Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Data Augmentation Based on Cross-Modal Back Tra...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 04, 2021
Technology
1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Data Augmentation Based on Cross-Modal Back Translation for Multimodal Language Understanding for Fetching Instruction
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 04, 2021
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
85
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
750
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
280
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
510
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
200
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
430
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
320
人とエージェントが高め合う協業設計
kintotechdev
0
750
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
2
260
文字起こし基盤の信頼性
abnoumaru
0
120
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
270
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
210
Featured
See All Featured
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
510
The Spectacular Lies of Maps
axbom
PRO
1
870
Believing is Seeing
oripsolob
1
170
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
Docker and Python
trallard
47
4k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Transcript
慶應義塾大学 飯田紡,九曜克之,石川慎太朗,杉浦孔明 物体指示理解タスクにおける クロスモーダル言語生成に基づくデータ拡張
背景︓⽣活⽀援ロボットに⾃然⾔語で命令できれば便利 2 ⽣活⽀援ロボット • 障がいを持つ⼈々を物理的に⽀援可能 • 在宅介護者不⾜を克服 スムーズな対話に基づいて ⽣活⽀援タスクを実⾏できれば便利 例)「机の上の飲み物を取ってきて」
対象物体の特定が困難なシーンが存在 3 対象物体の特定が困難な場合がある • 表現が曖昧 • 対象物体候補が複数存在 命令⽂中の参照表現を理解する必要がある “Grab the
red can near to white bottle and put it in the lower left box.” どっちの ⽸︖
問題設定︓物体操作指⽰理解 4 MLU-FI (Multimodal Language Understanding for Fetching Instruction) 命令⽂と画像をもとに,命令⽂中の移動対象物体を特定
⼊⼒︓対象物体候補の領域, 画像中の各物体の領域, 命令⽂ 出⼒︓候補領域中の物体が対象物体である確率の予測値 の物体は命令⽂中の移動対象物体︖ コンテキスト領域 候補領域 move the pink toy animal. 対象物体
関連研究︓物体指⽰理解における既存⼿法はサンプル効率が悪い 6 • [Hatori+ ICRA18] – 物体のピッキングタスクにおける指⽰理解⼿法 • MTCM, MTCM-AB
[Magassouba+ ICRA19, 20] – 命令⽂と全体画像から対象物体を特定 • Target-dependent UNITER[Ishikawa+ RAL & IROS21] – 全体画像の代わりに物体領域を⼊⼒し物体間の関係を学習 1⽂につき 正例: 1物体, 負例: 正例以外の物体全て ⼤量の負例サンプルを使⽤していなかった “Grab the red can near to white bottle and put it in the lower left box.”
提案⼿法︓クロスモーダル逆翻訳データ拡張 8 良い命令⽂のみをデータ拡張に使⽤ 良い命令⽂︓理解モジュールの出⼒! " # $ %!"#$ がしきい値!以上 "
#!"# = % & $%&' ()) | ( ) *()) % & $%&' ()) ≥ ! !: インデックス
⽣成モジュールにより⽣成した命令⽂の例 12 “grab the yellow color object near the white
bottle and put it in the upper right.” “move the green mug cup to the box with the teddy bear.”
提案⼿法における⽣成モジュール 13 Case Relation Transformer[Kambara+ RAL & IROS21] ⼊⼒︓対象領域 コンテキスト領域(対象以外の物体領域)
⽬標領域 出⼒︓対象物体を⽬標領域に移動させる命令⽂ CRB (Case Relation Block)と Transformerにより • 物体間の位置関係をモデル化 • 参照表現を含む⽂を⽣成可能
Target-dependent UNITER[Ishikawa+ RAL & IROS21] ⼊⼒︓候補領域 コンテキスト領域 命令⽂ 出⼒︓候補領域が命令⽂の対象物体である確率の予測値(() *)
提案⼿法における理解モジュール 14 物体間の関係をモデル化 命令⽂中の参照表現理解
実験設定︓データ数ごとのMLU-FIタスクにおける提案⼿法の性能評価 15 PFN-PIC データセット[Hatori+ 18] 画像と画像中の物体に関する命令⽂から構成 4つの箱に物体を無作為に配置 訓練データ数.+,を変化させて データ拡張の効果を確認 .+,
= 4000, 6000, 10000, 63330 (全⽂) が命令⽂中の対象物体かどうかの分類精度により性能評価 “Move the yellow container to the top left box.”
