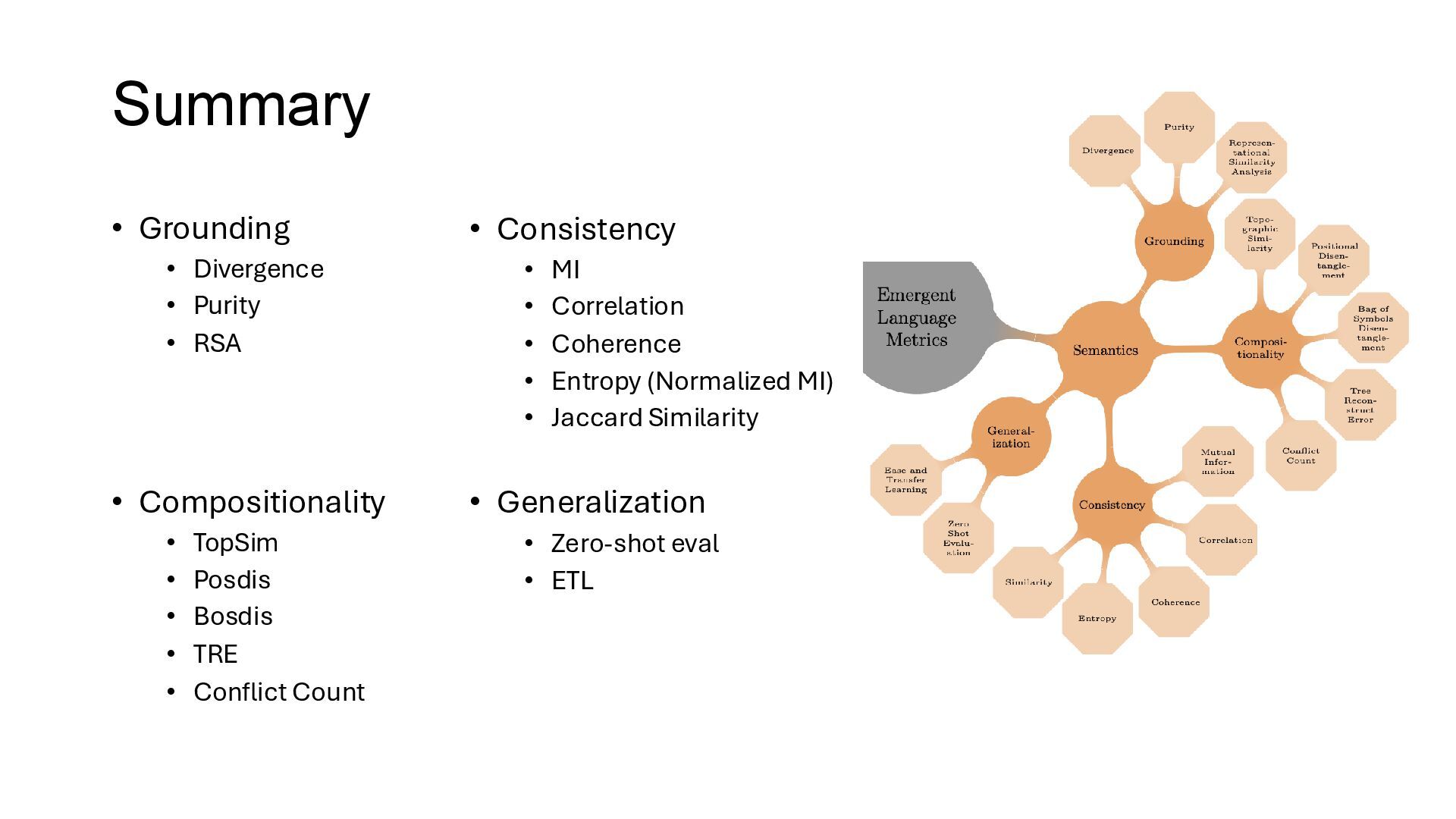
• A metric for evaluating the alignment between EL and NL • It ensurse that the statistical properties of EL messages resemble those of NL. • It allows that the same word can correspond to completely different concepts in the induced EL and NL (Weak grounding). • G_div: Grounding Divergence • k: sample • m: message • P_NL: true NL distribution (Can be approximated by trained language model)
• A metric for evaluating the alignment between predefined semantic categories and those observed in an EL. • It requires the existence of predefined ground- truth labels {C_k} : a set of clusters c_k: corresponding majority ground-truth label for each cluster sample C_k 1. Form clusters by grouping samples based on the most frequently activated words to describe them. 2. Evaluate the quality of these clusters using Purity metric
al. • Measures the global agreement between spaces, independent of their dimensionality • Has been employed to compare the similarity of embedding space structures between input, sender, and receiver in a referential game oξ: agent ξ’s observation. e (oξ) : ground truth structured embedding. φξ: internal meaning representation of agent ξ. R: conversion to rank vectors. (+) Applicable to heterogeneous agents and arbitrary input spaces. (-) Necessity for an embedding (not directly applicable to the language itself, particularly for discrete languages).
