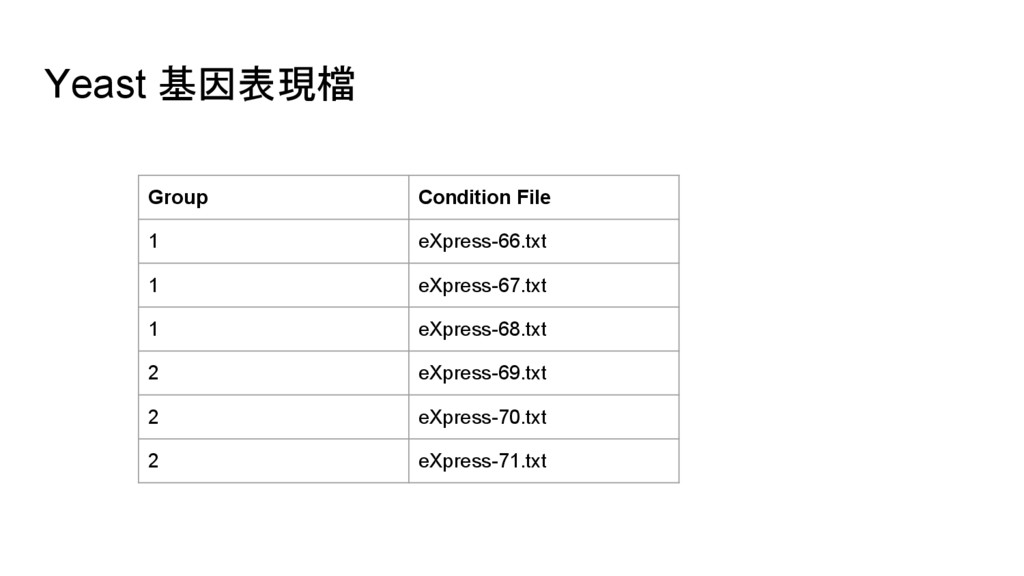
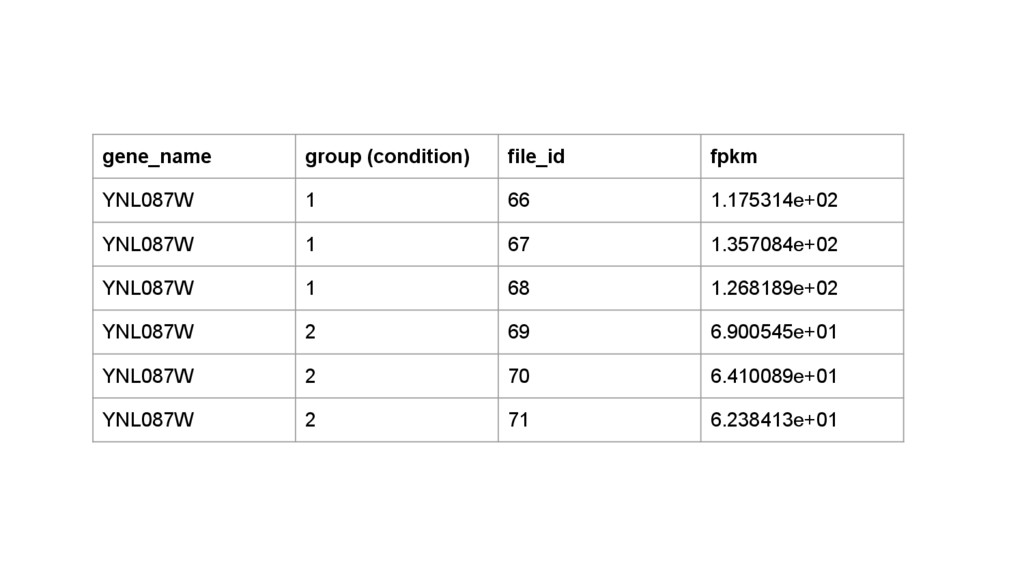
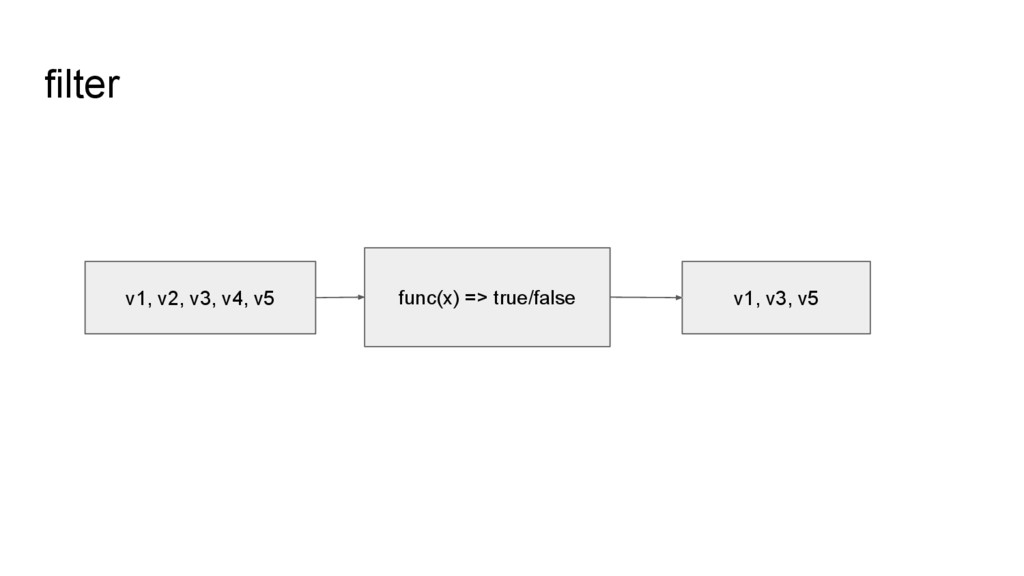
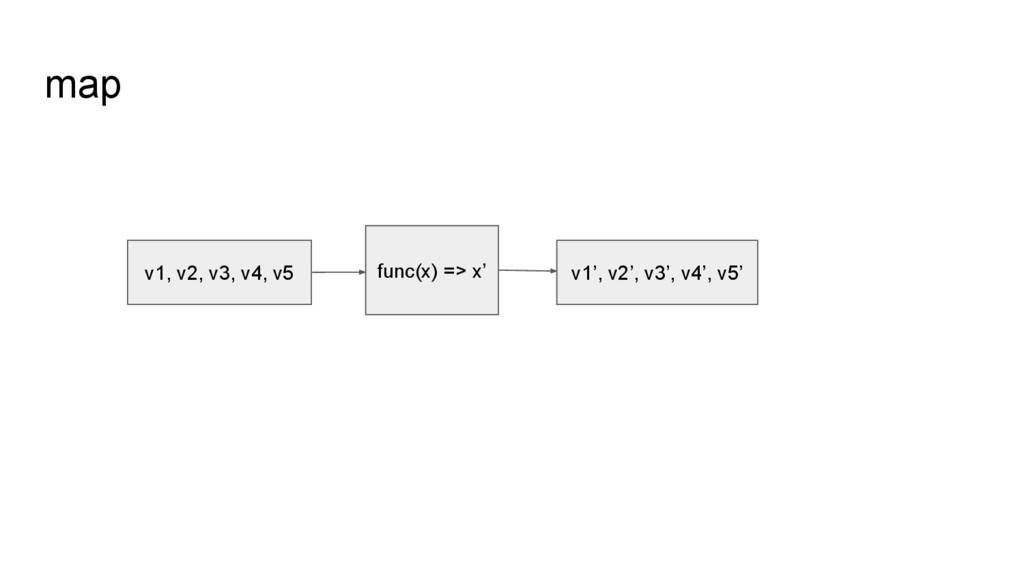
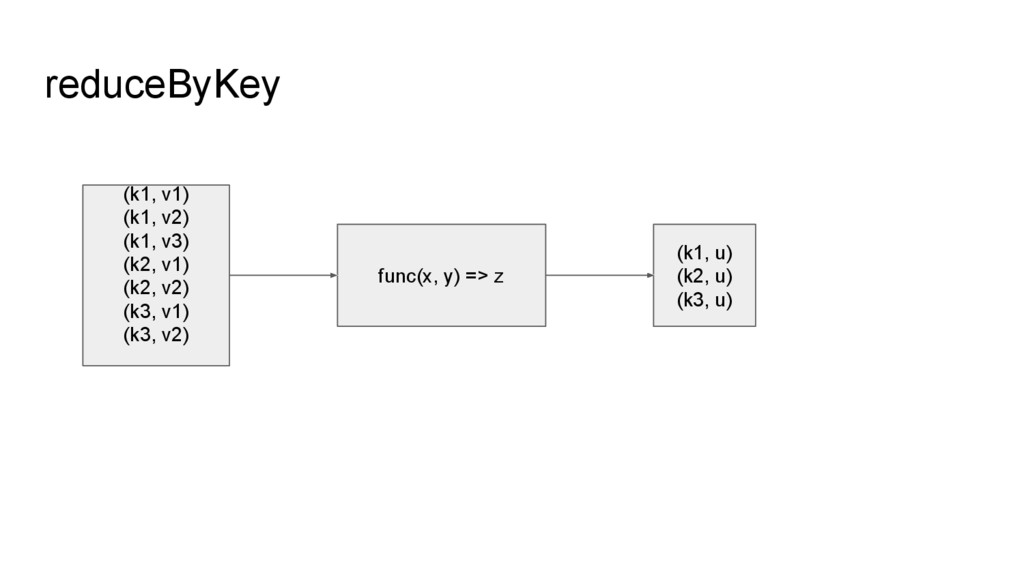
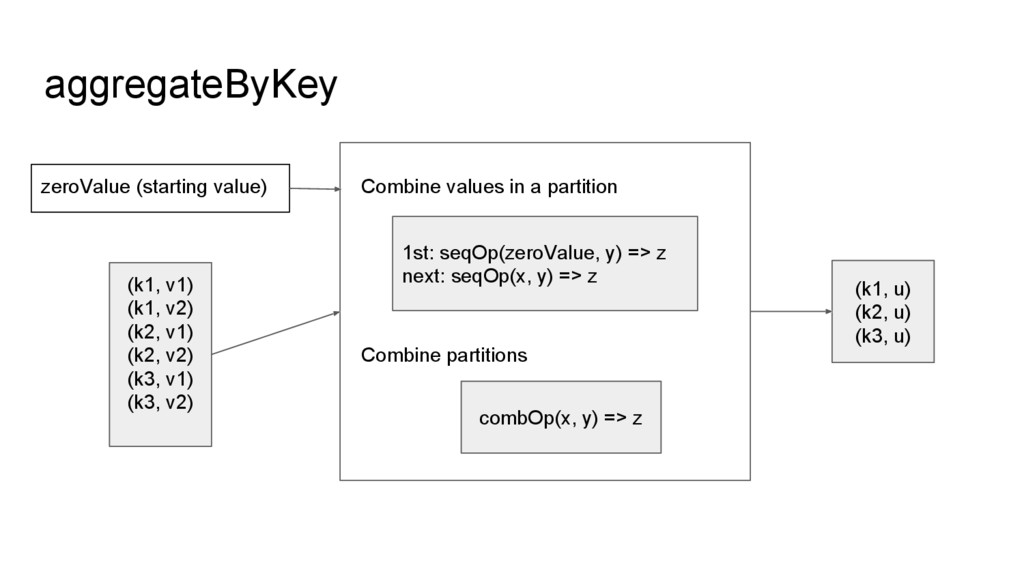
