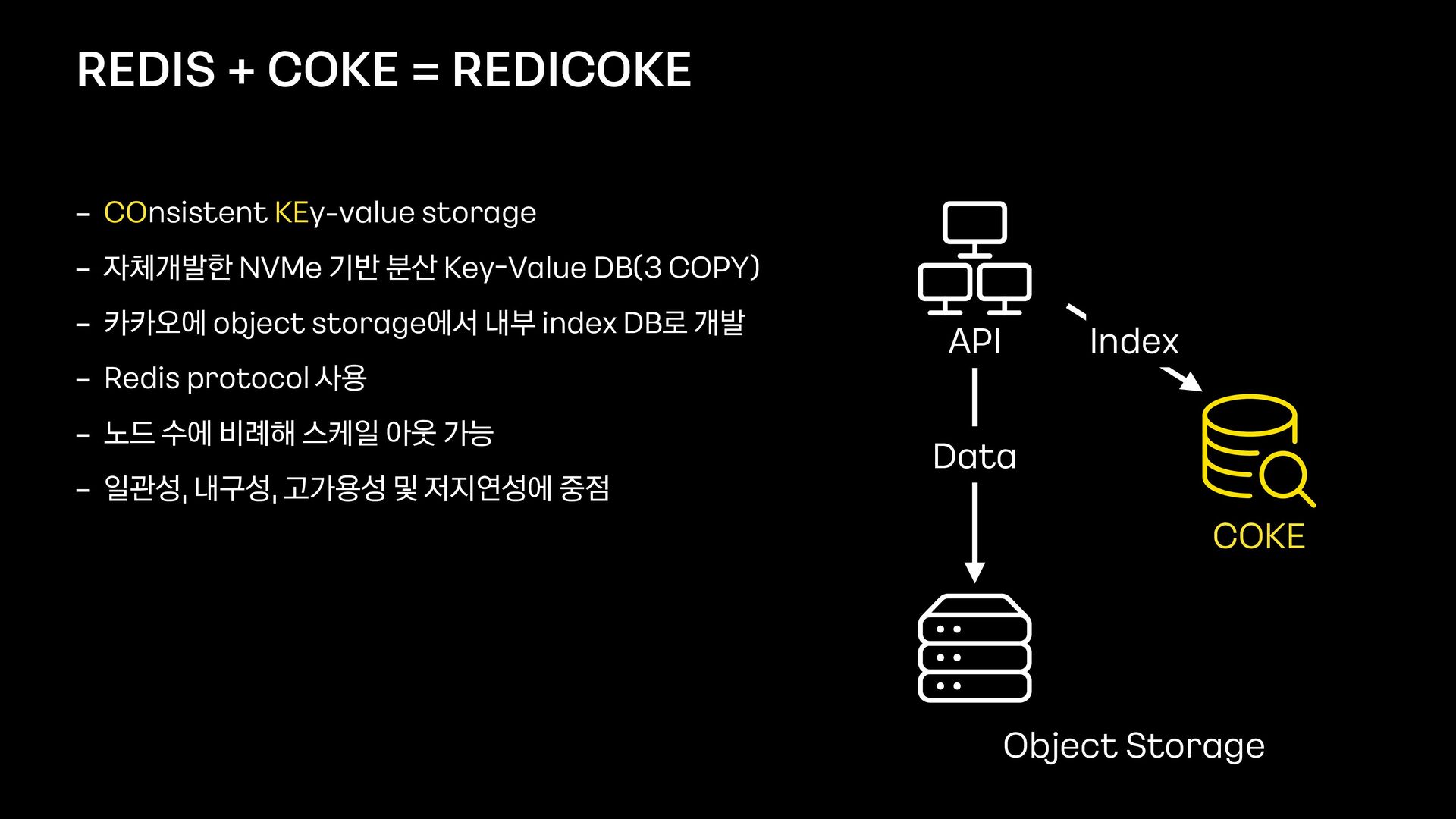
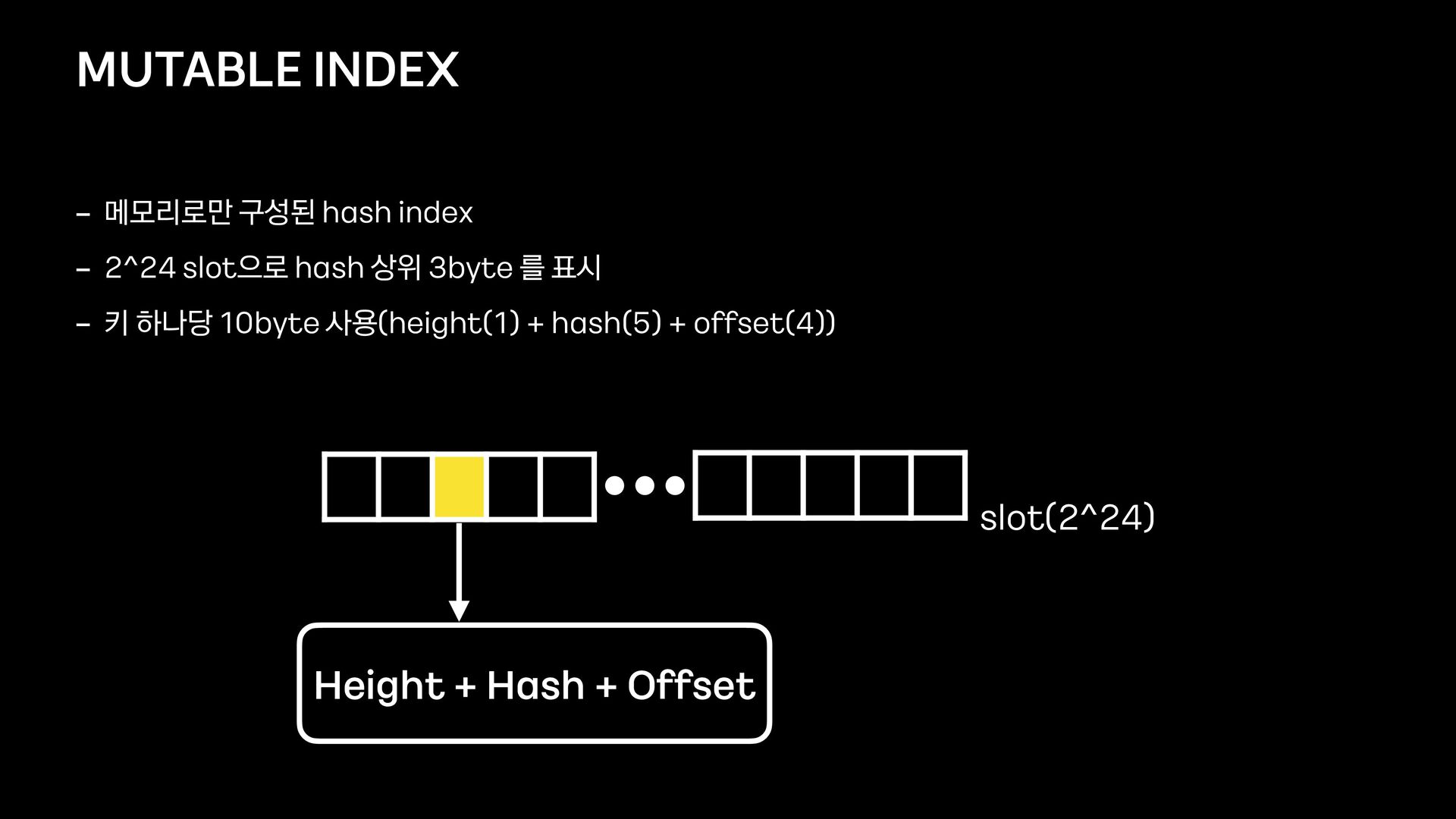
Index - COnsistent KEy - value storage - 자체개발한 NVMe 기반 분산 Key - Value DB(3 COPY) - 카카오에 object