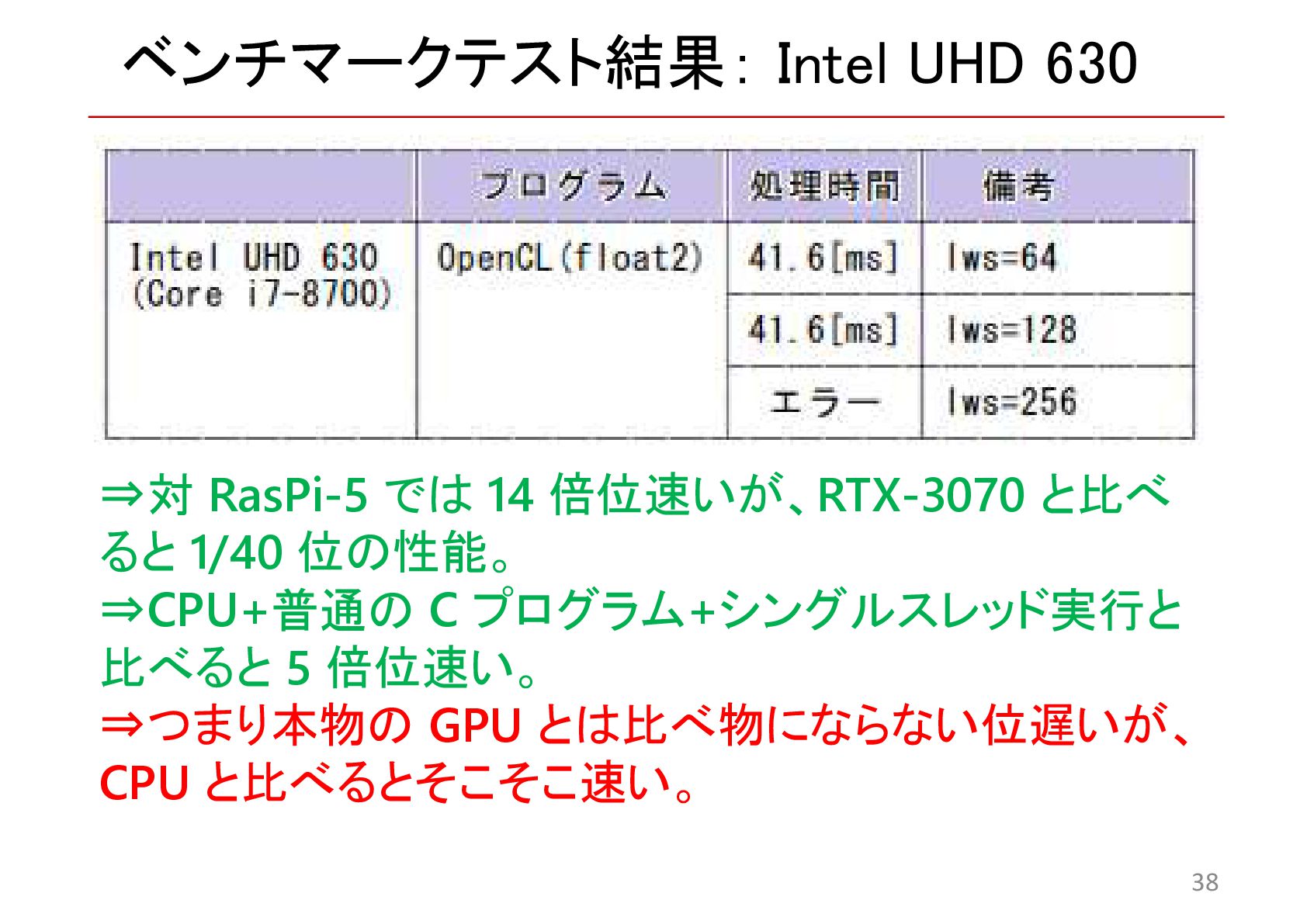{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
