빨라지겠지” “indirect call 은 매우 느리니 virtual 은 최대한 쓰지 말아야지” “cache line 에 맞게 구조체를 64 bytes align 에 맞춰야지” “이건 template 을 사용해서 컴파일타임에 계산하도록 하면 더 빨라지겠군” 좀 더 고수라면…
최적화에 착수합니다. (20FPS) 철수는 왠지 A 가 느린것 같아서 A 를 열심히 최적화합니다. 조금 개선을 하니 2배 정도로 빠르게 할 수 있었고, 진행을 하다보니 더 좋은 방법이 생각납니다. 2주일동안 최적화에 집중한 결과 200배 속도향상이라는 놀라운 결과를 이끌어냈습니다. 영희는 프로파일러를 돌려서 게임중에 A 가 1% 의 실행시간을 소요하는 반면, B 가 50% 나 되는 실행시간을 소요한다는 점을 발견하고 B를 점검해봅니다. 약간의 수정을 거친 결과 B 를 50% 정도 빠르게 만들 수 있었습니다. 두 가지 경우에서 FPS 에 기여하는 성능차이는 어떨까요?
가져왔다.” “B 를 최적화해서 1.5 배의 성능향상을 가져왔다.” 전체를 보는 우리의 직관 “철수가 영희보다 전체성능을 약 2.5 배 향상” 최적화 성과 전체 성능향상 철수 전체의 1% 부분을 200 배 빠르게 0.01 x 200 = 2 영희 전체의 50% 부분을 1.5 배 빠르게 0.5 x 1.5 = 0.75 우리의 직관은 과연 맞을까? (전체를 보지 못한다)
성능향상 01 . 1 200 01 . 0 ) 01 . 0 1 ( 1 ≒ S P P ) 1 ( 1 20 . 1 5 . 1 5 . 0 ) 5 . 0 1 ( 1 철수는 왠지 A 가 느린것 같아서 A 를 열심히 최적화합니다. 조금 개선을 하니 2배 정도로 빠르게 할 수 있었고, 진행을 하다보니 더 좋은 방법이 생각납니다. 2주일동안 최적화에 집중한 결과 200배 속도향상이라는 놀라운 결과를 이끌어냈습니다. 영희는 프로파일러를 돌려서 게임중에 A 가 1% 의 실행시간을 소요하는 반면, B 가 50% 나 되는 실행시간을 소요한다는 점을 발견하고 B를 점검해봅니다. 약간의 수정을 거친 결과 B 를 50% 정도 빠르게 만들 수 있었습니다.
가져왔다.” “B 를 최적화해서 1.5 배의 성능향상을 가져왔다.” 전체를 보는 우리의 직관 “철수가 영희보다 전체성능을 약 2.5 배 향상” 실제 결과 철수: 전체성능 1% 향상 - FPS 20.0 → FPS 20.2 영희: 전체성능 20% 향상 - FPS 20.0 → FPS 24.0 “영희가 철수보다 전체 성능을 20배 더 향상” 최적화 성과 전체 성능향상 철수 전체의 1% 부분을 200 배 빠르게 0.01 x 200 = 2 영희 전체의 50% 부분을 1.5 배 빠르게 0.5 x 1.5 = 0.75 (전체를 보지 못한다)
멋모르고 최적화를 하지 말라는 얘기 같지만.. 사실 작고 사소한 부분에 치우치지 말것을 강조 “ We should forget about small efficiencies, say about 97% of the time: Premature optimization is the root of all evil. ”
예측과 빗나간다 bottleneck 은 생각하지 못한 곳에 있곤 한다. 전체에 대한 부분의 영향은 직관적으로 알기 힘들다. 철수와 영희의 최적화 직관은 산술연산에 익숙하며, 지수나 제수(divisor)에는 약하다. 이처럼 성능개선에서의 직관은 종종 우리를 배신한다.
