Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
500xCompressor: Generalized Prompt Compression ...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Jundai Inoue
September 22, 2025
88
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
500xCompressor: Generalized Prompt Compression for Large Language Models
Jundai Inoue
September 22, 2025
More Decks by Jundai Inoue
See All by Jundai Inoue
輪講資料:UNI-SIGN: TOWARD UNIFIED SIGN LANGUAGE UN- DERSTANDING AT SCALE
jkmt
0
17
VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
jkmt
0
650
T2S-GPT: Dynamic Vector Quantization for Autoregressive Sign Language Production from Text
jkmt
0
110
Featured
See All Featured
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Making the Leap to Tech Lead
cromwellryan
135
9.9k
The Spectacular Lies of Maps
axbom
PRO
1
810
Docker and Python
trallard
47
3.9k
Scaling GitHub
holman
464
140k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Paper Plane
katiecoart
PRO
1
51k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
840
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
230
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.2k
Everyday Curiosity
cassininazir
0
230
Transcript
ss ACL2025読み会@名⼤ 読み⼿:井上純⼤(豊⽥⼯業⼤学 知識データ⼯学研究室 M2) 2025/9/26 ACL2025読み会@名⼤ 1 ※ 図表は論⽂より引⽤
論⽂のまとめ • LLMの推論速度向上,コスト削減を ⽬的としたプロンプト圧縮を改善 • 最⼤500倍の圧縮率を達成し, 計算/メモリコストを27-90%/55-83%削減 • 圧縮後のプロンプトでもLLMの推論能⼒の 70%以上を維持
• 選定理由 • 対話やRAGなどでプロンプトが⻑くなる中 圧縮技術の重要性が増すと考えたため 2025/9/26 ACL2025読み会@名⼤ 2
⻑⽂プロンプトの課題と既存の圧縮⼿法 • ⻑⽂プロンプトは推論速度低下,計算コスト増,UX悪化を招く → プロンプト圧縮が重要 Hard Prompt(重要度の低い語/⽂を削除)[1] Soft Prompt(少数の特殊トークンに圧縮)[2] 2025/9/26