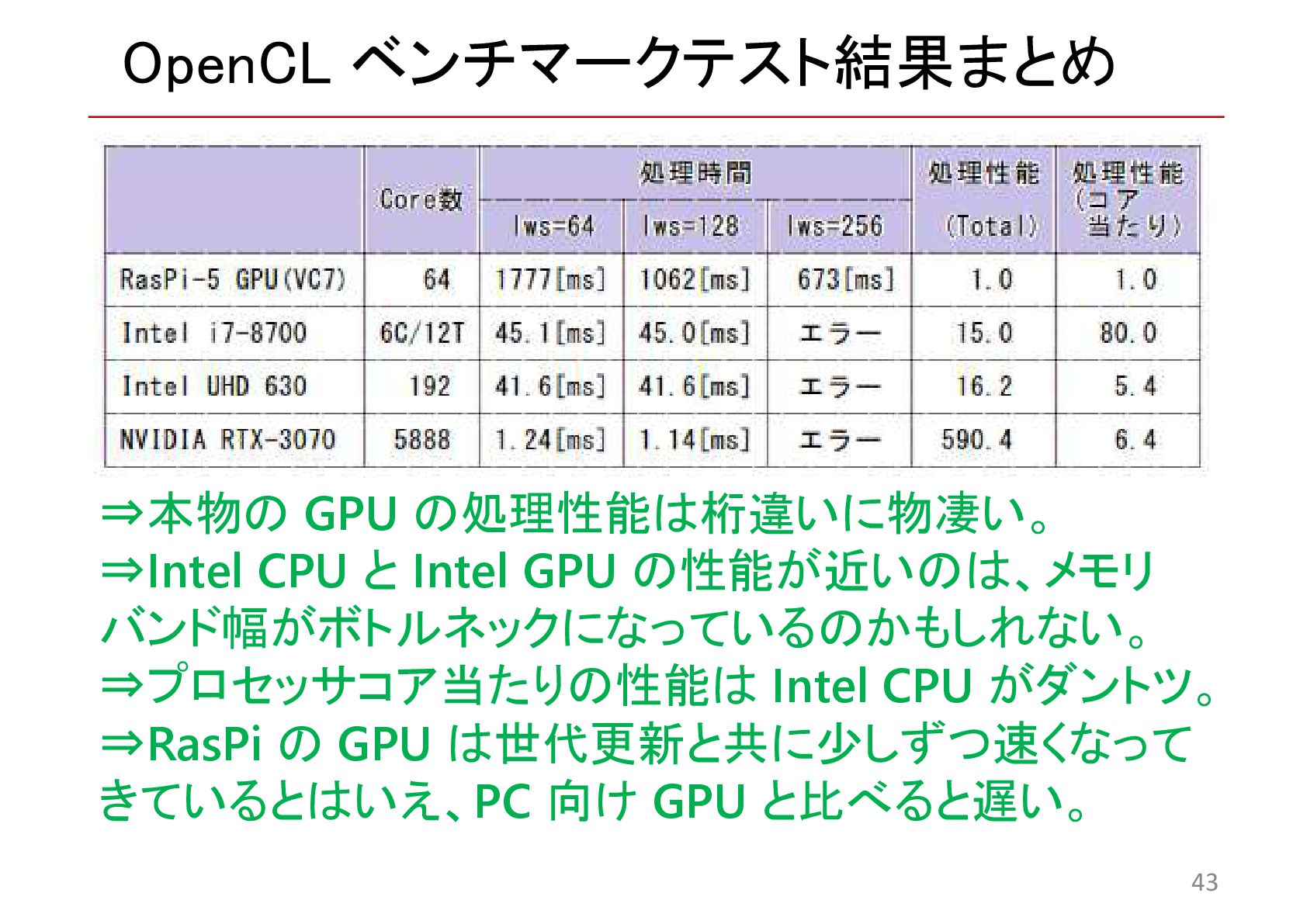{kind=link}
{kind=link}