guidance, as it does not naturally arise without specific interventions. • When a language is truly compositional, its components can be systematically rearranged or substituted with conceptually equivalent components without altering the overall meaning A language is compositional if L_prod and L_comp act as a homomorphism. (e.g.) L_comp: comprehension function L_prod: production function
Kirby, first applied to EL by Lazaridou et al. • Measure Spearman correlation between the pairwise distances in the input and message spaces (internal alignment within an agent’s meaning and message spaces. ) • The intuition behind this measure: semantically similar objects should have similar messages 1. sample k meaning representations from Φ. ∆L, ∆Φ: distance function for language and meaning space discrete space: Hamming or Levenshtein distance continuous spaces: cosine or Euclidean distance 2. Genrate corresponding messages for each sample. 3. Calculate ρ.
• A metric for evaluating the extent to which words in specific positions within a message uniquely correspond to particular attributes of the input. • “posdis assumes a message whose length equals the number of attributes in the input object, and where each message token, in a specific position, represents a single attribute” • characteristic feature of NL structures and is essential for the emergence of sophisticated syntactic patterns m: message w_p: word at position p. f: feature vector of the ground truth.
et al. • Relaxes the assumption of posdis; introduce permutation-invariance. • Order of words is irrelevant, and only the frequency of words carries meaning. • Maintains the requirement that each symbol uniquely refers to a distinct meaning, but shifts the focus to symbol counts as the primary informative element.
between a compositional approximation and the actual structure, using a composition function and a distance metric. • Measures the accuracy with which a given communication protocol can be reconstructed while adhering to the compositional structure of the derivation or embedding of the input e ∈ E. • Assumes prior knowledge of the compositional structure within the input data (an oracle setting). (+) • Flexibility across different settings, whether discrete or continuous. • Allows for various choices of compositionality functions, distance metrics, and other parameters (-) • requirement for an oracle-provided ground truth. • Necessity of pre-trained continuous embeddings.