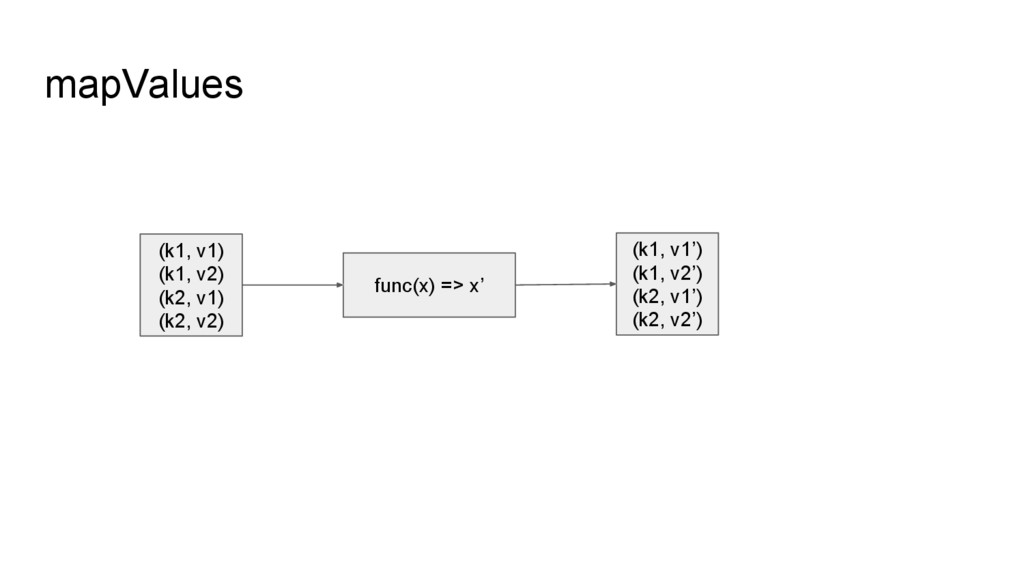
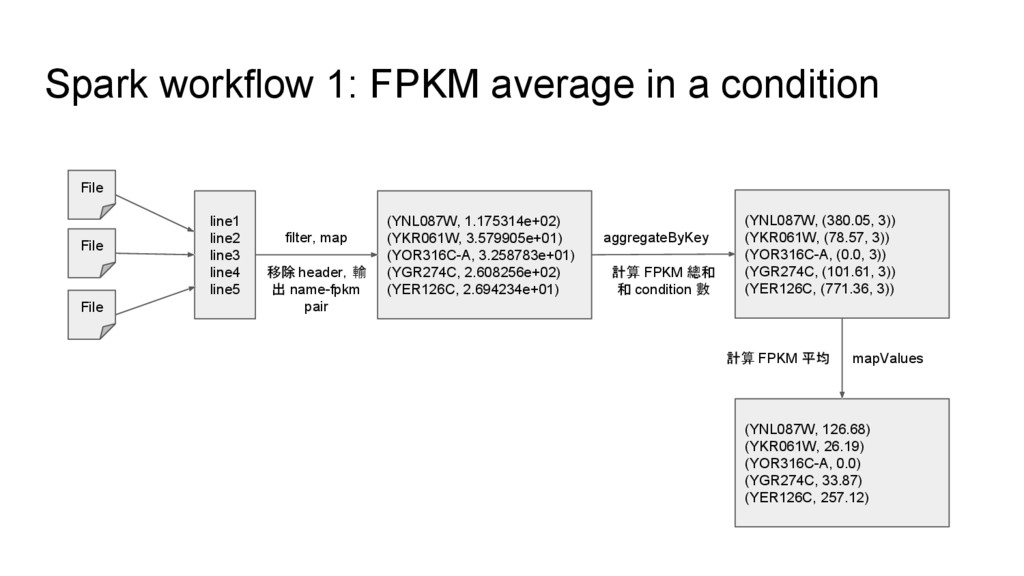
line2 line3 line4 line5 File File (YNL087W, 1.175314e+02) (YKR061W, 3.579905e+01) (YOR316C-A, 3.258783e+01) (YGR274C, 2.608256e+02) (YER126C, 2.694234e+01) filter, map (YNL087W, (380.05, 3)) (YKR061W, (78.57, 