ACL2025読み会@名⼤ 3 [1] Li et al., Compressing Context to Enhance Inference Efficiency of Large Language Models, EMNLP 2023 [2] Tao et al., In-context Autoencoder for Context Compression in a Large Language Model, ICLR 2024
既存⼿法の課題と本研究の概要 • 低い圧縮率(最⼤15倍程度 [2]) → 500トークン規模のテキストを 最⼩1トークン まで圧縮 • 圧縮による情報損失の定量評価が不明瞭
→プロンプトの圧縮前後で,質問応答タスクの性能を⽐較評価 • 評価における訓練データとテストデータの重複 → LLMが事前学習で⾒ていない,完全に未知のデータで性能を検証 2025/9/26 ACL2025読み会@名⼤ 4
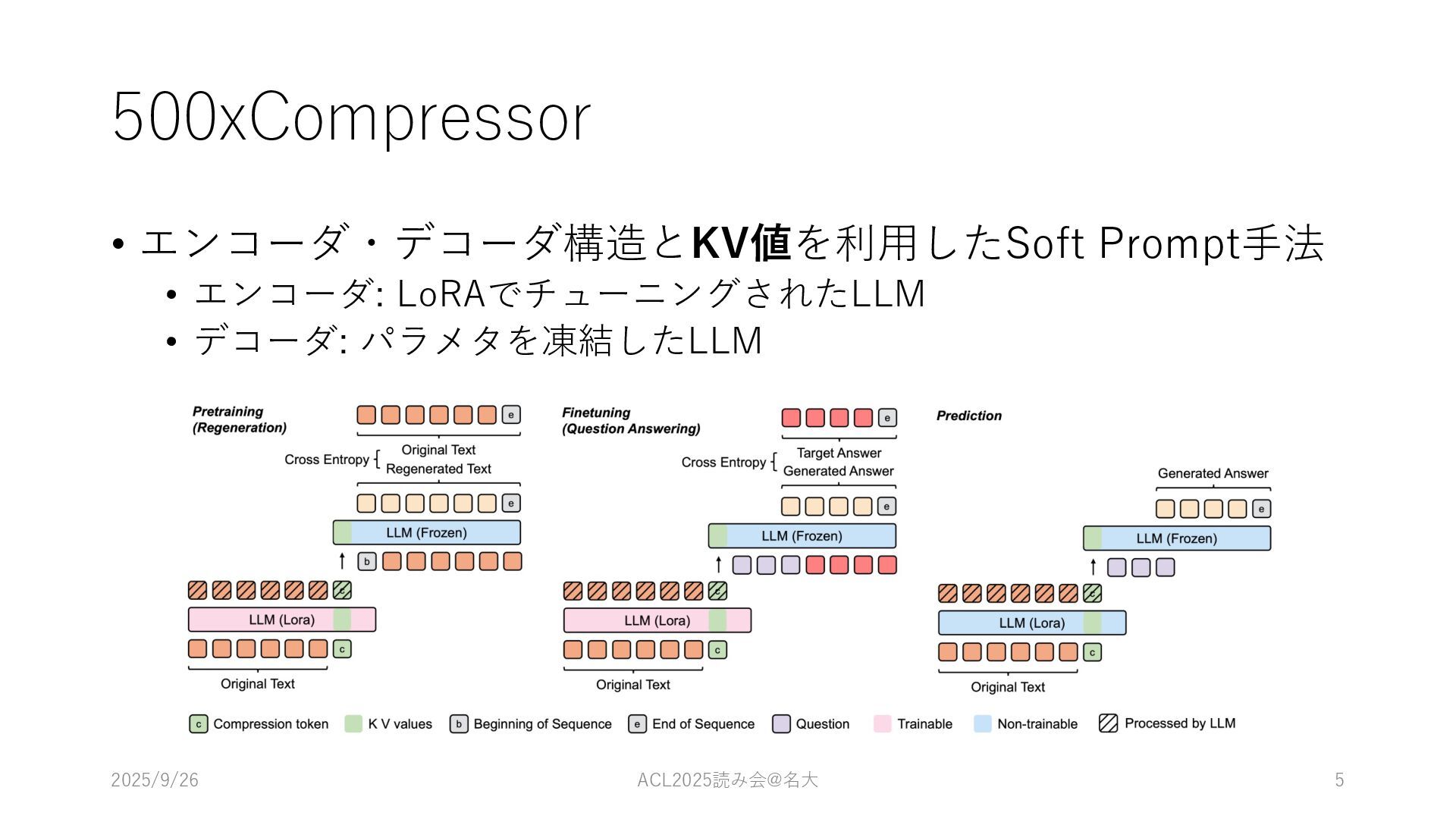
500xCompressor • エンコーダ・デコーダ構造とKV値を利⽤したSoft Prompt⼿法 • エンコーダ: LoRAでチューニングされたLLM • デコーダ: パラメタを凍結したLLM
2025/9/26 ACL2025読み会@名⼤ 5
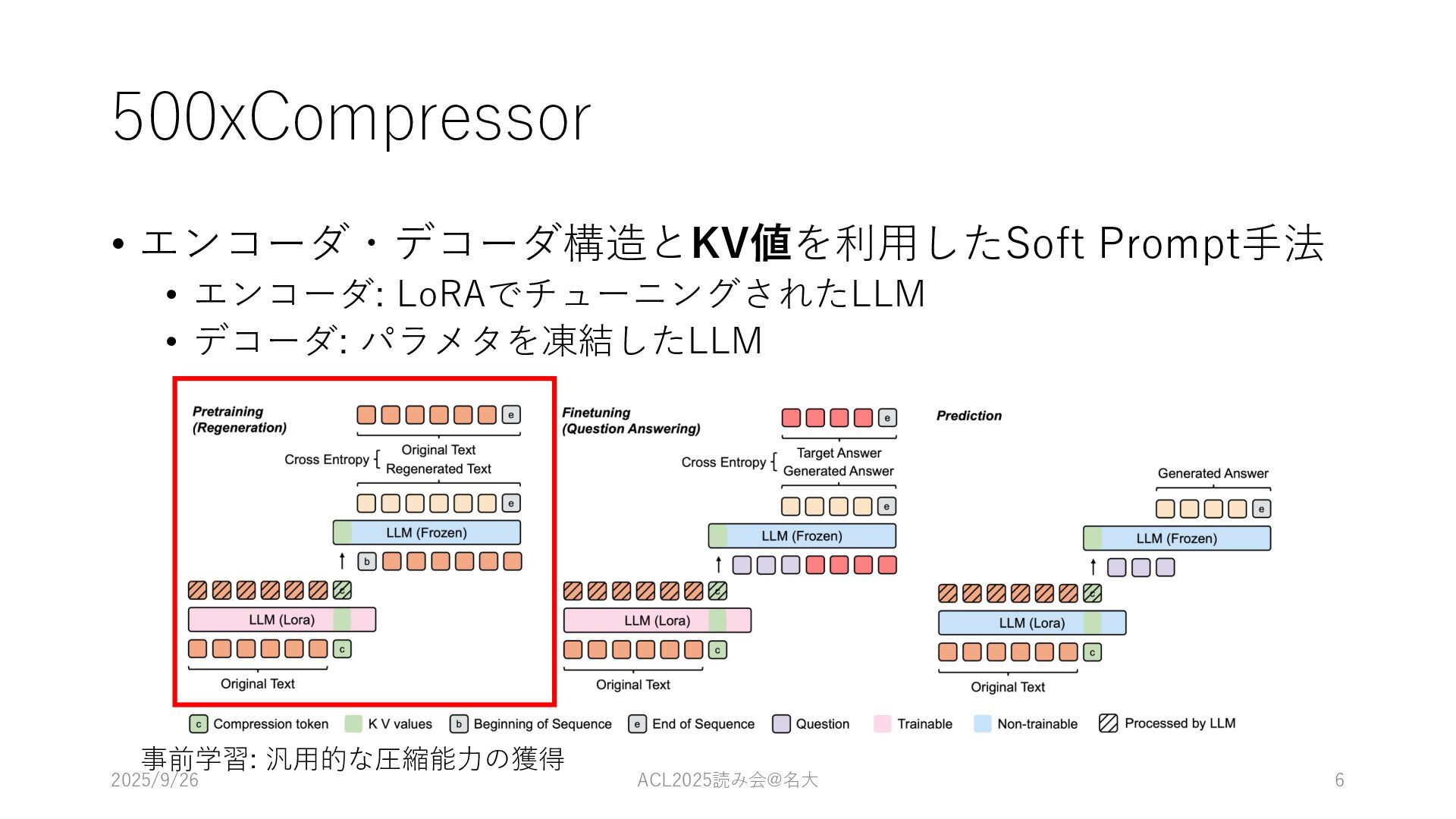
500xCompressor • エンコーダ・デコーダ構造とKV値を利⽤したSoft Prompt⼿法 • エンコーダ: LoRAでチューニングされたLLM • デコーダ: パラメタを凍結したLLM
事前学習: 汎⽤的な圧縮能⼒の獲得 2025/9/26 ACL2025読み会@名⼤ 6