:Learned language speaker :Learnable approximation function of TRE that satisfies: embedding consistency compositionality k (k ∈ K): sample from dataset m (m ∈ M): corresponding message Requirements δ : Distance fucntion η : Learnable parameters of a distance fucntion ◦ : Compositionality function e ∈ E : Pre-trained embeddings of ground truth
between the output of the learned language speaker and the approximation function, based on the ground truth The datum level The dataset level • TRE can be calcualated at two levels: • TRE value of zero indicates perfect reproduction of compositionality.
to which the assignment of features to words in a language deviates from the word’s principal meaning • Useful in scenarios where the language employs synonyms. • (Skip detail) Compositionality Metrics: Conflict Count
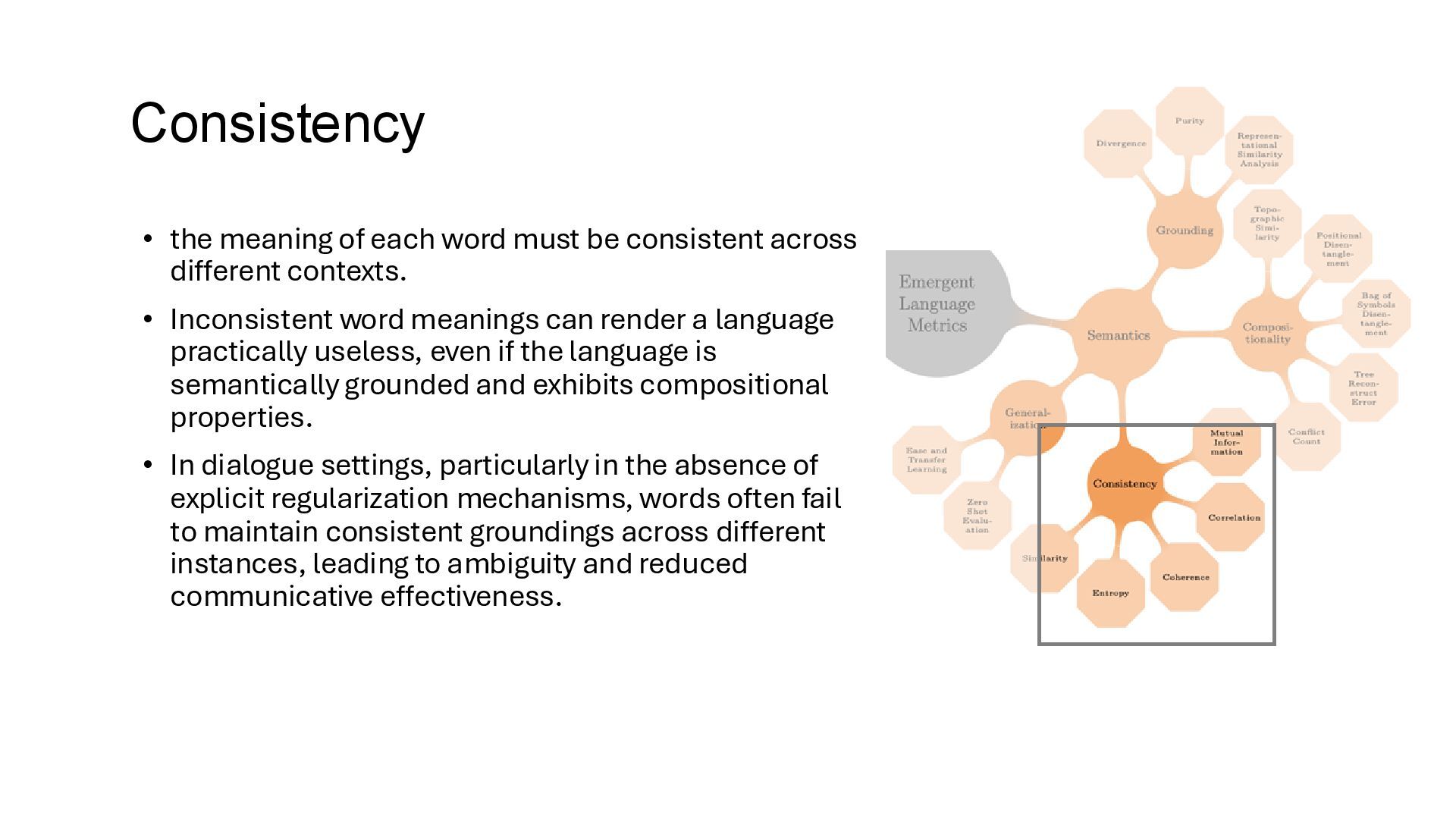
different contexts. • Inconsistent word meanings can render a language practically useless, even if the language is semantically grounded and exhibits compositional properties. • In dialogue settings, particularly in the absence of explicit regularization mechanisms, words often fail to maintain consistent groundings across different instances, leading to ambiguity and reduced communicative effectiveness. Consistency
• Ideally, a consistent language will exhibit a high degree of overlap between messages and features, leading to a high mutual information value. Consistency Metrics: Mutual Information
Metric for evaluating whether words within a language maintain consistent semantics across varying contexts. • May be considered restrictive, particularly in languages where synonyms are prevalent. • range from 0 to 1. • 1 indicating perfect alignment (each word retains its meaning consistently across different contexts and is thus used coherently). P (w | f) : Probability that a word w is used when a feature f is present. P (f | w) : Probability that a feature f appears when a word w is used
