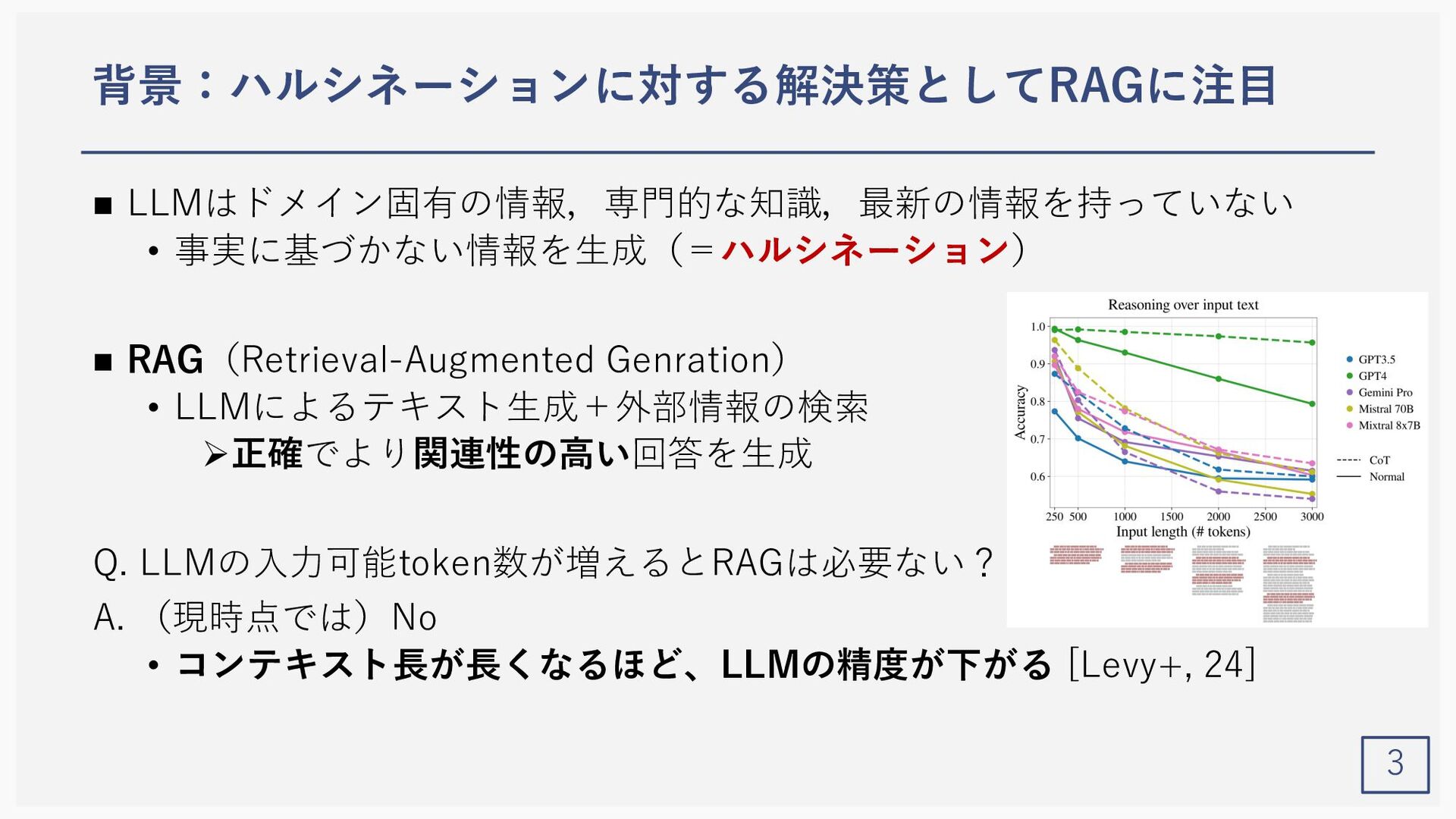
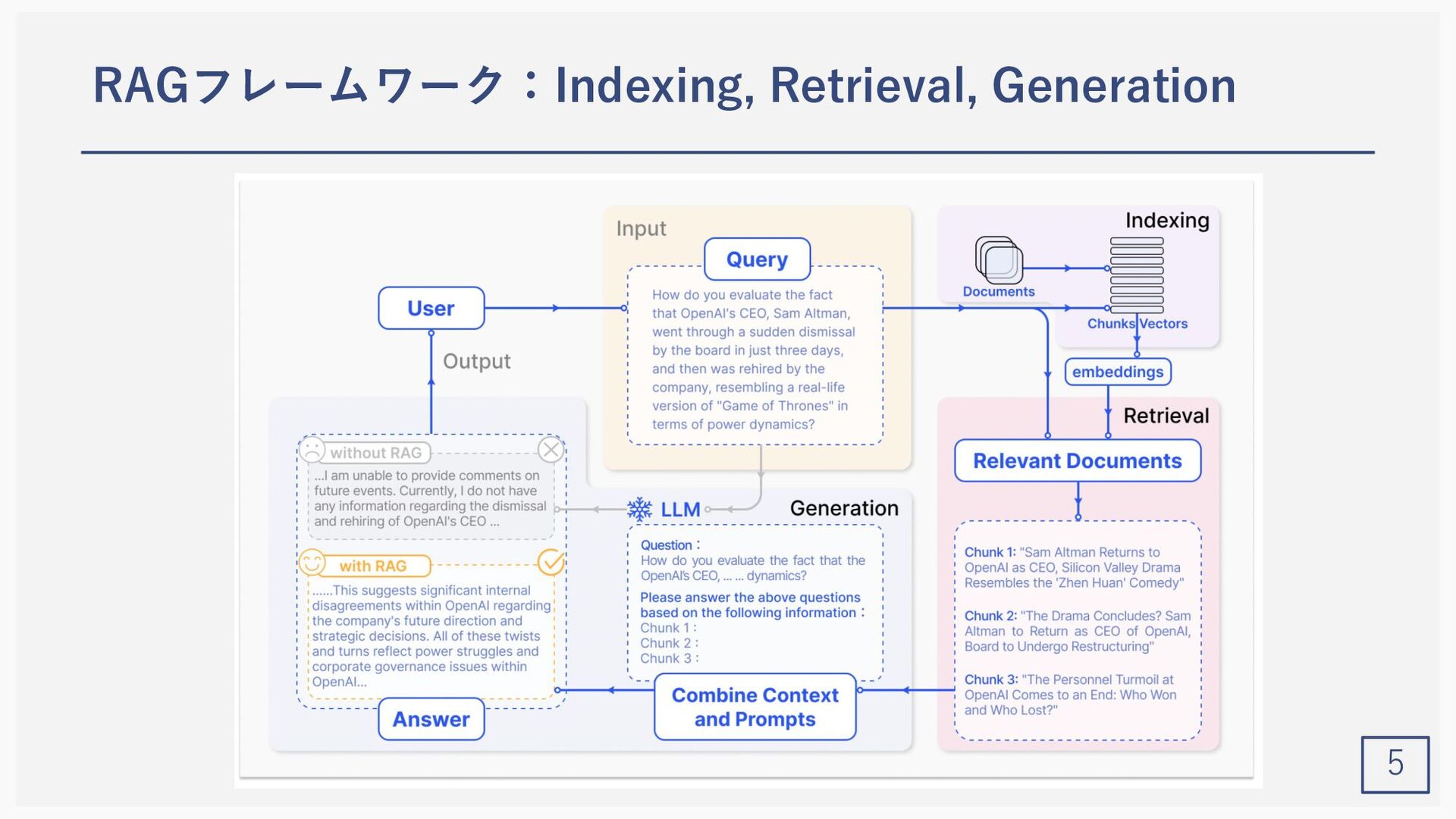
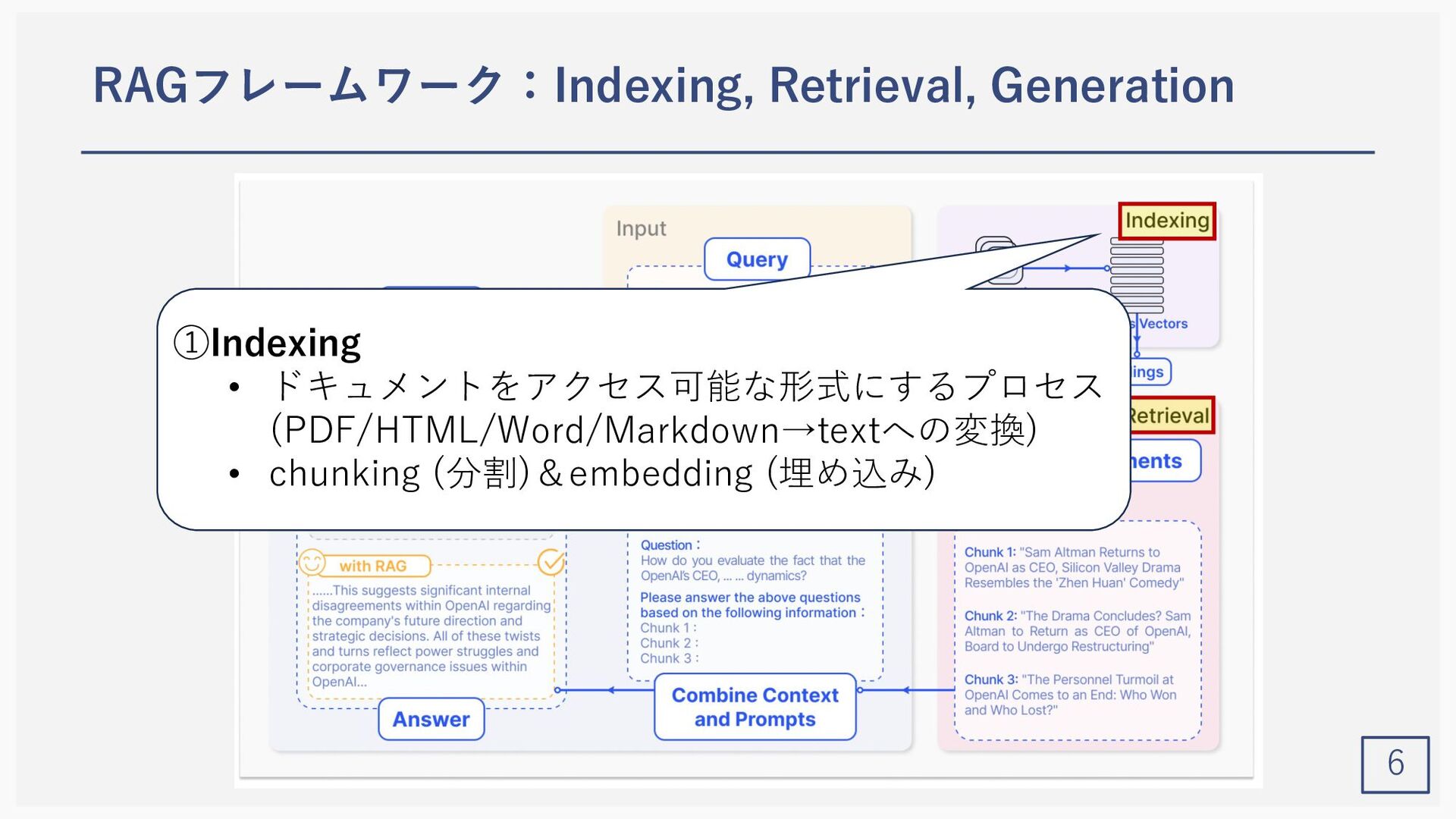
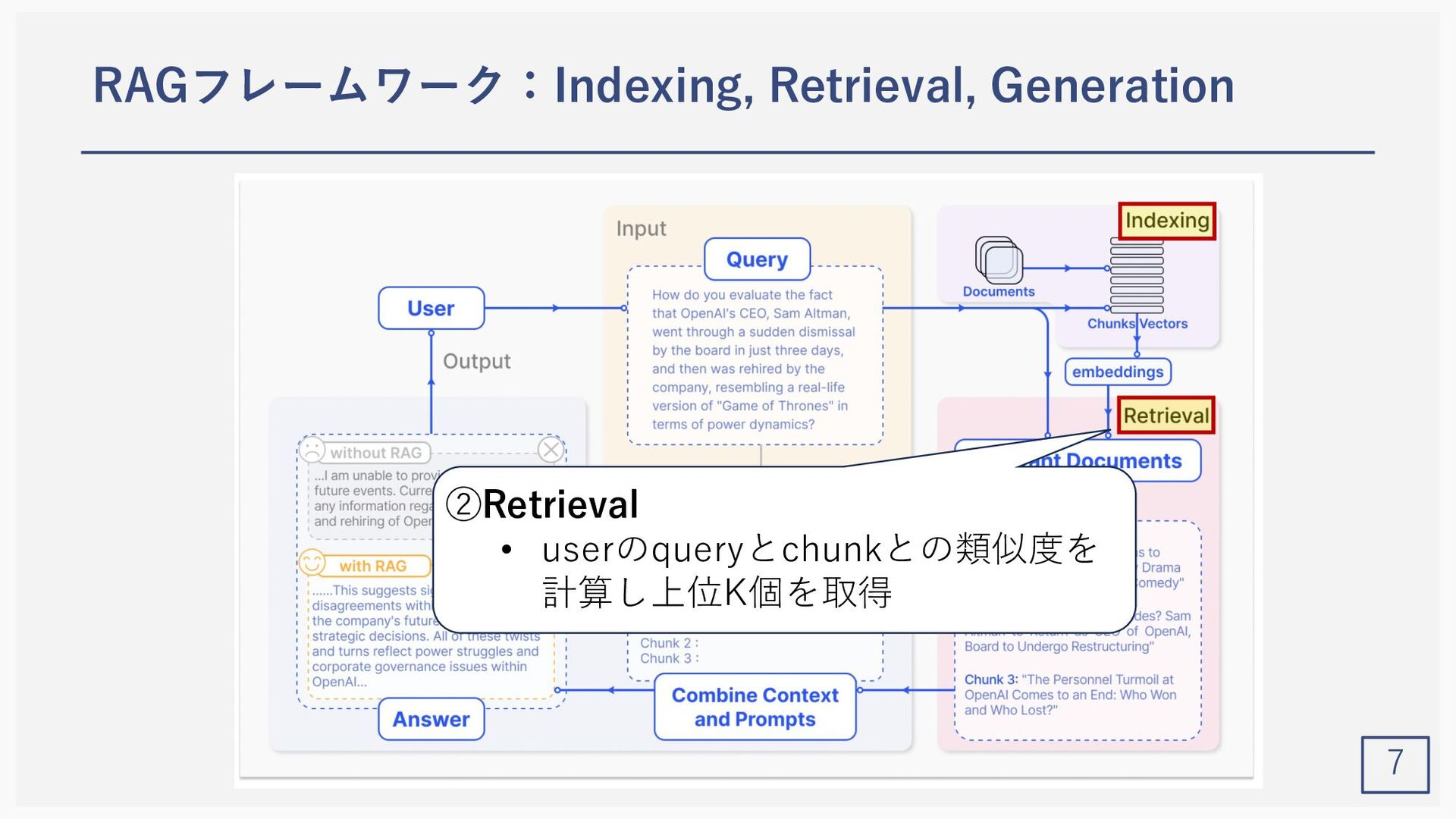
Yunfan Gao1, Yun Xiong2, Xinyu Gao2, Kangxiang Jia2, Jinliu Pan2, Yuxi Bic3, Yi Dai1, Jiawei Sun1, Meng Wang3, and Haofen Wang1,3 (1Shanghai Research Institute for Intelligent Autonomous Systems, Tongji