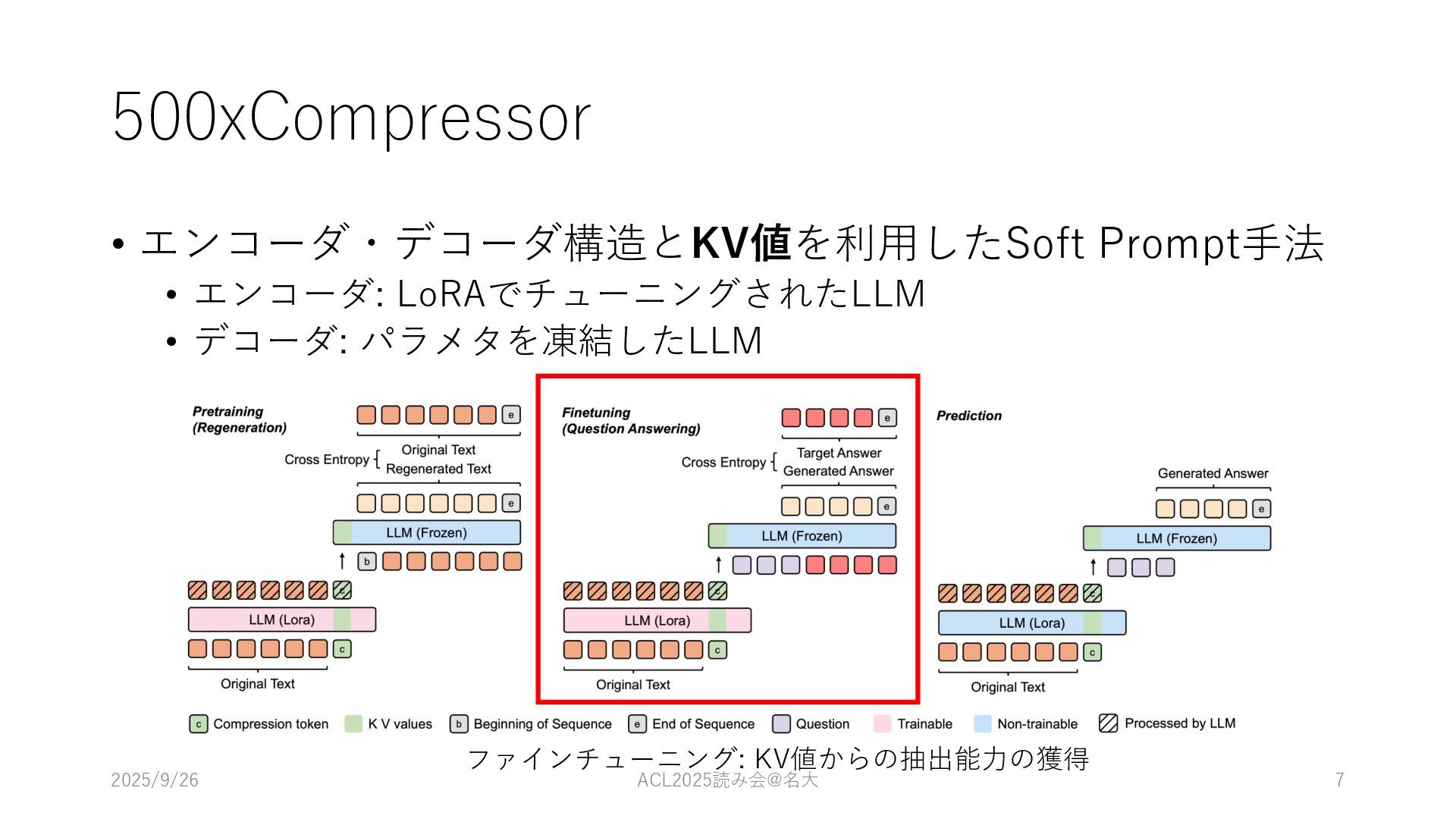
500xCompressor • エンコーダ・デコーダ構造とKV値を利⽤したSoft Prompt⼿法 • エンコーダ: LoRAでチューニングされたLLM • デコーダ: パラメタを凍結したLLM
ファインチューニング: KV値からの抽出能⼒の獲得 2025/9/26 ACL2025読み会@名⼤ 7
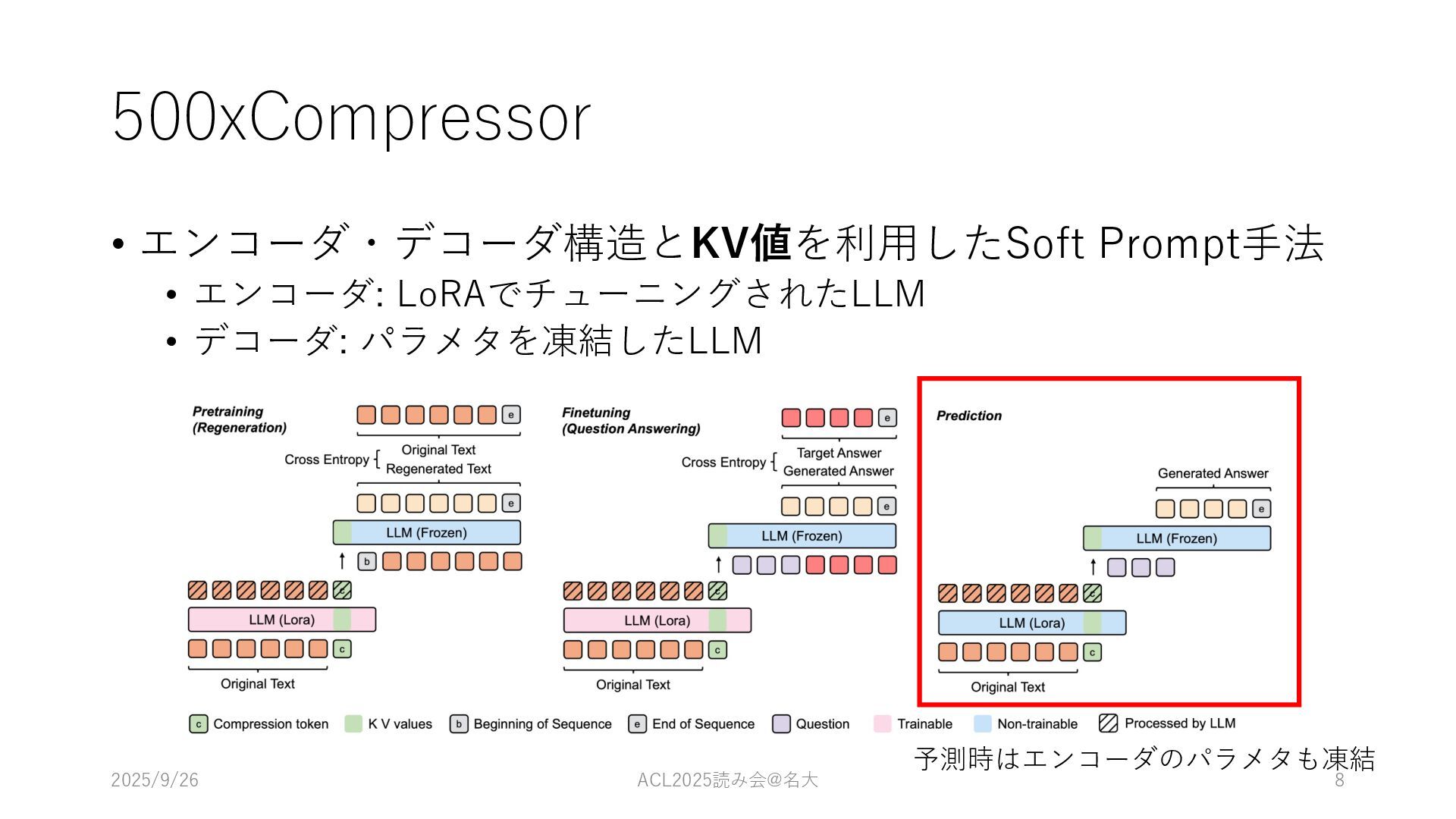
500xCompressor • エンコーダ・デコーダ構造とKV値を利⽤したSoft Prompt⼿法 • エンコーダ: LoRAでチューニングされたLLM • デコーダ: パラメタを凍結したLLM
予測時はエンコーダのパラメタも凍結 2025/9/26 ACL2025読み会@名⼤ 8
既存のSoft Prompt⼿法[2]との⽐較 • 提案⼿法はKV値に圧縮トークンをそのまま使⽤ • 既存⼿法はLLMの⼊⼒に圧縮トークンを使⽤ →圧縮した情報の劣化を防ぎ,推論速度も維持 2025/9/26 ACL2025読み会@名⼤ 9
実験設定 • ArxivCorpus(アブストラクト): 事前学習データ • LLM (LLaMA-3-8B) の知識カットオフ後の論⽂のみをテストに使⽤ • 訓練:
250,000,開発: 2,500,テスト: 5,000 • ArxivQA: ファインチューニングデータ • ArxivCorpusからLLaMA-3-70bを⽤いてデータ⽣成 • 訓練: 2,353,924,開発: 3,000,テスト: 2,500 • 評価指標 • 再⽣成タスク: ROUGE-2, BLEU • QAタスク: F1スコア, Exact Match (EM) 2025/9/26 ACL2025読み会@名⼤ 10