storage에서 내부 index DB로 개발 - Redis protocol 사용 - 노드 수에 비례해 스케일 아웃 가능 - 일관성, 내구성, 고가용성 및 저지연성에 중점
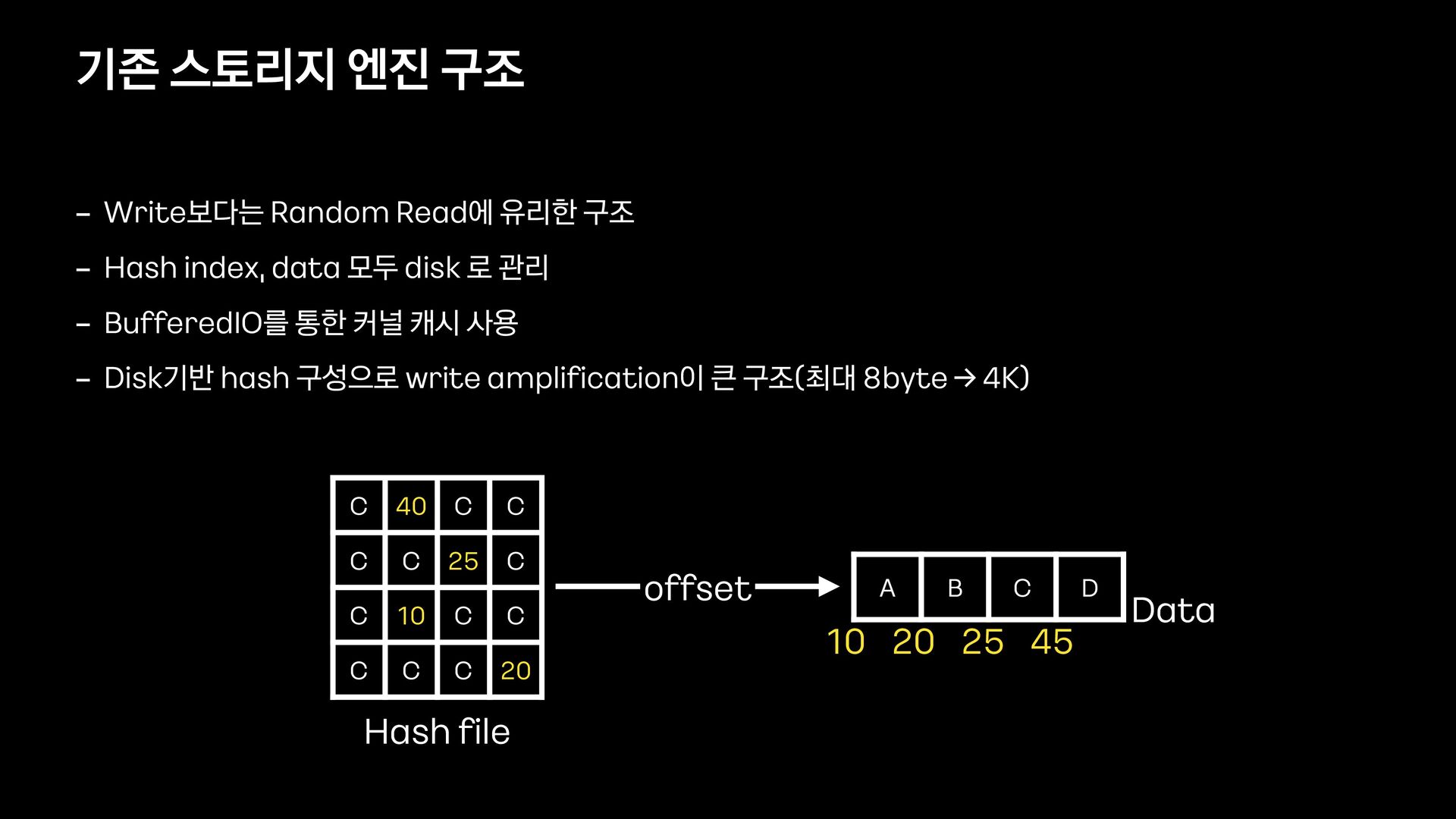
25 C C 10 C C C C C 20 Hash fi le A B C D Data