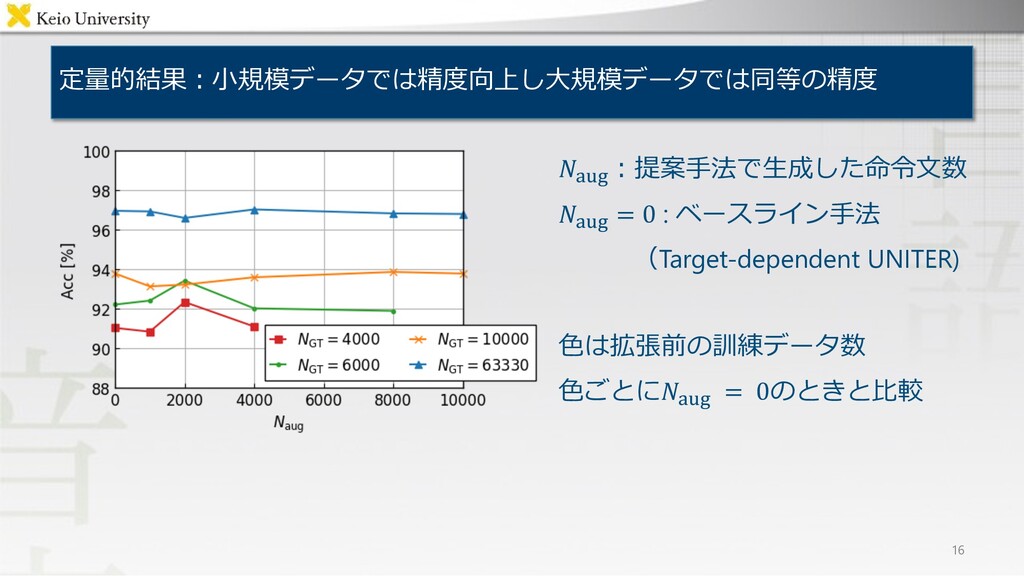
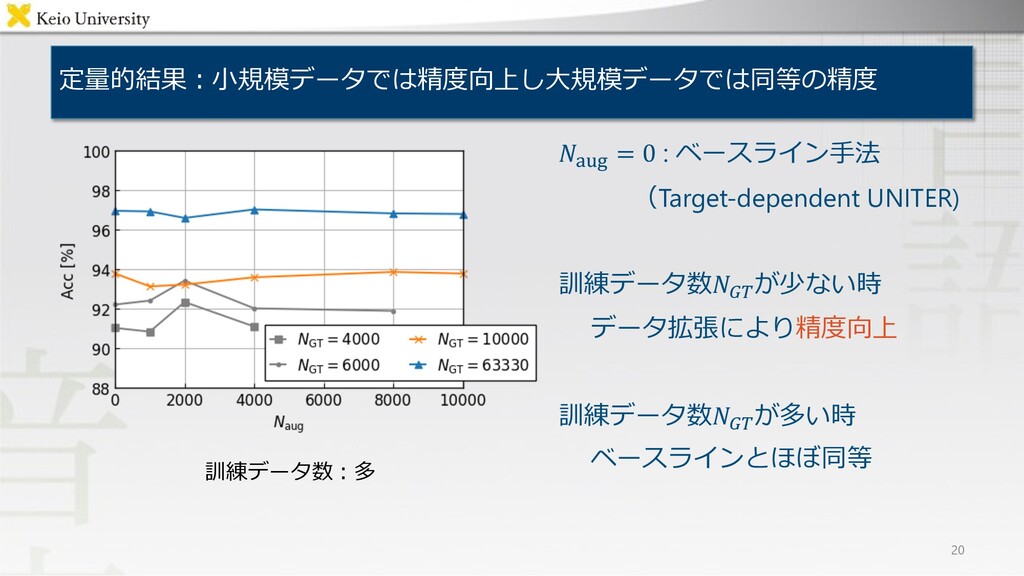
.!"#︓提案⼿法で⽣成した命令⽂数 .!"# = 0 : ベースライン⼿法 (Target-dependent UNITER) ⾊は拡張前の訓練データ数 ⾊ごとに.!"#
= 0のときと⽐較 定量的結果︓⼩規模データでは精度向上し⼤規模データでは同等の精度 16
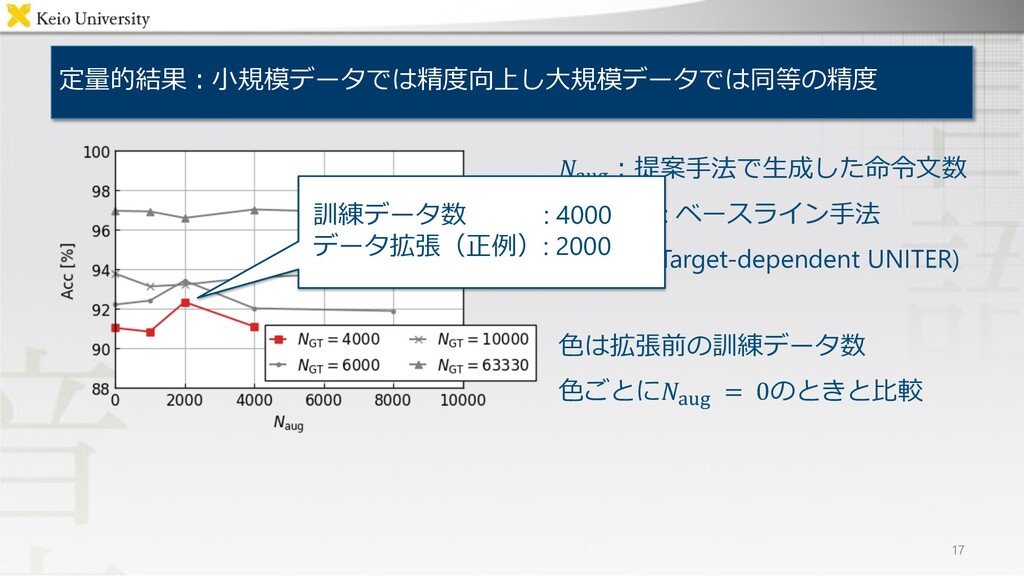
定量的結果︓⼩規模データでは精度向上し⼤規模データでは同等の精度 17 .!"#︓提案⼿法で⽣成した命令⽂数 .!"# = 0 : ベースライン⼿法 (Target-dependent UNITER)
⾊は拡張前の訓練データ数 ⾊ごとに.!"# = 0のときと⽐較 訓練データ数 : 4000 データ拡張(正例): 2000
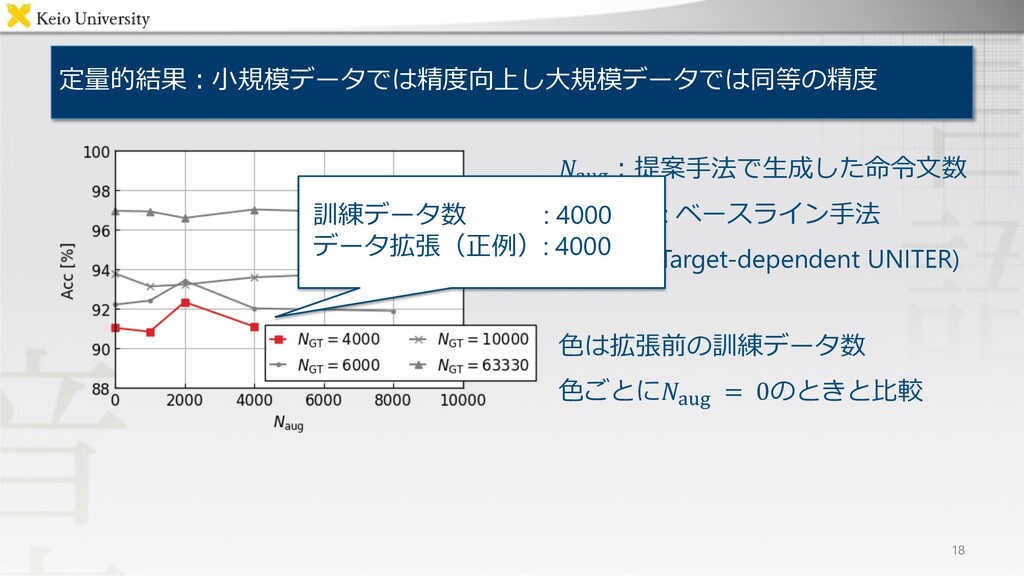
定量的結果︓⼩規模データでは精度向上し⼤規模データでは同等の精度 18 .!"#︓提案⼿法で⽣成した命令⽂数 .!"# = 0 : ベースライン⼿法 (Target-dependent UNITER)
⾊は拡張前の訓練データ数 ⾊ごとに.!"# = 0のときと⽐較 訓練データ数 : 4000 データ拡張(正例): 4000