by comparing the size of their intersection to the size of their union • Mξi and Mξj represent sets of messages generated by different agents based on the same input. The similarity ranges from 0 to 1, with 1 indicating complete overlap and thus perfect similarity (-) only applicable to scenarios where multiple agents generate messages about the same set of objects. Consistency Metrics: Similarity
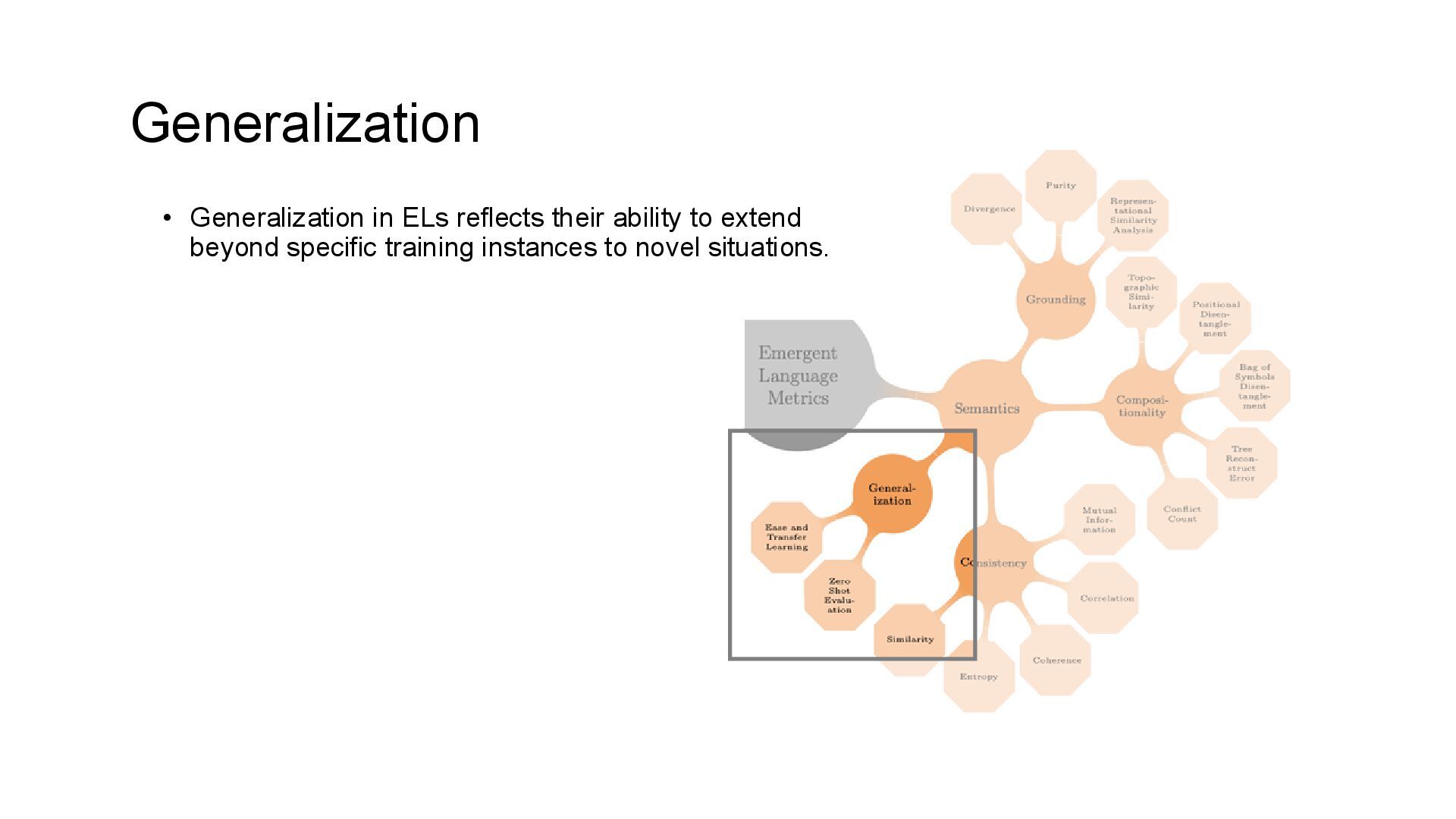
with feature combinations not encountered during training. • Evaluate with objects that resemble training data but have unseen properties or entirely novel combinations of features • Evaluate with entirely new input scenarios, such as testing the ability of agents to generalize across different game types (-) requires a ground truth oracle to withhold feature combinations unseen partner (cross-play or zero-shot coordination) • Evaluate models by pairing agents that did not communicate during training. (-) can introduce inefficiencies by requiring additional resources to train novel communication partners for testing. Generalization Metrics: Zero Shot Evaluation
easily new listeners can adapt to an EL on distinct tasks. • Assessing how effectively a deterministic language, developed by a fixed set of speakers, can be transferred to new listeners who are trained on tasks different from the original one for which the language was optimized. Generalization Metrics: Ease of Transfer Learning(ETL)
{kind=link}
{kind=link}
{kind=link}
![Grounding Metrics: Divergence • Proposed by Havrylov and Titov [15]](https://files.speakerdeck.com/presentations/8ceadc8c279142f38e4b13cca0151f9a/slide_3.jpg){kind=link}
![Grounding Metrics: Purity • Proposed by Lazaridou et al. [14]](https://files.speakerdeck.com/presentations/8ceadc8c279142f38e4b13cca0151f9a/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• Proposed by Chaabouni et al. [25] • Evaluates how](https://files.speakerdeck.com/presentations/8ceadc8c279142f38e4b13cca0151f9a/slide_22.jpg){kind=link}
{kind=link}