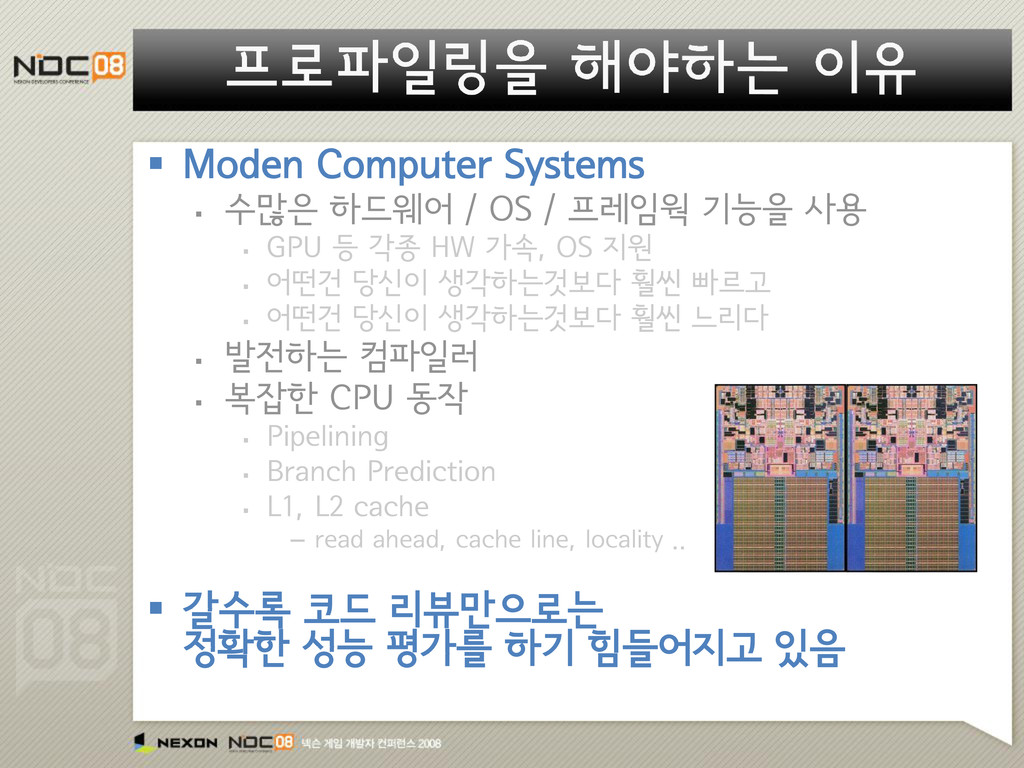
프레임웍 기능을 사용 GPU 등 각종 HW 가속, OS 지원 어떤건 당신이 생각하는것보다 훨씬 빠르고 어떤건 당신이 생각하는것보다 훨씬 느리다 발전하는 컴파일러 복잡한 CPU 동작 Pipelining Branch Prediction L1, L2 cache – read ahead, cache line, locality .. 갈수록 코드 리뷰만으로는 정확한 성능 평가를 하기 힘들어지고 있음
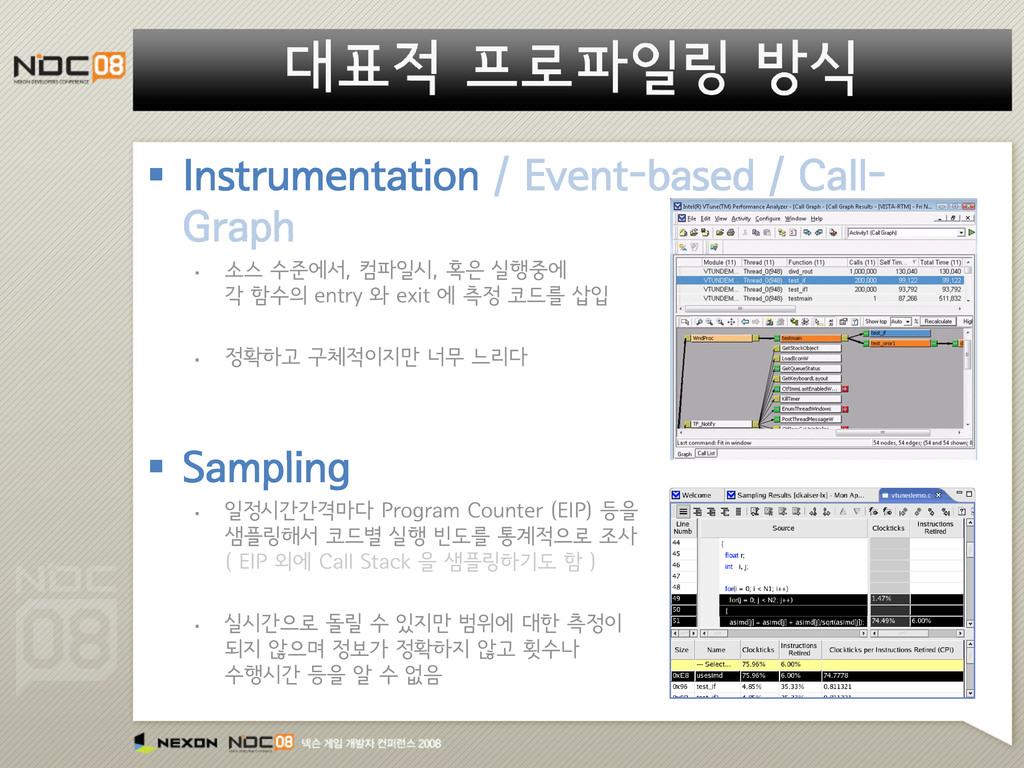
컴파일시, 혹은 실행중에 각 함수의 entry 와 exit 에 측정 코드를 삽입 정확하고 구체적이지만 너무 느리다 Sampling 일정시간간격마다 Program Counter (EIP) 등을 샘플링해서 코드별 실행 빈도를 통계적으로 조사 ( EIP 외에 Call Stack 을 샘플링하기도 함 ) 실시간으로 돌릴 수 있지만 범위에 대한 측정이 되지 않으며 정보가 정확하지 않고 횟수나 수행시간 등을 알 수 없음
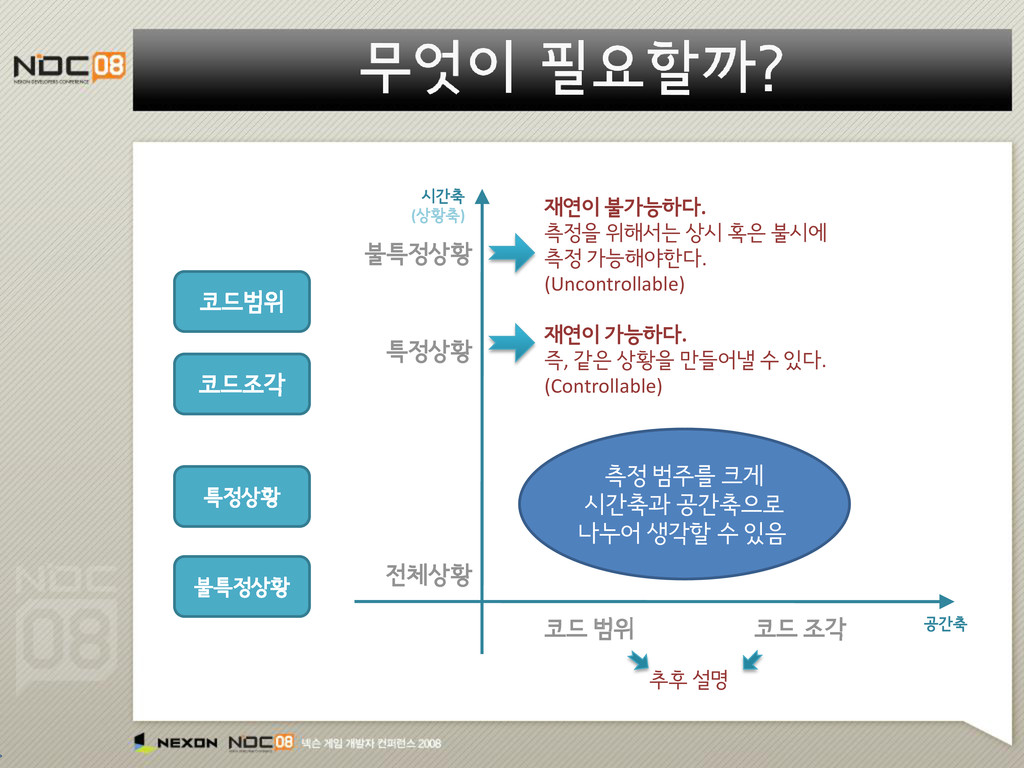
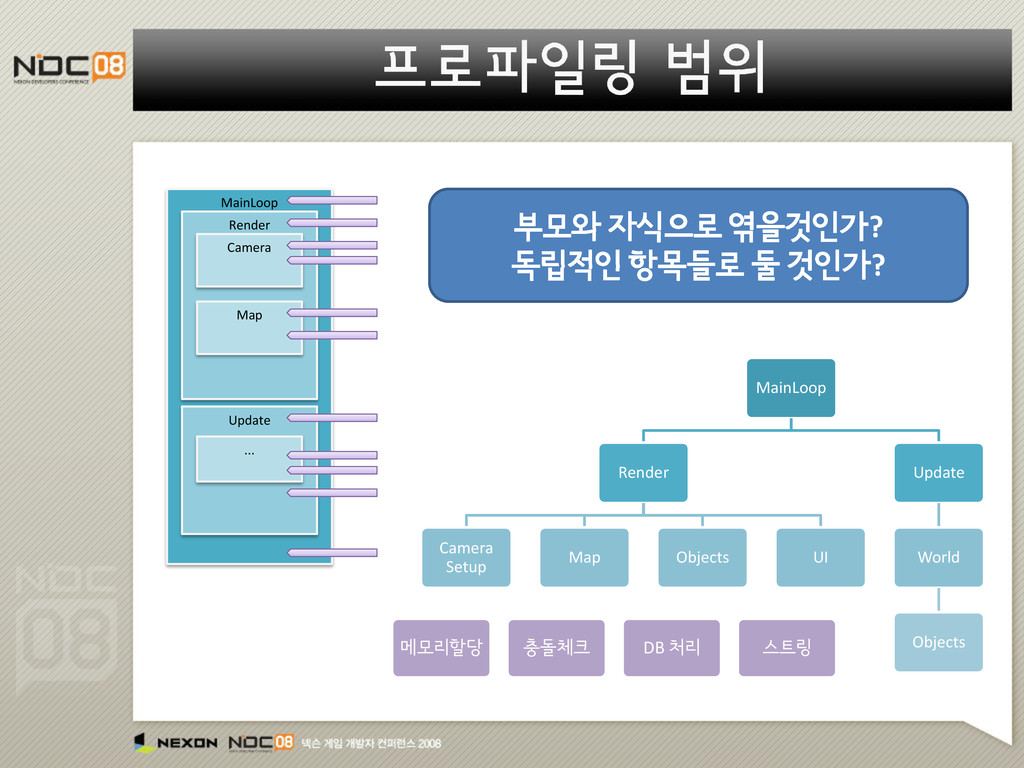
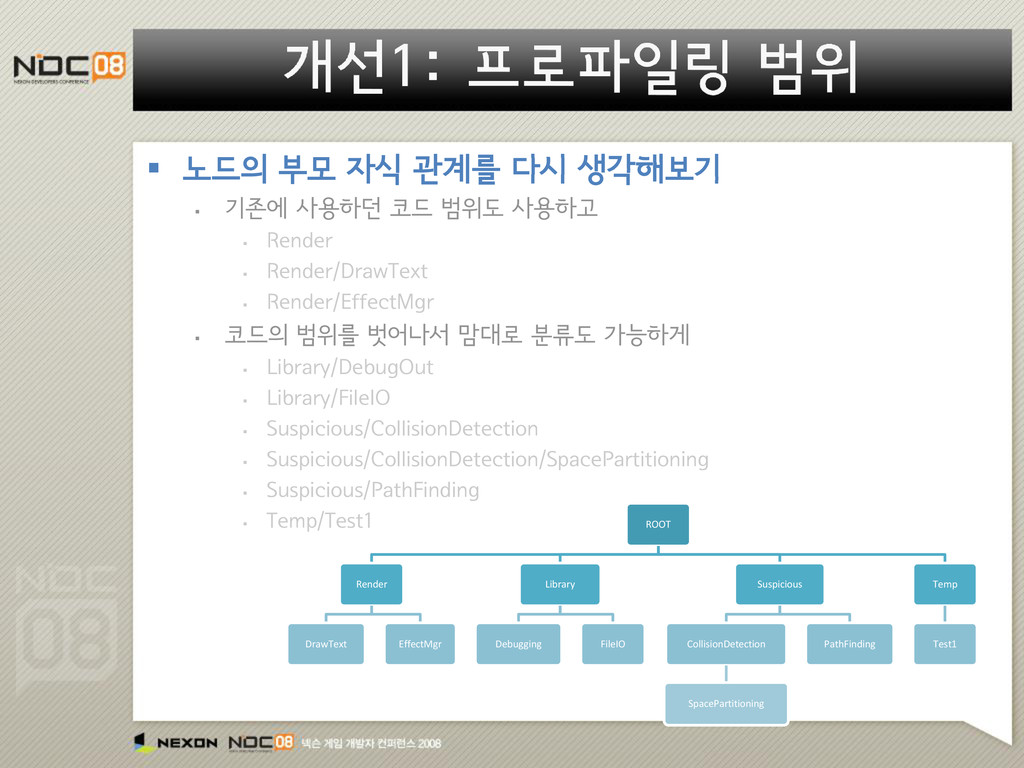