University, 2Shanghai Key Laboratory of Data Science, School of Computer Science, Fudan University, 3College of Design and Innovation, Tongji University) Gao, Yunfan, et al. "Retrieval-Augmented Generation for Large Language Models: A Survey." arXiv preprint arXiv:2312.10997 (2023).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
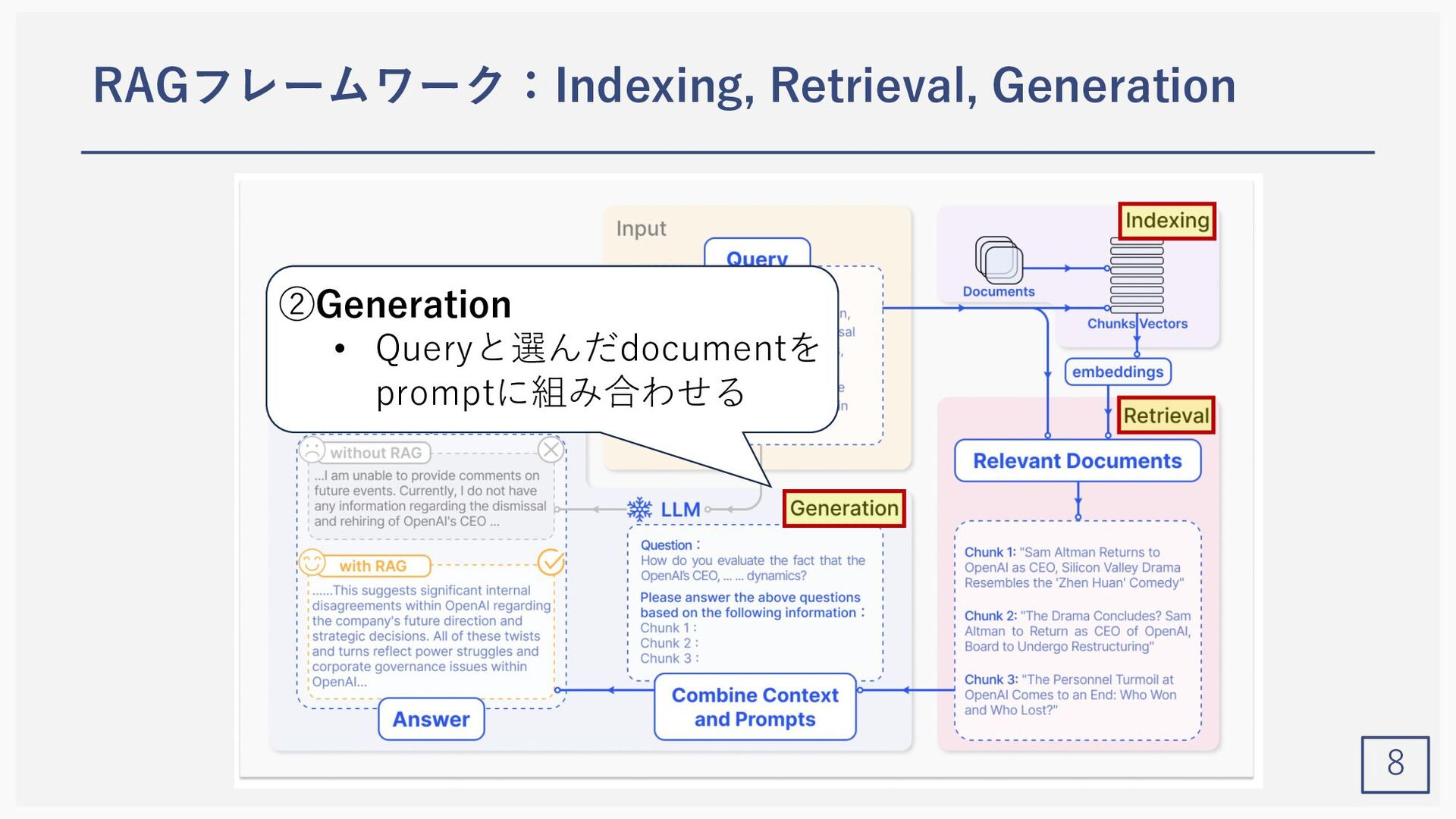{kind=link}
{kind=link}
{kind=link}
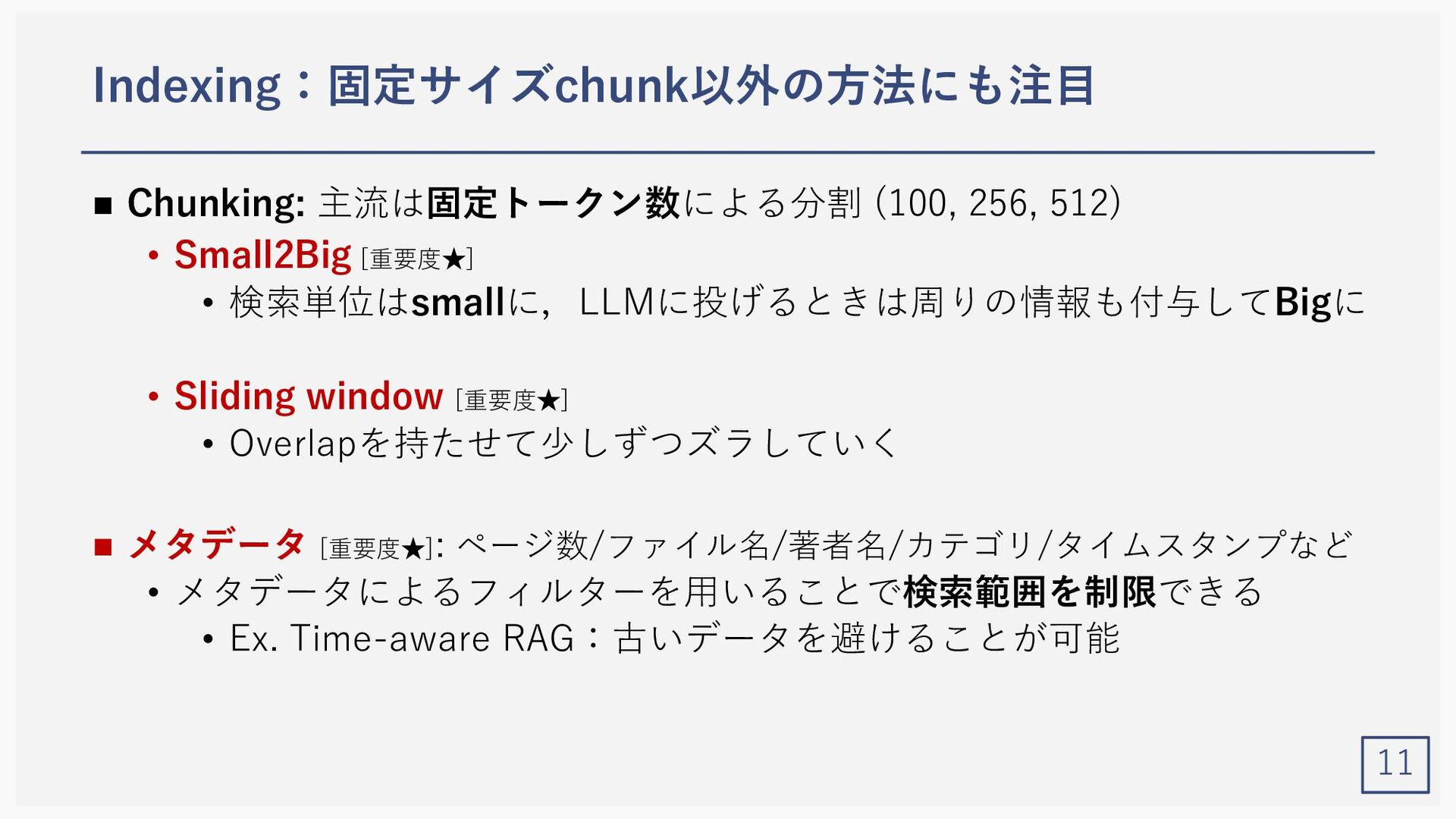{kind=link}
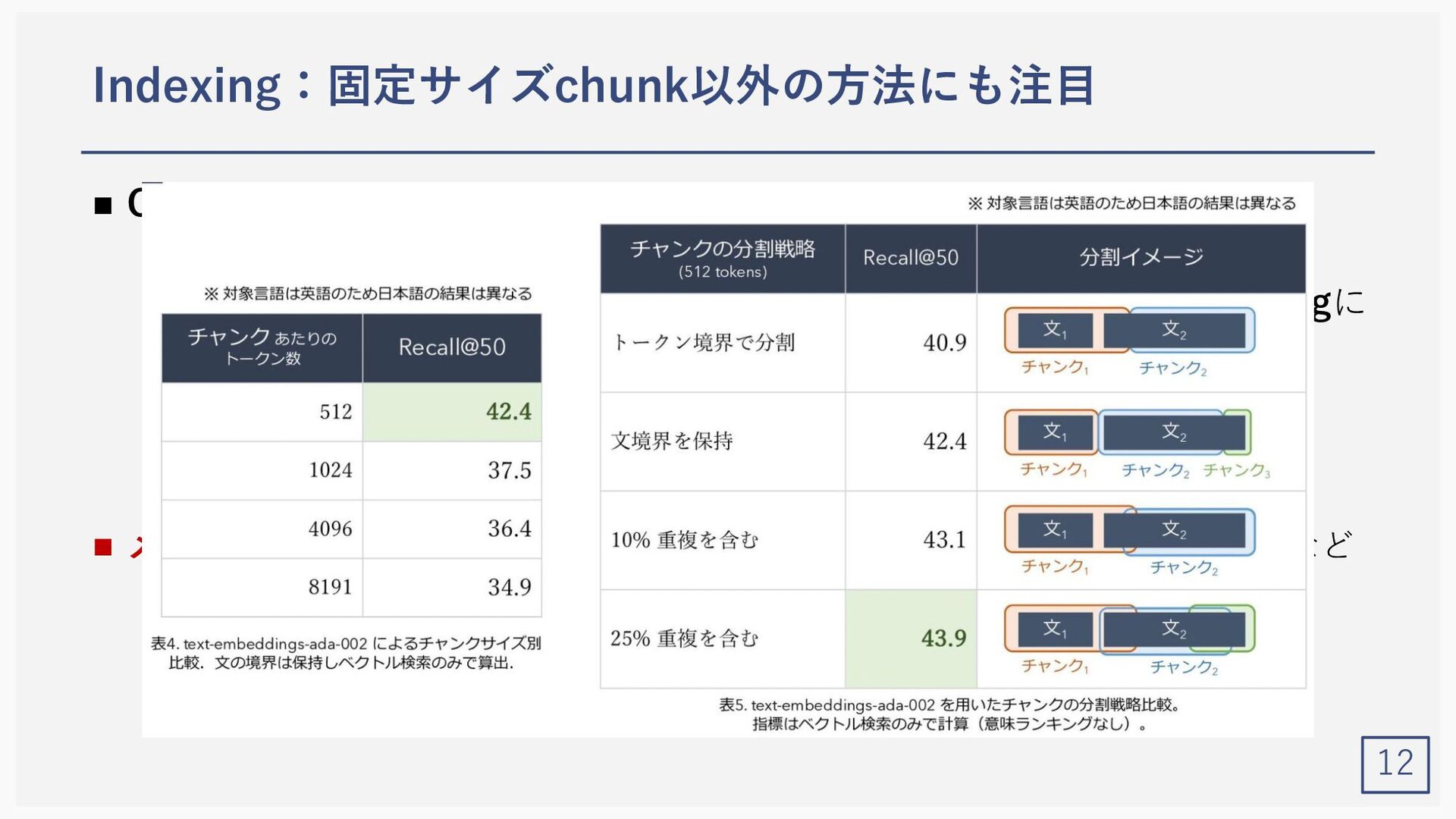{kind=link}
![クエリの最適化①: クエリ拡張,クエリ変換 13 n Query拡張 • RAG-Fusion [重要度★★★]: 類似queryを追加しそれらを並列に処理 n](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_12.jpg){kind=link}