offset 10 20 25 45 - Write보다는 Random Read에 유리한 구조 - Hash index, data 모두 disk 로 관리 - BufferedIO를 통한 커널 캐시 사용 - Disk기반 hash 구성으로 write ampli fi cation이 큰 구조(최대 8byte -> 4K)
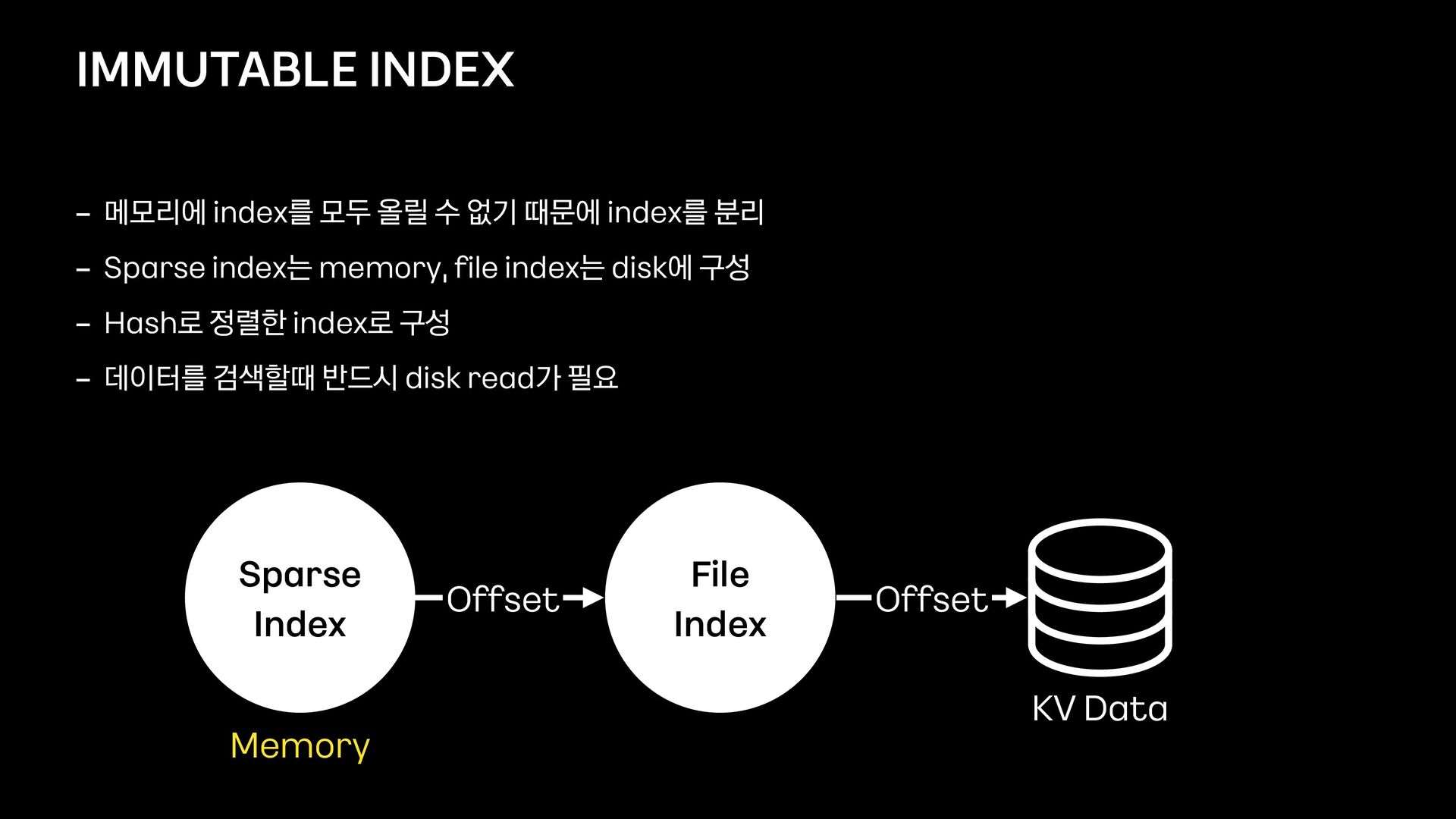
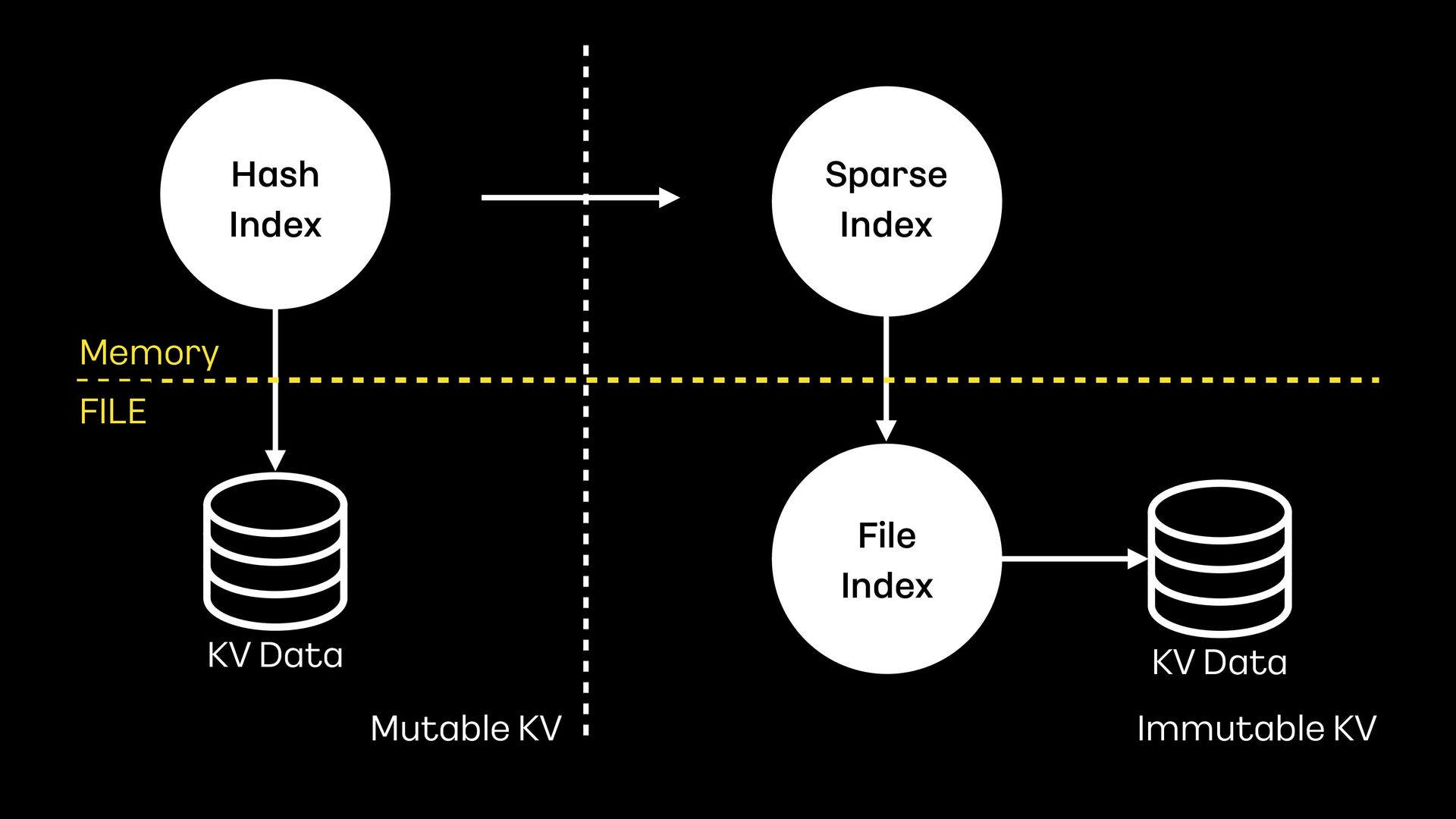
index를 분리 - Sparse index는 memory, fi le index는 disk에 구성 - Hash로 정렬한 index로 구성 - 데이터를 검색할때 반드시 disk read가 필요 Sparse