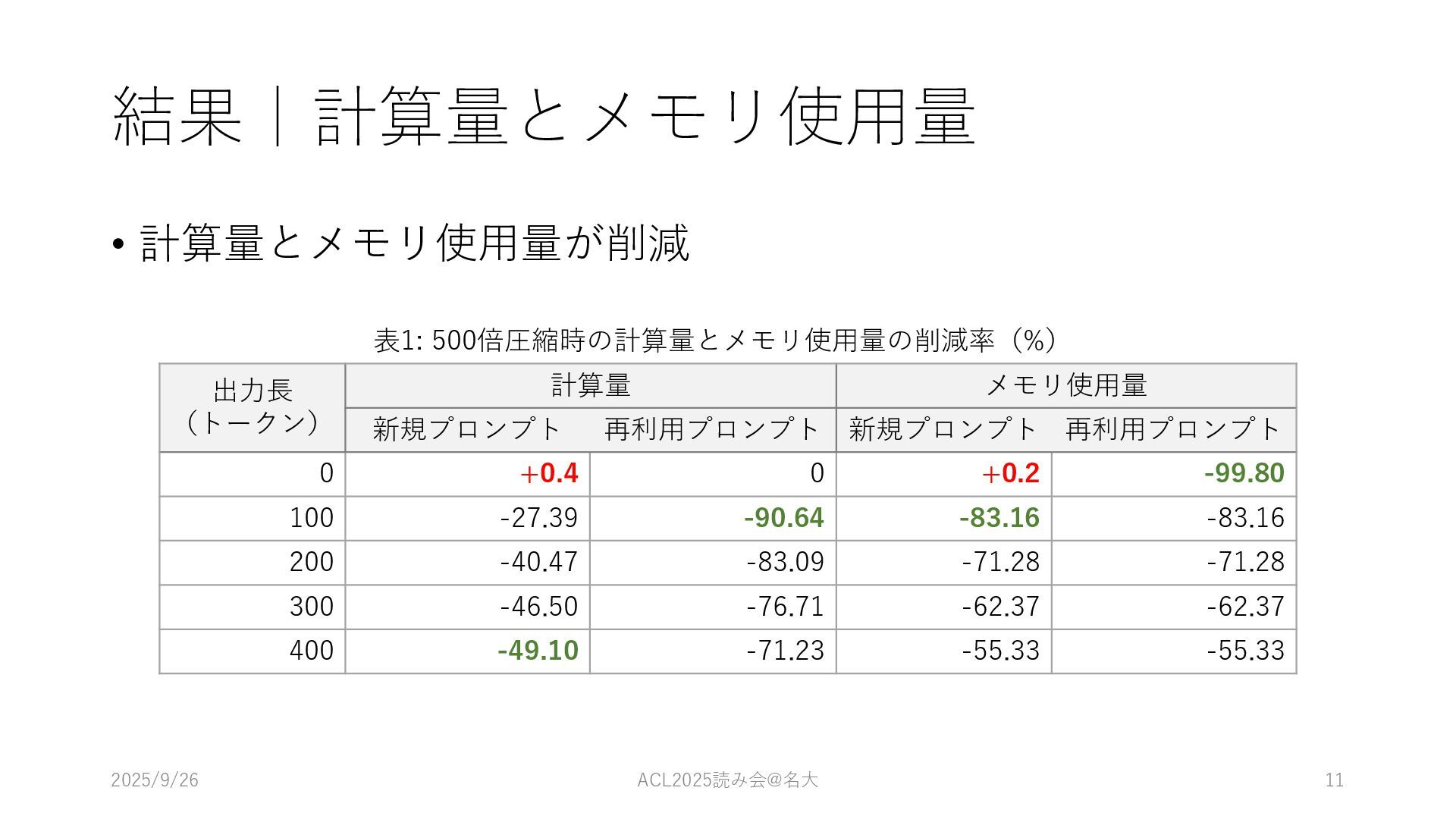
結果|計算量とメモリ使⽤量 • 計算量とメモリ使⽤量が削減 表1: 500倍圧縮時の計算量とメモリ使⽤量の削減率(%) 2025/9/26 ACL2025読み会@名⼤ 11 出⼒⻑ (トークン)
計算量 メモリ使⽤量 新規プロンプト 再利⽤プロンプト 新規プロンプト 再利⽤プロンプト 0 +0.4 0 +0.2 -99.80 100 -27.39 -90.64 -83.16 -83.16 200 -40.47 -83.09 -71.28 -71.28 300 -46.50 -76.71 -62.37 -62.37 400 -49.10 -71.23 -55.33 -55.33
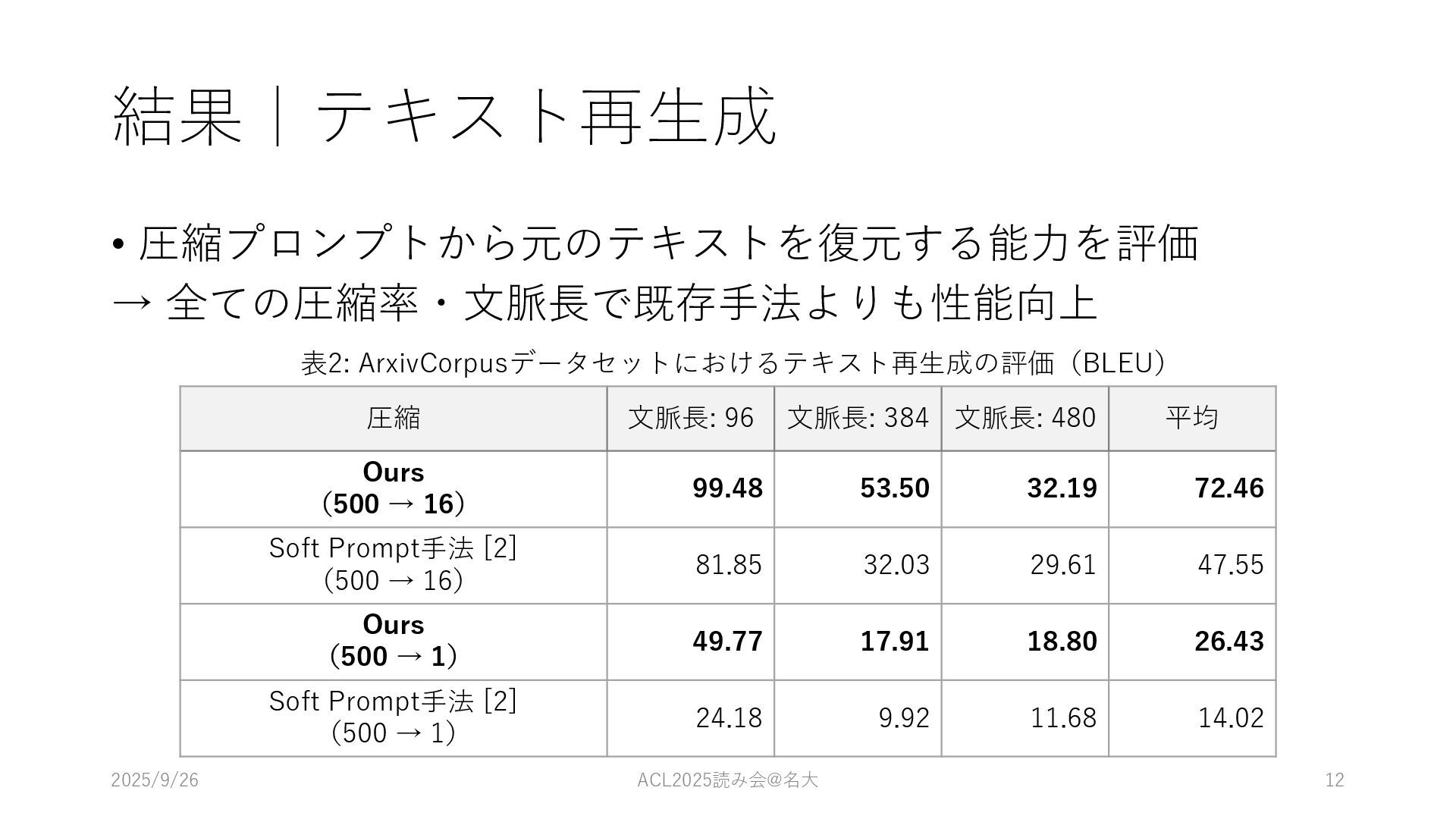
結果|テキスト再⽣成 • 圧縮プロンプトから元のテキストを復元する能⼒を評価 → 全ての圧縮率・⽂脈⻑で既存⼿法よりも性能向上 2025/9/26 ACL2025読み会@名⼤ 12 圧縮 ⽂脈⻑:
96 ⽂脈⻑: 384 ⽂脈⻑: 480 平均 Ours (500 → 16) 99.48 53.50 32.19 72.46 Soft Prompt⼿法 [2] (500 → 16) 81.85 32.03 29.61 47.55 Ours (500 → 1) 49.77 17.91 18.80 26.43 Soft Prompt⼿法 [2] (500 → 1) 24.18 9.92 11.68 14.02 表2: ArxivCorpusデータセットにおけるテキスト再⽣成の評価(BLEU)