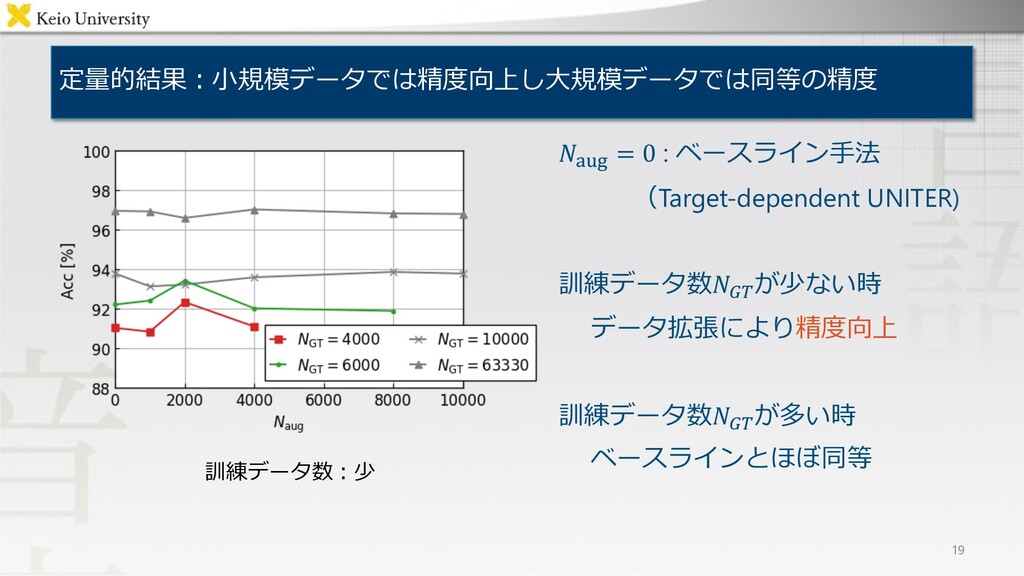
.!"# = 0 : ベースライン⼿法 (Target-dependent UNITER) 訓練データ数.-.が少ない時 データ拡張により精度向上 訓練データ数.-.が多い時
ベースラインとほぼ同等 定量的結果︓⼩規模データでは精度向上し⼤規模データでは同等の精度 19 訓練データ数︓少
.!"# = 0 : ベースライン⼿法 (Target-dependent UNITER) 訓練データ数.-.が少ない時 データ拡張により精度向上 訓練データ数.-.が多い時
ベースラインとほぼ同等 定量的結果︓⼩規模データでは精度向上し⼤規模データでは同等の精度 20 訓練データ数︓多
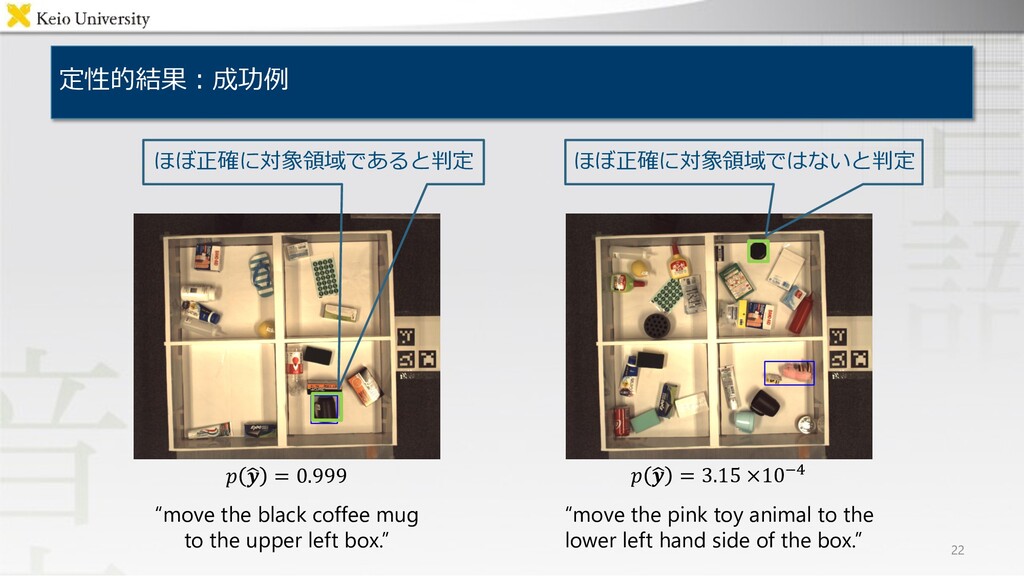
定性的結果︓成功例 22 “move the black coffee mug to the upper
left box.” ! " # = 0.999 ! " # = 3.15 ×10%& “move the pink toy animal to the lower left hand side of the box.” ほぼ正確に対象領域であると判定 ほぼ正確に対象領域ではないと判定