Index File Index KV Data Offset Offset Memory
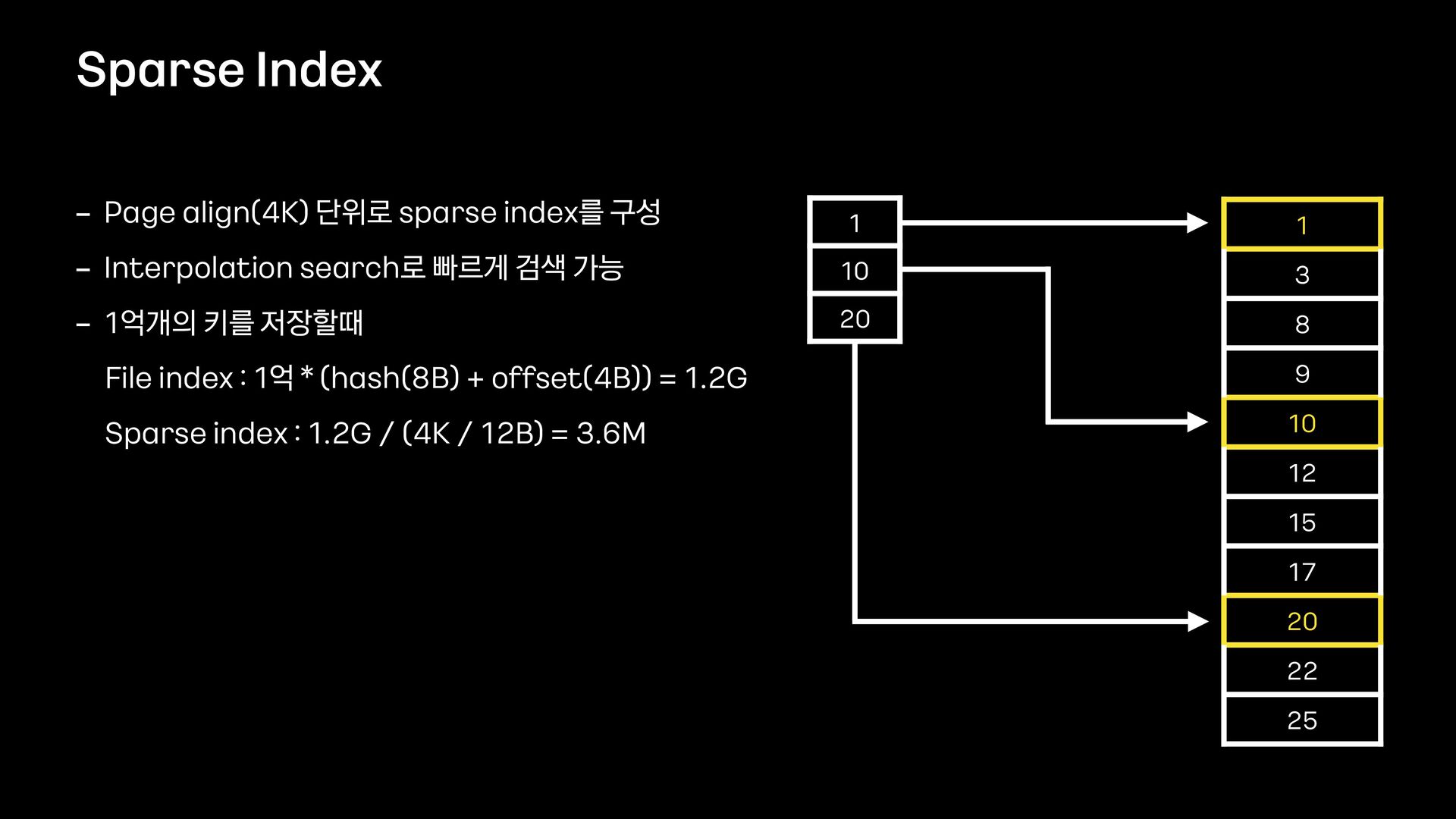
12 15 17 20 22 25 - Page align(4K) 단위로 sparse index를 구성 - Interpolation search로 빠르게 검색 가능 - 