지역에만 가면 느려지는 현상을 잡고싶어” “특정몹만 만나면 느려지는 현상을 잡고 싶어” “가끔 알수없이 발생하는 랙을 잡고싶어” “어느 컴퓨터에서는 가끔 엄청 느려진다던데..” “게임의 전반적인 Frame Rate 를 높이고 싶어” 코드범위 코드조각 특정상황 불특정상황 원하는 것 측정 범주
불특정상황 시간축 (상황축) 공간축 측정 범주를 크게 시간축과 공간축으로 나누어 생각할 수 있음 재연이 가능하다. 즉, 같은 상황을 만들어낼 수 있다. (Controllable) 재연이 불가능하다. 측정을 위해서는 상시 혹은 불시에 측정 가능해야한다. (Uncontrollable) 추후 설명
지역에만 가면 느려지는 현상을 잡고싶어” “특정몹만 만나면 느려지는 현상을 잡고 싶어” “가끔 알수없이 발생하는 랙을 잡고싶어” “어느 컴퓨터에서는 가끔 엄청 느려진다던데..” “게임의 전반적인 Frame Rate 를 높이고 싶어” 코드범위 코드조각 특정상황 불특정상황 원하는 것 측정 범주 상용프로파일러 측정가능 해당 시나리오를 재연하도록 구현후 측정가능 측정불가 측정가능 O △ X O
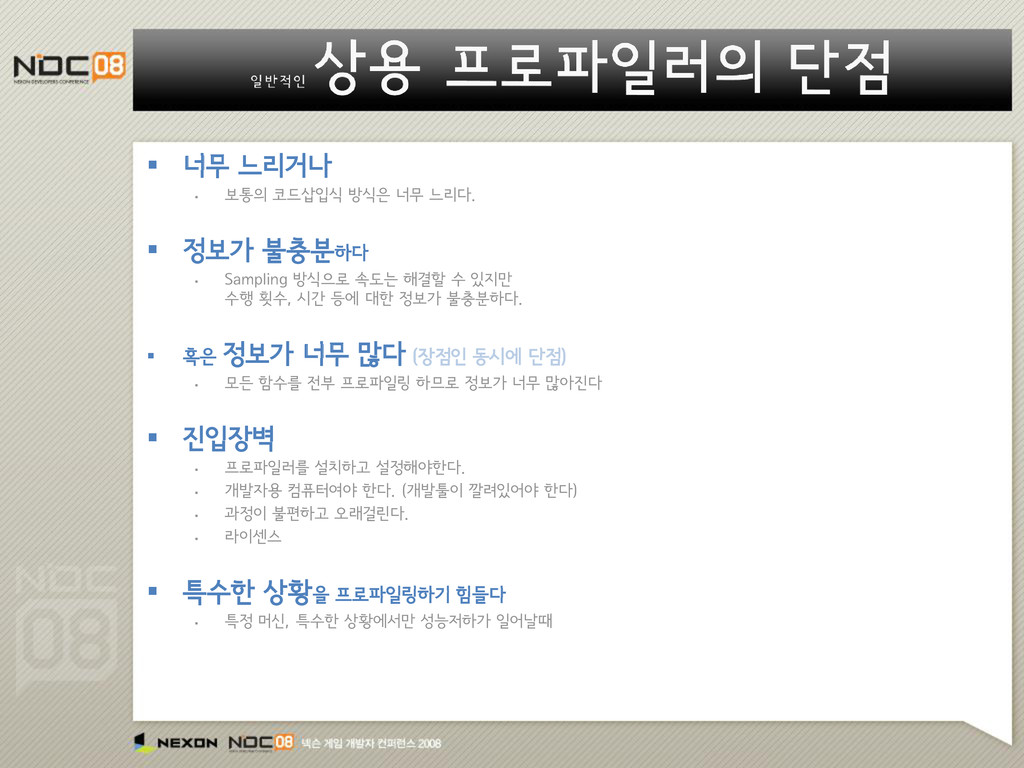