⼊⼒の領域数./012を変化させて検証 ./012 = 20︓候補領域に近い順20個に制限 訓練データ数.+,が少ない時 ⼊⼒領域数の制限がモデルの性能向上に寄与 Ablation Studies︓⼩規模データでは⼊⼒領域数の制限により精度向上 23 Acc
[%] .'()* .+, 20 全て 4000 92.4 ± 0.7 91.7 ± 0.9 6000 93.4 ± 0.6 93.2 ± 0.5 10000 93.2 ± 0.5 93.7 ± 0.5 63330 96.6 ± 1.1 97.1 ± 0.3
背景︓⽣活⽀援ロボットに⾃然⾔語で命令できれば便利 提案︓クロスモーダル逆翻訳データ拡張によるデータ拡張⼿法 結果︓標準データセットにおいて、ベースライン⼿法を精度で上回る まとめ 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![関連研究︓物体指⽰理解における既存⼿法はサンプル効率が悪い 6 • [Hatori+ ICRA18] – 物体のピッキングタスクにおける指⽰理解⼿法 • MTCM, MTCM-AB](https://files.speakerdeck.com/presentations/8d2aa69eaae14f3a91dcc707d7340e37/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
![提案⼿法における⽣成モジュール 13 Case Relation Transformer[Kambara+ RAL & IROS21] ⼊⼒︓対象領域 コンテキスト領域(対象以外の物体領域)](https://files.speakerdeck.com/presentations/8d2aa69eaae14f3a91dcc707d7340e37/slide_7.jpg){kind=link}
![Target-dependent UNITER[Ishikawa+ RAL & IROS21] ⼊⼒︓候補領域 コンテキスト領域 命令⽂ 出⼒︓候補領域が命令⽂の対象物体である確率の予測値(() *)](https://files.speakerdeck.com/presentations/8d2aa69eaae14f3a91dcc707d7340e37/slide_8.jpg){kind=link}
![実験設定︓データ数ごとのMLU-FIタスクにおける提案⼿法の性能評価 15 PFN-PIC データセット[Hatori+ 18] 画像と画像中の物体に関する命令⽂から構成 4つの箱に物体を無作為に配置 訓練データ数.+,を変化させて データ拡張の効果を確認 .+,](https://files.speakerdeck.com/presentations/8d2aa69eaae14f3a91dcc707d7340e37/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}