3)) (YOR316C-A, (0.0, 3)) (YGR274C, (101.61, 3)) (YER126C, (771.36, 3)) aggregateByKey (YNL087W, 126.68) (YKR061W, 26.19) (YOR316C-A, 0.0) (YGR274C, 33.87) (YER126C, 257.12) mapValues 計算 FPKM 總和 和 condition 數 移除 header,輸 出 name-fpkm pair 計算 FPKM 平均
{kind=link}
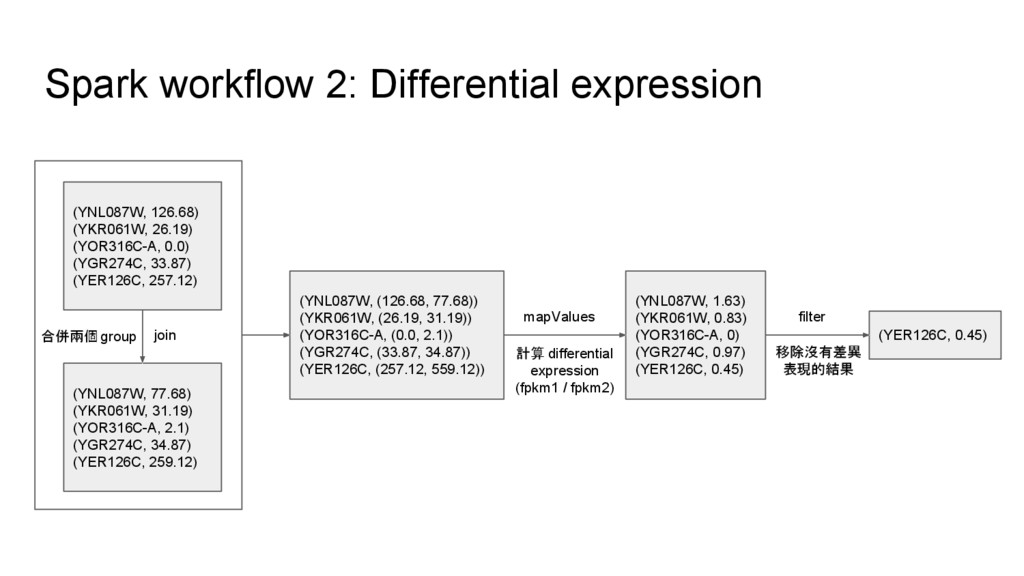
![[分析] 同一個RNA序列檔,可任選其中兩個 conditions 進行 differential analysis (最 好能擴展成任選兩個 groups of](https://files.speakerdeck.com/presentations/b72f861db3684da1848624d6c2edca7c/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}