結果|圧縮による情報損失の定量評価 • 質問応答タスクで圧縮前後の性能差を⽐較 → ⾼い圧縮率でも70%の性能を維持 Soft Prompt⼿法 [2] Hard Prompt⼿法
2025/9/26 13
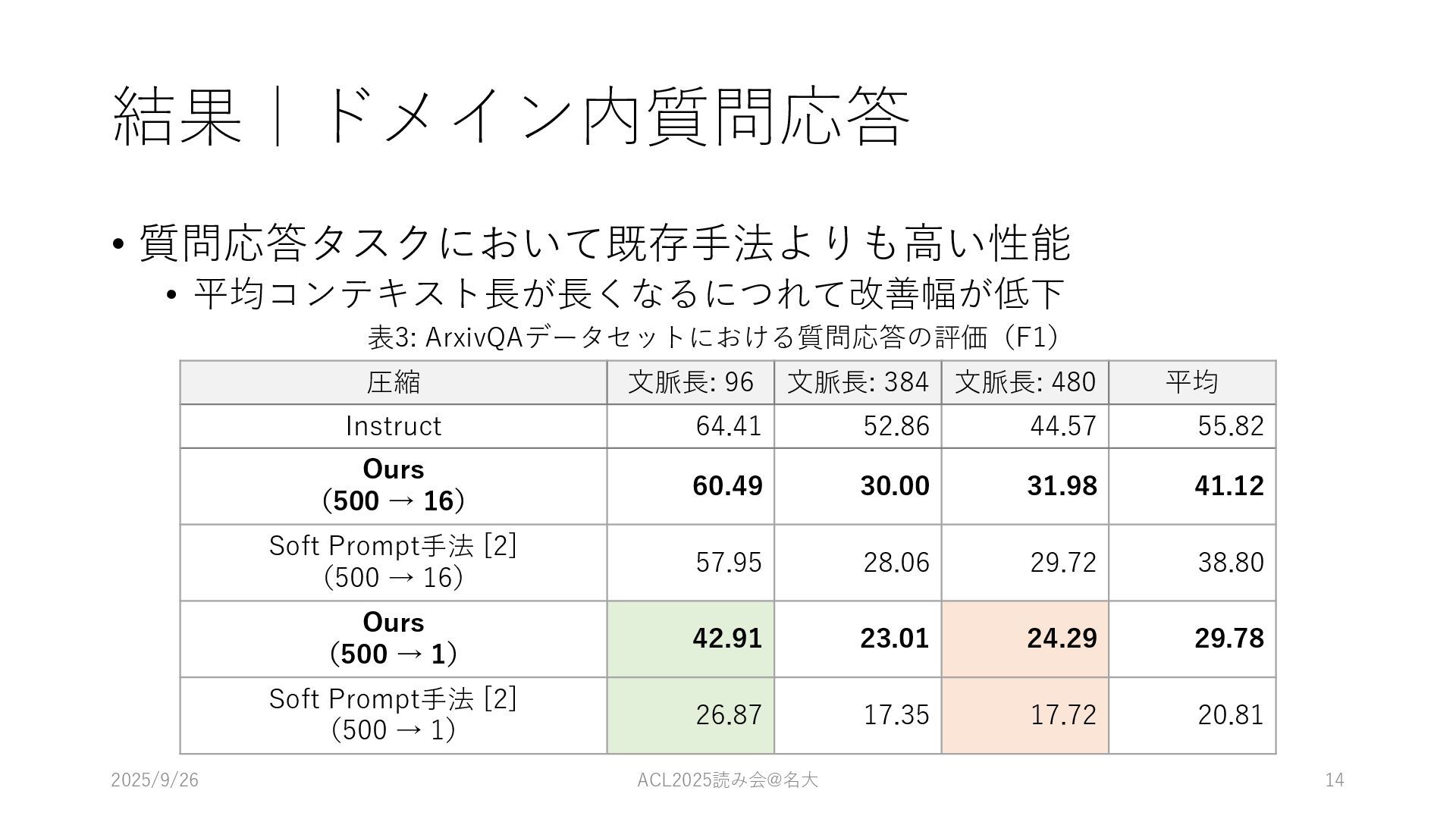
結果|ドメイン内質問応答 • 質問応答タスクにおいて既存⼿法よりも⾼い性能 • 平均コンテキスト⻑が⻑くなるにつれて改善幅が低下 2025/9/26 ACL2025読み会@名⼤ 14 圧縮 ⽂脈⻑:
96 ⽂脈⻑: 384 ⽂脈⻑: 480 平均 Instruct 64.41 52.86 44.57 55.82 Ours (500 → 16) 60.49 30.00 31.98 41.12 Soft Prompt⼿法 [2] (500 → 16) 57.95 28.06 29.72 38.80 Ours (500 → 1) 42.91 23.01 24.29 29.78 Soft Prompt⼿法 [2] (500 → 1) 26.87 17.35 17.72 20.81 表3: ArxivQAデータセットにおける質問応答の評価(F1)
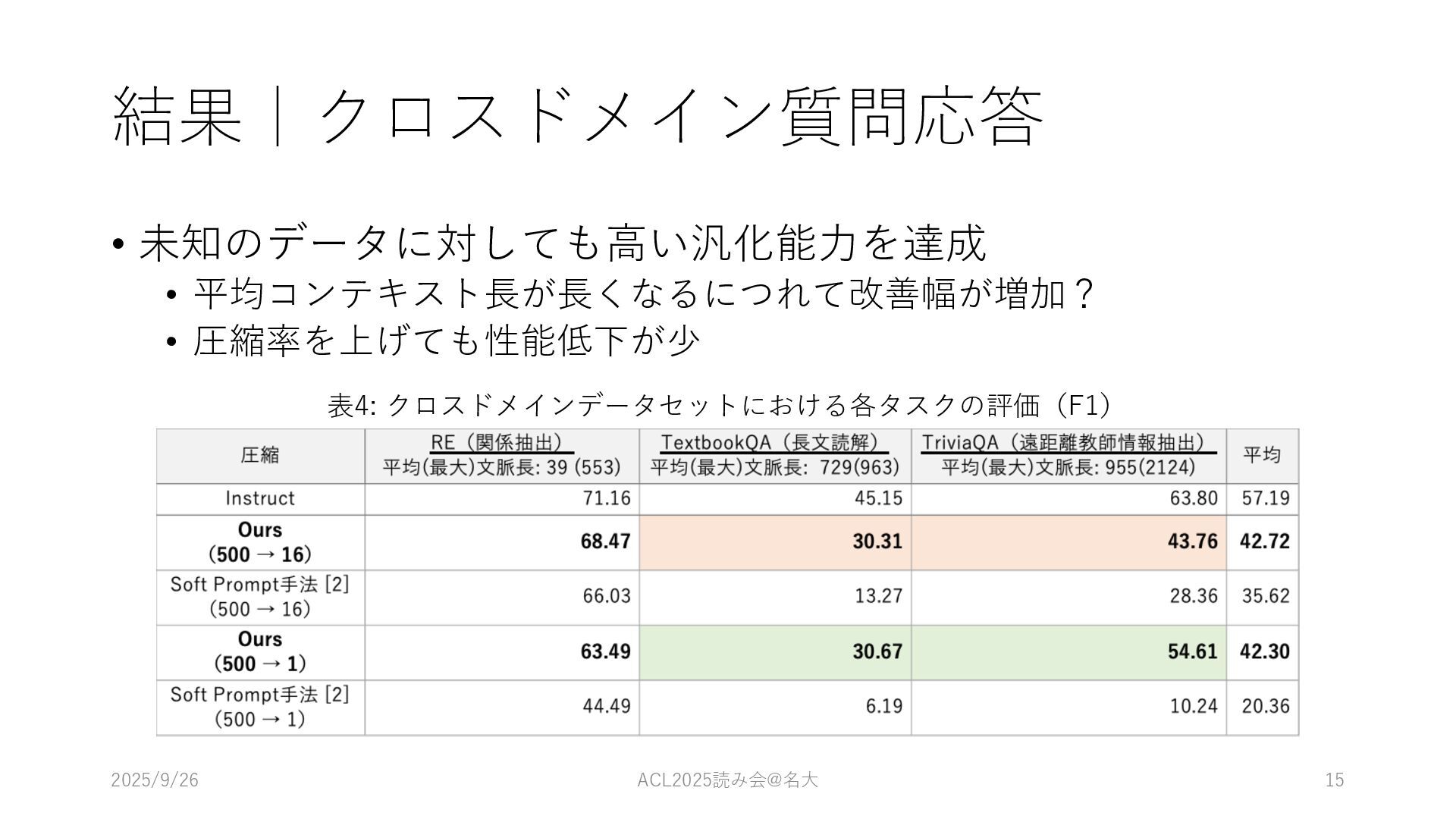
結果|クロスドメイン質問応答 • 未知のデータに対しても⾼い汎化能⼒を達成 • 平均コンテキスト⻑が⻑くなるにつれて改善幅が増加? • 圧縮率を上げても性能低下が少 2025/9/26 ACL2025読み会@名⼤ 15
表4: クロスドメインデータセットにおける各タスクの評価(F1)
Case Study • 情報の⽋落(⻩⾊) や間違い(⾚⾊) が少 • ハルシーネーション (⻘⾊)が少 2025/9/26
ACL2025読み会@名⼤ 16