정보가 불충분하다 Sampling 방식으로 속도는 해결할 수 있지만 수행 횟수, 시간 등에 대한 정보가 불충분하다. 혹은 정보가 너무 많다 (장점인 동시에 단점) 모든 함수를 전부 프로파일링 하므로 정보가 너무 많아진다 진입장벽 프로파일러를 설치하고 설정해야한다. 개발자용 컴퓨터여야 한다. (개발툴이 깔려있어야 한다) 과정이 불편하고 오래걸린다. 라이센스 특수한 상황을 프로파일링하기 힘들다 특정 머신, 특수한 상황에서만 성능저하가 일어날때
있다. 실시간으로 확인가능하다. 각 노드마다 하위 부분의 비중을 확인할 수 있다. 평균, 최대, 최소 값을 확인할 수 있다. 단점 side-effect 가 크다. 매번 측정의 시작과 끝마다 탐색을 수행 (게다가 문자열비교) 특별 릴리즈에만 프로파일링 기능이 들어감 BEGIN 과 END 의 쌍을 꼭꼭 맞추어 주어야 한다. return 이나 break 등의 상황에서 귀찮고 실수할 가능성이 있다. 평균값으로는 특정 순간의 성능하락을 확인하기 힘들다.
해당 코드의 전체 소요시간 Count 프로그램 시작 이후 해당 코드의 수행 횟수 Overall Average Time, Percentage 프로그램 시작 이후 해당 코드의 소요시간 평균 및 상위노드 대비 % 0.5 sec Average Time, Percentage 최근 0.5 까지의 해당 코드의 소요시간 평균 및 상위노드 대비 % half-cut FPS 암달의 법칙에 의해, 해당 항목을 두배 빠르게 했을 때의 FPS 리포팅 타이밍 실시간 출력 command 로 끄고 켤 수 있다 실시간 텍스트 출력에 의한 side-effect 디버그 출력 command 로 리포트를 출력