![クエリの最適化①: クエリ拡張,クエリ変換 14 n Query拡張 • RAG-Fusion [重要度★★★]: 類似queryを追加しそれらを並列に処理 n](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_13.jpg){kind=link}
![クエリの最適化①: クエリ拡張,クエリ変換 15 n Query拡張 • RAG-Fusion [重要度★★★]: 類似queryを追加しそれらを並列に処理 n](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_14.jpg){kind=link}
![クエリの最適化①: クエリ拡張,クエリ変換 16 n Query拡張 • RAG-Fusion [重要度★★★]: 類似queryを追加しそれらを並列に処理 n](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_15.jpg){kind=link}
![クエリの最適化①: クエリ拡張,クエリ変換 17 n Query拡張 • RAG-Fusion [重要度★★★]: 類似queryを追加しそれらを並列に処理 n](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_16.jpg){kind=link}
![Queryの最適化②: ルーティング 18 n ルーティング (経路設定) [重要度★★] • 複数のデータストアにまたがって検索したい場合に有⽤ •](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_17.jpg){kind=link}
![Embedding: Hybridサーチにより性能が向上 19 n Hybrid検索: 性質の異なる複数の検索⽅式を組み合わせる [重要度★★★] • 主流: BERTなどのベクトル検索&BM25などのキーワードベースの検索](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
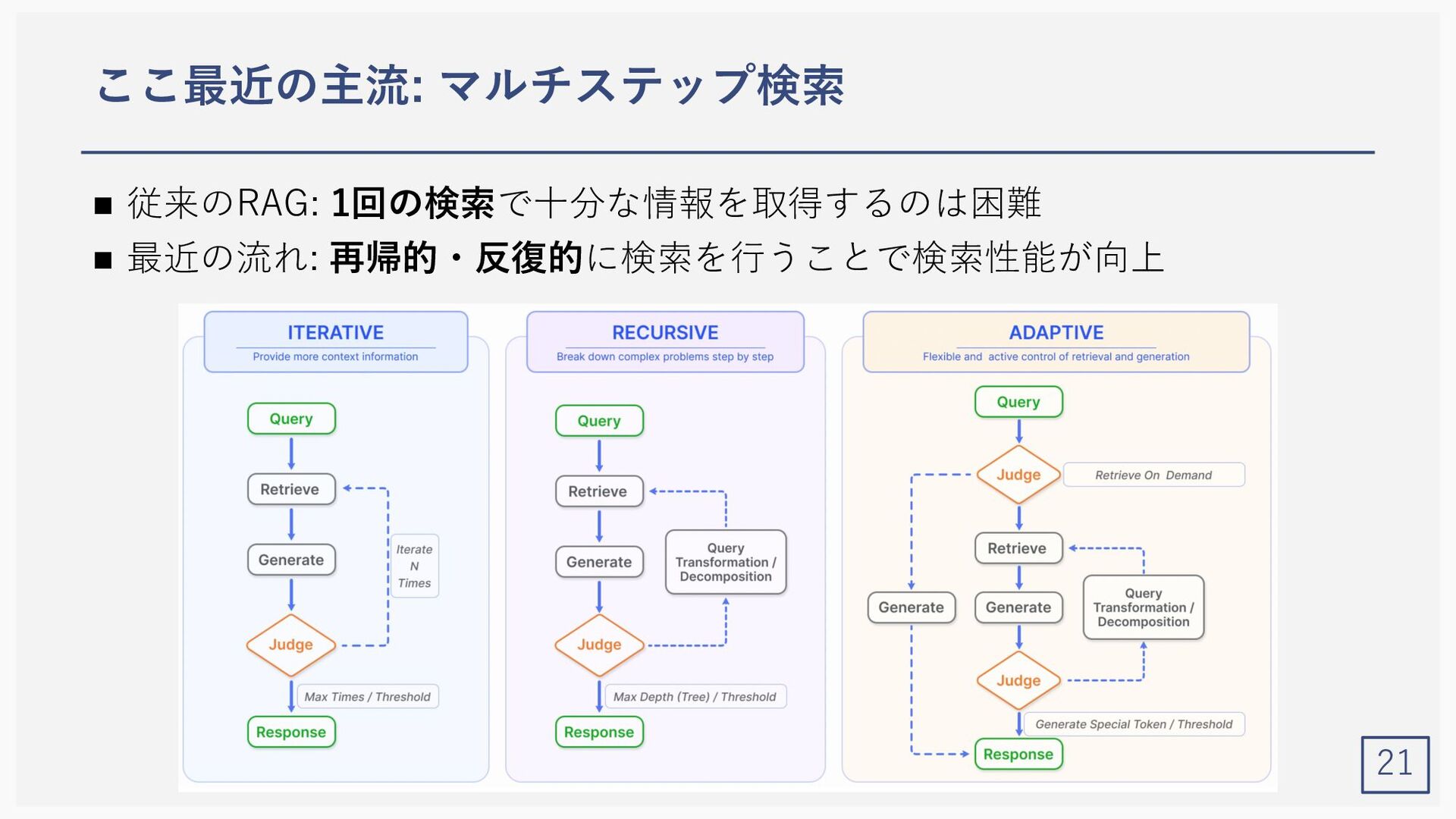
![反復検索により検索結果を洗練 22 n Iterative/Recursive Retrieval (反復・再起検索) [重要度★★] • 「検索→⽣成→評価」を繰り返すことにより性能向上 •](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_21.jpg){kind=link}
![Adaptive Retrieval: LLMが能動的に検索を制御 23 n Adaptive Retrieval (適応型検索) [重要度★★★] •](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_22.jpg){kind=link}
![Adaptive Retrieval: LLMが能動的に検索を制御 24 n Adaptive Retrieval (適応型検索) [重要度★★★] •](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_23.jpg){kind=link}
![Adaptive Retrieval: LLMが能動的に検索を制御 25 n Adaptive Retrieval (適応型検索) [重要度★★★] •](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_24.jpg){kind=link}
{kind=link}
![今後の展望: マルチモーダルRAG 27 n クエリを⾔語に限定せず,画像・動画・⾳声のクエリにも対応 • Transform-Retrieve-Generate [Gao+, CVPR22]](https://files.speakerdeck.com/presentations/fa31d8eb1db741659eff823edcbca9d1/slide_26.jpg){kind=link}
{kind=link}
{kind=link}