圧縮トークンは「新しいLLM⾔語」か? • ⾔語が持つべき主要な3要素を,圧縮トークンが満たす • 情報の保存 • 圧縮されたKV値から,元のテキストを⾼精度で再⽣成可能 → 情報損失が少なく保存可能 •
情報の伝達 • 圧縮されたKV値を⽤いて様々な質問に正しく回答可能 → 保存された情報が意味を保ったまま伝達可能 • 適応性 • 学習データに含まれない未知のドメインのテキストを圧縮し、タスクを遂⾏可能 → この「⾔語」が新しい状況に適応できること⽰唆 →圧縮トークンはLLMにとって効率的な新たな⾔語となりうる 2025/9/26 ACL2025読み会@名⼤ 18
まとめ • ⾼圧縮・⾼性能な500xCompressorを提案 • 500倍の圧縮率を達成し,計算コスト/メモリコストを削減 • 圧縮後のプロンプトでもLLMの推論能⼒の70%以上を維持 • モデルにとって完全に未知のデータセットでの厳密な評価 •
クロスドメインタスクにも応⽤可能であることを確認 2025/9/26 ACL2025読み会@名⼤ 19
所感 • 感想 • 推論速度向上やコスト削減できるプロンプト圧縮は実応⽤で重要そう • クロスドメインタスクまで解けるのは興味深い • 疑問点 •
圧縮トークンを増やせば500トークン以上を圧縮できるのでは? • 8000トークンを16トークンに圧縮(500x) • 500トークン以上の⼊⼒が与えられた時の処理はどうなる? 2025/9/26 ACL2025読み会@名⼤ 20
{kind=link}
{kind=link}
![⻑⽂プロンプトの課題と既存の圧縮⼿法 • ⻑⽂プロンプトは推論速度低下,計算コスト増,UX悪化を招く → プロンプト圧縮が重要 Hard Prompt(重要度の低い語/⽂を削除)[1] Soft Prompt(少数の特殊トークンに圧縮)[2] 2025/9/26](https://files.speakerdeck.com/presentations/d8597f816f30440cb68e10b206c19a2c/slide_2.jpg){kind=link}
![既存⼿法の課題と本研究の概要 • 低い圧縮率(最⼤15倍程度 [2]) → 500トークン規模のテキストを 最⼩1トークン まで圧縮 • 圧縮による情報損失の定量評価が不明瞭](https://files.speakerdeck.com/presentations/d8597f816f30440cb68e10b206c19a2c/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![既存のSoft Prompt⼿法[2]との⽐較 • 提案⼿法はKV値に圧縮トークンをそのまま使⽤ • 既存⼿法はLLMの⼊⼒に圧縮トークンを使⽤ →圧縮した情報の劣化を防ぎ,推論速度も維持 2025/9/26 ACL2025読み会@名⼤ 9](https://files.speakerdeck.com/presentations/d8597f816f30440cb68e10b206c19a2c/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![結果|圧縮による情報損失の定量評価 • 質問応答タスクで圧縮前後の性能差を⽐較 → ⾼い圧縮率でも70%の性能を維持 Soft Prompt⼿法 [2] Hard Prompt⼿法](https://files.speakerdeck.com/presentations/d8597f816f30440cb68e10b206c19a2c/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}