sceneMgr->RenderMapAnimation(); } { DEFINE_PROFILE_ITEM(L"/Render/EffectMgr"); effectMgr->Render(); } ... } int GraphicLib::DrawText(Rect trg, uint format, LPCWSTR text, ...) { DEFINE_PROFILE_ITEM(L"/Render/DrawText"); ... int GraphicLib::TextOut(int x, int y, LPCWSTR text, ...) { DEFINE_PROFILE_ITEM(L"/Render/DrawText"); ... Total Run Count Overall Average 0.5 sec Average Item (half-cut FPS)
bound 될 필요 없다. 알아보기 어렵게 런타임중에 마구 바뀌지 않는다. 프로파일 항목이 런타임중에 추가되거나 삭제되지 않음 현재값은 최근 0.5 초 평균으로 표시 side-effect 를 더 줄였다. static 으로 탐색과 동적생성을 없앰. 정밀도 향상 1/1000 ms 단위까지 표시 정보 보강 전체와 현재의 횟수/비중을 표시 Total Run Count Overall Average 0.5 sec Average Item (half-cut FPS)
카운터를 얻어오는 x86 계열 instruction NOTE: 요즘 컴퓨터는 CPU 클럭이 유동적으로 변함 QueryPerformanceCounter 도 요즘은 rdtsc 값을 리턴 ( don’t believe MSDN too much ) “서버도 프로파일링 하자!” - 멀티쓰레드 지원 Critical Section? InterlockedIncrement? thread-local 하게 데이터를 쌓다가, 일정간격으로 전체 쓰레드 데이터를 집계 (Aggregation) __declspec(naked) unsigned __int64 __cdecl rdtsc(void) { __asm { rdtsc ret } } 더 가볍게 더 가볍게
DX 상에 찍지 않고 윈도우로도 띄울 수 있게 비-실시간 리포팅 개선 Inclusive / Exclusive Time 등 보다 많은 정보 적정시간(1초)마다 저장한 결과의 추이 및 분포 분석 점유율이나 영향력 기준으로 정렬해서 보여주기 종료시마다 서버에 남겨서 DB 에 쌓도록 모니터링 기능 Frame Rate 에 가장 영향을 미치는 항목 DB 를 기반으로, 갑자기 추이가 변한 항목
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}