1억개의 키를 저장할때 File index : 1억 * (hash(8B) + offset(4B)) = 1.2G Sparse index : 1.2G / (4K / 12B) = 3.6M
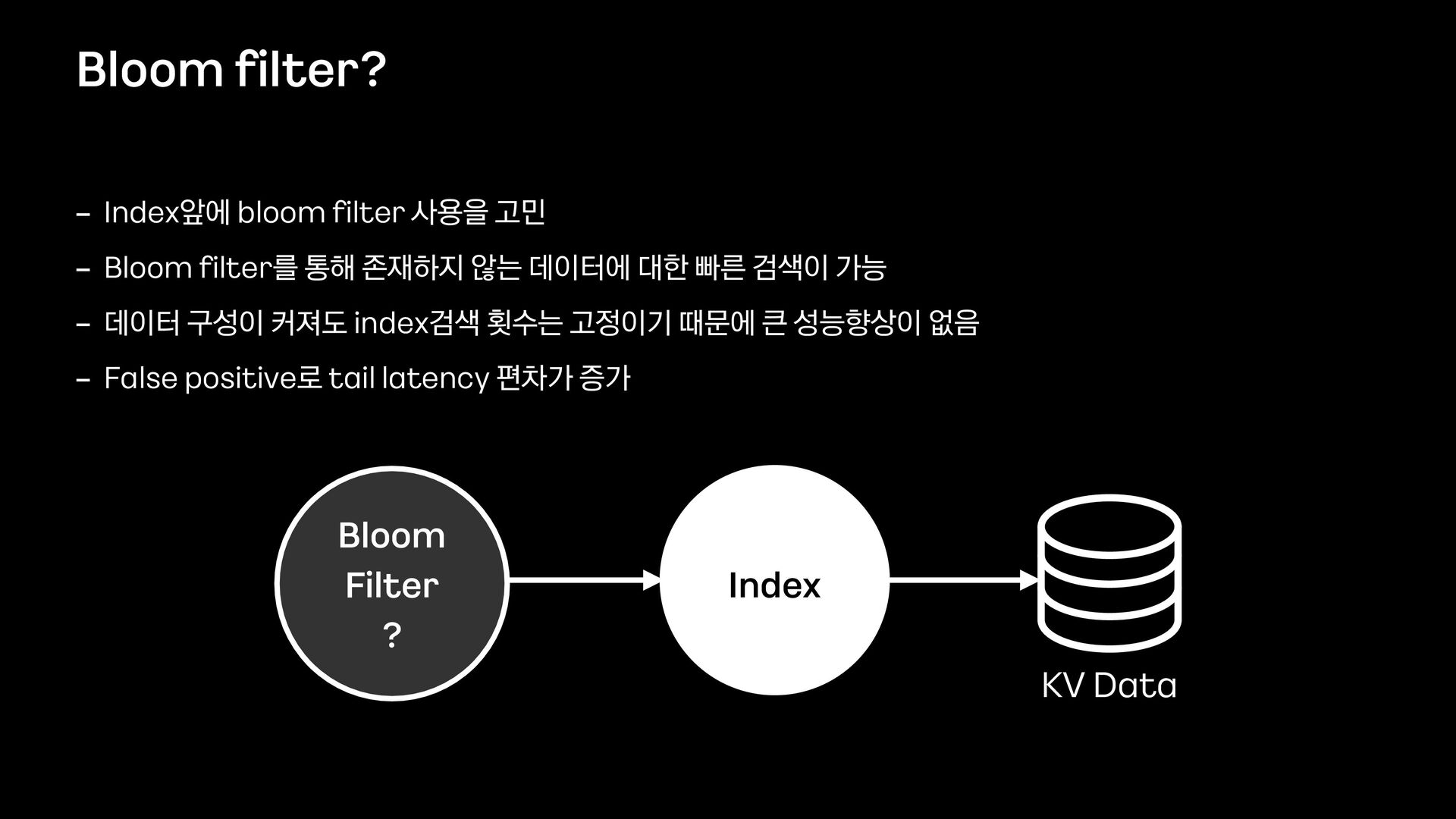
Data - Index앞에 bloom fi lter 사용을 고민 - Bloom fi lter를 통해 존재하지 않는 데이터에 대한 빠른 검색이 가능 - 데이터 구성이 커져도 index검색 횟수는 고정이기 때문에 큰 성능향상이 없음 - False positive로 tail latency 편차가 증가
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}